







概述
对于爬虫来说,整个爬虫包括了网络请求、数据解析、数据请求、设置代理、多线程等内容,这些部分在之前的内容中都分别进行了说明。因此如果在之前要完成一个爬虫的话,就要使用上面提到的所有工具,从头开始一步一步构建自己的爬虫,这无疑是一项繁琐的工作,而 Scrapy 解决了这个问题。
Scrapy 则实现了上边的所有功能,Scrapy 通过将基本的功能进行封装,从而提高了开发的效率。而正是因为它强大的功能,使得它也区别于之前提到的实现某一项功能的工具。这里先说明 Scrapy 框架。
数据流
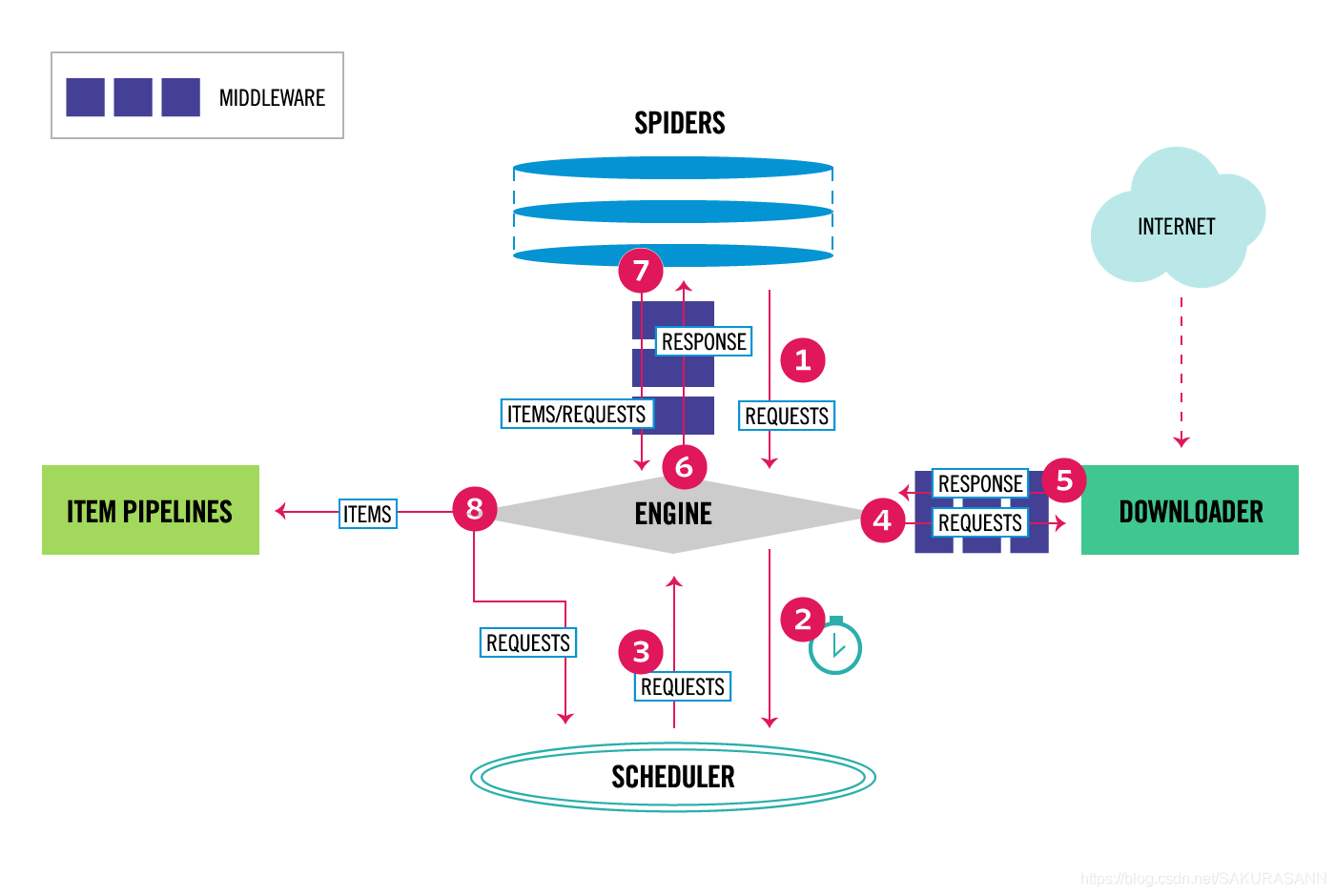
上边红色的箭头就表示了数据的流动。Engine 控制 Scrapy 中的数据流动,具体为:
- Engine 从 Spider 获取初始爬取请求
- Engine 在 Scheduler 中进行请求调度,并请求下一个爬取请求
- Scheduler 返回下一个请求到 Engine
- Engine 通过 Downloader Middlewares 发送请求到 Downloader
- 页面完成下载后,Downloader 生成页面的响应信息并通过 Downloader Midderwares 将之发送到 Engine
- Engine 接收到来自 Downloader 的响应信息,并通过 Spider Midderwares 将之发送到 Spider 进行处理
- Spider 通过 Spider Middlewares 处理响应并将废弃项和新请求返回到 Engine
- Engine 发送处理项到 Item Pipelines,然后发送处理请求到 Scheduler 并询问下一个爬取请求
- 该过程一直循环直到 Scheduler 中的请求被处理完毕
Scrapy Engine
Engine 负责控制系统中所有组件之间的数据流动,并在发生某些操作时触发某些事件
Scheduler
Scheduler 接收 Engine 发来的请求,并在 Engine 请求它们的时候使之队列化进行数据流动
Downloader
Downloader 负责获取网页并将之反馈到 Engine,Engine 再将之反馈给 Spider
Spiders
Spiders 是用户编写的自定义类,用于解析响应和提取信息
Item Pipeline
Item Pipeline 负责在 Spiders 提取信息的时候对信息进行处理, 主要包括清理、验证和存储
Downloader middlewares
Downloader middlewares 位于 Engine 和 Downloader 之间,主要是处理从 Engine 到 Downloader 的请求和从 Downloader 到 Engine 的响应。可以用来:
- 在将请求发送到 Downloader 之前处理请求
- 在将接收到的响应传递给 spider 之前进行更改
- 发送新的请求而不是将接收到的响应传递给 spider
- 传递响应到 spider,而不需要获取网页
- 删除请求
Spider middlewares
Spider middlewares 位于 Engine 和 Spiders 之间,能够处理 spider 的输入(响应)和输出(信息和请求)。可以用来:
- spider 回调的后处理输出——更改/添加/删除请求或信息
- start_requests 后处理
- 处理 spider 异常
- 对某些基于响应内容的请求调用 errback 而不是 callback
Event-driven networking
Scrapy 是由 Twisted(一个大众的事件驱动的 python 网络框架),因此是非阻塞的(异步)。














 811
811











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









