






目录
引子
自C语言诞生数年后,C++也同样于贝尔实验室问世。不同于C语言面向过程的编程特性,C++同时还可以进行以抽象数据类型为特点的基于对象的程序设计,还可以进行以继承和多态为特点的面向对象的程序设计。C++擅长面向对象程序设计的同时,还可以进行基于过程的程序设计(兼容C)。
可以认为,C++是比C语言更高级一些的语言,它解决了很多C语言的不足,使用起来更方便,同时它也兼容C。
命名空间
我们知道,C语言中在一个域里不能有重复的变量名、函数名,但是在不同域里面可以。
编译器的两种查找规则
比如这里全局域里和局部域里都定义了变量a,在main函数里打印a的值,默认先访问的是离得近的局部域里的a,如果要访问全局域里的a,需要在前面加域作用限定符 : :
因为 : : 前是空的,默认访问全局。

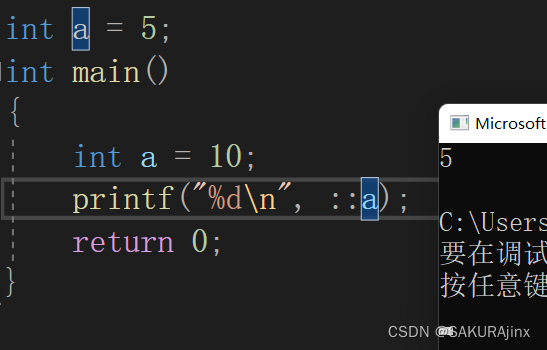
可以得知:编译查找规则是默认先访问局部,再访问全局。
这个例子也可以看出,一个域里不能有重名。
C语言中在一个域里不能有重复的变量名、函数名,但是在C++中是支持的。
为什么C++中支持,就是因为命名空间的存在。
当我们在全局域里建立了一个命名空间,并在里面创建了变量、类型、函数等,那么即使命名空间外有重名的也不会造成影响(前提是使用时需要指定是命名空间的还是外部的)。
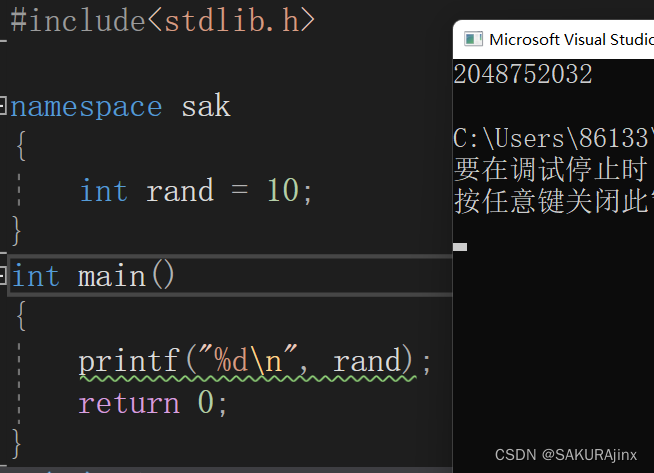
我们定义一个命名空间sak,在里面创建一个变量rand,此时就算和头文件里包含的函数rand重名,也不会有影响,因为namespace里的rand就像被围墙围起来的一样,从外面看不到了 (此时默认访问的是命名空间外的rand)。
此外,这里的rand也还是全局变量,别看它在{ }内就觉得它是局部变量,它任然是全局的。
命名空间namespace只是改变了编译查找规则,并没有改变变量的生命周期。
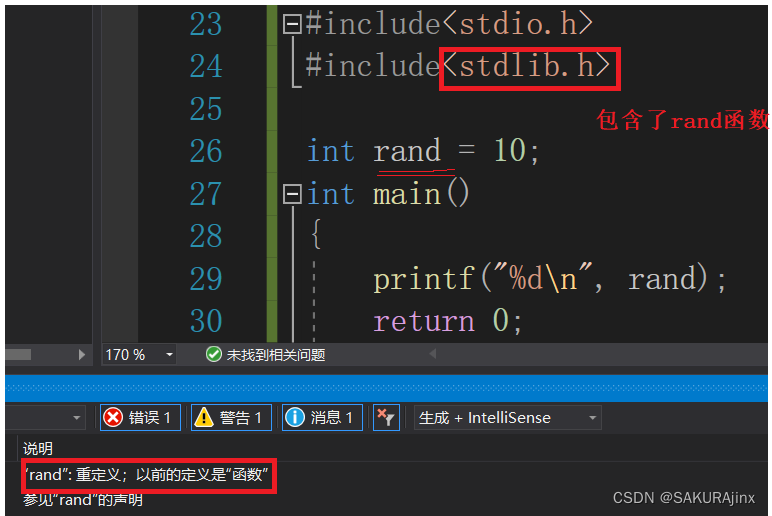
编译器默认是先找局部再找全局,如果加上指定域查找,比如指定要找namespace里的变量,那么就改变了编译查找方式,直接去namespace里找,找不到就报错。
像上面,rand前不加任何指定修饰,默认访问的是全局的并且不在命名空间中的rand,也就是头文件stdlib.h 里 函数rand的地址。
要指定访问namespace里的rand,这么写就可以:

注意:指定去命名空间中找,没找到的话会报错,而不是再去其他地方找。
上面就是编译器的两种查找规则。
命名空间里除了变量,还可以定义类型和函数。
namespace sak
{
int a;
struct node
{
double b;
struct node* next;
};
void func()
{
printf("hello\n");
}
}并且命名空间还可以嵌套命名空间:
namespace sak
{
int a = 0;
namespace sak1
{
int b = 1;
namespace sak2
{
int c = 2;
}
}
}
int main()
{
printf("%d\n", sak::sak1::sak2::c);
return 0;
}这里打印的时候先访问sak,找sak1,再找sak2,再找变量c,如果有一环找不到就报错。
当然,上面的变量a, b, c都是全局变量。(一定要纠正在{ }内的就是局部变量的错误概念)
C++标准库中的函数和库类都是是在命名空间std中定义的 ,所以我们要使用标准库中的函数或类都要使用std来限定。
也就是说C++有一个超大的命名空间,里面放的是C++标准库中的函数和类,而这个命名空间叫std,我们从最简单的打印来看窥探其貌。
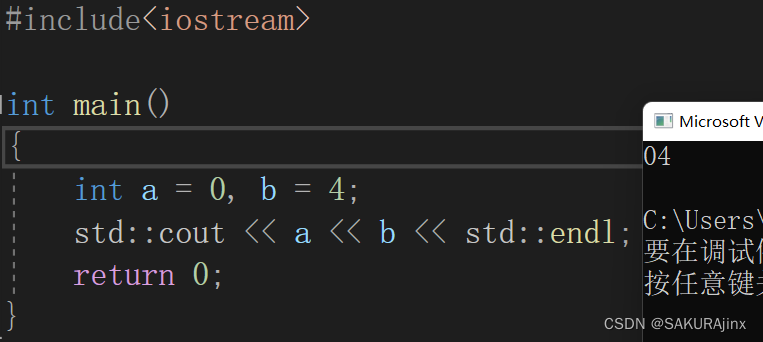
这里std:: 就是指定C++命名空间std,cout其实是个类,等我们到后面学了类和对象、重载、继承相关概念再说。
现在简单的记一下这是干什么的就可以了。可以将cout看作是控制台,输出a,b的值,endl 则类似换行的意思。下面这样写一样可以证明。

其实从取名方式也可以看出,cout 是 console out (控制台)的缩写,endl则是end line(换行)
<<在C语言中是左移操作符,C++中还代表流输出运算符。
对应的,>>在C语言中是右移操作符,C++也代表流提取运算符。与cin配对使用,从控制台提取数据拿到变量中。
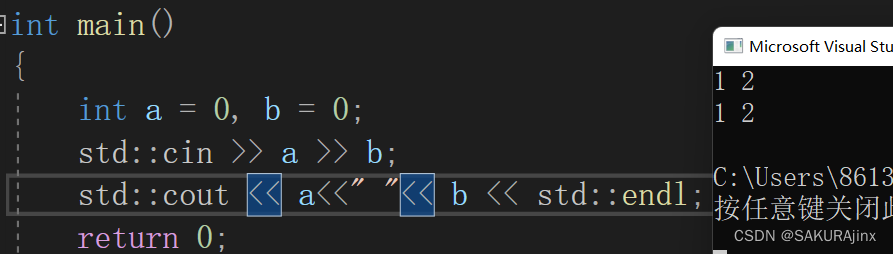
cout 和 cin都是自动识别类型的。
如果浮点数需要保留一位小数等,我们尽量还是用C语言的方法,C++ cout也可以做到,但是比较麻烦,因为C++兼容C,因此还是直接写成 %.1f 比较方便。
如果是字符需要显示ASCLL值,强转即可。

还有些打印在C++中比较麻烦,可以用C的方式打印。
我们知道std这个命名空间非常大,里面的东西也非常多,那么std是在一个文件内吗?
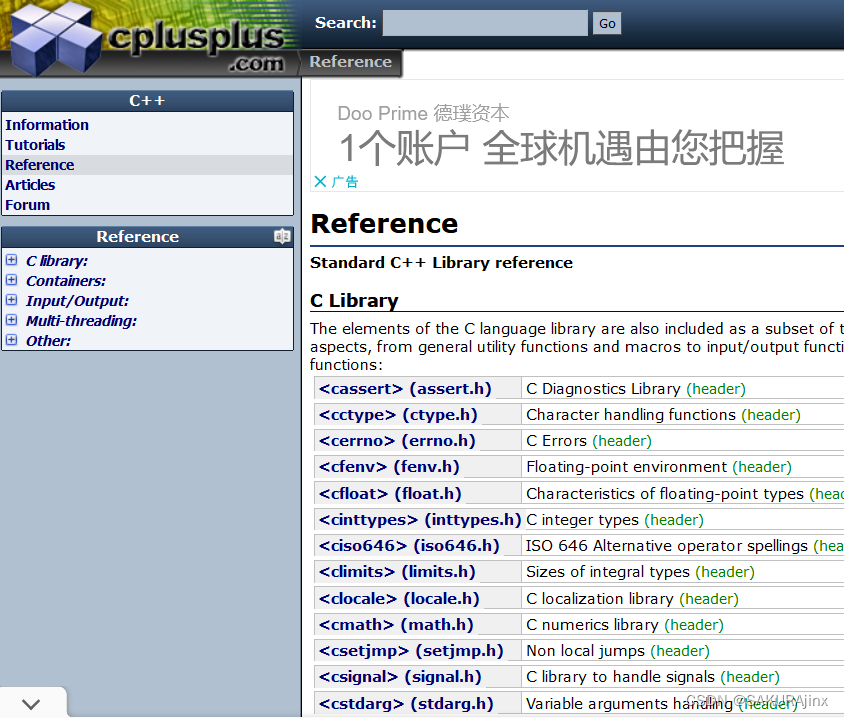
显然不是的,可以看到C++是分文件装到std里面的,那不同文件的可以合并吗?
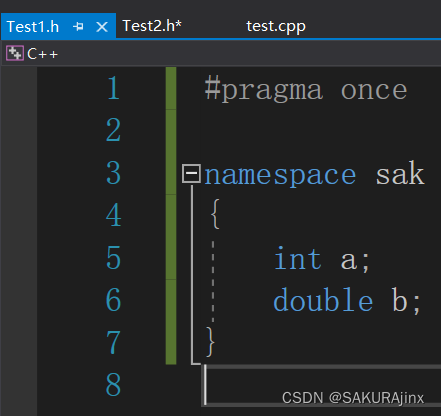
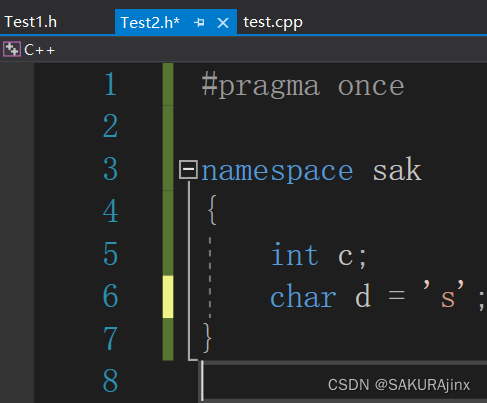

由此得出,不同文件中,只要namespace名字相同,则默认编译时会合并。
C++的命名空间std 也是如此合并的。头文件在编译的时候会展开,此时不同文件的std也就合并了。并且同一个文件中同名的namespace也会合并。
至于嵌套,嵌套的命名空间不是同一级的,不可能合并也不需要考虑,同一级的才有可能合并。
补充:
C++的头文件没有规定要不要加 .h 但是#include<iostream>是不加.h的
除非是一些很老的编译器(如VC6.0)是#include<iostream.h>
我们要使用C++标准库里的命名空间std时,和我们自己定义的命名空间一样,需要在类或对象前面加std: :
如果是平常练习每次要加std : : 太过麻烦可以在前面先加using namespace std,这样相当于将std的围墙拆掉,展开命名空间了。这样是存在一些问题的,因为命名空间存在的意义就是防止重名,展开命名空间可能会造成重名的情况。
还有一种介于上面两种方法之间的方法,就是“将围墙拆一半” ,比如cout使用频繁,可以在前面加一句using std: : cout ,这样只有cout是从命名空间里被拿出来了,只要避免使用和它重名的变量或函数就可以了。
缺省参数
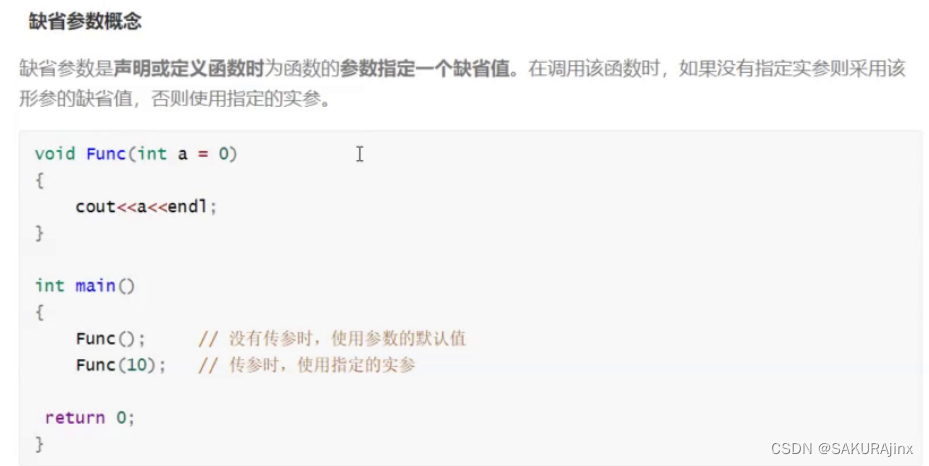
传参时,只能从左往右依次传参,不能跳过某一个参数。


缺省参数分为全缺省和半缺省,全缺省就像上面的代码一样,所有参数都缺省。
半缺省则是部分参数缺省,并且只能从右往左连续缺省,同样不能跳。
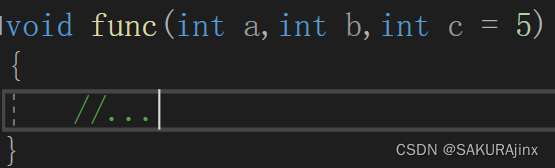
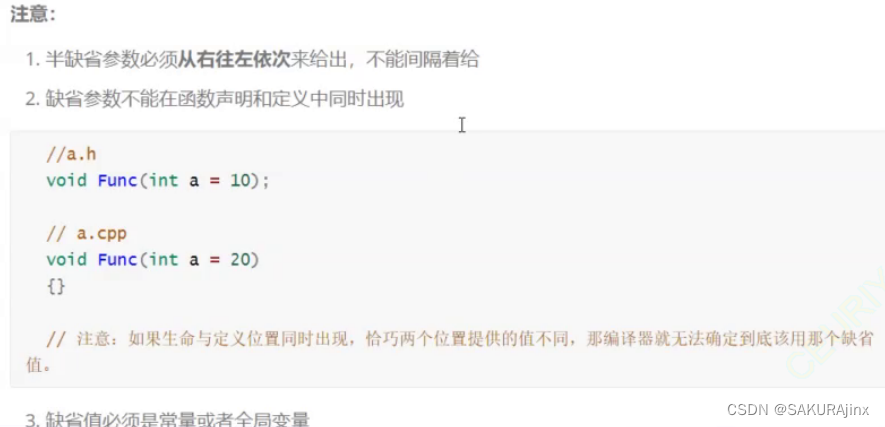
缺省参数不能在定义和声明中同时出现。如:
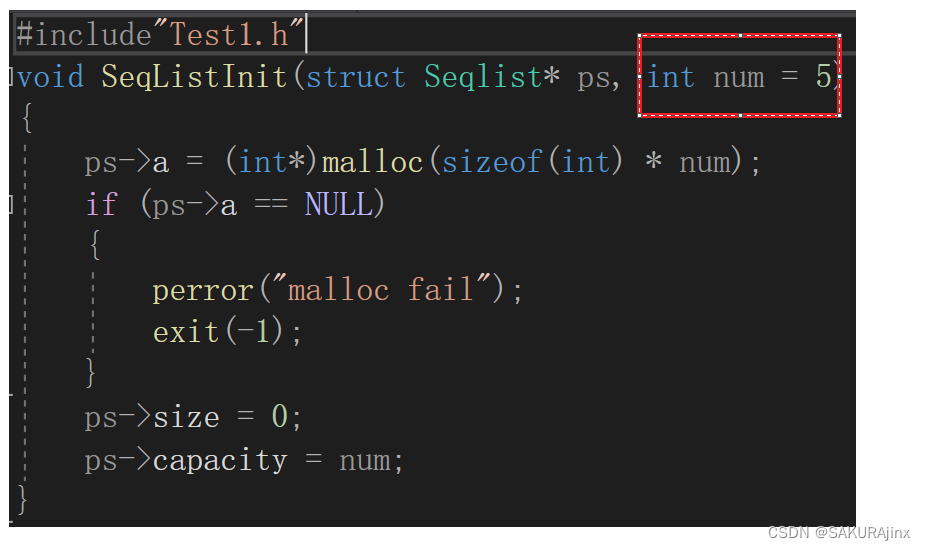
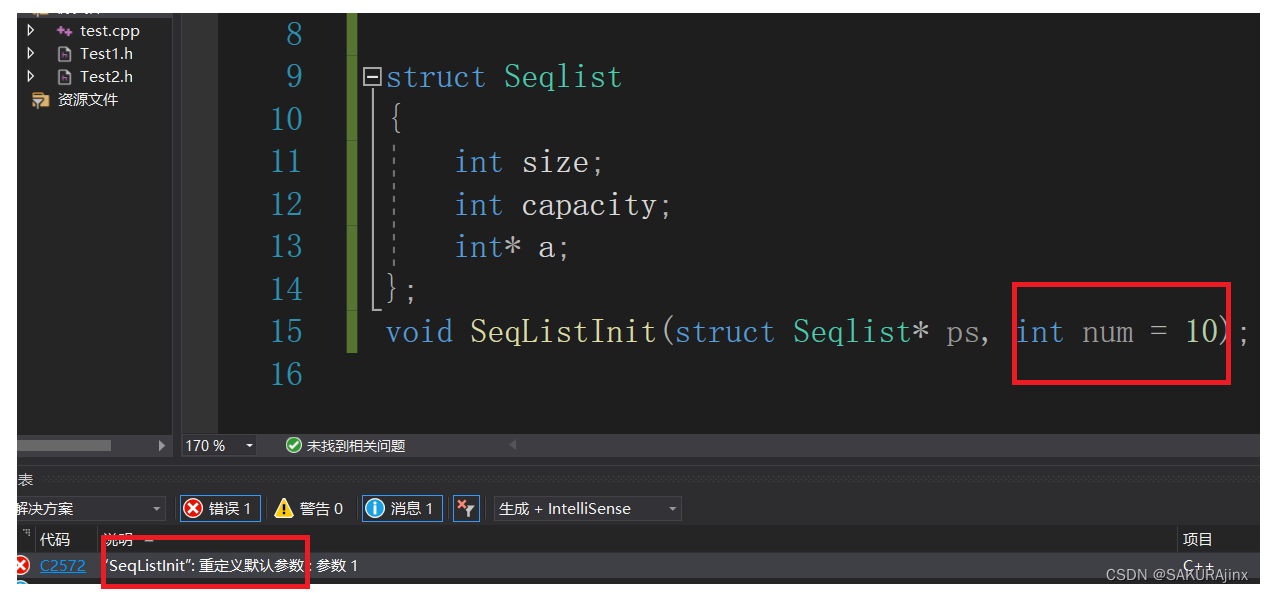
像这里,如果.h 和.cpp里面缺省参数不一致,就会报重定义的错误,应该在声明中给缺省值,而不是在定义中给。
缺省参数有很多应用,比如上面代码,创建顺序表时,如果事先知道需要多大空间,就可以不扩容而是提前用缺省参数代替,不知道的情况下也直接用缺省参数,会方便很多。
函数重载
函数重载就是允许使用同名函数,但是函数的参数不能一样,可以参数个数不同、参数类型不同,也可以参数类型顺序不同。
一、参数个数不同
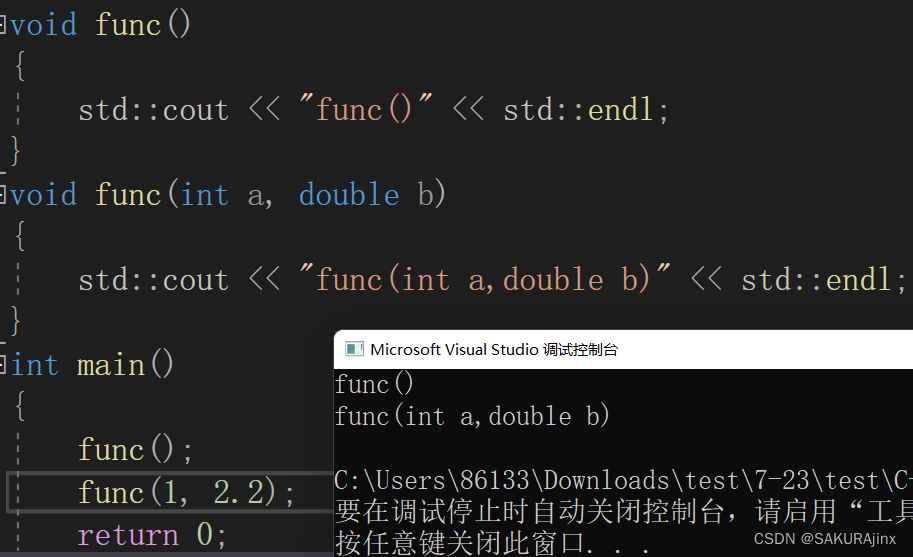
二、参数类型不同
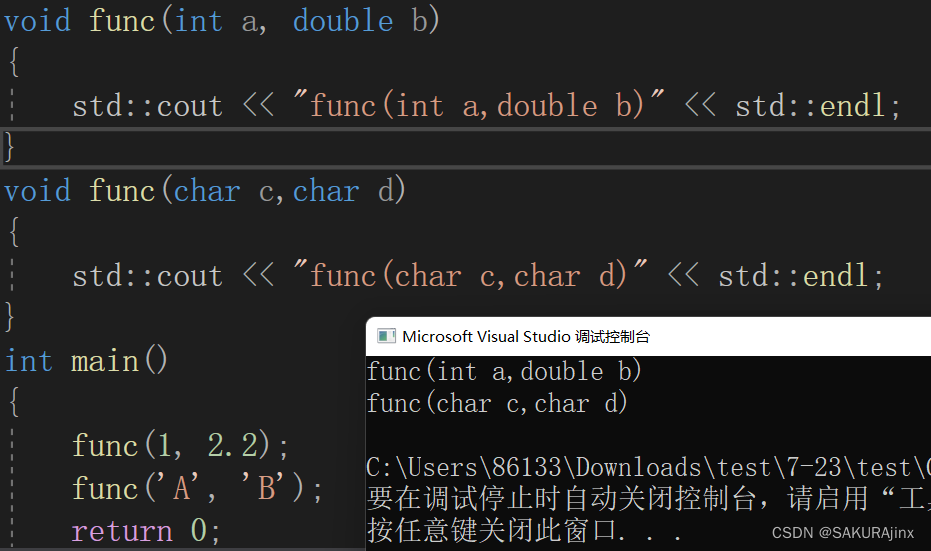
三、参数类型顺序不同
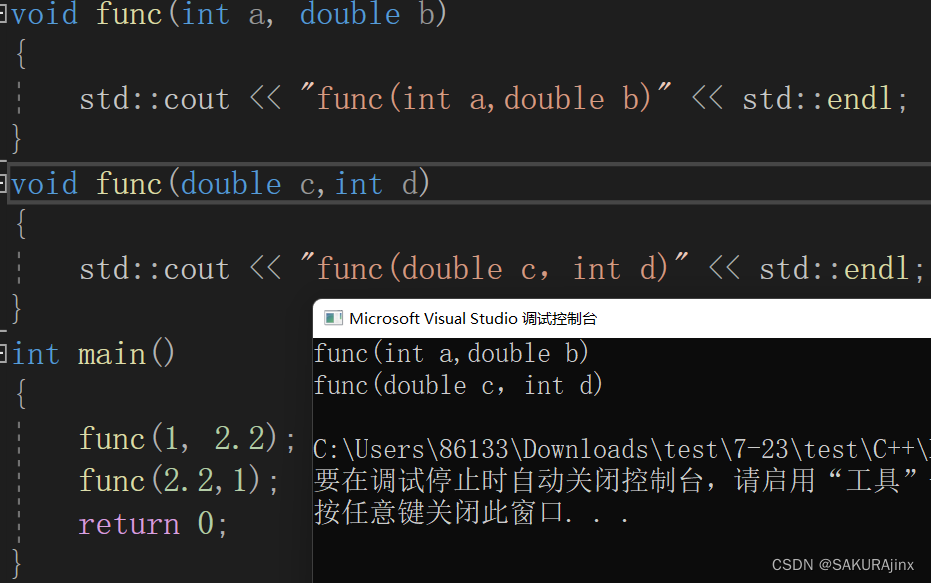
那么下面这种是不是参数类型不同的函数重载呢?
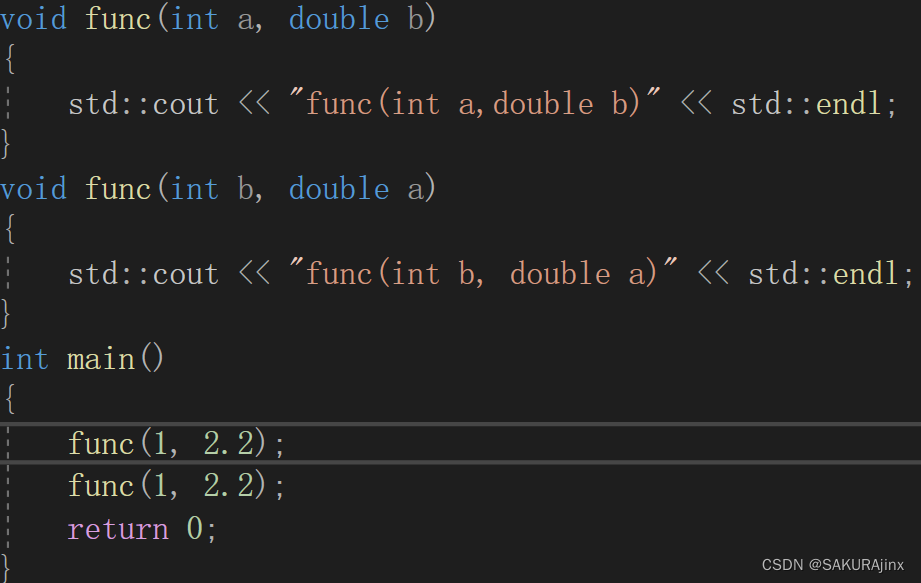
显然不是,类型顺序不同是多个不同的类型的顺序不同,int a,double b 和 int b,double a 它们本质是一样的,不属于函数重载
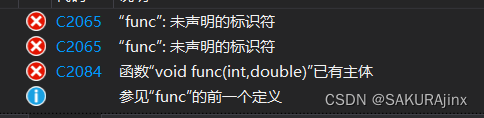
再来看一种:
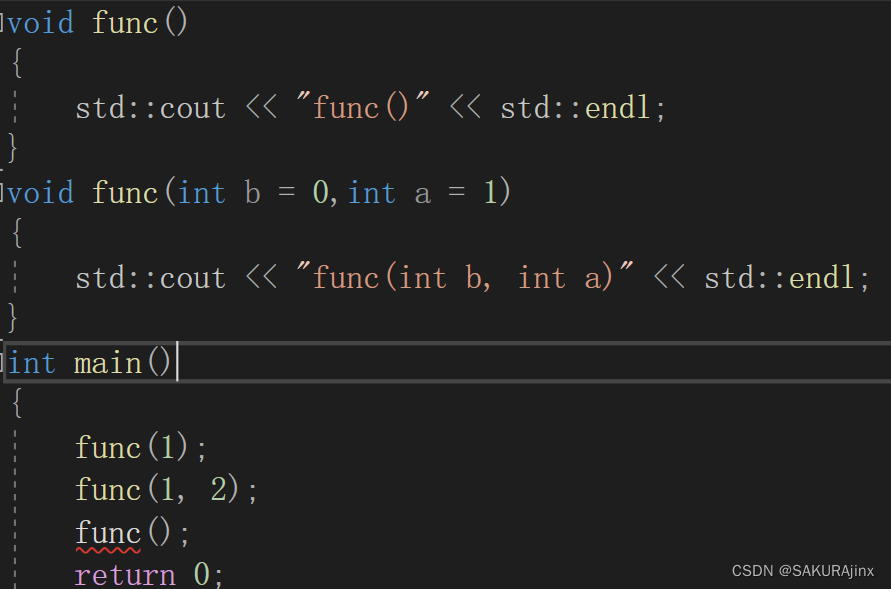
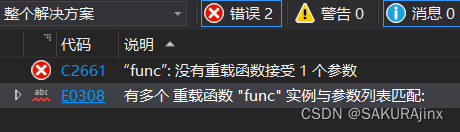
这种为什么会报错呢? 因为编译器不知道func调用的是哪一个函数,究竟是func( ),还是缺省参数的func(int b = 0,int a = 1) ,这就存在二义性的问题。
C++如何支持函数重载
在了解C++是如何支持函数重载之前,先来看一下C语言为什么不支持函数重载。
我们知道,C语言调用函数时,是去找它的地址的,从汇编角度来看,也就是call函数的地址
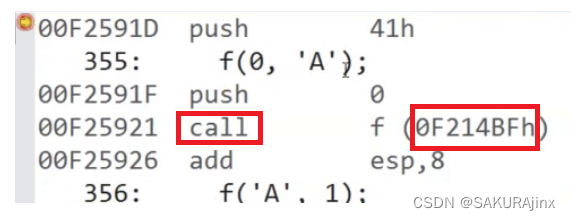
我们是如何找到函数的地址的?是借助符号表,符号表里面存的是函数名以及它的地址。
C语言不允许函数重载就是因为符号表存的函数名是唯一的,比如存swap函数,符号表里存的函数名就是swap,跟地址。
而C++里面不仅仅存的是函数名,还有参数名的首字母
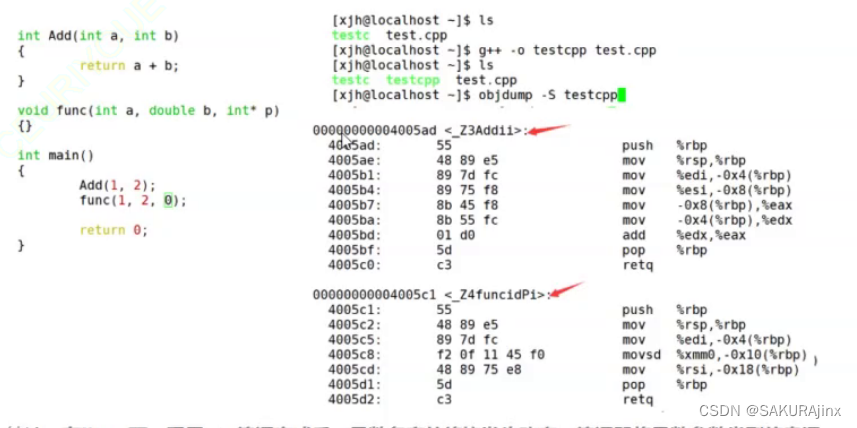
Add(int a,int b) 符号表里:_...Addii
func(int a,double b,int* c) 符号表里:_...funcidpi
这样就区分了同名函数。
返回值不同的函数能不能构成函数重载?
不能!根据上面讲的函数名修饰规则,可以让符号表里的函数名带上返回值的首字母,这样理论上是可以区分的,但是关键是调用时的二义性。
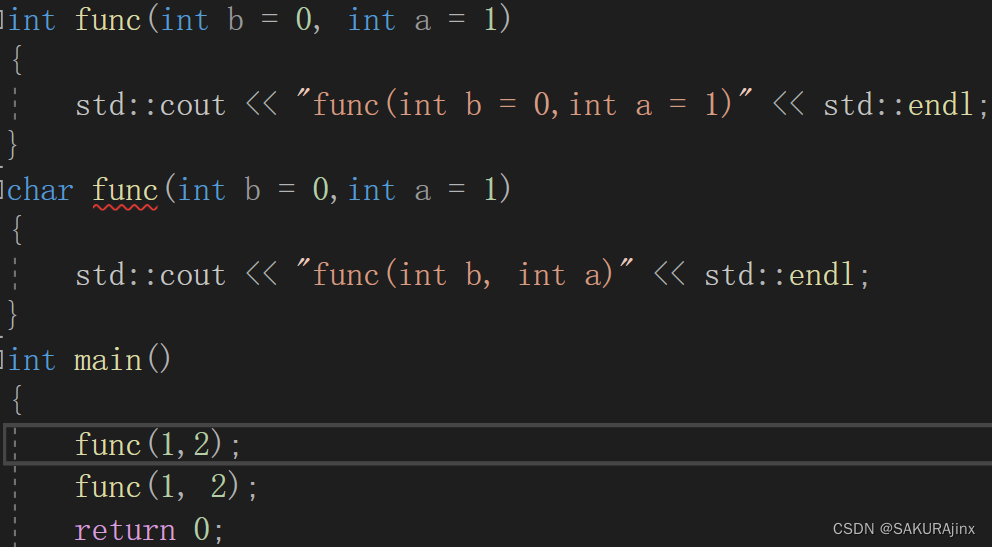
如何区分要调用哪个函数呢?这就造成了二义性。
因此,这才是返回值不同不能构成函数重载的原因。
引用
引用的目的主要用于在函数参数传递中,解决大块数据或对象的传递效率和空间不如意的问题。
用引用传递函数的参数,能保证参数传递中不产生副本(没有拷贝),提高传递的效率,且通过const的使用,保证了引用传递的安全性。
简单来说,引用可以减少拷贝,提高效率,并且可以操作函数返回值,在很多地方取代了C的繁复指针使用,但是C++没有摒弃指针,而是将两者结合并用。
Java里引用完全取代了指针,但是C++里面并没有完全取代,但也方便了不少。
引用其实就是给变量取别名,这个变量可以是整型变量,也可以是指针变量.......

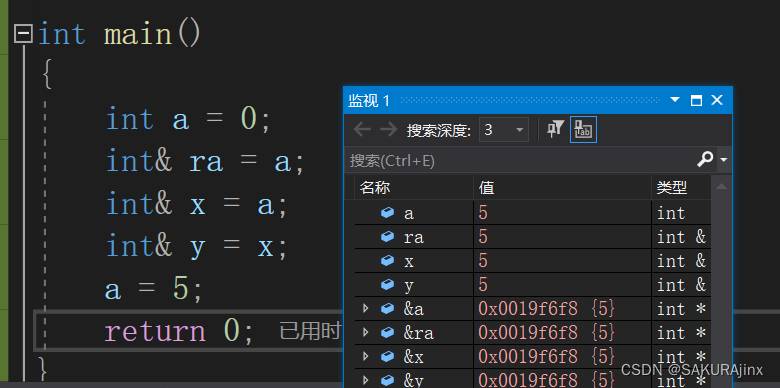
经过引用,a现在有了4个名字:a,ra,x,y,它们都代表a,地址也相同,修改其中一个值,其他也都跟着改变。
那引用具体有什么好处呢?
以swap函数为例,C语言写法如下:


我们要将a,b的地址传参给swap,swap以指针形式接收,通过*解引用来改变外部实参a,b
如果不传地址只传值,那么形参不会改变实参。
这里只是简单的一级指针使用,比较好理解,如果是二级、乃至多级指针就很麻烦而且难以理解了,如果用引用,相当于直接改变变量本身,就比较好理解而且方便了。
引用,可以这么写:


有的C++书上乃至教材,在讲述链表时为了简化会用到引用,避免使用二级指针。
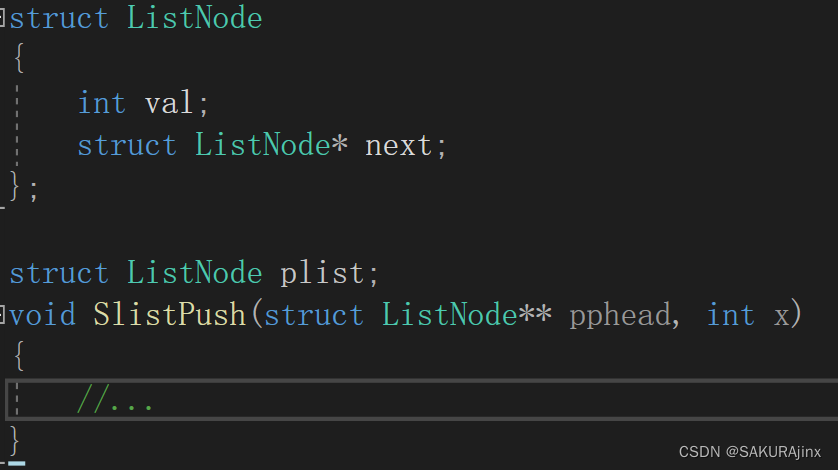
本来是需要二级指针的,为了避免使用二级指针,改成引用的方式。
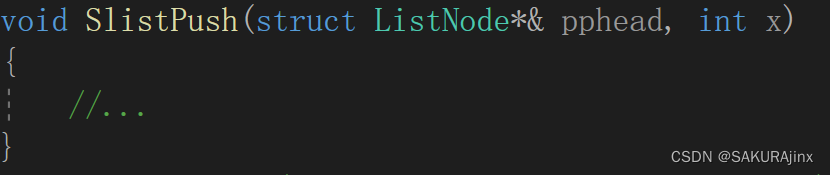
有的书上还会这么写:
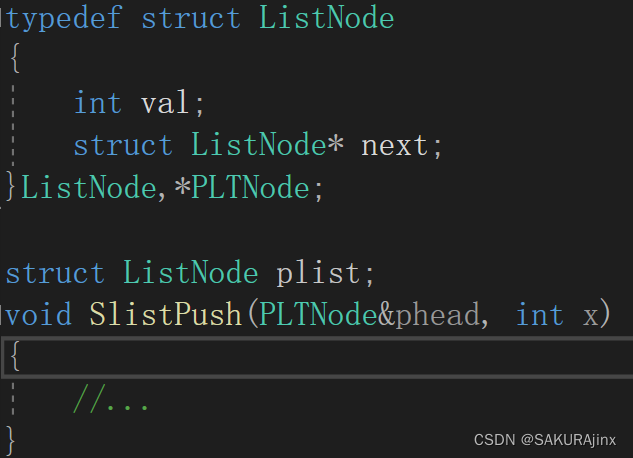
将结构类型重命名,并将结构指针也重命名为PLTNode
这里其实是typedef struct ListNode ListNode; typedef struct ListNode* PListNode;两句话
然后下面用引用简化代码,这样避免了二级指针的使用。

特性 1、引用时必须初始化,也就是必须给定引用指向的值,指针可以不初始化,但会指向随机位置(基本不会这么做)。
2、一个变量可以有多个引用
3、引用有一个实体,就不能指向其他实体了。
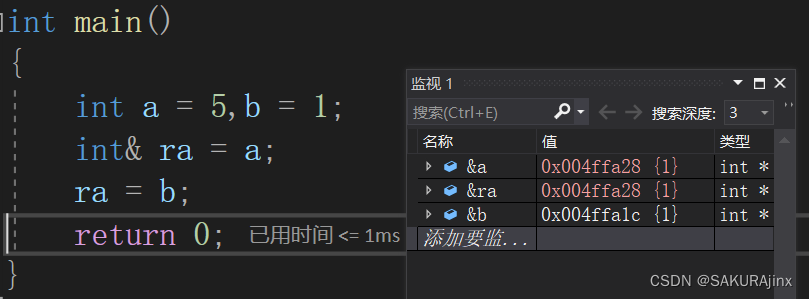
这里ra = b,是赋值,不是改变ra的指向。从地址就可以看出。
这就决定了C++引用无法替代指针! 因为不能改引用指向。而JAVA就可以改变指向,所以Java引用可以替代指针。
引用的使用场景
一、做参数
平时我们写代码,比如排序里面 void Sort(int* arr,int num) 这里的arr和num做的是输入型参数,也就是这里的参数是传进来给我们用的。
而引用做参数,可以做输出型参数,比如swap函数里 void Swap(int& x,int& y) x,y 是输出型参数,
在swap函数里面改变以后传到外面使用的。 平时刷力扣,做OJ经常会碰到returnsize,那也是输出型参数,外面需要这个参数。
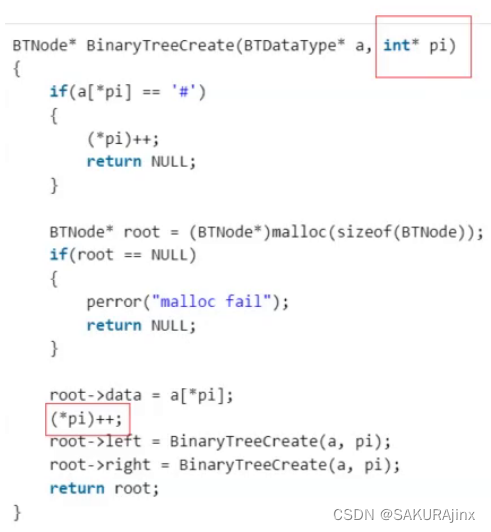
像这段代码要改变形参,C里面都是用指针,需要解引用来改变值;C++里面可以直接用引用,直接改变外面变量的值。
二、做返回值
这里就涉及到两种返回方式了。一种是传值返回;一种是引用返回。
传值返回:
int Count()
{
static int n = 0;
n++;
return n;
}
int main()
{
int ret = Count();
return 0;
}传值返回类似传参,都是需要拷贝的,我们从操作系统和建立栈帧的角度来看一下真个过程。
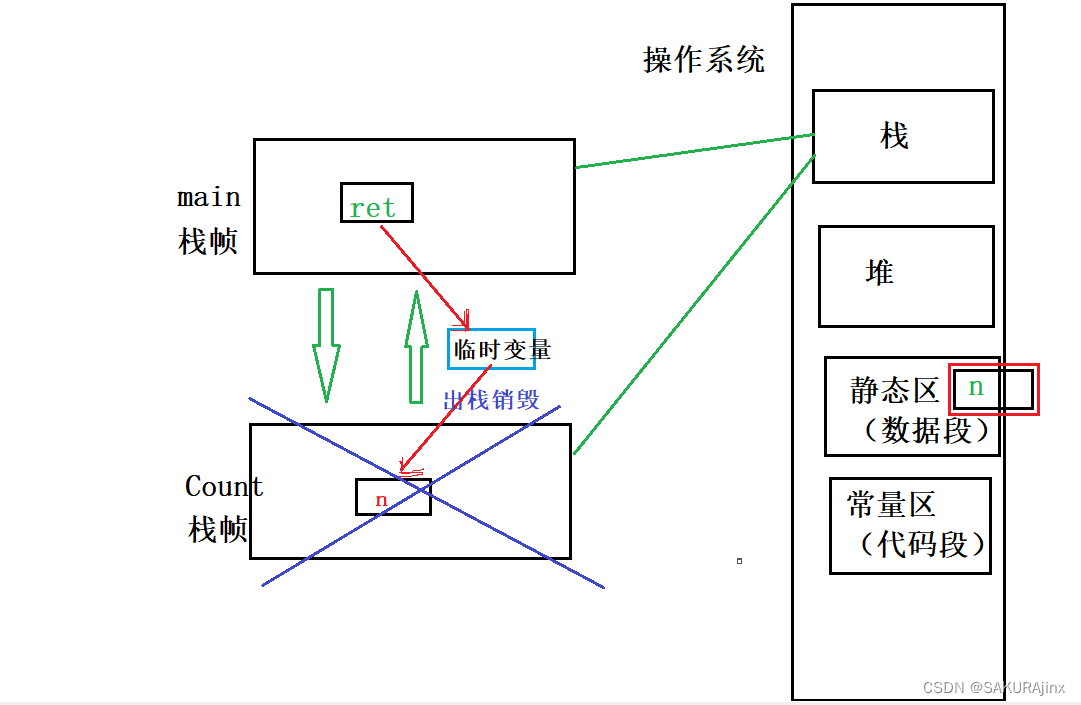
如图所示:main函数先建立栈帧,里面有一个ret变量,调用Count函数,建立Count函数的栈帧,如果n是static修饰的话,n就在静态区,n++,此时要返回n,先是创建一个临时变量,将n拷贝给临时变量然后再将临时变量给ret,调用函数结束Count函数栈帧随之销毁,但是n在静态区所以没有跟着销毁。
如果n没有static修饰的话,就在Count栈帧里,随栈帧销毁而销毁。因为是创建了临时变量拷贝数据,所以n销毁了ret也可以拿到n的值(实际上是拿到临时变量拷贝的值)。临时变量如果比较小,就在寄存器里,大的话是提前在main函数栈帧里开辟好空间给它了。
引用返回
int& Count()
{
static int n = 0;
n++;
return n;
}
int main()
{
int& ret = Count();
return 0;
}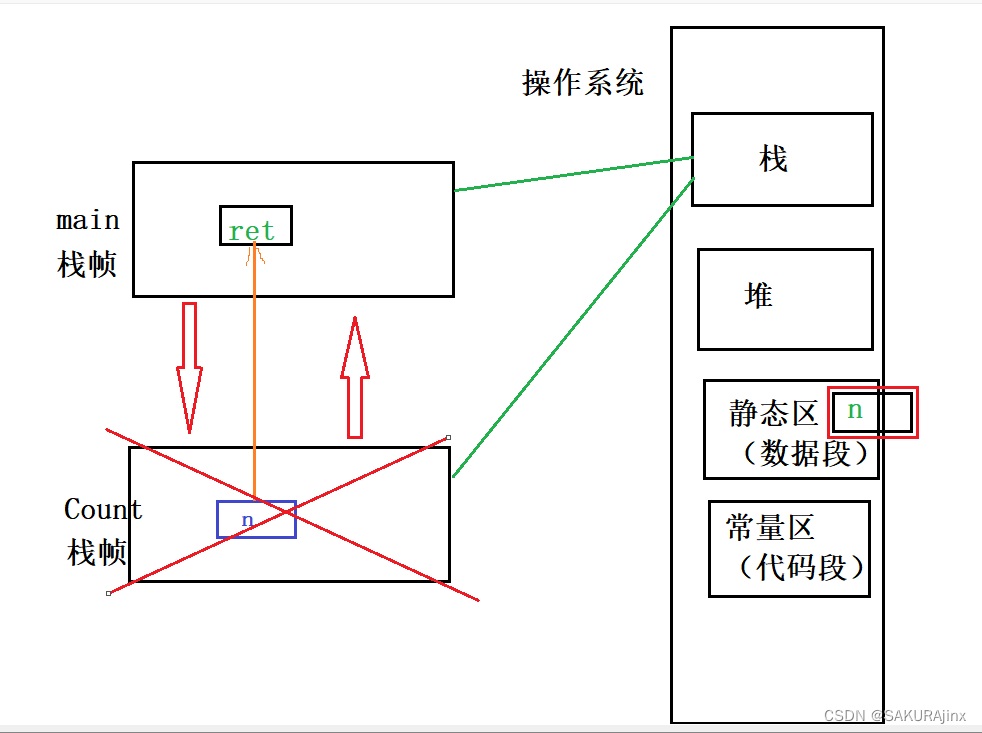
引用返回的不同之处就在于n相当于是ret的别名,直接返回给ret了,不需要拷贝,但是这样有一个问题。
如果n是在静态区还好(static修饰n),不影响返回。但如果n是在Count栈帧里的(没有static修饰n),那随着栈帧销毁n也就销毁了,ret拿到的就不一定是n的值了。
为什么说拿到的不一定是n的值呢?我们来看——

所以我们一定要清楚空间的申请和释放,空间原本就在那里,申请是获得了空间的使用权,释放销毁不是把空间丢掉了,而是还给操作系统使用权。
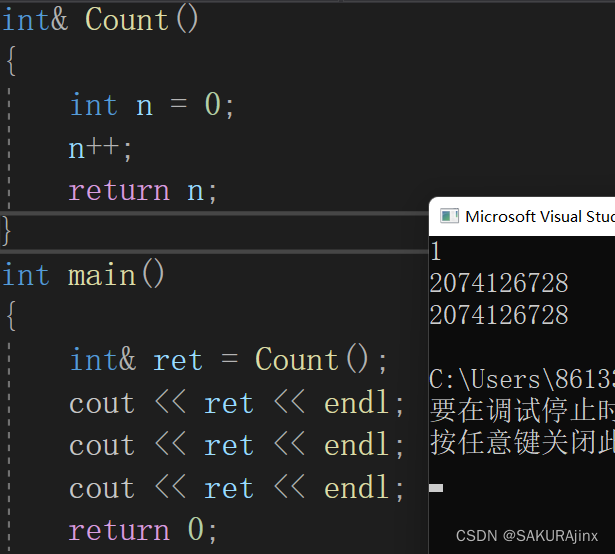
为什么第二三次打印会出现随机值呢?
结合上面所说的,Count栈帧销毁后,n也销毁了,ret是n的别名,会去n所在的地址拿值。
如果原本Count所在的位置没有被覆盖,那么原本n所在的位置也还是它原来的值1.
第二、三次打印,实际上cout也调用了函数,覆盖了原本Count栈帧的位置,所以ret此时取到的就是随机值。
结论:出了函数作用域,返回变量销毁了,不能引用返回,因为引用返回结果是未定义的。
出了函数作用域,返回变量存在,才能引用返回。
那么引用返回比传值返回有什么优势呢?
1、引用返回可以减少拷贝,提高效率(小的数据返回可能看不出,但是返回大的结构体等就很明显了)
2、引用返回可以改变函数返回值。
常引用
常引用是指用const修饰的引用。

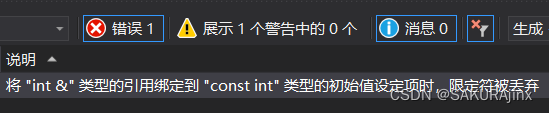
经const修饰的变量b不能直接引用,需要在前面加const。
这是权限大小问题。权限可以平移、可以缩小,但是不能放大。

const int& rra = a; rra加了限制不能++,但是a还是可以++的。
权限缩小 缩小的是自己得到的权限,而不是原本变量的权限。
那这里const修饰引用有什么作用呢?
int main()
{
int a = 0;
//权限平移
int& ra = a;
//权限缩小
const int& rra = a;
const int b = 1;
//权限平移
const int& rb = b;
//权限放大(不可以)
//int& rb = b;
a = b;
return 0;
}大家看个问题:a = b,改变a对b有没有影响?——没有,因为b是拷贝给a的;
int& ra = a; 改变ra对a有影响吗?——有,因为ra是a的别名,不是拷贝。
既然如此:
void func(int x)
{
}
int main()
{
int a = 0;
//权限平移
int& ra = a;
//权限缩小
const int& rra = a;
const int b = 1;
//权限平移
const int& rb = b;
//权限放大(不可以)
//int& rb = b;
func(a);
func(rra);
func(b);
return 0;
}这里调用func,都可以成功调用,因为x是a, rra, b的拷贝,修改x对实参没有影响。
但如果:
void func(int& x)
{
}如果x是引用,那么rra 和 b就不能调用了 。
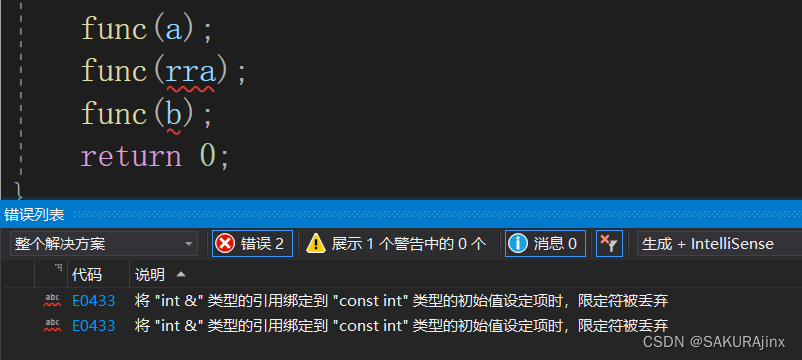
因为修改X就相当于修改了rra 和 b,将权限放大了,所以要在X前面加const修饰。
而我们使用引用作为参数时,一般都会加const修饰,不能修改参数,权限平移或权限缩小都是被接受的,总之不能权限放大。
有人会说,加const修饰就不能修改参数了,那要这个干什么?
在设计这个的时候,就是考虑到实际应用才设计的。const修饰的变量,正是不需要修改所以才const+引用避免误改,我们说引用是为了减少拷贝,提高效率的。
如果需要修改参数的场景,那不加const就行了,比如swap函数的使用。
再来看一个:
void func(const int& x = 1)
{
}
int main()
{
const int& a = 10;
return 0;
}引用是可以引用常量的,但需要加const修饰,同理函数中缺省参数也是可以引用常量的。

int& rb = b;是不可以的,但是int a = b; int a = (int)b; 是可以的。

实际上,相当于将double类型的b给临时变量,再将临时变量给a,强制类型转化也是一样。
临时变量具有常性,rb引用的是临时变量(double类型),所以不能直接引用,只能加const才可以。

同理:函数返回也是一样。
int func()
{
int n = 0;
n++;
return n;
}
int main()
{
const int& ret = func();
return 0;
}引用是否开辟空间,从语法的角度来说是不开辟空间的,而指针是存变量的地址,要开辟空间的。
但是从底层来说,两者都是开辟空间的。

观察引用和指针的反汇编代码,可以发现,两者的代码几乎一样,都要开辟空间。
从语法上说,ra是a的别名,不开辟空间;从底层来说,引用是指针来实现的。
引用和指针的区别:

其实引用还有很多小细节,篇幅原因就写到这里了,后续我会继续更新,将所有细节呈现给大家。














 2369
2369











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









