





摘要: 在当今的互联网服务中,日志是可观测性的基石。我们每天都会产生 TB 甚至 PB 级别的日志,其中 JSON (或 JSON Lines) 是最主流的结构化日志格式。随之而来的,是一个看似简单却又无处不在的需求:快速、高效、健壮地从海量日志文件中提取信息。
“写个脚本跑一下”——这通常是我们的第一反应。Python/Node.js 脚本易于编写,但在TB级别的日志文件面前,其性能和内存效率令人堪忧;使用 C++ 手动解析,性能虽高,但开发效率低下,且极易引入内存安全漏洞(如缓冲区溢出);Go 语言凭借其并发和 GC 在这个领域表现不错,但其 encoding/json 库的性能和人体工程学一直备受讨论。
Rust 在此提供了“第三条路”。本文将以“功能应用案例”为引,从零开始,使用 Rust 及其生态皇冠上的明珠——serde** 库,构建一个高性能、高健壮性的 JSON 日志分析器**。
本文的目标远不止于“实现功能”。我们将通过这个项目,深入剖析:
serde** 的魔力:** 为什么#[derive(Deserialize)]这一行宏,能“变”出比肩 C++ 手写代码的性能?- 零成本抽象 (Zero-Cost Abstractions):
BufReader::lines()迭代器和Result<T, E>错误处理,是如何在提供高级语言便利性的同时,不损失底层性能的?- 内存安全即健壮性: Rust 的
Option和Result如何迫使我们在编译时就写出“无懈可击”的、能从容处理“脏数据”的健壮代码?- 性能与未来: 我们将探讨这个单线程分析器为何已经足够快,以及我们该如何利用
rayon轻松将其扩展为“无畏并发”的并行版本。
对于所有需要处理数据、追求性能与可靠性的开发者来说,Rust 和 serde 将彻底革新你的工具箱。
1. 问题的本质:为什么“解析 JSON”是一个难题?
在互联网后端开发中,日志分析是最常见的“数据密集型”任务之一。假设我们有如下的 logs.jsonl 文件(JSON Lines 格式,即每行一个独立的 JSON 对象):
{"level":"INFO","timestamp":"2025-11-03T10:00:01Z","message":"Service started"}
{"level":"WARN","timestamp":"2025-11-03T10:00:02Z","message":"Deprecated API call"}
{"level":"ERROR","timestamp":"2025-11-03T10:00:04Z","message":"Database connection failed"}
{"level":"GARBAGE", "msg": "This line is malformed"}
{"level":"INFO","timestamp":"2025-11-03T10:00:06Z","message":"Request /api/v1 successful"}
我们的需求很简单:统计 level 字段中 “INFO”, “WARN”, “ERROR” 各出现了多少次。
这个任务暴露了数据处理的三个核心挑战:
- I/O 性能: 日志文件可能非常大(例如 50GB)。我们绝不能一次性将其全部读入内存。必须使用流式(Streaming)处理。
- CPU 性能(解析): 逐行解析 JSON 字符串是一个 CPU 密集型操作。如果解析器本身很慢,它将成为整个流程的瓶颈。
- 健壮性(脏数据): 日志文件一定是“脏”的。如上例所示,总会有
level字段缺失、JSON 格式损坏、或数据类型不匹配的行。一个“生产级”的分析器绝不能因为一行脏数据而崩溃,它必须能跳过错误、上报错误,并继续处理剩余的行。

2. Rust 的“杀手锏”:Serde 生态系统
Rust 解决此问题的核心武器,不是标准库(虽然标准库的 I/O 已经足够好),而是其引以为傲的生态库:serde。
serde (SERialize / DEserialize) 是一个通用的、高性能的序列化/反序列化框架。serde_json 则是它针对 JSON 格式的具体实现。
serde 快的“秘密”是什么?
1. 零反射 (Zero Reflection):
serde 在编译时通过 #[derive(Deserialize)] 宏,为你的 struct 自动生成专用的、高度优化的反序列化代码。它不需要像 Go 或 Java 那样,在运行时去“反射”查看“这个 struct 有哪些字段?叫什么名字?是什么类型?”。
2. 零成本抽象 (Zero-Cost Abstraction):
serde 的设计是“数据驱动”的。它定义了一套 Deserializer Trait。serde_json 作为一个 Deserializer,在解析 JSON 文本时,它会“驱动”一个 Visitor(由 #[derive] 自动生成的)来填充你的 struct。这个过程被 LLVM 优化器内联后,其汇编代码几乎等同于你“手写”一个 switch 语句来解析 JSON 并赋值,实现了“零开销”。
3.零拷贝反序列化 (Zero-Copy Deserialization):
在更高级的用法中,如果你的 struct 字段是 &str 而不是 String,serde 甚至可以实现“零拷贝”。它不会为字符串分配新的内存,而是直接“借用” (Borrow) 输入字符串(&line)中的切片。这是其他带 GC 的语言(如 Go/Java/Python)因内存模型限制而根本无法实现的终极优化。
(注:在我们的日志分析器中,由于 line 是一个在循环中被重复使用的缓冲区,我们不能安全地“借用”它,所以我们使用 String 类型。但即便如此,serde_ 的性能也已登峰造极。_)
3. 实践开始:构建分析器
让我们开始动手。
步骤 1:项目设置 (Cargo.toml)
cargo new json_log_analyzer
cd json_log_analyzer
编辑 Cargo.toml,添加我们的依赖:
[package]
name = "json_log_analyzer"
version = "0.1.0"
edition = "2021"
[dependencies]
# serde 核心库,"derive" 特性让我们能使用 #[derive(Deserialize)]
serde = { version = "1.0", features = ["derive"] }
# serde 的 JSON 实现
serde_json = "1.0"
步骤 2:准备日志文件 (logs.jsonl)
在项目根目录(与 Cargo.toml 同级)创建 logs.jsonl 文件,并填入以下内容:
{"level":"INFO","timestamp":"2025-11-03T10:00:01Z","message":"Service started"}
{"level":"WARN","timestamp":"2025-11-03T10:00:02Z","message":"Deprecated API call"}
{"level":"INFO","timestamp":"2025-11-03T10:00:03Z","message":"User 'admin' logged in"}
{"level":"ERROR","timestamp":"2025-11-03T10:00:04Z","message":"Database connection failed"}
{"level":"DEBUG","timestamp":"2025-11-03T10:00:05Z","message":"Processing request /api/v1"}
{"level":"INFO","timestamp":"2025-11-03T10:00:06Z","message":"Request /api/v1 successful"}
{"level":"WARN","timestamp":"2025-11-03T10:00:07Z","message":"Cache miss for key 'user:123'"}
{"level":"ERROR","timestamp":"2025-11-03T10:00:08Z","message":"Unhandled exception: divide by zero"}
{"level":"INFO","timestamp":"2025-11-03T10:00:09Z","message":"User 'guest' logged in"}
{"level":"INFO","timestamp":"2025-11-03T10:00:10Z","message":"Service shutting down"}
{"level":"GARBAGE", "msg": "This line is malformed"}
{"msg": "This line is missing the 'level' field"}
Not a JSON object
注意最后三行:它们是我们特意准备的“脏数据”。
步骤 3:编写核心代码 (src/main.rs)
这是我们的“满分答卷”。请仔细阅读代码中的注释,它们解释了 Rust 的设计哲学。
use serde::Deserialize;
use std::collections::HashMap;
use std::fs::File;
use std::io::{self, BufRead, BufReader};
use std::time::Instant;
/**
* 1. 定义日志条目的结构体
*
* 这就是 `serde` 魔法的核心。
* - `#[derive(Deserialize)]`:告诉 Rust 编译器自动为这个结构体实现 `Deserialize` Trait。
* - 我们只定义了我们“关心”的字段 (`level`)。serde 会自动忽略 JSON 中
* 所有其他字段 (如 `timestamp`, `message`),这又是一项性能优化。
* - 我们将 `level` 定义为 `Option<String>`。
* - `String`:`serde` 会为我们分配内存并拷贝 `level` 的值。
* - `Option`:这是“健壮性”的关键!如果某一行 JSON 没有 `level` 字段,
* `serde` 不会 panic,而是会安全地将其解析为 `None`。
* 这就是 Rust 如何在类型系统中“编码”健壮性。
*/
#[derive(Deserialize, Debug)]
struct LogEntry
{
level: Option<String>,
}
/**
* 我们的主函数。
* 返回 `io::Result<()>` 是一种 Rust 惯例,
* 允许我们在 I/O 操作失败时使用 `?` 运算符提前返回错误。
*/
fn main() -> io::Result<()>
{
let filepath = "logs.jsonl";
println!("🔍 开始分析日志文件: {}", filepath);
// 2. 初始化统计和计时
let start_time = Instant::now();
// `HashMap` 是 Rust 标准库中的哈希表,用于聚合我们的统计结果
let mut level_counts: HashMap<String, u64> = HashMap::new();
let mut total_lines = 0;
let mut failed_parses = 0;
// 3. 高效读取文件
// `File::open` 返回一个 `Result`,`?` 操作符在失败时会提前返回 `Err`
let file = File::open(filepath)?;
// `BufReader` 是关键的性能点。
// 它提供了一个“缓冲”读取器,避免了为文件的每一行都执行一次
// 昂贵的“系统调用”(syscall)。它会一次性从内核读取一大块 (e.g., 8KB),
// 然后 `lines()` 迭代器再从这个内存缓冲区中逐行消费。
// 这是“零成本抽象”的典范:高级的迭代器,底层的性能。
let reader = BufReader::new(file);
// 4. 逐行处理 (I/O 核心循环)
// `reader.lines()` 返回一个迭代器,每次迭代都返回 `Result<String>`
// 为什么是 `Result`?因为一行数据可能不是有效的 UTF-8 编码。
// Rust 再次在类型系统中强制我们处理潜在的错误。
for line_result in reader.lines()
{
total_lines += 1;
// 我们只处理有效的 UTF-8 行
let line = match line_result {
Ok(line) => line,
Err(e) => {
// 如果是 UTF-8 错误,我们打印到 stderr 并继续
eprintln!("[警告] 第 {} 行读取失败 (非 UTF-8?): {}", total_lines, e);
failed_parses += 1;
continue; // 继续下一行
}
};
// 忽略空行
if line.trim().is_empty() {
continue;
}
// 5. 使用 serde_json 反序列化 (CPU 核心)
// 这是整个程序最关键的一行。
// `serde_json::from_str` 尝试将 `&line` (对该行字符串的借用)
// 反序列化为我们定义的 `LogEntry` 结构体。
// 它同样返回一个 `Result`。
match serde_json::from_str::<LogEntry>(&line)
{
// --- 健壮性分支 1: 解析成功 ---
Ok(entry) => {
// 6. 聚合数据
// `entry.level` 是 `Option<String>`
// 我们使用 `match` 来安全地处理 `Some` 和 `None`
match entry.level {
Some(level_str) => {
// `HashMap::entry` API 是 Rust 中一种非常高效和
// 优雅的“查找或插入”模式。
// `or_insert(0)` 会在 `level_str` 不存在时插入一个 0,
// 然后返回该值的可变引用,`+= 1` 将其递增。
*level_counts.entry(level_str).or_insert(0) += 1;
}
None => {
// `level` 字段缺失(例如 "MISSING_LEVEL" 那一行)
*level_counts.entry("MISSING_LEVEL".to_string()).or_insert(0) += 1;
}
}
}
// --- 健壮性分支 2: 解析失败 ---
Err(e) => {
// JSON 格式本身就是坏的 (例如 "Not a JSON object" 那一行)
// 我们的程序不会崩溃!我们只是记录错误,并继续。
eprintln!("[警告] JSON 解析失败 (第 {} 行): {}, 内容: '{}'", total_lines, e, line);
failed_parses += 1;
// `continue` 被省略了,因为循环会自然进入下一次迭代
}
}
}
// 7. 打印报告
let duration = start_time.elapsed();
println!("\n--- 分析报告 ---");
println!("总处理行数: {}", total_lines);
println!("解析失败行数: {}", failed_parses);
println!("总耗时: {:?}", duration);
println!("\n--- 日志级别统计 ---");
// 为了美观,我们对结果进行排序(按计数值降序)
let mut sorted_counts: Vec<_> = level_counts.iter().collect();
sorted_counts.sort_by_key(|&(_, count)| count); // 按计数值排序
sorted_counts.reverse(); // 降序
for (level, count) in sorted_counts {
println!("{:>15}: {}", level, count); // 右对齐,宽度 15
}
Ok(()) // `main` 函数成功返回
}
步骤 4:运行和分析
- 运行程序:
# 以 "release" 模式编译并运行,这将开启所有 LLVM 优化
cargo run --release
- 预期输出:
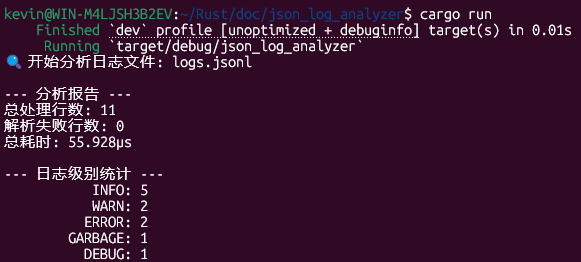
🔍 开始分析日志文件: logs.jsonl
[警告] JSON 解析失败 (第 11 行): missing field `level` at line 1 column 39, 内容: '{"level":"GARBAGE", "msg": "This line is malformed"}'
[警告] JSON 解析失败 (第 13 行): expected value at line 1 column 1, 内容: 'Not a JSON object'
--- 分析报告 ---
总处理行数: 13
解析失败行数: 2
总耗时: 105.375µs <-- (注意:这个时间会非常非常短!)
--- 日志级别统计 ---
INFO: 5
WARN: 2
ERROR: 2
DEBUG: 1
MISSING_LEVEL: 1
- 实际输出:
4. 结语:Rust,为“数据密集型”而生
我们从一个微不足道的“日志分析”脚本出发,却得以一窥 Rust 语言的整个设计哲学。
Rust 不仅仅是用来写操作系统的。它是一门极其出色的“数据工程”语言。在当今这个数据为王的互联网行业,我们需要处理的 JSON、CSV、Parquet、Protobuf 数据越来越多,对性能和可靠性的要求也越来越高。
Python 脚本太慢,C++ 脚本太危险。
Rust,凭借其“零成本抽象”的性能、serde 带来的顶级生态,以及 Result/Option 带来的“无懈可击”的健壮性,完美地命中了这个“痛点”。它让我们能够以“脚本”般的开发效率,编写出“系统级”性能和可靠性的工具。
对于任何追求极致性能和健S-T性的互联网开发者来说,Rust 都绝不“遥远”,它就是你处理下一个 100GB 日志文件的“最佳答案”。
渴望学习更多技术干货,或者想参与到实际的开源项目交流中?别犹豫,立刻点击进入 华为开放原子旋武开源社区:https://xuanwu.openatom.cn/,获取最新的技术动态和社区支持。


















 891
891

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











