





前言:代码写到深夜,谁来陪你?
作为一个程序员,我不知道你们有没有这种时刻:凌晨两点,盯着屏幕上那段死活跑不通的递归逻辑,周围安静得只剩下风扇的嗡嗡声。这时候,你打开 ChatGPT,把代码扔进去,它秒回一堆建议。
它很强,效率极高,但它……太冷了。
对着那个闪烁的光标,我总觉得自己在跟一个无底洞对话。虽然圈子里流行“橡皮鸭调试法”——对着桌上的玩具鸭子讲代码思路,讲着讲着自己就悟了——但那毕竟是死物。
我就在想:现在的 LLM 智商已经够了,缺的其实是“肉体”。 如果把 GPT 的脑子,接在一个能看、能听、会点头、会皱眉的“人”身上,这只“橡皮鸭”是不是就能活过来?
我偶然了解到了魔珐星云这个平台,并申请了 Xingyun SDK 的Key。据说这东西能搞定“具身智能”。抱着试一试(甚至有点想找茬)的心态,我花了两天时间,用 Vue3 + 他们的 SDK,搓了一个**“会说话、会用眼神鄙视我 Bug”**的 3D 数字人编程助手。
这篇文章不是软广,而是记录我如何用 200 行核心代码,把一个大模型变成“大活人”的全过程,以及这里面那些让我起鸡皮疙瘩的技术细节。
文章目录
第一阶段:不仅是“看见”,而是“感受到”
1. 为什么是星云?

起初我也看过国外的有些方案(比如 D-ID),或者国内的一些数字人 SaaS。大多数给我的感觉是:视频播放器。
你发一段字,它在云端生成一段 MP4 视频,然后推流给你。
这就带来三个致命问题:
- 贵:云端一直在跑 GPU 渲染,这成本谁顶得住?
- 慢:生成视频要时间,传输要带宽,延迟起码 3-5 秒,根本没法像真人一样插嘴聊天。
- 假:只是嘴动,眼神和肢体语言跟不上语义。
星云吸引我的点在于它的“端侧渲染”架构。简单说,它不传视频,只传参数(骨骼数据、表情系数)。渲染的工作交给我的浏览器(WebGL)来做。
2. 初始化:极客风的开局
注册过程略过不表,拿到 AppID 和 Secret 后,我建了个 Vue3 + TS 的项目。(创建一个应用后即可获取AppID 和 Secret)
官方文档:https://xingyun3d.com?utm_campaign=daren&utm_source=DevKevin
【魔珐星云】数字人实时驱动Demo:https://rsjqcmnt5p.feishu.cn/wiki/U1TkwoTj5iP5gDkfXbwcUFsYngi
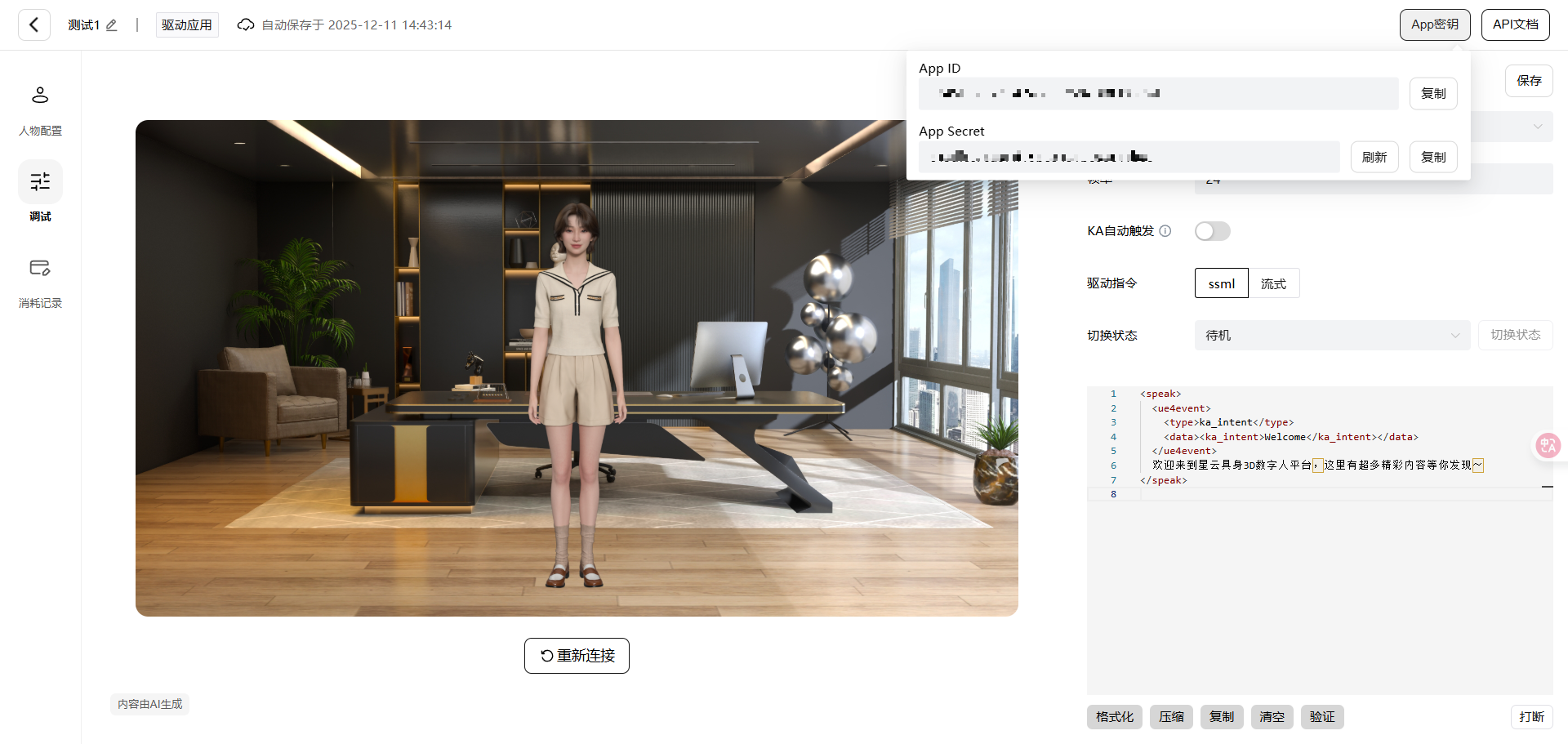
引入 SDK 的过程异常丝滑。有些厂家的 SDK 恨不得把全家桶都塞给你,但星云这个很克制:
import { XmovAvatar } from '@xmov/avatar-sdk';
// 初始化配置:简单得不像实力派
const avatar = new XmovAvatar({
containerId: '#avatar-container', // 挂载点
appId: import.meta.env.VITE_APP_ID,
appSecret: import.meta.env.VITE_APP_SECRET,
// 核心:状态机监听
// idle(发呆) -> listen(倾听) -> think(思考) -> speak(表达)
onStateChange: (state) => {
updateUIStatus(state); // 更新我界面上的状态条
},
// 甚至能监听字幕事件
onWidgetEvent: (event) => {
if (event.type === 'subtitle_on') {
renderSubtitle(event.text);
}
}
});
// 启动!
await avatar.init();
就这几行代码,页面上那个 3D 小姐姐就加载出来了。材质极其细腻,皮肤的光泽度甚至会随着环境光变化。
第二阶段:注入灵魂(核心开发)
光有皮囊不行,得有脑子。我接的是智谱 GLM-4-Flash 的 API(便宜大碗)。
1. 橡皮鸭的“人设”
我不想让它直接给我写代码,那样我永远学不会。我要的是苏格拉底。
这是我写的 System Prompt:
“你是一只具身智能编程橡皮鸭。
你的目标不是直接给出代码,而是通过苏格拉底式提问引导用户发现逻辑漏洞。
你的语气要像一个耐心的资深架构师。
当用户思路正确时,给予简短的肯定;当用户逻辑混乱时,用反问句引导。”
2. 攻克“实时对话”的难点
这是整个项目最硬核的部分。
如果我等 LLM 把几百字的回复全生成完,再发给数字人,那我就得盯着屏幕干等 10 秒。这不叫对话,这叫“听报告”。
星云支持流式驱动(Streaming)。这意味着:LLM 蹦出第一个字,数字人就能开始准备口型了。
但这中间有个坑:断句。
LLM 的流是碎片的,可能一次只返回“我”、“觉得”、“这个”。如果直接喂给 SDK,数字人说话就会像机关枪卡壳。
我写了一段缓冲逻辑:
// 一个简易的流式处理队列
async function handleLLMStream(stream: AsyncIterable<string>) {
let buffer = '';
let isFirstSentence = true;
// 1. 先让数字人进入思考状态(这一步极其重要,增加真实感)
avatar.think();
for await (const chunk of stream) {
buffer += chunk;
// 用正则智能断句:遇到逗号、句号、感叹号就切分
const sentenceMatch = buffer.match(/.*?[,。!?,.!?]/);
if (sentenceMatch) {
const sentence = sentenceMatch[0];
buffer = buffer.slice(sentence.length); // 清理缓存
// 2. 驱动数字人说话
// speak(text, is_start, is_end)
// 这个API设计很有意思,is_start 告诉引擎这是新的一段话,重置情感基调
avatar.speak(sentence, isFirstSentence, false);
isFirstSentence = false;
}
}
// 处理剩下的尾巴
if (buffer) {
avatar.speak(buffer, false, true);
}
}
第三阶段:见证奇迹的时刻
代码写完,F5 刷新。
我对着麦克风说:“我想实现一个LRU缓存了。”
接下来发生的一幕,让我真正理解了什么是“具身智能”:
- ****数字人立刻停止了原本的闲晃动作,头微微侧向镜头,眼神聚焦。(Listen 状态)
- 她没有马上开口,仿佛在检索知识库。(Think 状态)
- 她开口了,声音不是那种机械的 TTS,而是带着一种关切的语调:
“LRU缓存,是按照访问顺序来淘汰数据的吗?
_ 你考虑过如何实现一个简单的访问顺序记录机制吗?”_

重点来了!当她说到“方便地在”时,她的手做了一个摆开的手势,眼神从思考状转为直视我,仿佛在强调重点。
这是自己根据语义生成的。它理解了这句话里的强调语气,自动匹配了手势和微表情。
以前用 ChatGPT,是“我问你答”。
现在,是“我们在交流”。那种眼神的接触,虽然隔着屏幕,却能产生一种微妙的被关注感。
星云凭什么打破“不可能三角”?
做过实时音视频开发的都知道,数字人领域有个“不可能三角”:高质量、低延迟、低成本,通常只能三选二。
- 要高质量(电影级模型),就得云端渲染,成本高、延迟大。
- 要低成本端侧跑,通常只能做成 2D 纸片人或者低模卡通人。
星云是怎么打破这个三角的?通过这次开发,我摸清了它的底牌:
- 参数流 vs 视频流:
它传输的数据量极小。一分钟的视频流可能要几百兆,而一分钟的动作参数流可能只有几百 K。这直接把网络延迟几乎抹平了。- 端侧渲染引擎的黑科技:
我特意看了下任务管理器。我的电脑只有集成显卡(Intel UHD),在 Chrome 里跑这个 3D 页面,CPU 占用率居然只有 15%-20%,内存占用也很稳。
官方宣称连 RK3566 这种百元级的安卓板子都能跑,这意味着它不仅仅能活在电脑里,以后什么智能音箱、车机屏幕、甚至商场的导购屏,都能塞进一个“人”。- 语义与动作的对齐:
这是最难的。传统的方案是 TTS 归 TTS,动画归动画,经常出现“嘴在动,脸很僵”的情况。星云是同一个大模型同时输出音频和表情参数,所以那种**“笑得恰到好处”、“眉头皱得合情合理”**的自然感,是目前市面上少有的。
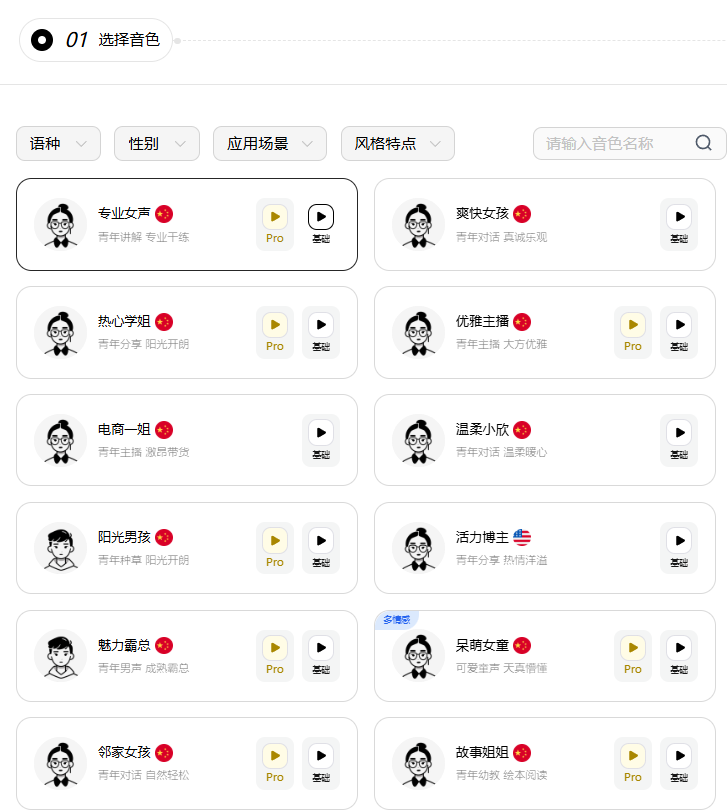
该平台有个语音合成功能,看上去描述可能感觉很普通,和其他平台的那些音色看着很像。**BUT!PlEASE BELIEVE ME!!**我第一次测试音色的时候确实被惊艳到了。也有一个原因是:全靠同行衬托~
用过小说软件的都知道,如果点那个听小说的话,如果那个小说没有真人配音的,就会有很僵硬的机器音来给你讲故事,用过的都说孬 ( bushi
但是但是,这个平台的语音转化非常逼真,语气也可以准确的识别出来,我放个链接在下面,推荐直接试听电商一姐的,一秒转粉了兄弟们~
跑题了一些,下面继续回归这个Demo的测试过程。
魔珐星云具身智能3D数字人开放平台 - 全球领先的3D具身智能体基础设施
还有哪些坑?(开发者视角的真实反馈)
吹了半天,作为开发者也要客观吐槽一下目前的不足,方便大家避坑:
- 首次加载的“真空期”:
因为是端侧渲染,第一次打开必须下载 3D 模型资产(大概十几兆)。如果网速慢,用户会看到几秒钟的空白。
解决建议:自己做一个好看的 Loading 遮罩,或者利用 SDK 的预加载功能提前把资源拖下来。 - 打断逻辑需要精细控制:
真人的对话是可以随时插嘴的。如果数字人还在滔滔不绝,用户又说话了,必须立刻调用avatar.think()强制它闭嘴。这块逻辑需要结合前端的 VAD(语音活动检测)来做,稍微有点复杂,但调好了体验极佳。 - 移动端的适配:
Web 端目前很完美,但如果想集成到自己的原生 App 里,虽然有 Android SDK,但 iOS 还没完全开放(据说快了)。目前在手机浏览器里跑 Web 版,性能压力比 PC 大一些,手机会微微发热。
不只是个玩具
做完这个项目,我把它挂在我的副屏上。写代码累了,我就跟她聊两句;思路卡住了,我就对着她讲一遍逻辑。
慢慢地,我发现自己不再把它当成一个“程序接口”,而是某种程度上的“伙伴”。
具身智能(Embodied AI) 之前对我来说只是个学术名词,现在我才理解。
当 AI 拥有了身体,它能承载的信息量就从“文本”变成了“情感”。
- 未来的在线教育,老师不再是录播课里那个永远在笑的视频,而是盯着你看、发现你走神会敲黑板的数字人。
- 未来的老人陪伴,不再是冷冰冰的智能音箱,而是能坐在屏幕里陪爷爷奶奶唠嗑、会跟着笑会跟着叹气的虚拟儿女。
- 未来的游戏 NPC,不再是只会念台词的木头人,而是每个人都有独立性格、能和你真正产生羁绊的生灵。
而对于我们开发者来说,星云这样的平台,就像是当年的 iOS SDK。它把底层的渲染、驱动、多模态全封装好了,让我们能用 200 行代码,去探索这个新世界的可能性。
建议所有对 AI 感兴趣的兄弟,都去申请个号玩玩。哪怕不为了做产品,光是看着自己写的代码变成一个“人”看着你,那种成就感,真的不一样。
项目资源与参考:
- 魔珐星云官网:https://xingyun3d.com?utm_campaign=daren&utm_source=DevKevin (注册就有免费额度,够玩很久了)
- 我的 Demo 源码已开源至github:https://github.com/ruijayfeng/XingYunSDKUseCase



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











