







学习《scikit-learn机器学习》时的一些实践。
kNN分类
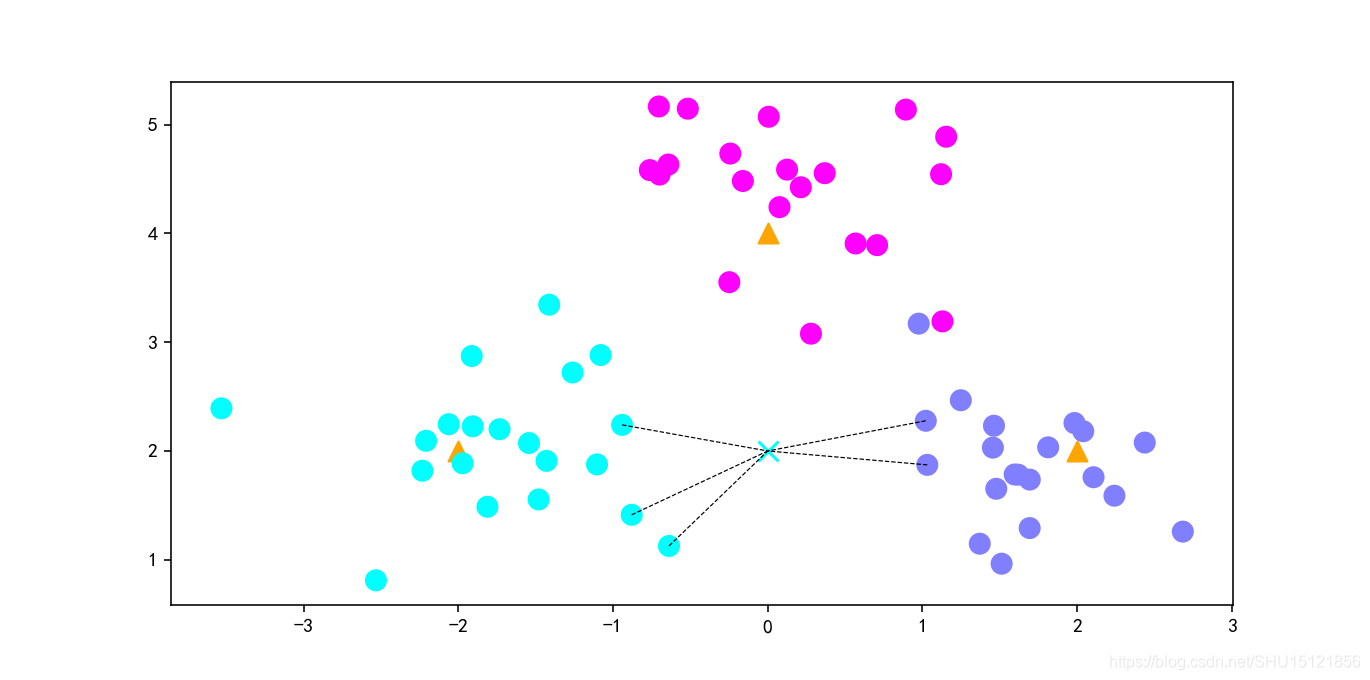
在三个点周围生成聚类样本,然后做的kNN分类。
这种把标准差取得好(不要太小),得到的就不一定是线性可分的数据了。比如图上右侧有个玫红点和蓝点交错。
from sklearn.datasets.samples_generator import make_blobs # 用于生成聚类样本
from matplotlib import pyplot as plt
import numpy as np
from sklearn.neighbors import KNeighborsClassifier # kNN分类
# 使matplotlib正常显示负号
plt.rcParams['axes.unicode_minus'] = False
'''
kNN分类,特征数=2(x轴坐标,y轴坐标),类别数目=3
'''
# 要生成的样本中心点
centers = [[-2, 2], [2, 2], [0, 4]]
# 围绕centers列表里提供的中心点坐标,以每类标准差0.6(可以传入列表指定不同方差),按随机种子0生成60个聚类样本
# 这里生成的X是样本的坐标,shape=(60,2);y是样本的类别标记,shape=(60,),因为是三类,其值只取0,1,2表示所属类别
X, y = make_blobs(n_samples=60, centers=centers, random_state=0, cluster_std=0.60)
# 训练(其实就是记下来)
k = 5
clf = KNeighborsClassifier(n_neighbors=k)
clf.fit(X, y)
# 预测一个测试样本点,这里要转换成"样本数*特征数"shape的numpy数组
X_sample = np.array([0, 2]).reshape(-1, 2)
y_sample = clf.predict(X_sample)
print("预测样本点{}属于{}类".format(X_sample, y_sample))
# 看看预测它用到的最近的k个点
neighbors = clf.kneighbors(X_sample, return_distance=False)
print("它最近的{}个点在训练样本X中的索引是{}".format(k, neighbors))
# 绘制数据点
plt.figure(figsize=(16, 10), dpi=144)
c = np.array(centers)
plt.scatter(c[:, 0], c[:, 1], s=100, marker='^', c='orange') # 中心点
plt.scatter(X[:, 0], X[:, 1], c=y, s=100, cmap='cool') # 生成的聚类样本,这里用类别号当颜色号
plt.scatter(X_sample[:, 0], X_sample[:, 1], marker='x', c=y_sample, s=100, cmap='cool') # 预测的样本
# 绘制最近的k个点到预测样本的连线
for i in neighbors[0]: # 对于每个索引值i,表示它是X中行号为i的样本
# 每次取k个最近邻点中的一个,和测试样本点放在一组里画线,就画出了k条从紧邻点到测试样本点的连线
plt.plot([X[i, 0], X_sample[0, 0]], [X[i, 1], X_sample[0, 1]], 'k--', linewidth=0.6)
plt.show()
运行结果:
预测样本点[[0 2]]属于[0]类
它最近的5个点在训练样本X中的索引是[[16 20 48 6 23]]
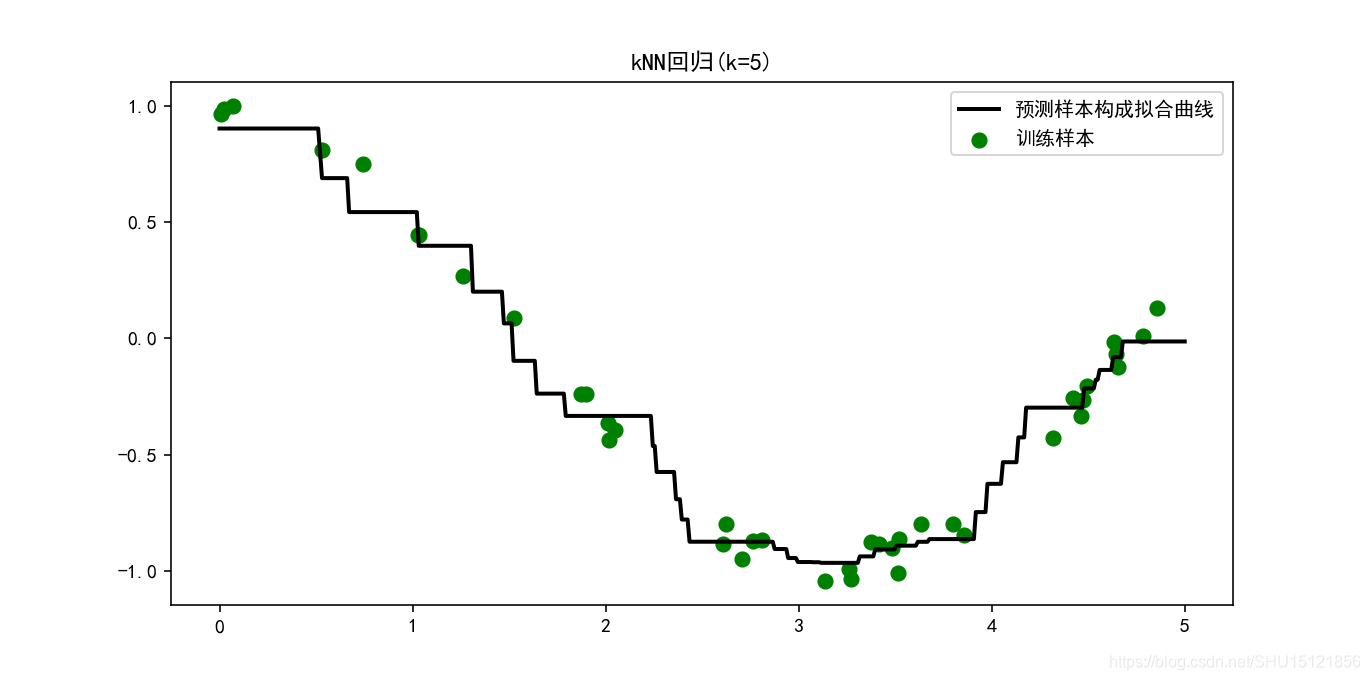
kNN回归
这个和前面那个分类问题不一样,这个特征就是一维的,那就很容易在这个维度上采样,然后用kNN预测其输出值,采样够密就得到了回归曲线。
这和之前上模式识别课的时候也做过的绘制分类面不一样,不仅在于那个是在一个平面上采样,然后用kNN做预测,还在于那个本质就是一个分类问题,得到的都是"点属于哪一类",然后最后很多很多点就绘制出了类的形状,最后分类线是挤出来的。而这个是去预测取值(具体怎么做的还不清楚),最后直接得到"线"的。
import numpy as np
from sklearn.neighbors import KNeighborsRegressor
from matplotlib import pyplot as plt
# 使matplotlib正常显示负号
plt.rcParams['axes.unicode_minus'] = False
'''
kNN回归,特征数=1(x轴坐标),对每个x可以预测一个y值
'''
n_dots = 40
# 生成5*[0,1)之间的数据在数组中,shape=(n_dots,1)
X = 5 * np.random.rand(n_dots, 1)
# ravel()的作用和flatten一样,只是flatten()重新拷贝一份,但ravel()返回视图,操作ravel()后的会影响原始的
# np.cos(X).shape=(n_dots,1)和X一样;而np.cos(X).ravel().shape=(n_dots,)即是摊平以后的了
y = np.cos(X).ravel()
# 添加正负0.1范围内的噪声
y += 0.2 * np.random.rand(n_dots) - 0.1
# 训练回归模型
k = 5
knn = KNeighborsRegressor(k)
knn.fit(X, y)
print(knn.score(X, y)) # 得分0.98..,低的时候只有0.78..
# 生成足够密集的点,作为回归用的样本
# 这里[:, np.newaxis]表示为其添加一个维度,使其从shape=(500,)变成shape=(500,1)
T = np.linspace(0, 5, 500)[:, np.newaxis]
# 预测标签y的值,这里shape=(500,)
y_pred = knn.predict(T)
# 这些预测点构成拟合曲线
plt.figure(figsize=(16, 10), dpi=144)
plt.scatter(X, y, c='g', label="训练样本", s=50) # s是点的大小
plt.plot(T, y_pred, c='k', label="预测样本构成拟合曲线", lw=2) # lw就是linewidth,线宽
plt.axis("tight") # 自动调整坐标轴使其能完整显示所有的数据
plt.title("kNN回归(k=%i)" % k)
plt.legend(loc="best") # 自动选择最合适的位置设置图例
plt.show()
运行结果:
0.9824227320396742
在糖尿病数据集上的表现
数据可以在kaggle上观察和下载。这个例子更多的是在学习作者解决ML问题的思路,从观察数据到观察模型的表现,模型的选择,可视化一下去判断一下模型的问题,这里是因为kNN模型复杂度太低导致欠拟合。
读取数据,建立模型
注意下带中文目录时Pandas的读取方式。
import pandas as pd
from matplotlib import pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier, RadiusNeighborsClassifier # kNN和半径kNN
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import ShuffleSplit
from z3.learning_curve import plot_learning_curve # 上节实践的绘制学习曲线
from sklearn.feature_selection import SelectKBest # 特征选择
'''
kNN和RN预测印第安人糖尿病
'''
BASE_DIR = "E:/WorkSpace/ReadingNotes/scikit-learn机器学习/data/"
# 读取数据,路径中有中文的时候要用open打开再给pandas读取
with open(BASE_DIR + "z4/diabetes.csv") as f:
df = pd.read_csv(f, header=0) # shape=(768, 9),其中前8个是特征,最后一列是标签
# 分离特征(前8列)和标签(第9列)
X = df.iloc[:, 0:8]
y = df.iloc[:, 8]
# 模型列表,里面存("模型名称",模型对象)
models = []
k = 2
# 普通kNN模型
models.append(("kNN", KNeighborsClassifier(n_neighbors=k)))
# 带权重的kNN:距离作为权重,距离越近的话语权越重
models.append(("带权重的kNN", KNeighborsClassifier(n_neighbors=k, weights="distance")))
# RN(这里指基于半径的邻居算法)
models.append(("半径kNN", RadiusNeighborsClassifier(n_neighbors=k, radius=500.0)))
比较三种模型(一次划分)
print("-" * 20 + "一次划分和训练" + "-" * 20)
# 分离训练集和测试集:拿出其中20%的样本作为测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# 训练三个模型,计算在测试集上的score
for name, model in models:
model.fit(X_train, y_train)
print(name, ":", model.score(X_test, y_test))
运行结果:
--------------------一次划分和训练--------------------
kNN : 0.6623376623376623
带权重的kNN : 0.6103896103896104
半径kNN : 0.6493506493506493
比较三种模型(K折交叉验证)
这种方式能较好消除随机划分带来的影响。
print("-" * 20 + "多次划分和训练,取平均" + "-" * 20)
# K折交叉验证对象,这里表示划分10次(K=10)
kfold = KFold(n_splits=10)
# 对于每个模型
for name, model in models:
# 用K折交叉验证的方式对样本集做划分,并训练得到K个score
scores = cross_val_score(model, X, y, cv=kfold)
print(name, ":", scores.mean()) # 取平均
运行结果:
--------------------多次划分和训练,取平均--------------------
kNN : 0.7147641831852358
带权重的kNN : 0.6770505809979495
半径kNN : 0.6497265892002735
传统的kNN表现更好,所以选用它。
训练模型,观察score和学习曲线
# 训练
knn = KNeighborsClassifier(n_neighbors=2)
knn.fit(X_train, y_train)
# 查看在训练集和测试集上的score
train_score = knn.score(X_train, y_train) # 0.8420195439739414
test_score = knn.score(X_test, y_test) # 0.6753246753246753
print("训练集score:{},测试集score:{}".format(train_score, test_score))
# 绘制学习曲线
knn = KNeighborsClassifier(n_neighbors=2)
cv = ShuffleSplit(n_splits=10, test_size=0.2, random_state=0) # 划分10份,测试集占20%
plt.figure(figsize=(10, 6), dpi=200)
# 这里要把函数里面最后一句return plt打开,全局的多余代码注释掉
plt = plot_learning_curve(knn, "kNN(k=2)学习曲线", X, y, ylim=(0.0, 1.01), cv=cv)
plt.show()
运行结果:
训练集score:0.8485342019543974,测试集score:0.6623376623376623
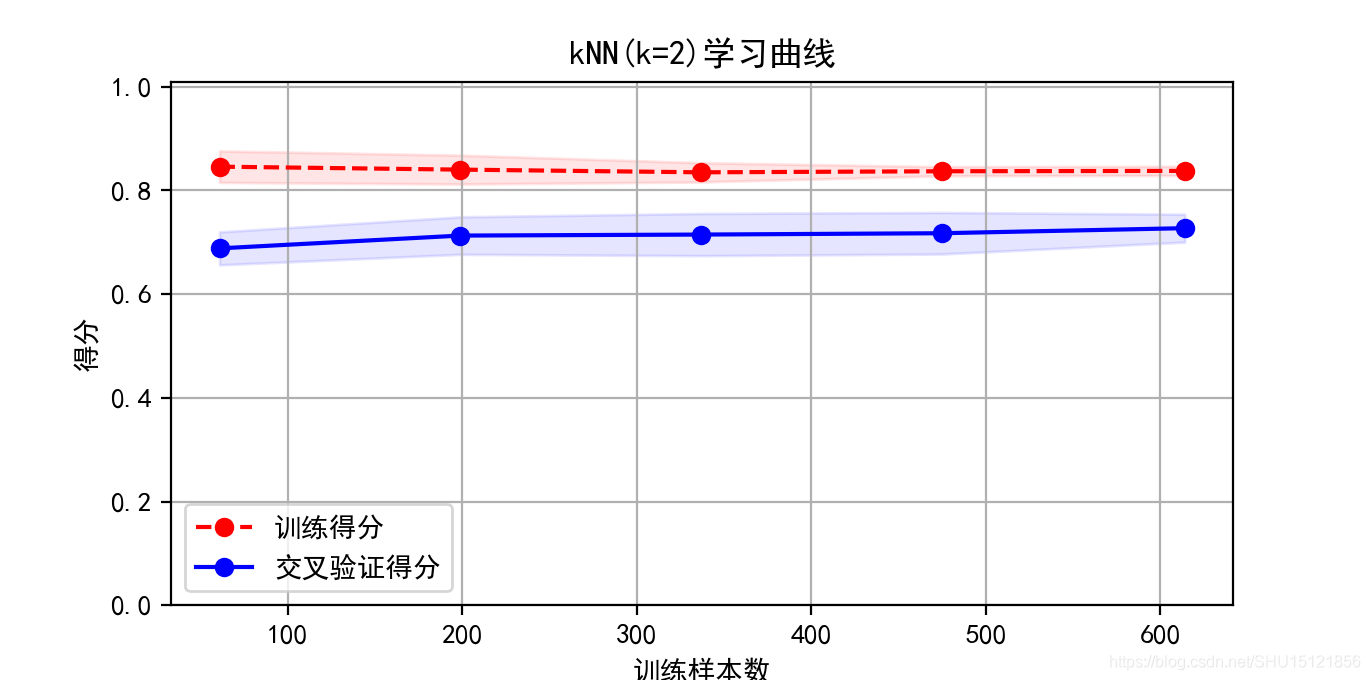
训练集和测试集的表现都不佳,可以认为是欠拟合了,但两条曲线相隔距离也比较大,书上说这种现象就是样本数量不够导致的。
特征选择,再比较三种模型(K折交叉验证)
这里只使用两个特征的时候,后面两种模型的score反而高了,它们的复杂度比普通kNN高。特别是RN在维度高的时候似乎反倒不奏效。
# 特征选择
selector = SelectKBest(k=2) # 只选择其中两个和输出相关性最大的
X_new = selector.fit_transform(X, y) # 这里会寻找和y相关性最大的X中的特征,提取相应列的数据
# 如果只使用这两个相关性最大的特征,比较前述的三种模型平均score
print("-" * 20 + "只使用两个相关性最大的特征" + "-" * 20)
for name, model in models:
scores = cross_val_score(model, X_new, y, cv=kfold)
print(name, ":", scores.mean())
运行结果:
--------------------只使用两个相关性最大的特征--------------------
kNN : 0.725205058099795
带权重的kNN : 0.6900375939849623
半径kNN : 0.6510252904989747
数据可视化
通过特征选择就只剩两个特征了,对于离散的分类问题可以可视化到一个平面上了。
# 观察数据的分布情况,只使用刚刚提取的两个特征,这样就可以可视化在平面上
plt.figure(figsize=(10, 6), dpi=200)
plt.xlabel("血糖浓度")
plt.ylabel("BMI指数")
# 分别绘制阴性样本(y=0)和阳性样本(y=1)
# 数组和数值的比较运算可以返回每个数值进行比较运算的True/False序列
# 然后这里是投给X做布尔索引,也就返回了相应的样本数据
plt.scatter(X_new[y == 0][:, 0], X_new[y == 0][:, 1], c='r', s=20, marker='o')
plt.scatter(X_new[y == 1][:, 0], X_new[y == 1][:, 1], c='b', s=20, marker='^')
plt.show()
运行结果:
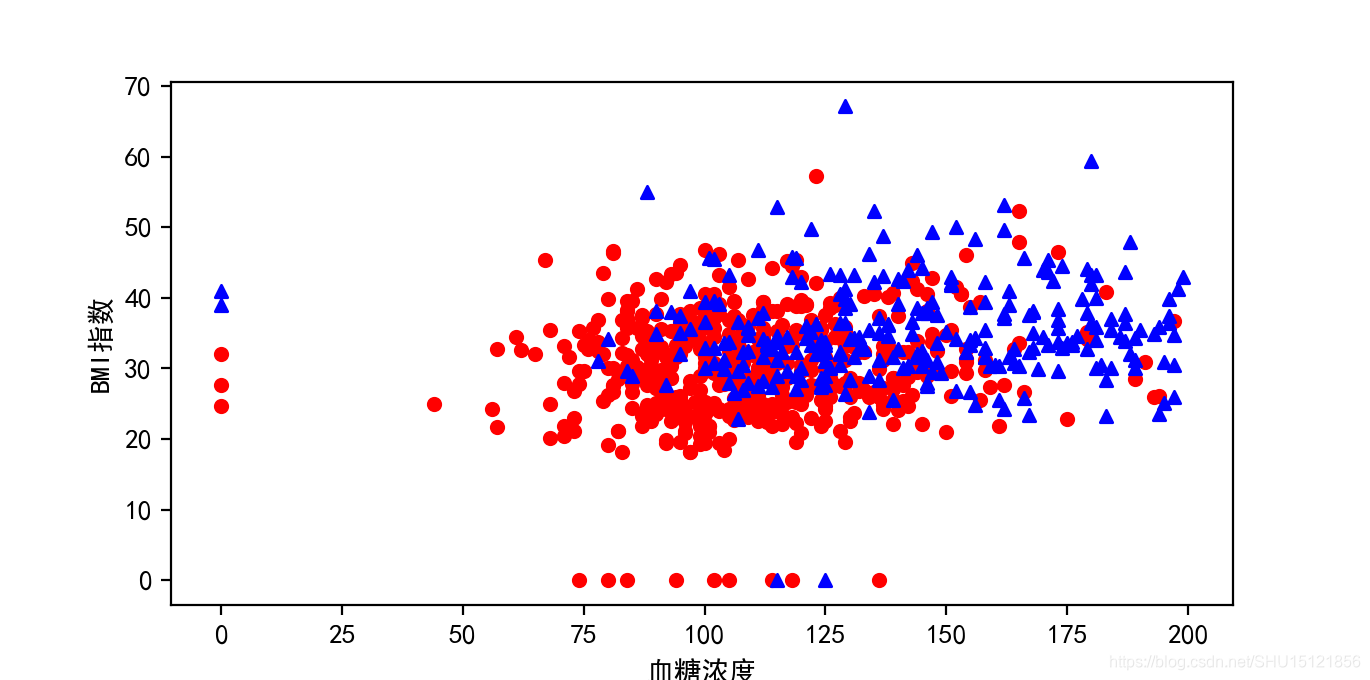
显然在这样的维度上这两类数据很难区分得开。














 2287
2287











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









