







其它机器学习、深度学习算法的全面系统讲解可以阅读《机器学习-原理、算法与应用》,清华大学出版社,雷明著,由SIGAI公众号作者倾力打造。
原创声明:本文为 SIGAI 原创文章,仅供个人学习使用,未经允许,不能用于商业目的。
我们在网上购买水果的时候经常会看到同一种水果会标有几种规格对应不同价格进行售卖,水果分级售卖已经是电商中常见的做法,那么水果分级具体是怎么操作的呢?一种简单的做法是根据水果果径的大小进行划分。今年老李家苹果丰收了,为了能卖个好价钱,老王打算按照果径对苹果进行分级。想法是很好的,但是面对成千上万的苹果这可愁坏了老李。老李的儿子小李是计算机系毕业的,他知道这件事后设计了一个算法,按照老李的要求根据果径大小定义了5个等级
70mm左右(<72.5mm)
75mm左右(>=72.5mm&&<77.5mm)
80mm左右(>=77.5mm&&<82.5mm)
85mm左右(>=82.5mm&&<87.5mm)
90mm左右(>=87.5mm)
如下图:

当一个未分级的苹果拿到后可以首先将这个苹果的果径测量出来,然后再和这5个等级的苹果进行对照,假如未分级苹果的果径是82mm则划分为第三个等级,如果是83mm则划分为第二个等级,以此类推。基于这个原则小李发明了一个分级装置,见下图,大大提高了工作效率,很快将老李的问题解决了。

老李的问题是一个经典的最近邻模板匹配,根据一个已知类别参考模板对未分类的数据进行划分,小李选择的每个类的模板数是一,现实生活中的问题往往会复杂很多,可能需要多个参考模板进行综合决策,当选定的模板数为k的时候就是k近邻算法的思想了,最近邻算法是k近邻算法k=1时的一种特殊情况。
k近邻算法简称kNN算法,由Thomas等人在1967年提出[1]。它基于以下思想:要确定一个样本的类别,可以计算它与所有训练样本的距离,然后找出和该样本最接近的k个样本,统计这些样本的类别进行投票,票数最多的那个类就是分类结果。因为直接比较样本和训练样本的距离,kNN算法也被称为基于实例的算法。
基本概念
确定一个样本所属类别的一种最简单的方法是直接比较它和所有训练样本的相似度,然后将其归类的最相似的样本所属的那个类,这是一种模板匹配的思想。下图6.1是使用k近邻思想进行分类的一个例子:
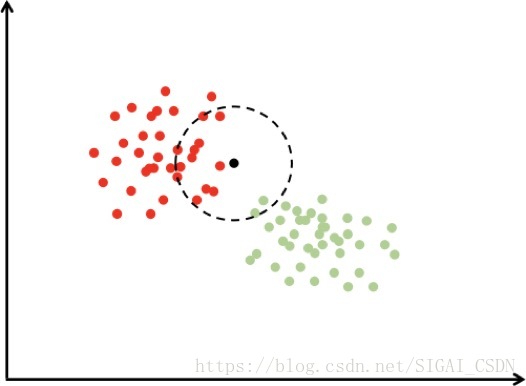
图6.1 k近邻分类示意图
在上图中有红色和绿色两类样本。对于待分类样本即图中的黑色点,我们寻找离该样本最近的一部分训练样本,在图中是以这个矩形样本为圆心的某一圆范围内的所有样本。然后统计这些样本所属的类别,在这里红色点有12个,圆形有2个,因此把这个样本判定为红色这一类。上面的例子是二分类的情况,我们可以推广到多类,k近邻算法天然支持多类分类问题。
预测算法

k近邻算法实现简单,缺点是当训练样本数大、特征向量维数很高时计算复杂度高。因为每次预测时要计算待预测样本和每一个训练样本的距离,而且要对距离进行排序找到最近的k个样本。我们可以使用高效的部分排序算法,只找出最小的k个数;另外一种加速手段是k-d树实现快速的近邻样本查找。
一个需要解决的问题是参数k的取值。这需要根据问题和数据的特点来确定。在实现时可以考虑样本的权重,即每个样本有不同的投票权重,这称方法称为为带权重的k近邻算法。另外还其他改进措施,如模糊k近邻算法[2]。

距离定义
根据前面的介绍,kNN算法的实现依赖于样本之间的距离值,因此需要定义距离的计算方式。接下来介绍常用的几种距离定义,它们适用于不同特点的数据。

常用距离定义

这是我们最熟知的距离定义。在使用欧氏距离时应该尽量将特征向量的每个分量归一化,以减少因为特征值的尺度范围不同所带来的干扰。否则数值小的特征分量会被数值大的特征分量淹没。例如,特征向量包含两个分量,分别为身高和肺活量,身高的范围是150-200厘米,肺活量为2000-9000,如果不进行归一化,身
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









