







Pandas模块可以解决数据的预处理问题,如数据类型的转换、缺失值的处理、描述性统计分析、数据的汇总等。
本章学习的重点
- 两种重要的数据结构,即序列和数据框。
- 如何读取外部数据(如文本文件、电子表格或数据库中的数据)。
- 数据类型转换及描述性统计分析。
- 字符型与日期型数据的处理。
- 常见的数据清洗方法。
- 如何应用iloc、loc与ix完成数据子集的生成。
- 实现Excel中的透视表操作。
- 多表之间的合并和连接。
- 数据集的分组和聚合操作。
序列和数据框的构造
Pandas模块的核心操作对象就是序列(Series)和数据框(DataFrame)。序列可以理解为数据集中的一个字段,数据框是指至少两个字段(或序列)的数据集。
构造序列
构造一个序列可以通过如下方式实现:
- 通过同质的列表或元素构建。
- 通过字典构造。
- 通过Numpy中的一维数组构建。
- 通过数据框DataFrame中的某一列构建。
#导入模块
import pandas as pd
import numpy as np
#构造序列
gdp1 = pd.Series([2.8,3.08,3.2,4.5,6.7])
gdp2 = pd.Series({'北京':2.9,'上海':3.01,'广东':8.99,'浙江':23.12})
gdp3 = pd.Series(np.array((2.8,3.08,3.2,4.5,6.7)))
print(gdp1)
print(gdp2)
print(gdp3)
OUT:
0 2.80
1 3.08
2 3.20
3 4.50
4 6.70
dtype: float64
北京 2.90
上海 3.01
广东 8.99
浙江 23.12
dtype: float64
0 2.80
1 3.08
2 3.20
3 4.50
4 6.70
dtype: float64
#导入模块
import pandas as pd
import numpy as np
#构造序列
gdp1 = pd.Series([2.8,3.08,3.2,4.5,6.7])
gdp2 = pd.Series({'北京':2.9,'上海':3.01,'广东':8.99,'浙江':23.12})
gdp3 = pd.Series(np.array((2.8,3.08,3.2,4.5,6.7)))
# print(gdp1)
# print(gdp2)
# print(gdp3)
# 取出gdp1中的第一、第四和第五个元素
print('行号风格的序列:\n',gdp1[[0,3,4]])
#取出gdp2中的第一、第四个元素
print('行号风格的序列:\n',gdp2[[0,3]])
#取出gdp2中的上海和浙江的gdp值
print('行名称风格的序列:\n',gdp2[['上海','浙江']])
#数学函数——取对数
print('通过numpy函数:\n',np.log(gdp1))
#平均gdp
print('通过numpy函数:\n',np.mean(gdp1))
print('通过序列的方法:\n',gdp1.mean())
OUT:
行号风格的序列:
0 2.8
3 4.5
4 6.7
dtype: float64
行号风格的序列:
北京 2.90
浙江 23.12
dtype: float64
行名称风格的序列:
上海 3.01
浙江 23.12
dtype: float64
通过numpy函数:
0 1.029619
1 1.124930
2 1.163151
3 1.504077
4 1.902108
dtype: float64
通过numpy函数:
4.056
通过序列的方法:
4.056
构造数据框
数据框实质上就是一个数据集,数据集的行代表每一条观测,数据集的列则代表各个变量。在一个数据框中可以存放不同数据类型的序列,如整数型、浮点型、字符型和日期时间型,数组和序列则没有这样的优势(数组和序列只能存放同质数据。构造数据框的方法:
- 通过嵌套的列表或元组构造。
- 通过字典构造。
- 通过二维数组构造。
- 通过外部数据读取构造。
import pandas as pd
import numpy as np
df1 = pd.DataFrame([['张三',23,'男'],['李四',27,'女'],['王二',26,'女']])
df2 = pd.DataFrame({'姓名':['张三','李四','王二'],'年龄':[23,27,26],'性别':['男','女','女']})
df3 = pd.DataFrame(np.array([['张三',23,'男'],['李四',27,'女'],['王二',26,'女']]))
print('嵌套列表构造数据框:\n',df1)
print('字典构造数据框:\n',df2)
print('二维数组构造数据框:\n',df3)
OUT:
嵌套列表构造数据框:
0 1 2
0 张三 23 男
1 李四 27 女
2 王二 26 女
字典构造数据框:
姓名 年龄 性别
0 张三 23 男
1 李四 27 女
2 王二 26 女
二维数组构造数据框:
0 1 2
0 张三 23 男
1 李四 27 女
2 王二 26 女
外部数据的读取
本节内容就是重点介绍如何基于Pandas模块实现文本文件、电子表格和数据框数据的读取。
文本文件的读取
读取txt或csv格式的数据,可以使用Pandas模块中的read_table函数或read_csv函数。
举一个读取txt文件数据的例子。
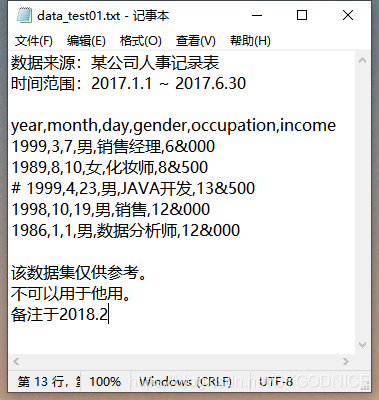
上图所呈现的txt格式数据集存在一些常见的问题,具体如下:
- 数据集并不是从第一行开始的,前面几行实际上是数据集的来源说明,读取数据时需要注意什么问题。
- 数据集的末尾3行仍然不是需要读入的数据,如何避免后3行数据的读入。
- 中间部分的数据,第四行前加了#号,表示不需要读取该行,该如何处理。
- 数据集中的收入一列,千分位符是&,如何将该字符读入为正常的数值型数据。
- 如何需要将year,month和day三个字段解析为新的birthday字段,该何如解决。
- 数据集中含有中文,一般在读取含中文文件时都会出现编码错误,该如何解决。
import pandas as pd
user_income = pd.read_table(r'C:\Users\SyGod\Desktop\data_test01.txt',sep=',',parse_dates={'birthday':[0,1,2]},skiprows=2,skipfooter=3,comment='#',encoding='utf-8',thousands='&')
print(user_income)
OUT:
birthday gender occupation income
0 1999-03-07 男 销售经理 6000
1 1989-08-10 女 化妆师 8500
2 1998-10-19 男 销售 12000
3 1986-01-01 男 数据分析师 12000
代码说明:由于read_table函数在读入数据时,默认将字段分割符sep设置为Tab制表符,而原始数据集是用逗号分割每一列,所以需要改变sep参数;parse_dates参数通过字典实现前三列的日期解析,合并为新字段birthday;skiprows和skipfooter参数分别实现原数据集开头几行和末尾几行的跳过;由于数据部分的第四行前面加了#号,因此通过comment参数指定跳过特殊行;这里仅改变字符编码参数encoding是不够的,还需要将原始的txt文件另存为UTF-8格式。最后,对于收入一列,由于千分位为&,因此为了保证数值型数据的正常读入,需要设置thousands参数为&。
电子表格的读取
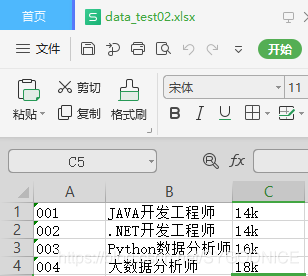
import pandas as pd
data_test02 = pd.read_excel(io = r'C:\Users\SyGod\Desktop\data_test02.xlsx',header=None,converters={0:str},names={'job_xz','job_name','job_id'})
print(data_test02)
OUT:
job_id job_name job_xz
0 001 JAVA开发工程师 14k
1 002 .NET开发工程师 14k
2 003 Python数据分析师 16k
3 004 大数据分析师 18k
数据库数据的读取
从Mysql数据库读取数据。
#读入MySQL数据库数据
#导入第三方模块
import pymysql
import pandas as pd
#连接MYSQL数据库
conn = pymysql.connect(host='****',user='****',password='****',database='****',port=****,charset='****')
#读取数据
user = pd.read_sql('select * from ****',conn)
#关闭连接
conn.close()
print(user)
从SQL Server数据库读取数据。
import pandas as pd
import pymssql
connect = pymssql.connect(server = 'localhost',user='',password='',database='DB1',charset='utf8')
data = pd.read_sql("select * from doker",con=connect)
connect.close()
data.head()















 1141
1141











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











