最近在看《集体智慧编程》,相比其他机器学习的书籍,这本书有许多案例,更贴近实际,而且也很适合我们这种准备学习machine learning的小白。
这本书我觉得不足之处在于,里面没有对算法的公式作讲解,而是直接用代码去实现,所以给想具体了解该算法带来了不便,所以想写几篇文章来做具体的说明。以下是第一篇,对皮尔逊相关系数作讲解,并采用了自己比较熟悉的java语言做实现。
皮尔逊数学公式如下,来自维基百科。
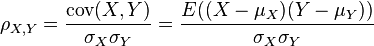
其中,E是数学期望,cov表示协方差,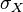 和
和 是标准差。
是标准差。
化简后得:


皮尔逊相似度计算的算法还是很简单的,实现起来也不难。只要求变量X、Y、乘积XY,X的平方,Y的平方的和。我的代码所使用的数据测试集来自《集体智慧编程》一书。代码如下:
- package pearsonCorrelationScore;
-
- import java.util.ArrayList;
- import java.util.HashMap;
- import java.util.List;
- import java.util.Map;
- import java.util.Map.Entry;
-
-
-
-
-
-
-
-
- public class PearsonCorrelationScore {
-
- private Map<String, Map<String, Double>> dataset = null;
-
- public PearsonCorrelationScore() {
- initDataSet();
- }
-
-
-
-
- private void initDataSet() {
- dataset = new HashMap<String, Map<String, Double>>();
-
-
- Map<String, Double> roseMap = new HashMap<String, Double>();
- roseMap.put("Lady in the water", 2.5);
- roseMap.put("Snakes on a Plane", 3.5);
- roseMap.put("Just My Luck", 3.0);
- roseMap.put("Superman Returns", 3.5);
- roseMap.put("You, Me and Dupree", 2.5);
- roseMap.put("The Night Listener", 3.0);
- dataset.put("Lisa Rose", roseMap);
-
-
- Map<String, Double> jackMap = new HashMap<String, Double>();
- jackMap.put("Lady in the water", 3.0);
- jackMap.put("Snakes on a Plane", 4.0);
- jackMap.put("Superman Returns", 5.0);
- jackMap.put("You, Me and Dupree", 3.5);
- jackMap.put("The Night Listener", 3.0);
- dataset.put("Jack Matthews", jackMap);
-
-
- Map<String, Double> geneMap = new HashMap<String, Double>();
- geneMap.put("Lady in the water", 3.0);
- geneMap.put("Snakes on a Plane", 3.5);
- geneMap.put("Just My Luck", 1.5);
- geneMap.put("Superman Returns", 5.0);
- geneMap.put("You, Me and Dupree", 3.5);
- geneMap.put("The Night Listener", 3.0);
- dataset.put("Gene Seymour", geneMap);
- }
-
- public Map<String, Map<String, Double>> getDataSet() {
- return dataset;
- }
-
-
-
-
-
-
-
-
- public double sim_pearson(String person1, String person2) {
-
- List<String> list = new ArrayList<String>();
- for (Entry<String, Double> p1 : dataset.get(person1).entrySet()) {
- if (dataset.get(person2).containsKey(p1.getKey())) {
- list.add(p1.getKey());
- }
- }
-
- double sumX = 0.0;
- double sumY = 0.0;
- double sumX_Sq = 0.0;
- double sumY_Sq = 0.0;
- double sumXY = 0.0;
- int N = list.size();
-
- for (String name : list) {
- Map<String, Double> p1Map = dataset.get(person1);
- Map<String, Double> p2Map = dataset.get(person2);
-
- sumX += p1Map.get(name);
- sumY += p2Map.get(name);
- sumX_Sq += Math.pow(p1Map.get(name), 2);
- sumY_Sq += Math.pow(p2Map.get(name), 2);
- sumXY += p1Map.get(name) * p2Map.get(name);
- }
-
- double numerator = sumXY - sumX * sumY / N;
- double denominator = Math.sqrt((sumX_Sq - sumX * sumX / N)
- * (sumY_Sq - sumY * sumY / N));
-
-
- if (denominator == 0) {
- return 0;
- }
-
- return numerator / denominator;
- }
-
- public static void main(String[] args) {
- PearsonCorrelationScore pearsonCorrelationScore = new PearsonCorrelationScore();
- System.out.println(pearsonCorrelationScore.sim_pearson("Lisa Rose",
- "Jack Matthews"));
- }
-
- }
将各个测试集的数据反映到二维坐标面中,如下所示:
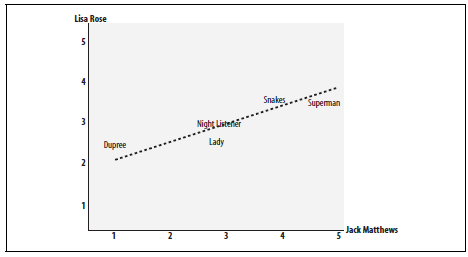
上述程序求得的值实际上就为该直线的斜率。其斜率的区间在[-1,1]之间,其绝对值的大小反映了两者相似度大小,斜率越大,相似度越大,当相似度为1时,该直线为一条对角线。























 118
118

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









