







Sigmoid 交叉熵损失函数(Sigmoid Cross Entropy Loss)
官方: loss ![$ E = \frac{-1}{n} \sum\limits_{n=1}^N \left[ p_n \log \hat{p}_n + (1 - p_n) \log(1 - \hat{p}_n) \right] $](http://caffe.berkeleyvision.org/doxygen/form_63.png) ,
,
输入:
形状:






 得分
得分







 , 这个层使用 sigmoid 函数
, 这个层使用 sigmoid 函数

 映射到概率分布
映射到概率分布






形状:
标签

输出:
- 形状:
计算公式:









应用场景:
预测目标概率分布
| bottom | input Blob vector (length 2)
|
| top | output Blob vector (length 1)
|
![$ x \in [-\infty, +\infty]$](http://caffe.berkeleyvision.org/doxygen/form_64.png) , which this layer maps to probability predictions
, which this layer maps to probability predictions ![$ \hat{p}_n = \sigma(x_n) \in [0, 1] $](http://caffe.berkeleyvision.org/doxygen/form_65.png) using the sigmoid function
using the sigmoid function 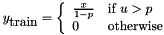 (see
(see ![$ y \in [0, 1] $](http://caffe.berkeleyvision.org/doxygen/form_67.png)
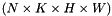 the computed cross-entropy loss:
the computed cross-entropy loss: Computes the sigmoid cross-entropy loss error gradient w.r.t. the predictions.
Gradients cannot be computed with respect to the target inputs (bottom[1]), so this method ignores bottom[1] and requires !propagate_down[1], crashing if propagate_down[1] is set.
-
Parameters
-
top output Blob vector (length 1), providing the error gradient with respect to the outputs propagate_down see Layer::Backward. propagate_down[1] must be false as gradient computation with respect to the targets is not implemented. bottom input Blob vector (length 2) 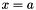 the predictions
the predictions 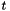 ; Backward computes diff
; Backward computes diff 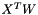
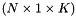 the labels – ignored as we can't compute their error gradients
the labels – ignored as we can't compute their error gradients
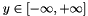 , as
, as 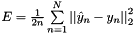 in the overall
in the overall 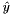 ; hence
; hence 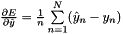 . (*Assuming that this top
. (*Assuming that this top 













 8159
8159











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









