






承接JVM-2 运行时数据区域(上),本文主要介绍堆内存、方法区以及常量池部分。
1.堆内存
Java堆是虚拟机管理的最大的一块内存,在JVM进程启动时创建,所有线程共享,主要目的是存放对象实例。
《Java虚拟机规范》中对java堆的描述:“所有的对象实例以及数组都应当在堆中分配”。
随着编译技术以及逃逸分析技术的发展,一些优化手段使得上述面题不完全成立。对象可以通过栈上分配和标量替换的方式进行创建,这样的好处是对象可以在方法执行完时,随着栈帧的弹出而释放内存,给GC较小了负担。
堆内存和垃圾回收器最熟的内存区域,因为GC主要针对的对象是堆内存和方法区,而方法区的GC条件比较苛刻。现代的垃圾回收器基本都是基于分代理论,结合垃圾回收算法,将堆内存进一步地细化为新生代、老年代;新生代又可划分为Eden区域和两个Survivor。对Java堆的细化分是为了更有效地回收内存。

其中:Eden区域可以为每个线程分配了一个TLAB(可以通过 -XX:UseTLAB来设置是否使用TLAB)。由于是线程私有的,因此在分配对象时就没有竞争关系,减少了锁的使用,相对于直接在堆中分配,效率提升很多。
另外,我们给虚拟机设置参数的时候,使用-Xms和-Xmx来设置堆内存的最小和最大内存(推荐设置成一样,避免内存振荡而影响jvm效率)。
2.方法区
方法区是一个JVM规范中的逻辑结构,供各线程共享。Java虚拟机规范中原话是“用于储存已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码缓存等数据。”
hotspot虚拟机在不同的jdk版本有不同的实现方式:在jdk7以及以前版本中使用Permanent-Generation(永久代);在jdk8版本及以后(目前为止发布的版本)使用Meta-Space(元空间)。
使用元空间替换永久代的主要原因是:Hotspot有意愿与JRockit合二为一,顺便为了解决突出的类和类加载器元数据过多导致的OOM问题。
这个过程中,方法区中存放的数据也有计划地进行了调整:
在jdk6以及以前版本:元空间还是一个整体,运行时常量池,类型信息,字符串常量池、静态类型、常量等都存在方法区(永久代)里。
jdk7中:字符常量池和静态变量被转移到了堆中,方法区(永久代)仅存放运行时常量池和类型信息等数据;
jdk8中:方法区(元空间)中存放 运行时常量池,类型信息,常量等;字符串常量池和静态变量还是在堆中储存。
3.运行时常量池和字符串常量池
把这两个概念放在一起是因为运行时常量池和字符串常量池都涉及池的概念。池本来就是就是一个为了节约资源以及提高系统性能的享元设计模式。
3.1运行时常量池
class文件中的常量池被加载器加载进jvm内存后,形成运行时常量池。对于每个类都有一个对应的运行时常量池区域,该区域存放编译时形成的字面量和符号引用。与class文件的常量池不同点是,运行时常量池是个动态的概念,存储的内容是可以变化的,运行时可以将新的常量加入运行时常量池。
3.2 字符串常量池
这部分个人觉得比较重要,因为实际编写代码时需要经常和字符串打交道,理解常量池的本质,有助于编写高效率的代码,减少不必要的内存浪费。由于全面介绍需要结合编译器前端优化一起,所以归档在JVM-4 前端编译与优化中。
如上文所提及的,字符串常量池随着jdk版本的发布,存储位置发生了变化:jdk6时存在于方法区(永久代),在jdk7及之后存在于堆内存中。
以下通过一个简单的例子进行对比讲解(印象中来源于某次求职笔试题)。
jdk6和jdk7中分别执行以下代码:
String s1 = new String("sheng") + new String("yu");
s1.intern();
String s2 = "shengyu";
System.out.println(s1 == s2);
在jdk6中:
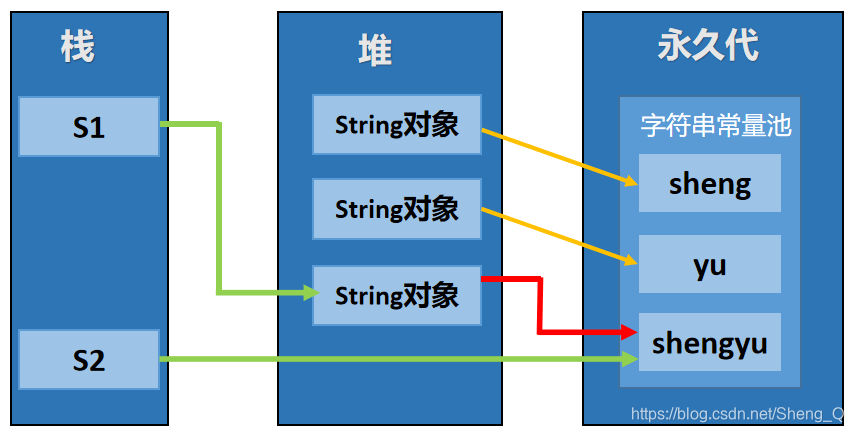
如上图所示,在jdk6中:
String s1 = new String("sheng") + new String("yu");
“sheng"和"yu"是字符串字面量,所以直接在字符串常量池中有对应的实例。两个匿名String对象的值是常量池中"sheng"和"yu"的地址。s1变量指向的String对象是由匿名变量拼接创建生成的,该String实例的内容是"shengyu”。
s1.intern();
先从字符串常量池中搜索,没有搜索到,将"shengyu"这个字符串拷贝到字符串常量池中,此时字符串常量池存放的值是"shengyu"这个实例。
String s2 = "shengyu";
让s2的直接指向了字符串常量池"shengyu"的地址;此时,s1指向的是堆内存中一个String对象实例,而s2指向的是字符串常量池的一个实例对象,s1和s2保存的值(内存地址)不一样;因此s1 == s2的执行结果为fasle;
在jdk7中:
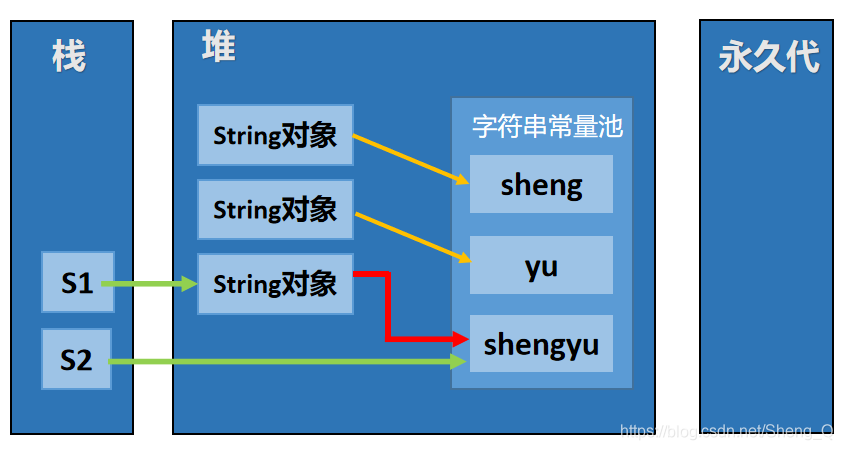
String s1 = new String("sheng") + new String("yu");
“sheng"和"yu"是字符串字面量,所以在字符串常量池中有对应的实例。新创建的两个匿名对象的值是常量池中"sheng"和"yu"的地址。s1变量指向的String对象是由匿名变量拼接创建生成的,该String实例的内容是"shengyu”。
s1.intern();
先从字符串常量池中搜索,没有搜索到,就在字符串常量池中新增一个常量,指向s1指向的对象,即此时常量池中保存的是对象的引用(与栈变量s1中值相同),而不是一个实例。
String s2 = "shengyu";
让s2指向了字符串常量池代表"shengyu"的地址,此时该地址是s1指向对象的地址。此时,s1和s2指向的是堆内存中同一个String对象实例,因此s1 == s2的执行结果为true。
由以上分析:
(1) 字符串常量池在jdk6以前,存放在方法区;在jdk7以后存放在堆内存中;
(2) 字符串常量池在jdk6以前只会存放string实例;在jdk7以及以后可以存放String对象实例也可存放String对象的应用;
(3) 对于字符串字面量,在字符串常量池中保存实例;
(4) 对于动态生成的字符串,使用intern()形式同步到常量池时,常量池保存的是对象的引用。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









