







谁挡了我的神经网络?(一)—— 如何在训练中得到更好的结果
博主最近在尝试训练自己新设计的神经网络,但是网络收敛到的损失并不让人满意。于是,博主决定在这里记录下在尝试让网络收敛得更好的过程中,成功与失败的经验(包括实验)。这一系列会随着博主研究的不断深入,有选择地更新。本文更新于2018.11.2。
写在前面的话:
虽然有各种各样会影响网络收敛效果的因素,但归根结底还是需要通过实验来检验想法的正确性。可以在实验过程中通过修改迭代次数、随机Seed、超参数(如dropout ratio)、归一化项(regularization weight penalties)、early stopping等方式,最终确定能够使得神经网络收敛到最优的一组方案。
除此之外,为了提高对噪声数据的范化性,也可以通过训练多个神经网络再平均它们输出或权重的方法,实现更好的结果。
目前存在很多基础的网络结构,开发者们也可以根据自己的实际需要选择合适的网络结构。比如,如果需要做股票预测,RNN可能更适合你。
最后,祝愿大家都能得到令自己满意的神经网络!Happy surfing!
文章目录
网络结构
在所有参数面前,网络结构的合理性是影响结果的最重要的因素。好的网络结构的表现通常会更好。
至于如何确定自己设计的网络结构是否正确,除了理论上的分析,也就只有实验能告诉你了。
对网络结构的理解
对于与图像相关的问题,神经网络通常用来习得更复杂的特征以描述目标,而每一层的描述方式、视野等都是不同的。如何理解这些层的功能,从而设计神经网络,是需要好好考量的。
下面是两个例子:
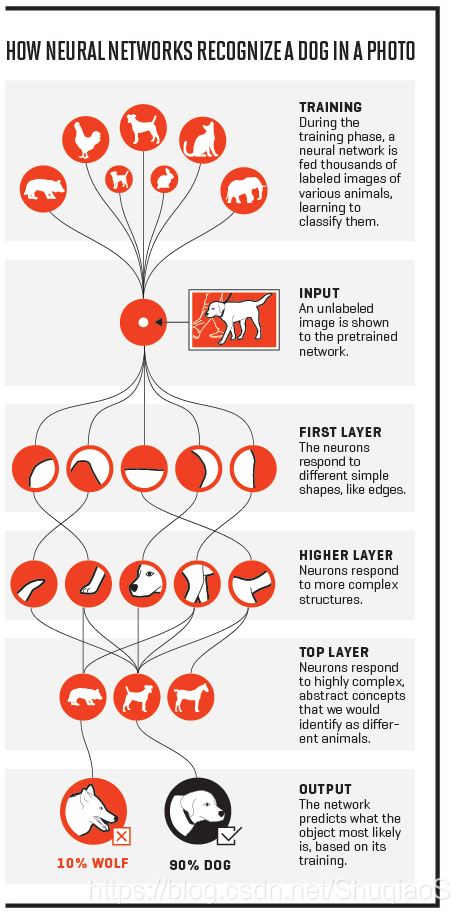
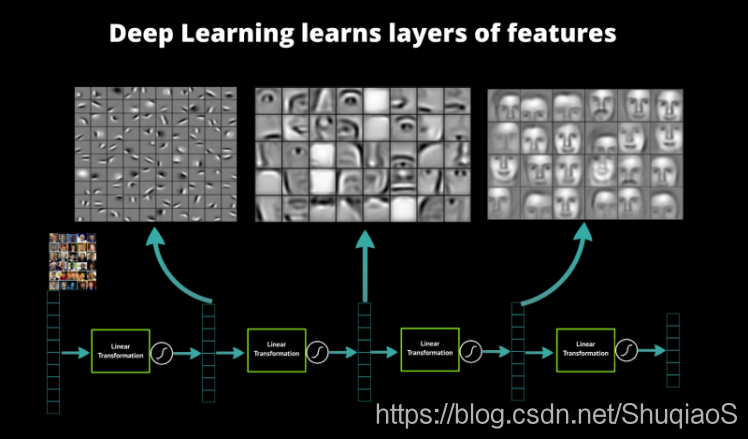
特征的选取
通常来讲,神经网络会自动过滤掉那些对于决策无用的特征(比如将其权重设成几乎为0),但是这仍然有可能影响到网络最终的结果。因此,如果可能的话,建议尝试从不同的角度去引导神经网络输入或习得的特征。
换个角度想问题
打破思维定式,尝试用不同的方法解决当前的问题,或者将当前的问题分解或综合。这样,你可能会从根本上提升神经网络的效果。
数据集
在网络结构确定以后,最重要的莫过于数据集了。通常来讲,好的数据集或更多的数据能够帮助你获得更好的结果,且这种提升很有可能比调参带来的更大。比如,就博主的实验经验而言,一个大规模的数据集,在其他设置完全相同的情况下,对网络最终的收敛结果的精度提高了近一倍。
规模
通常来讲,一个小的数据集训练出来的网络很有可能会过拟合(overfit),从而导致测试损失的增大。最理想的情况是我们有一个足够大的数据集用来训练神经网络。但是如果无法获得足够规模的数据集该怎么办呢?一个有效的办法就是进行数据扩张,也就是人为地将已有的数据集通过旋转、缩放、平移、增加噪声、修改亮度等手段,在原本数据的基础上”创造“出新的数据集。
归一化
一般情况下,对数据集进行scaling或normalizing会提高神经网络的效果,比如让其收敛更快且更不容易陷入局部最优。除此之外,权重下降和Bayesian估计等在归一化的输入下也更容易实现。这是因为,在没有归一化的数据集下,梯度下降的方向很有可能被哪几组数据掌控了,从而引导向了错误的收敛方向。
实验验证
博主目前在验证数据集对网络训练结果的影响。实验设置:网络结构相同,学习率、优化方法等完全相同(1e-4、Adam),只是用不同的数据集。考虑到更大的数据集需要更大的网络灵活性,因此这里用作实验和对比的都是后面会提到的通道数翻倍的网络。
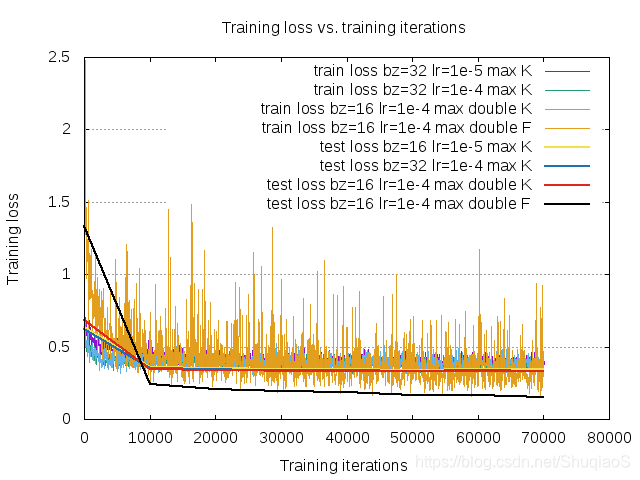
学习曲线
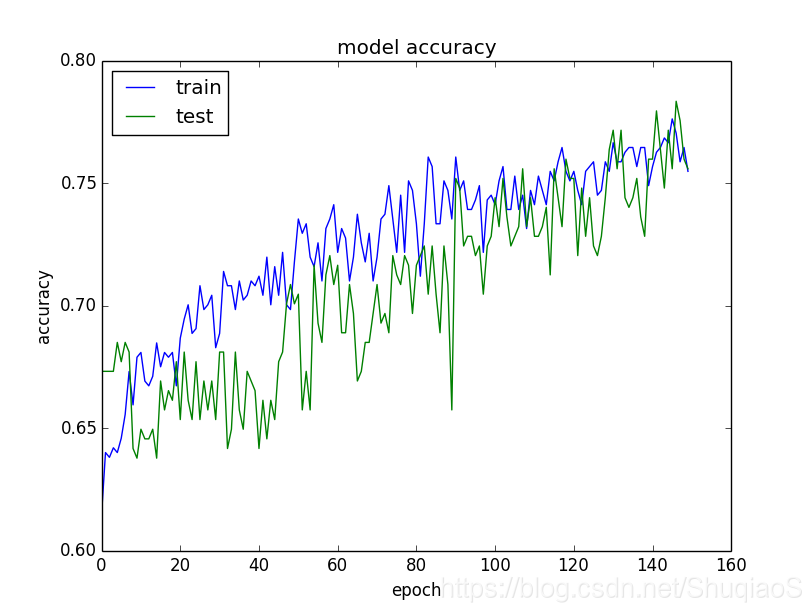
在神经网络的训练过程中,一定要养成绘制训练曲线的习惯,从而监测自己的神经网络是否存在欠拟合或过拟合的问题:
- 如果训练损失明显小于测试损失,那么网络很有可能存在过拟合,此时需要应用regularization或更换归一化方法;
- 如果训练损失和测试损失都很大,那么网络有可能存在欠拟合,此时可以尝试增加网络容量或迭代次数;
- 如果像下图一样存在一个反超点,那么可能需要提前停止。
学习率
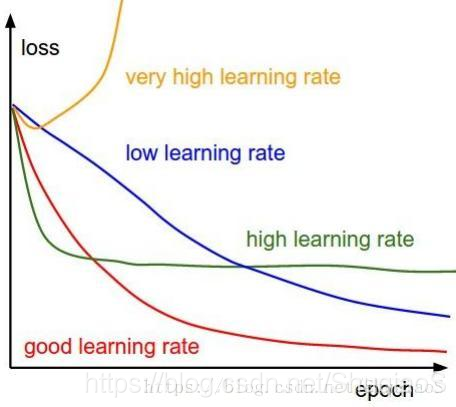
博主之前写过一篇博文,里面简单提到了学习率对于网络收敛结果的影响。概括来说,就是选择了合适的学习率会在一定程度上降低网络收敛到的损失。需要注意的是,学习率是与迭代次数、batch size、优化方法等协同工作的。
直观来讲,学习率决定了神经网络的收敛过程中每次迭代的“步子”有多大,而我们的目标是让它走到全局最优的位置(走进最深的坑)。但是,这块地不平,有很多局部最优(其他的小坑),深浅不一、口径不同。那么合适的学习率就是:既能在网络走进局部最优的时候,能让它的步子足够在下几次的迭代过程中逐渐迈出这个坑;又能在它遇到真正的全局最优时不至于步子太大,跳出了最深的坑。比如下面两张图,分别演示了如果学习率过大和学习率太小对收敛过程会造成的影响。

这是不同学习率对应的训练曲线的趋势:
下图是博主的一个网络的训练和测试曲线。这两条曲线的训练状况完全相同,唯一的区别就在于学习率。可以看到,除了收敛速度上有明显变化外,曲线收敛到的训练和测试损失也有所下降。
至于具体如何选择学习率,博主的建议是,在控制变量的情况下,尝试各种可能的学习率(从过大到过小),绘制学习曲线,从而确定最好的那一个。
另外,在训练过程中,也可以尝试在几次迭代以后逐渐缩小学习率,或者增加动量,考察动量与学习率结合的曲线。
注:有文章说,越复杂的网络需要的学习率越大,但是这个与博主目前的经验有出入,所以还是建议根据自己的网络多多尝试,再确定最终的学习率。
Batch Size
Batch Size的大小决定了神经网络多久更新一次权重。越复杂的网络通常会应用更小的Batch Size和更多的迭代次数。
如果可能的话,可以尝试以下几种Batch Size:
- 等于整个数据集的尺寸(批学习);
- 等于1(在线学习);
- 不同mini-batch(8,16,32,…)。
目前博主还没有做关于Batch Size的影响的实验,做了会补上。
迭代次数
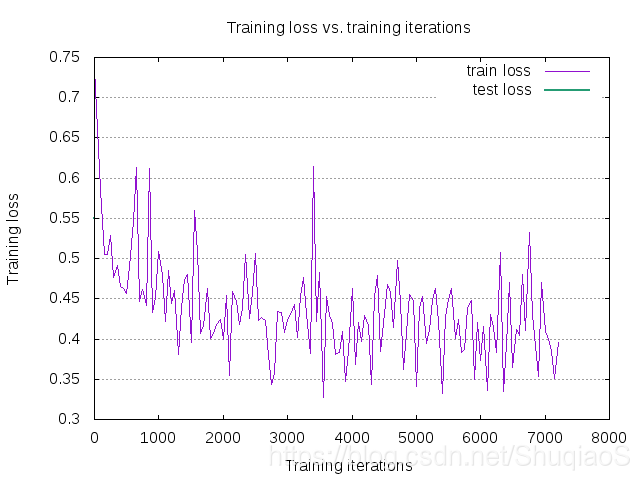
通常来讲,网络在确定合适的学习率后需要大量的梯度更新才会收敛,而这个量级通常要在100万次左右。也就是说,如果batch size取10,那么大概需要迭代10万次,网络才会真正收敛。不过,这只是一个参考,具体确定网络是否收敛还是要依赖学习曲线。如果发现曲线仍在下降,不如就耐心一点,多迭代几次。
这里给出一个还完全收敛的训练曲线的样子:
卷积层通道数(网络宽度)
通常来讲,神经元的个数(通道数)应当谨慎选择。因为,通道数太少的话,网络无法习得足够复杂的方程来描述需要描述的场景,或完成需要完成的任务;但网络通道数太多,又会导致网络收敛缓慢,甚至过拟合。但是,究竟用多少个神经元(通道),同样地,只能靠实验告诉你答案了。
(插一句:为了避免过拟合,训练中一定要有交叉验证集!)
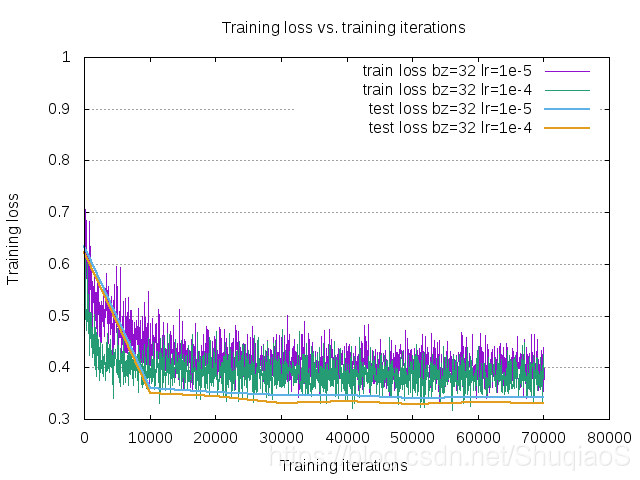
博主对卷积层通道数对结果的影响进行了实验,发现单纯增加网络宽度无法使得网络精度有明显提升,但从可视化的结果来看,网络确实体现了更强的适应性。然而这种适应性需要谨慎处理,因为这虽然意味着更好的描述能力,却也意味着更容易描述不需要或错误的东西。不过,在拥有更复杂或更大规模的数据集的情况下,更多的网络参数对于效果的提升还是有帮助的。
实验设置是:网络结构相同,学习率为1e-4;区别是batch size分别为32和16,卷积层Channel数翻倍。
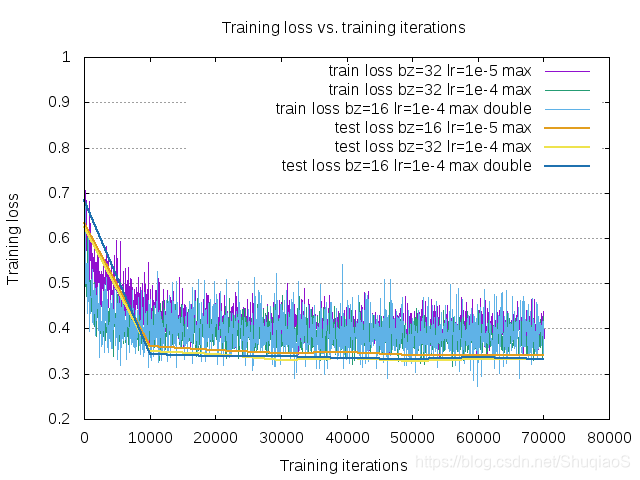
通道数n

通道数2n

卷积层数(网络深度)
这一部分的道理与增加网络宽度(即参数个数)是类似的,区别是,增加网络的深度可以通过更多不同种类的层的组合,创造更复杂的函数。对于复杂的情况,如增加了很多不同种类的层或增加了许多层与层之间的连接关系,在某种程度上可以视为网络结构的改变了。因此,这里博主只考虑单纯增加某一种类的层的个数,在不改变关键层含义的基础上,单纯增加网络的复杂性(模块的复制),是否会影响网络训练的最终结果。在得到这一部分的实验结果以后会附在这里。
优化方法和损失函数
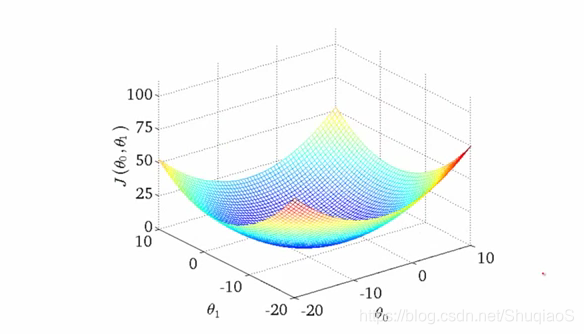
对于复杂的网络结构,损失地图往往非常复杂,会拥有许多的局部最优。比如,我们通常脑海中的损失地图是这样的
或者再复杂一点是这样的
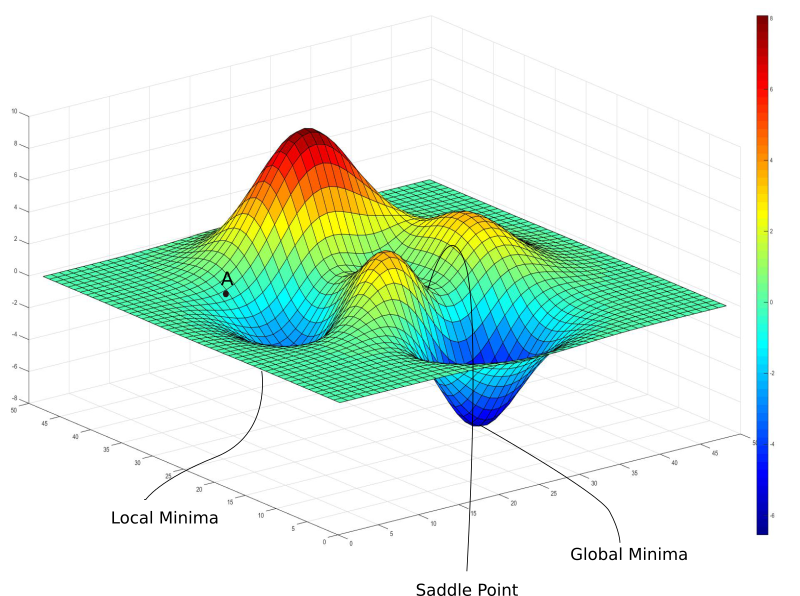
但其实,很有可能它是这样的

SGD是很久以前的优化方法了,其具有很多局限性,比如陷入局部最优、收敛速度慢等;现在有很多新的网络优化方式,能够提供更多参数选择,从而实现更准确、快速的收敛。因此,根据分析和实验,选择适合当前神经网络的优化方法很重要。目前比较流行的优化方法有ADAM、RMSprop等。
在确定优化方法后,一定要潜下心来,仔细研究其中各个参数的作用,从而确定优化方法的参数取值。如果有需要,可以参考博主的这篇文章,也许能有所启发。不过就博主的了解,如果应用目前的主流优化算法,通常就可以保证效果(避开局部最优)且收敛的速度也比较快。因此如果不是有特殊需要,或者你很明确自己在干什么,选择主流的优化算法和其默认的参数就可以了。
至于损失函数,就需要根据具体的问题,找到最能描述问题的那个损失函数。
激活函数
网络中是需要激活函数来将线性的变换转化成非线性的变换的,否则即使写了再多的层,也相当于是一层(线性变换)。至于是在中间应用还是在输出应用,还是其他的组合方式,就要根据具体问题分析了。
不同的激活函数对于网络训练的效果影响也不小,尤其是tanh,很难训练。因此现在大部分的神经网络里面都以ReLU作为激活函数(ReLU不仅收敛速度更快,同时也不太会出现梯度消失的问题)。即使是这样,ReLU的种类(regular ReLU、Leaky ReLU、Very Leaky reLU、RReLU、PReLU、ELU等,具体可能会写一篇学习博文,如果写了,在这里放上链接)和参数也有可能影响网络的效果。
另外,选择了不同的激活函数,也应当根据它们的属性做调整。比如,如果选择了tanh,那么类别就应该是-1和1,而非0和1。
权重初始化
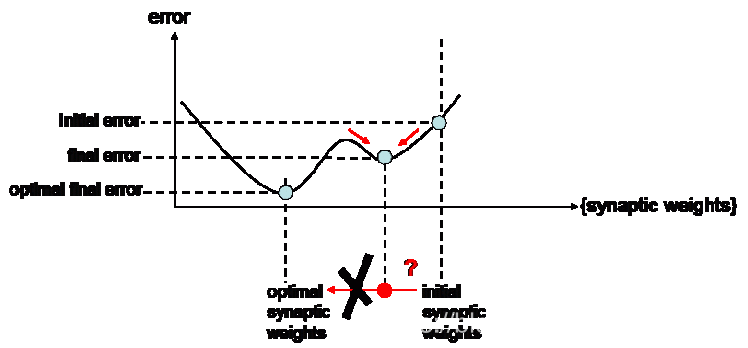
前面提到过,我们希望一个神经网络最终收敛到的是一个全局最优的位置,这个目标虽然困难,但是通过选择合适的学习率和初始权重是可以实现的。学习率的作用已经说过了,而初始权重就是告诉网络从哪里开始走。
通常来讲,网络都是被放在一个随机的位置上开始走的(随机权重)。但这样做存在一个危险,那就是不巧它正好被放在了许多的局部最优周围,甚至就被放在了局部最优那里。这就很有可能导致网络陷在了局部最优里面,出不来。
正则化
正则化是处理过拟合的一个行之有效的方法。目前比较常用的正则化方法是dropout,如果出现了过拟合可以尝试。
除此以外,还有一些比较传统的正则化方法,比如用权重下降法惩罚较大的权重,或利用约束条件惩罚较明显的行为。
更多内容,欢迎加入星球讨论。

参考文献
https://d4datascience.wordpress.com/2016/09/29/fbf/
https://machinelearningmastery.com/improve-deep-learning-performance/
https://www.topbots.com/14-design-patterns-improve-convolutional-neural-network-cnn-architecture/
梯度下降法:https://blog.paperspace.com/intro-to-optimization-in-deep-learning-gradient-descent/














 2477
2477











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









