







1. 范式概念
关系型数据库设计时,遵照一定的规范要求,目的在于降低数据的冗余性,目前业界范式有:第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、巴斯-科德范式(BCNF)、第四范式(4NF)、第五范式(5NF)。
范式可以理解为一张数据表的表结构,符合的设计标准的级别。
使用范式的根本目的是:
1)减少数据冗余,尽量让每个数据只出现一次。
2)保证数据一致性。
缺点是获取数据时,需要通过Join拼接出最后的数据。
2 .函数依赖
2.1 完全函数依赖:
设X,Y是关系R的两个属性集合,X’是X的真子集,存在X→Y,但对每一个X’都有X’!→Y,则称Y完全函数依赖于X。记做:![]()
人类语言:
比如通过,(学号,课程) 推出分数 ,但是单独用学号推断不出来分数,那么就可以说:分数 完全依赖于(学号,课程) 。
即:通过AB能得出C,但是AB单独得不出C,那么说C完全依赖于AB。
2.2 部分函数依赖:
假如 Y函数依赖于 X,但同时 Y 并不完全函数依赖于 X,那么我们就称 Y 部分函数依赖于 X,记做:![]()
人类语言:
比如通过,(学号,课程) 推出姓名,因为其实直接可以通过,学号推出姓名,所以:姓名 部分依赖于 (学号,课程)
即:通过AB能得出C,通过A也能得出C,或者通过B也能得出C,那么说C部分依赖于AB。
2.3 传递函数依赖:
传递函数依赖:设X,Y,Z是关系R中互不相同的属性集合,存在X→Y(Y !→X),Y→Z,则称Z传递函数依赖于X。记做:![]()
人类语言:
比如:学号 推出 系名 , 系名 推出 系主任, 但是,系主任推不出学号,系主任主要依赖于系名。这种情况可以说:系主任 传递依赖于 学号
通过A得到B,通过B得到C,但是C得不到A,那么说C传递依赖于A。
3.三范式区分
3.1 第一范式1NF核心原则就是:属性不可切割:

很明显上图所示的表格设计是不符合第一范式的,商品列中的数据不是原子数据项,是可以进行分割的,因此对表格进行修改,让表格符合第一范式的要求,修改结果如下图所示:

实际上,1NF是所有关系型数据库的最基本要求,你在关系型数据库管理系统(RDBMS),例如SQL Server,Oracle,MySQL中创建数据表的时候,如果数据表的设计不符合这个最基本的要求,那么操作一定是不能成功的。也就是说,只要在RDBMS中已经存在的数据表,一定是符合1NF的。
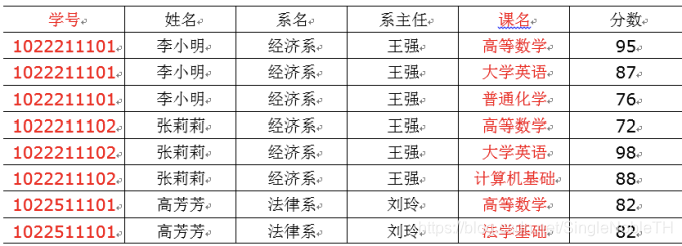
3.2 第二范式2NF核心原则:不能存在“部分函数依赖”:
以上表格明显存在,部分依赖。比如,这张表的主键是 (学号,课名),分数确实完全依赖于 (学号,课名),但是姓名并不完全依赖于(学号,课名)

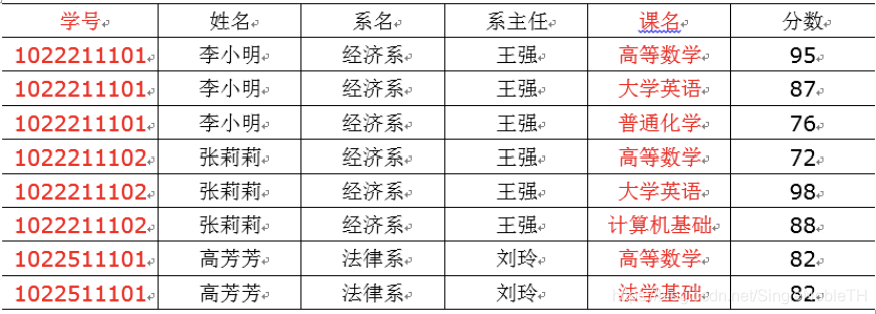
以上符合第二范式,去掉部分函数依赖依赖。
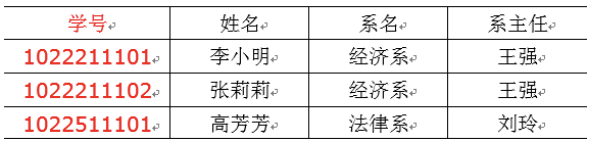
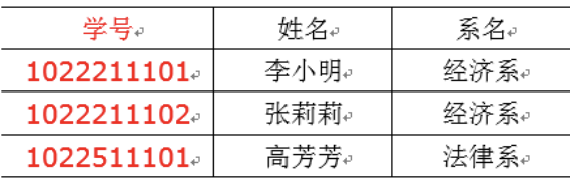
3.3 第三范式 3NF核心原则:不能存在传递函数依赖:
在下面这张表中,存在传递函数依赖:学号->系名->系主任,但是系主任推不出学号。
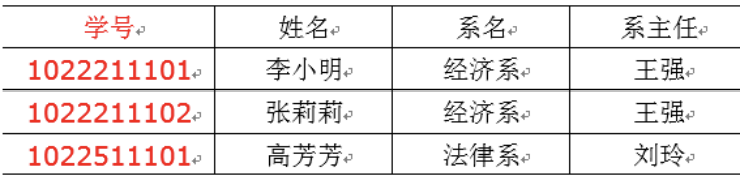
上面表需要再次拆解:

欢迎各位小伙伴更正。














 7888
7888











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









