







一、为什么要降维?
举个例子
两个特征“千克”,“磅”。可以发现,虽然是两个变量,但它们传达的信息是一致的,即物体的重量。所以我们只需选用其中的一个就能保留原始意义,把2维数据压缩到1维,这样的好处减少矩阵大小,在集合中就是减少维度,减少计算量,减少共线性。
在高维超正方体中,大多数点都分布在边界处: 在二维平面的一个正方形单元(一个 1×1 的正方形)中随机取一个点,那么随机选的点离所有边界大于 0.001(靠近中间位置)的概率为 0.4%( 1 - 0.998^2 )。在一个 1,0000 维的单位超正方体(一个 1×1×…×1 的立方体,有 10,000 个 1),这种可能性超过了 99.999999%。
高维数据集有很大风险分布的非常稀疏:在一个平方单位中随机选取两个点,那么这两个点之间的距离平均约为0.52,三维空间中这个距离是0.66,在一个 1,000,000 维超立方体中随机抽取两点,他们的距离大概是408.25。大多数训练实例可能彼此远离,训练集的维度越高,过拟合的风险就越大。
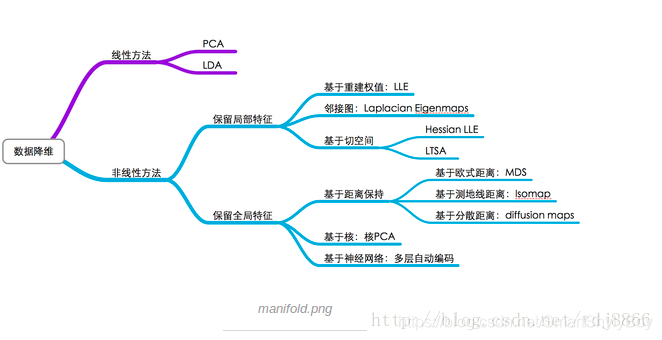
二、降维技术
降低数据维度的方法主要有两种
- 仅保留原始数据中最相关的变量(特征选择)
- 寻找一组较小的新变量,其中每个变量都是输入变量的组合,包含与输入变量基本相同的信息(降维)。
具体方法:
1、缺失值比率(Missing Value Ratio)
核心思想:空值率太低,果断舍弃(特征选择)
code:
train=pd.read_csv(“Train_UWu5bXk.csv”)
#用.isnull().sum()检查每个变量中缺失值的占比
# 保存变量中的缺失值
a = train.isnull().sum()/len(train)*100
2、低方差滤波(Low Variance Filter)
核心思想:如果我们某一列的数值基本一致,也就是他的方差非常非常小,那么这个值没有价值,低方差变量携带的信息量很少,这是可以考虑删除
放在示例中,我们先估算缺失值:
train[‘Item_Weight’].fillna(train[‘Item_Weight’].median, inplace=True)
train[‘Outlet_Size’].fillna(train[‘Outlet_Size’].mode()[0], inplace=True)
检查缺失值是否已经被填充:
train.isnull().sum()/len(train)*100
再计算所有数值变量的方差:
train.var()
再设定某个阈值,小于该阈值的全部删除
3、高相关滤波(High correlation filter)
核心思想:如果两个变量是高度相关的,它意味着他们具有相似的趋势,我们可以计算独立数值变量之间的相关性。如果相关性超过某个阈值,就删除其中一个变量
df=train.drop(‘Item_Outlet_Sales’, 1)
df.corr()
如上表所示,示例数据集中不存在高相关变量,但通常情况下,如果一对变量之间的相关性大于0.5-0.6,那就应该考虑是否要删除一列了。
4、随机森林 random forest
随机森林是一种广泛使用的特征选择算法,他会自动计算各个特征之间的重要性,无需单独编码。(注意:在开始降维前,我们先把数据转换成数字格式,因为随机森林只接受数字)
5、反向特征消除(backward feature elimination)
- 先获取数据集n个变量,然后用他们训练一个模型
- 计算模型性能
- 在删除每个变量(n次)后计算模型性能,即我们每次都去掉一个变量,用剩余的n-1个变量训练模型。
- 确定对模型性能影响最小的变量,把他删除
- 重复此过程,知道不在能删除变量
lreg = LinearRegression()
rfe = RFE(lreg, 10)
rfe = rfe.fit_transform(df, train.Item_Outlet_Sales)
6、向前特征选择(Forward Feature selection)
前向特征选择其实就是反向特征消除的相反过程,即找到能改善模型性能的最佳特征,而不是删除弱影响特征。
-
选择一个特征,用每个特征训练模型n次,得到n个模型。
-
选择模型性能最佳的变量作为初始变量。
-
每次添加一个变量继续训练,重复上一过程,最后保留性能提升最大的变量。
-
一直添加,一直筛选,直到模型性能不再有明显提高。
7、因子分析(Factor Analysis)
因子分析是一种常见的统计方法,它能从多个变量中提取共性因子,并得到最优解。假设我们有两个变量:收入和教育。它们可能是高度相关的,因为总体来看,学历高的人一般收入也更高,反之亦然。所以它们可能存在一个潜在的共性因子,比如“能力”。
8、主成分分析 PCA
核心思想: 找到接近数据集分布的超平面,然后将所有的数据都投影到这个超平面上。
如果说因子分析是假设存在一系列潜在因子,能反映变量携带的信息,那PCA就是通过正交变换将原始的n维数据集变到一个新的被称作主成分的数据集中,即从现有的大量变量中提取一组新的变量。
- 主成分是原始变量的线性组合
- 第一个主成分具有最大的方差值(选择保持最大方差的轴,因为它比其他投影损失更少的信息。)
- 第二主成分试图解释数据集中剩余的方差,并且与第一主成分不相关(正交)
- 第三主成分试图解释前两个主成分等没有解释的方差
9、独立分量分析(ICA)
总结:
缺失值比率:如果数据集的缺失值太多,我们可以用这种方法减少变量数。
低方差滤波:这个方法可以从数据集中识别和删除常量变量,方差小的变量对目标变量影响不大,所以可以放心删去。
高相关滤波:具有高相关性的一对变量会增加数据集中的多重共线性,所以用这种方法删去其中一个是有必要的。
随机森林:这是最常用的降维方法之一,它会明确算出数据集中每个特征的重要性。
前向特征选择和反向特征消除:这两种方法耗时较久,计算成本也都很高,所以只适用于输入变量较少的数据集。
因子分析:这种方法适合数据集中存在高度相关的变量集的情况。
PCA:这是处理线性数据最广泛使用的技术之一。
ICA:我们可以用ICA将数据转换为独立的分量,使用更少的分量来描述数据。
ISOMAP:适合非线性数据处理。
t-SNE:也适合非线性数据处理,相较上一种方法,这种方法的可视化更直接。
UMAP:适用于高维数据,与t-SNE相比,这种方法速度更快。
原文地址: www.analyticsvidhya.com/blog/2018/08/dimensionality-reduction-techniques-python/














 6913
6913











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









