









机器学习课程2 回归分析
【题目1】
使用R对内置鸢尾花数据集iris(在R提示符下输入iris回车可看到内容)进行回归分析,自行选择因变量和自变量,注意Species这个分类变量的处理方法。
解答:
1. iris数据集介绍
鸢尾花(iris)是数据挖掘常用到的一个数据集,包含150种鸢尾花的信息,每50种取自三个鸢尾花种之一(setosa,versicolour或virginica)。每个花的特征用下面的5种属性描述萼片长度(Sepal.Length)、萼片宽度(Sepal.Width)、花瓣长度(Petal.Length)、花瓣宽度(Petal.Width)、类(Species)。
观察这5个变量,我们发现Species是字符变量、非连续,难以直接进行线性分析。故首先应对定义哑变量处理离散变量Species。
在这里了我参考了“练数成金”论坛数据分析与数据挖掘技术板块
“fjchenxd”的文章
http://www.dataguru.cn/forum.php?mod=viewthread&tid=265621
以及“夕阳无语”的文章
http://www.dataguru.cn/forum.php?mod=viewthread&tid=262887


2 样本多重线性检查
2.1 求方阵,并对其标准化、中心化

2.2 求方阵的条件数,即kappa值

kappa = 291.2384,易知100kappa1000,多重共线性处于可忍受范围。
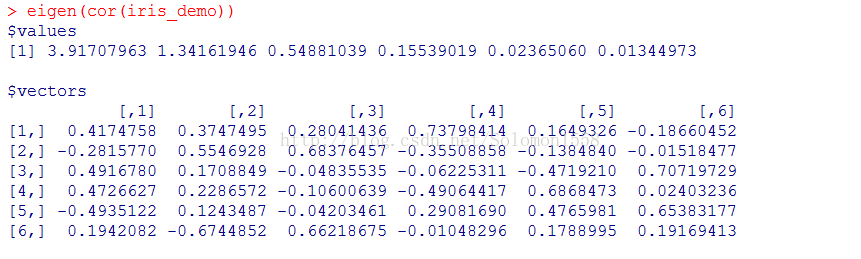
2.3 求解矩阵的特征值与相应的特征根
3. 一元线性回归分析
3.1 观察散点图
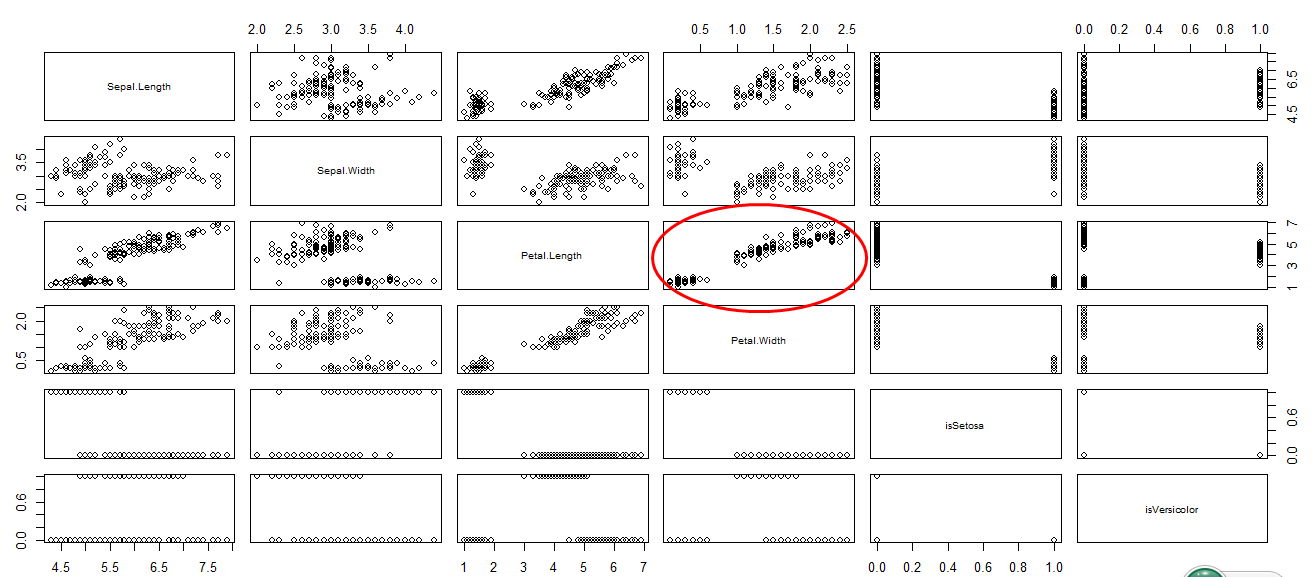
通过plot(iris_demo)命令,我们目测得到Petal.Width与Petal.Length有很强的线性关系。
3.2 对Petal.Width与Petal.Length做一元线性回归分析
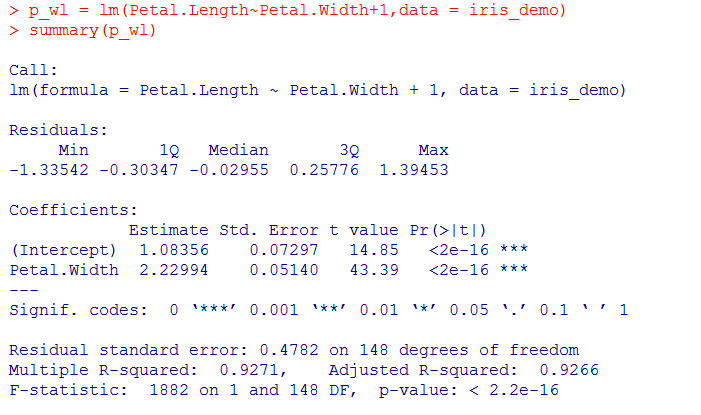
我们发现回归系数中,截距与因变量都有3颗*,t值很大,Pr值很小,拒绝系数不正确的假设检验。
相关系数平方:0.9271,数据相当好。
3.3 对Petal.Width与Petal.Length做一元线性回归诊断
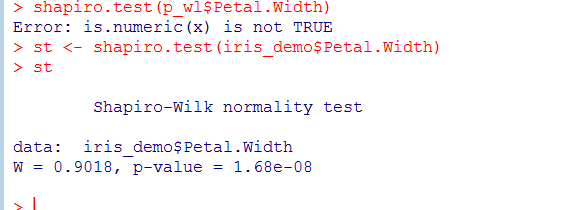
P = 1.68e-08 <0.05,具有统计学意义,拒绝原假设,说明自变量Petal.Width不服从正态分布。(?)

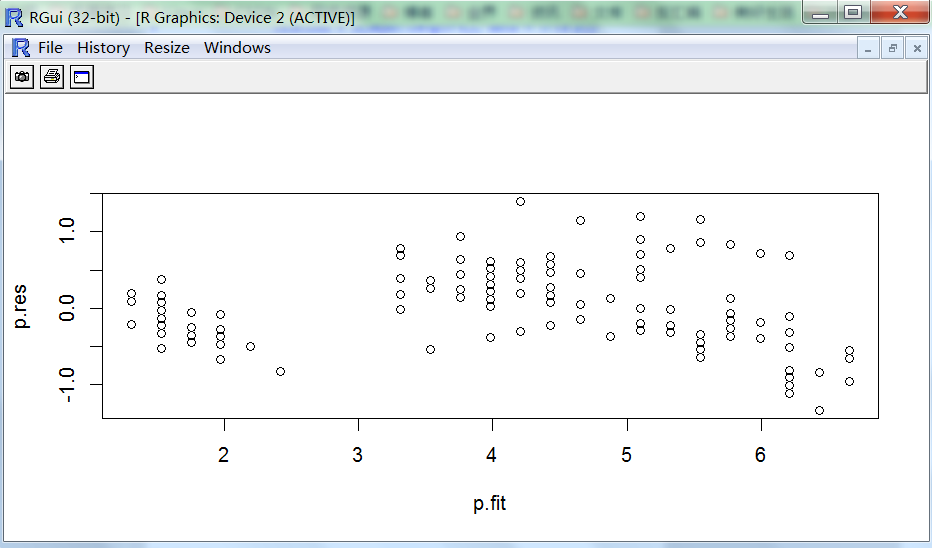
残差图正常,模型的残差服从正态分布。
结论:
综上,关于Petal.Width与Petal.Length的一元线性回归模型样本服不服从正态分布假设,误差满足独立性,等方差。线性回归模型的系数通过假设检验,相关系数平方和接近1。
此一元线性回归模型合理有效。
4 多元线性回归分析
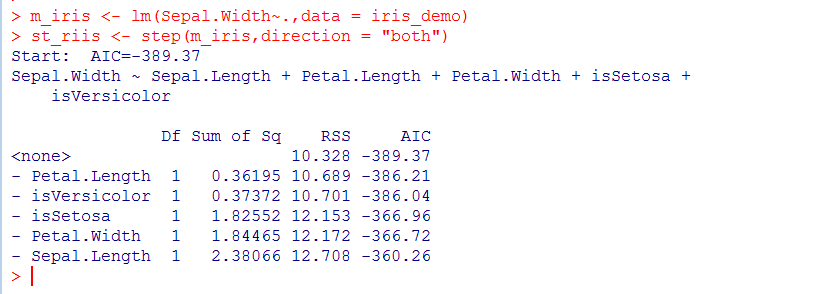
4.1变量进行逐步回归
4.2 多元线性回归模型的探索
4.2.1 包含全部变量
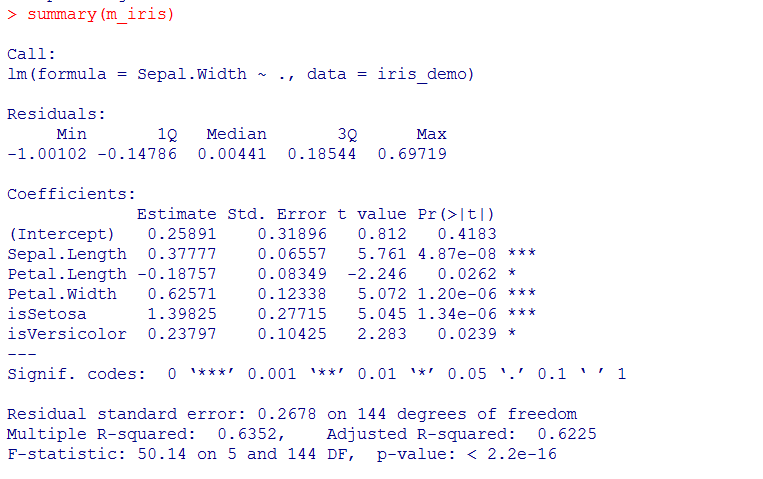
回归系数中Petal.length和isVerisicolor只有一颗星,而根据step结果,如果去掉这两个,AIC值只会从-389增大到-386,所以尝试去掉这两个值:
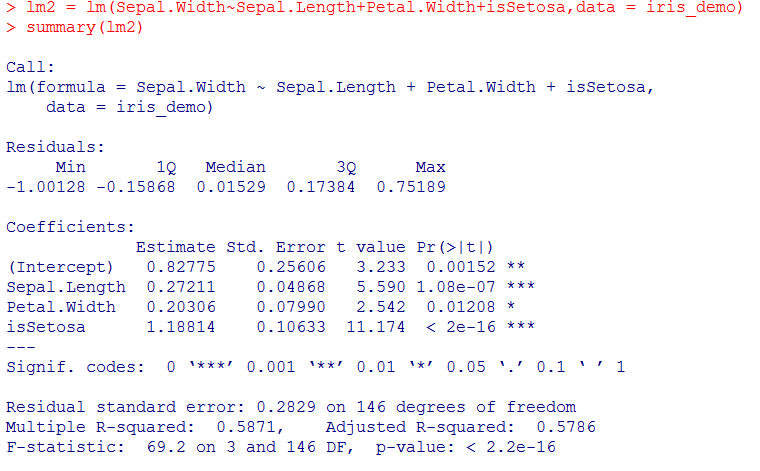
去掉Petal.Length和 isVersicolor后,截距的假设检验效果提升至两颗*,但Petal.Width的Pr值反而增大。更严重的是,相关系数平方和从0.6352降至0.5871。效果反而变差。
4.2.2尝试加上二次项
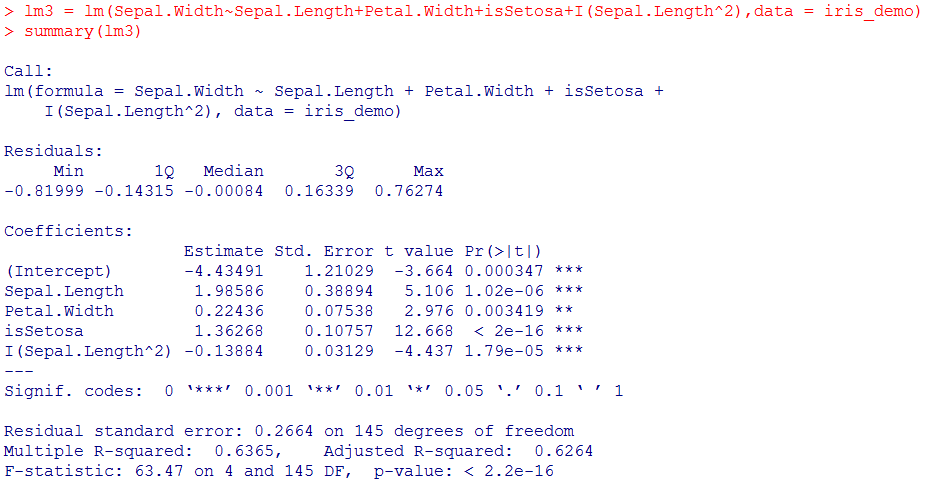
增加了Sepal.Length^2项后,相关系数提升到了0.6365。
4.2.3 增加乘积项
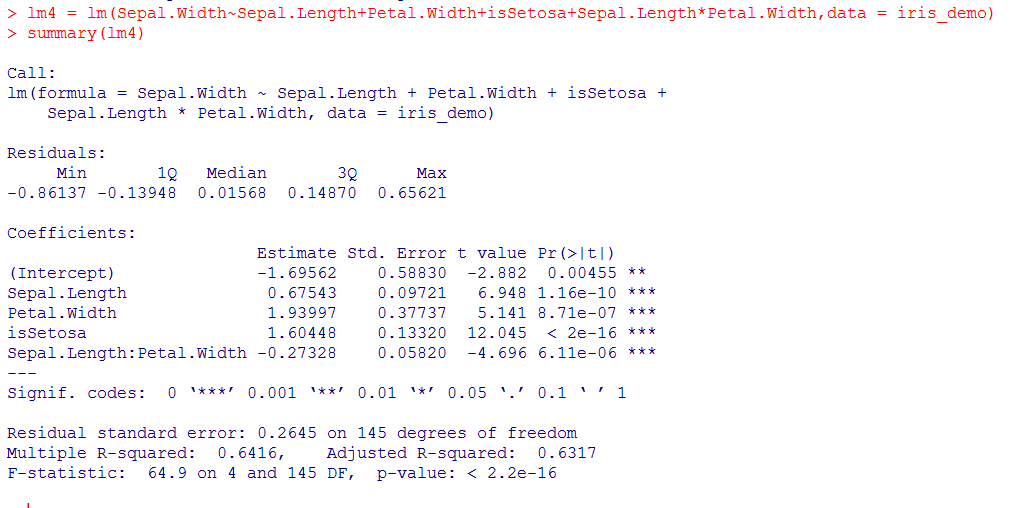
在增加了乘积项后,多元线性回归模型更加合理。
4.2.4 在所有变量的基础上直接加乘积项
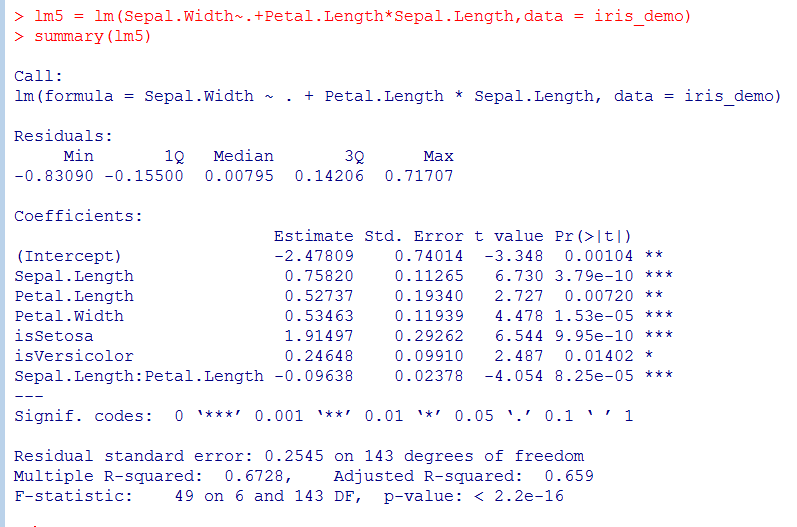
此模型的相关系数0.6728,相比4.2.3的模型更好,但是变量isVersicolor假设检验只有一颗* .
5. 回归诊断
对4.2.3与4.2.4的两个多元线性回归模型进行回归诊断:

5.1 变量正态分布检验
对变量进行正态分布检验,P值均小于0.05,拒绝了原假设(样本服从正态分布)。
5.2 残差图
(1)4.2.3 多元线性回归模型残差图
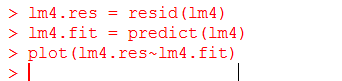
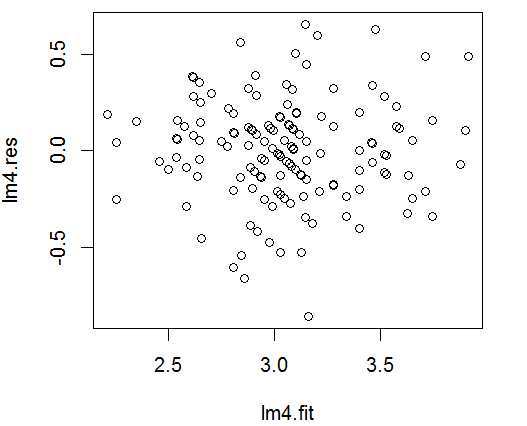
(2)4.2.4 多元线性回归模型残差图
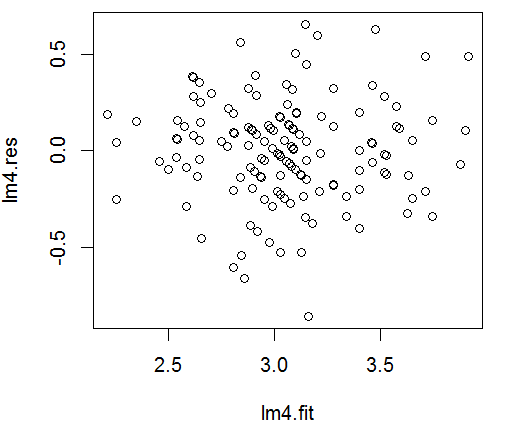
由以上两幅图可知残差分布正常,服从正态分布。
结论:
综上,采用4.2.4回归模型更优。

【题目2】
使用R对内置longley数据集进行回归分析,如果以GNP.deflator作为因变量y,问这个数据集是否存在多重共线性问题?应该选择哪些变量参与回归?
解答:
1. longley数据集
1.1 longley数据集简介
Longley数据集来自J.W.Longley(1967)发表在JASA上的一篇论文,是强共线性的宏观经济数据,包含GNP deflator(GNP平减指数)、GNP(国民生产总值)、Unemployed(失业率)、ArmedForces(武装力量)、Population(人口)、year(年份),Emlpoyed(就业率)。
LongLey数据集因存在严重的多重共线性问题,在早期经常用来检验各种算法或计算机的计算精度。
1.2 观察散点图
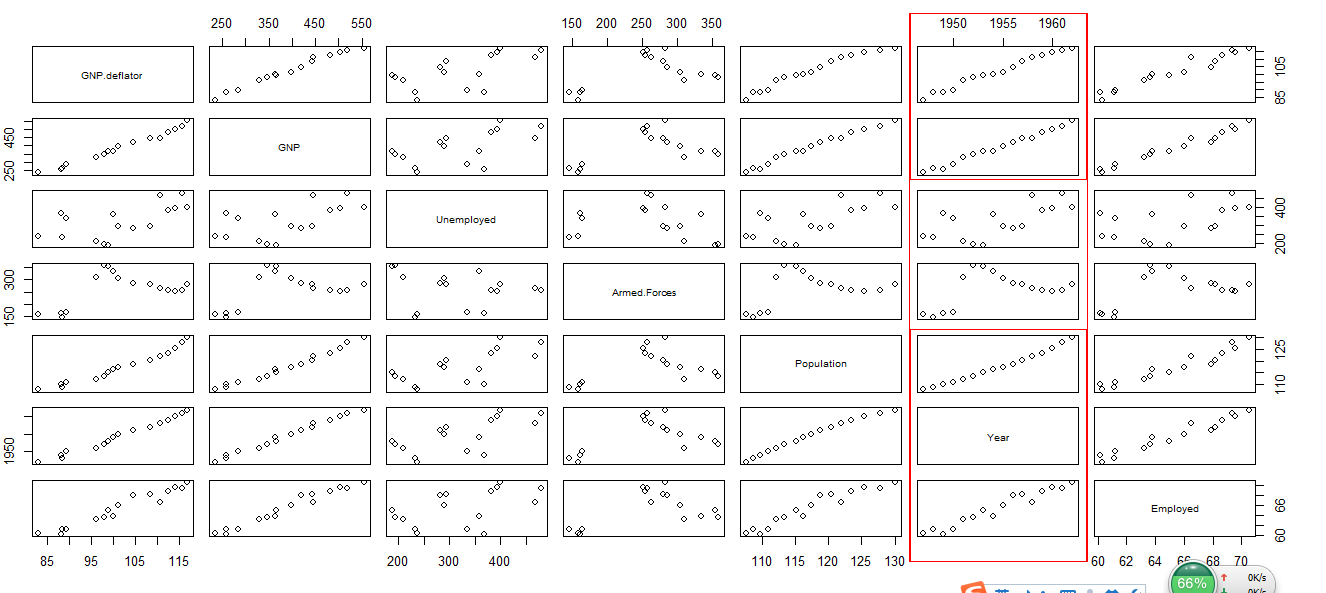
通过散点图观察,我发现变量GNP.deflator、GNP、Population、Employed
分别与year的函数图像趋势相近,可能隐含多重共线性。
2. 样本多重共线性检查
2.1 求方阵,并对其标准化、中心化
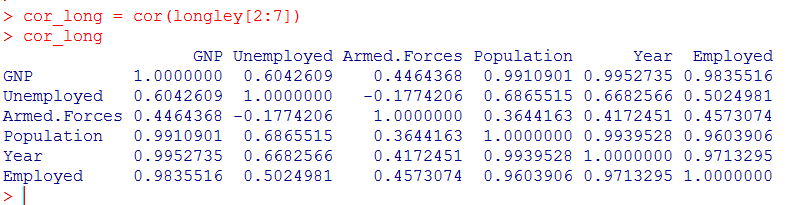
2.2 求方阵的条件数,即kappa值

kappa = 14550.47, kappa1000,多重共线性非常严重。
2.3 求解矩阵的特征值与相应的特征根

2.4 删选变量
可以看到变量4,5,6的特征值都非常小,逐步缩小所取变量数:

故删除变量Population,Year,Employed,只选取1:4共4个变量:
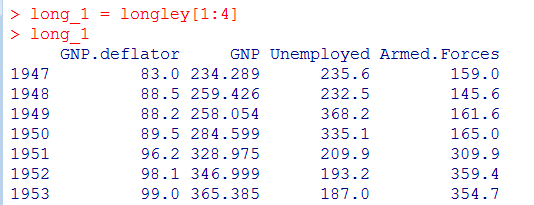
3. 逐步删选变量
3.1 原始模型
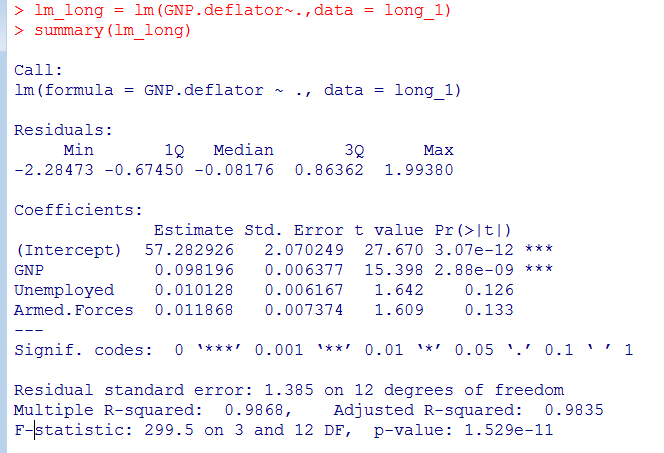
可以看到此回归模型自变量Uemployed,Armed.Froces没有很好地拒绝假设检验。
3.2 使用step函数逐步回归分析
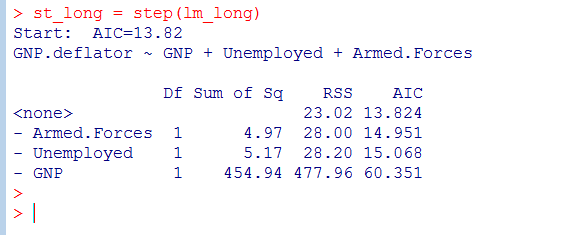
逐步回归分析显示减去Armed.Forces和Uemployed变量,对AIC的影响不大
3.3 去掉Armed.Forces和Uemployed的线性模型
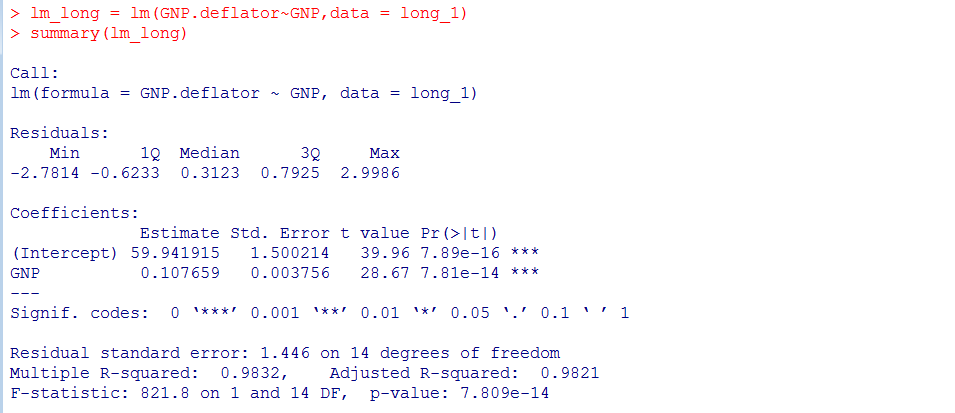
以上线性回归模型截距与回归系数均有3颗*,很好的拒绝了假设检验。
同时线性相关系数平方:0.9832,模型线性程度非常高。
4. 样本回归诊断
4.1 样本正态分布假设检验
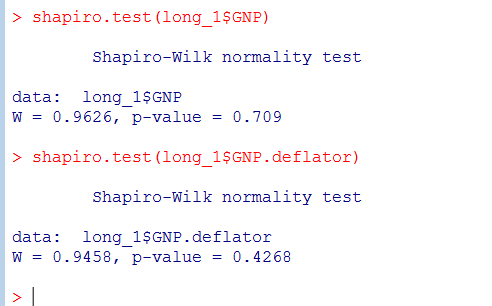
由正态假设检验可得:自变量GNP的p值>0.5接受了假设检验,符合正态分布;
因变量GNP.deflator的 p值 = 0.4268<0.5,具有较强统计学意义,拒绝了假设检验。
4.2 残差分析

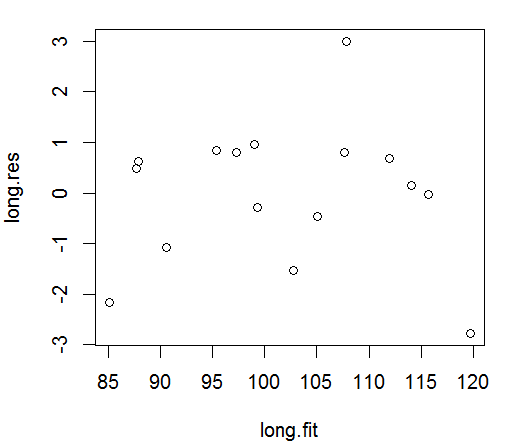
结论:
线性回归模型 lm(formula = GNP.deflator ~ GNP, data =long_1)符合正态分布假设,误差满足独立性,等方差,不存在多重共线性。
回归系数Pr值很小,拒绝假设检验(假设系数不正确),相关系数十分接近1。
综上,该线性模型合理。
【题目3】 (可选)对课程幻灯片里的top1000 sites(数据集上传在课程资源里)分析进行改进,使到带pageviews的预测模型的检验指标比幻灯片里所显示的更加理想
1. 读入top_1000数据集

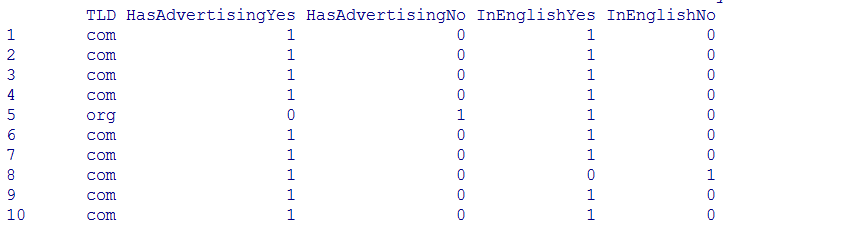
2. 定义哑变量

3. 多元线性回归分析
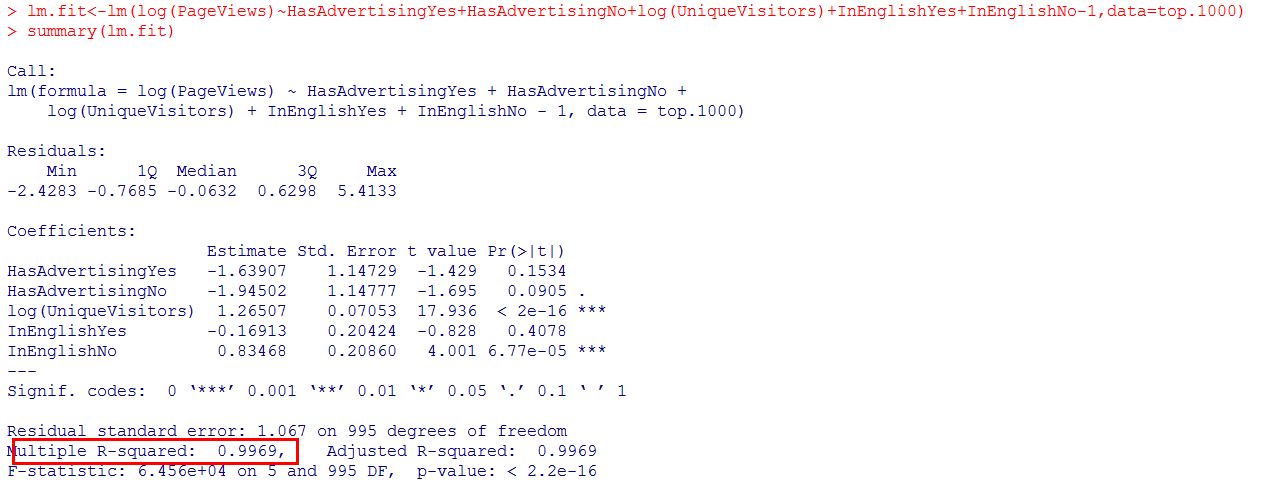
无截距多元线性回归模型:
formula= log(PageViews) ~ HasAdvertisingYes + HasAdvertisingNo+ log(UniqueVisitors) +InEnglishYes + InEnglishNo – 1
该回归模型相关系数平方:0.9969,数据令人满意。但是自变量中有多余变量。
4. 逐步回归分析
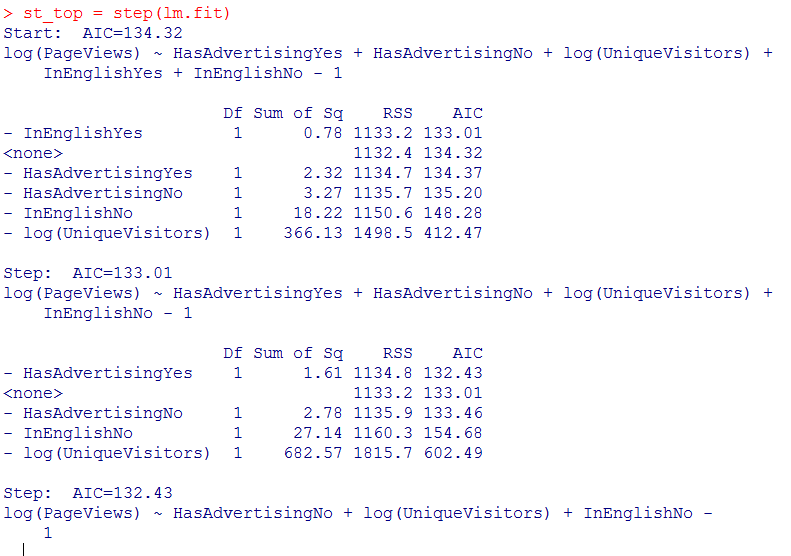
逐步回归分析结果:
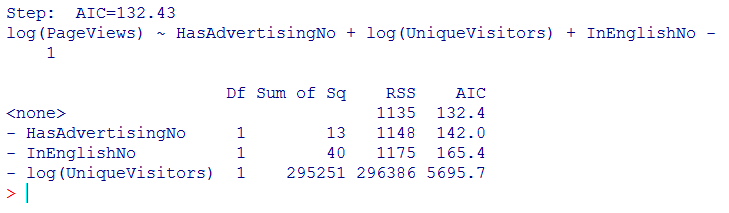
根据逐步回归分析结果编写新模型:
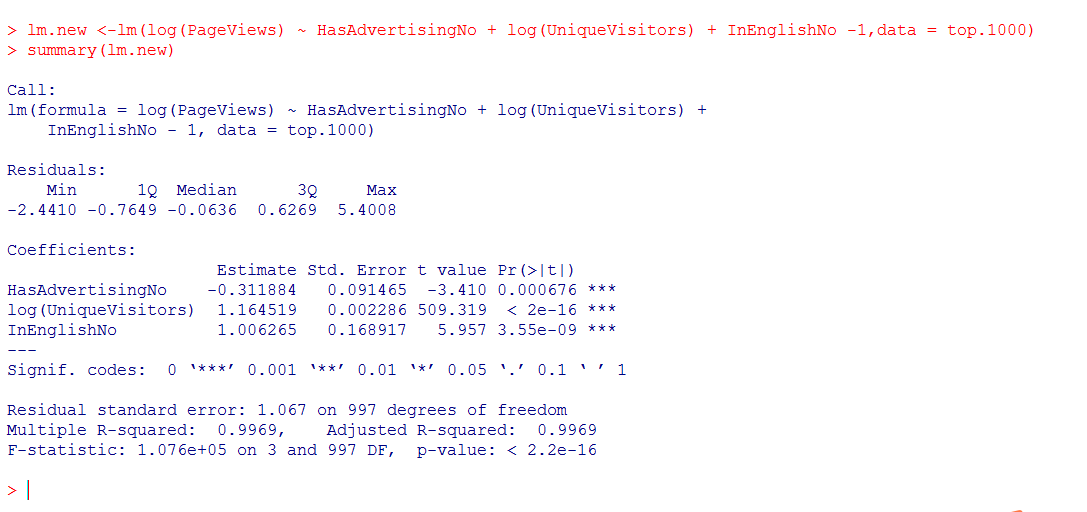
5. 结论:
log(PageView)~1.164519*log(UniqueVisitors) + 1.006265*InEnglishNo-
0.311884*HasAdvertisingNo
各自变量拒绝系数不正确的假设检验,Multiple R-squared结果高达0.9969。
该模型相较于课堂所讲模型,更具合理性!














 2836
2836











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









