






文章目录
本文是笔者进行神经网络学习的个人学习日记
图片和链接均源自网络,侵删
1 BERT
BERT的预训练阶段包括两个任务,一个是Masked Language Model,还有一个是Next Sentence Prediction。
1.1 Masked Language Model
MLM可以理解为完形填空,会随机mask每一个句子中15%的词,用其上下文来做预测,例如:my dog is hairy → my dog is [MASK]
但是该方法有一个问题,因为是mask15%的词,其数量已经很高了,这样就会导致某些词在fine-tuning阶段从未见过,为了解决这个问题,作者做了如下的处理:
- 80%的时间是采用[mask]:
my dog is hairy → my dog is [MASK] - 10%的时间是随机取一个词来代替mask的词:
my dog is hairy -> my dog is apple - 10%的时间保持不变:
my dog is hairy -> my dog is hairy
在任何一个词都有可能是被替换掉的条件下,强迫模型在编码当前时刻不能太依赖于当前的词,而是要考虑它的上下文,甚至根据上下文进行纠错。
1.2 Next Sentence Prediction
选择一些句子对A与B,其中50%的数据B是A的下一条句子,剩余50%的数据B是语料库中随机选择的,学习其中的相关性。其输入形式是,开头是一个特殊符号[CLS],然后两个句子之间用[SEP]隔断,例如:
- Input = [CLS] the man went to [MASK] store [SEP]he bought a gallon [MASK] milk [SEP]
Label = IsNext - Input = [CLS] the man [MASK] to the store [SEP]penguin [MASK] are flight ##less birds[SEP]
Label = NotNext
1.3 输入
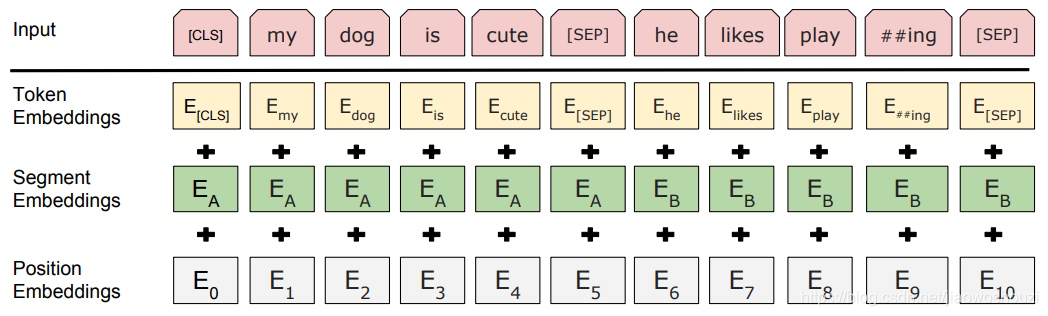
BERT的输入可以是单一的一个句子或者是句子对,输入词向量是三个向量之和:
- Token Embedding:WordPiece tokenization subword词向量。
- Segment Embedding:表明这个词属于哪个句子(NSP需要两个句子)。
- Position Embedding:学习出来的embedding向量。
1.4 输出
- last_hidden_state:
torch.FloatTensor类型的,最后一个隐藏层的序列的输出。大小是(batch_size, sequence_length, hidden_size),sequence_length是我们截取的句子的长度,hidden_size是768。 - pooler_output:
torch.FloatTensor类型的,[CLS]的这个token的输出,输出的大小是(batch_size, hidden_size)。 - hidden_states:
tuple(torch.FloatTensor),这是输出的一个可选项,如果输出,需要指定config.output_hidden_states=True,它也是一个元组,它的第一个元素是embedding,其余元素是各层的输出,每个元素的形状是(batch_size, sequence_length, hidden_size)。 - attentions:这也是输出的一个可选项,如果输出,需要指定
config.output_attentions=True,它也是一个元组,它的元素是每一层的注意力权重,用于计算self-attention heads的加权平均值。
2 Longformer
传统的Transformer模型由于其自注意力机制,处理长序列时会遇到计算和内存效率的问题。具体来说Transformer的自注意力机制计算复杂度为 O ( n 2 ) O(n^2) O(n2)。因此,当序列变长时,计算量和内存需求都会显著增加,难以处理长文本数据。
Longformer通过引入稀疏注意力机制解决了这一问题,使其能够处理更长的文本序列。
2.1 稀松注意力机制
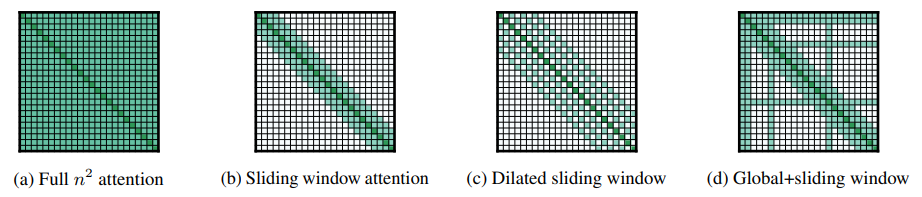
Longformer通过限制每个位置只关注一部分位置,从而降低计算复杂度。主要有以下几种稀疏模式:
-
滑动窗口注意力(Sliding Window Attention):
每个位置只关注其局部窗口内的固定数量位置。例如,一个窗口大小为 w w w的局部窗口注意力机制意味着每个位置只关注其前后 w / 2 w/2 w/2个位置。主要用于构建上下文表示。
-
膨胀滑动窗口(Dilated Sliding Window):
对于Sliding Window,其顶层接受域是 l × w l\times w l×w,如果要增加接受域,可以使用“膨胀”的方法,在窗口之间设置一个gap,大小为 d d d,则接受域就变成了 l × d × w l\times d\times w l×d×w。
-
全局注意力(Global Attention):
对于某些特定的位置,如序列开头的[CLS]标记或一些特别重要的标记,可以使用全局注意力,使这些位置能够关注整个序列中的所有位置。
2.2 注意力计算
初始化的过程与自注意力相似,输入序列X经过线性变换得到Q、K、V:
Q
=
X
W
Q
,
K
=
X
W
K
,
V
=
X
W
V
Q = XW_Q, \quad K = XW_K, \quad V = XW_V
Q=XWQ,K=XWK,V=XWV
2.2.1 滑动窗口注意力
对于每个位置
i
i
i,只计算其局部窗口内的注意力得分:
Attention
local
(
Q
i
,
K
j
,
V
j
)
=
softmax
(
Q
i
K
j
T
d
k
)
V
j
\text{Attention}_{\text{local}}(Q_i, K_j, V_j) = \text{softmax}\left( \frac{Q_i K_j^T}{\sqrt{d_k}} \right) V_j
Attentionlocal(Qi,Kj,Vj)=softmax(dkQiKjT)Vj
其中,
j
j
j在窗口
[
i
−
w
/
2
,
i
+
w
/
2
]
[i-w/2, i+w/2]
[i−w/2,i+w/2]内。
2.2.2 全局注意力
对于选定的全局注意力位置
g
g
g,计算其与所有位置的注意力得分:
Attention
global
(
Q
g
,
K
,
V
)
=
softmax
(
Q
g
K
T
d
k
)
V
\text{Attention}_{\text{global}}(Q_g, K, V) = \text{softmax}\left( \frac{Q_g K^T}{\sqrt{d_k}} \right) V
Attentionglobal(Qg,K,V)=softmax(dkQgKT)V
合并注意力结果:将局部窗口注意力和全局注意力的结果合并,得到最终的注意力输出。
2.3 Longformer-Encoder-Decoder(LED)
Longformer-Encoder-Decoder(LED)是一种改进的 Transformer 架构,旨在处理长序列的生成任务,例如摘要生成和翻译。它在原始 Transformer 的编码器-解码器架构基础上进行了修改,以支持更长的输入序列。
- 编码器:LED的编码器部分采用了 Longformer 的局部+全局注意力模式。
- 解码器:解码器部分则仍然采用全自注意力机制。
3 大语言模型
大语言模型是深度学习的一个分支。使用的是Transformer架构,可以通过微调在特定的下游任务上进一步训练,适应具体任务需求。
3.1 指令微调
一种提高模型在各种任务上表现的策略是指令微调。例如,如果想提高模型的摘要能力,应该构建一个包含摘要指令和相关文本的数据集。在翻译任务中,应包含“翻译这段文本”等指令。这些提示有助于让模型以新的专业方式“思考”,并服务于特定任务。
3.2 全微调(FFT)
即更新模型所有权重的过程,被称为全微调。会产生一个具有更新权重的新模型版本。需要注意的是,与预训练一样,全微调需要足够的内存和计算预算来存储和处理训练过程中的所有梯度、优化器和其他更新组件。
3.3 参数高效微调(PEFT)
PEFT(Parameter-Efficient Fine-Tuning)技术旨在通过最小化微调参数的数量和计算复杂度,来提高预训练模型在新任务上的性能,从而缓解预训练模型的训练成本。因此,PEFT技术可以在提高模型效果的同时,大大缩短模型训练时间和计算成本,让更多人能够参与到深度学习研究中来。
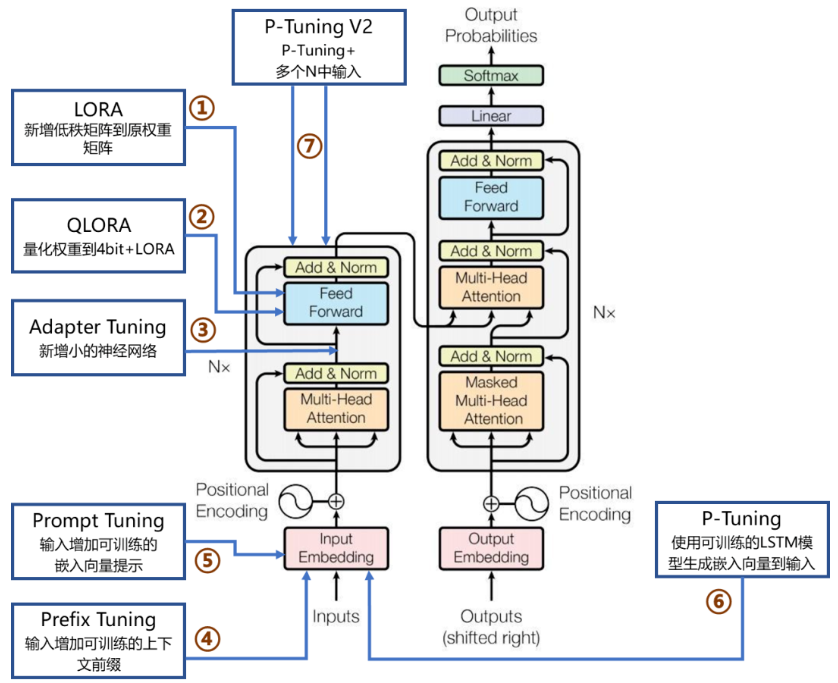
PEFT技术包括LORA、QLoRA、Adapter Tuning、Prefix Tuning、Prompt Tuning、P-Tuning及P-Tuning v2等。
-
适配器调优(Adapter Tuning):
在每一层Transformer中插入小型适配器模块,只微调这些适配器的参数,而保持原始模型参数不变。这些适配器通常是一些小型的前馈神经网络,它们通过调整特定层的输出来适应特定任务。
-
低秩适应(Low-Rank Adaptation, LoRA):
这种方法通过在预训练模型的特定层中添加低秩矩阵,只微调这些低秩矩阵的参数。这种方法利用了低秩矩阵能够有效捕捉数据的低维结构,从而实现参数高效的微调。
-
偏置微调(BitFit):
只调整模型中的偏置参数,而保持权重参数不变。虽然只调整了少量参数,但在许多任务中,这种方法已经证明能够取得良好的效果。
-
前缀调优(Prefix Tuning):
在输入序列的前面添加一些可学习的前缀,并且只微调这些前缀参数。这种方法适用于生成任务和需要长序列输入的任务。
-
提示调优(Prompt Tuning):
类似于Prefix Tuning,但在输入序列的特定位置插入可学习的提示词,并且只微调这些提示词的参数。这种方法特别适用于少样本学习和零样本学习任务。
2024年大语言模型(LLM)微调方法最全总结!_大模型微调:https://blog.csdn.net/weixin_59191169/article/details/138133132
一文读懂大语言模型:https://blog.csdn.net/m0_49711991/article/details/135752379
个人神经网络学习日记:
【神经网络学习日记(1)】神经网络基本概念
【神经网络学习日记(2)】全连接神经网络(FCNN)及Pytorch代码实现
【神经网络学习日记(3)】卷积神经网络(CNN)
【神经网络学习日记(4)】循环神经网络(RNN、LSTM、BiLSTM、GRU)
【神经网络学习日记(5)】数据加载器(DataLoader)的调用
【神经网络学习日记(6)】Transformer结构详解
【神经网络学习日记(7)】Transformer的应用(BERT、Longformer、LLM)
【神经网络学习日记(8)】一些图神经网络的简单介绍(GCN、GAT、rGCN)
文中引用部分都尽可能写出了,如果有侵犯其他人文章版权的问题,请务必联系我,谢谢!


















 776
776

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









