










Prototypical Networks for Few-shot Learning
- 论文链接:https://arxiv.org/abs/1703.05175
- 开源代码:https://github.com/jakesnell/prototypical-networks
- 发表时间:2017年6月
- 该论文属于metric_based
- 论文中心思想:经过神经网络学会一个映射,将所有样本映射到同一空间,每个类别样本存在一个原型(我理解就是每个聚类的中心),该原型就是对应类别所有样本embedding的均值。局里度量是欧式距离的平方,训练时,每个query set中样本embedding到所属类别的原型距离越近越好,到其他类别原型距离越远越好。
- 论文创新点:原型(即class_level representation)
- 算法结构
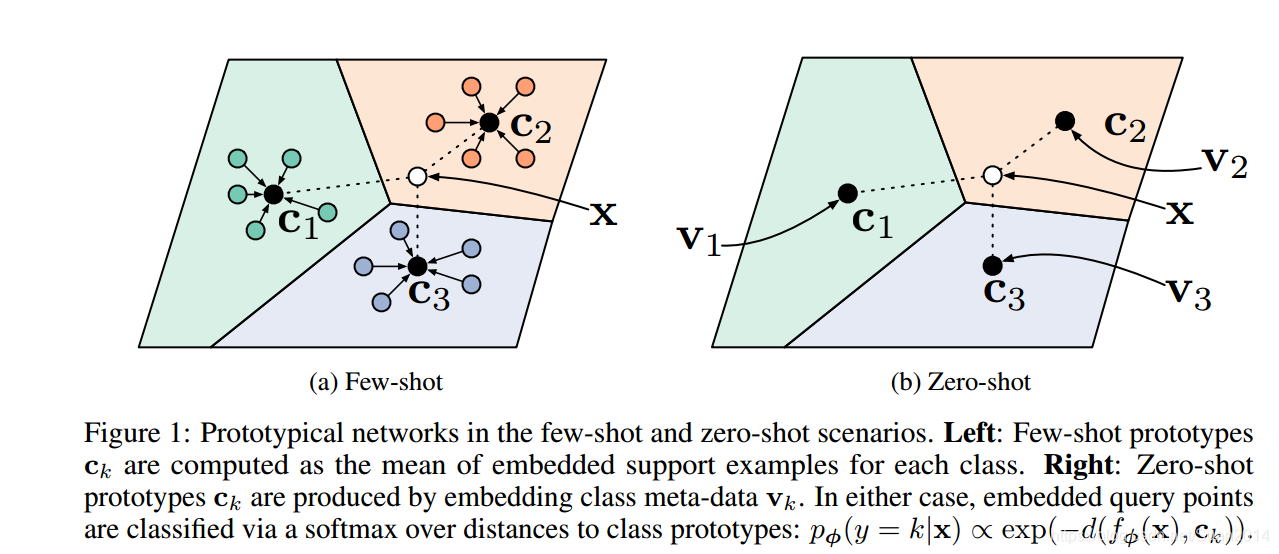

注:上如图J更新公式有一处错误,最后的 c k c_k ck应该为 c k ′ c_{k'} ck′。 - loss函数:
p ϕ ( y = k ∣ x ) = e x p ( − d ( f ϕ ( x ) , c k ) ) ∑ k ′ e x p ( − d ( f ϕ ( x ) , c k ′ ) ) p_{\phi}(y=k|x)=\frac{exp(-d(f_{\phi}(\mathbf{x}),\mathbf{c}_k))}{\sum_{k'}exp(-d(f_{\phi}(\mathbf{x}),\mathbf{c}_{k'}))} pϕ(y=k∣x)=∑k′exp(−d(fϕ(x),ck′))exp(−d(fϕ(x),ck))
J ( ϕ ) = − l o g p ϕ ( y = k ∣ x ) J(\phi)=-logp_{\phi}(y=k|x) J(ϕ)=−logpϕ(y=k∣x)
Hybrid Attention-Based Prototypical Networks for Noisy Few-Shot Relation Classification
- 论文链接:https://gaotianyu1350.github.io/assets/aaai2019_hatt_paper.pdf
- 开源代码:https://github.com/thunlp/HATT-Proto
- 发表时间:2019年
- 该论文属于metric_based
- 论文中心思想:该论文是基于NLP的,包括三大模块:1)Instance Encoder模块:输入为一句文本,将其编码为一个向量;2)Prototypical Networks:基于模块1)为support set中的每个instance(sentence)计算一个embedding,输入到Prototypical Networks,为每个Relation(分类中是每个类)计算一个原型(原型的概念参看上篇论文);3)Hybrid Attention:该模块是模块2)的一部分,通常计算原型时是直接对support set中每个instance的embedding求和或求均值,这样易受噪声影响,该模块提出了两种注意力机制,一个是instance-level注意力,利用注意力机制给每个instance赋予不同权重,然后求原型;另外一种是feature-level注意力机制,用于识别对分类有辨别力的特征维度。
- 论文创新点:混合注意力机制:1)instance-level注意力机制:降低噪声样本影响,同时选出对query判别游泳的instance;2)feature-level注意力机制:选出对任务有用的特征维度。
- 算法结构:

- loss函数:
-
p
ϕ
(
y
=
r
i
∣
x
)
=
e
x
p
(
−
d
(
f
ϕ
(
x
)
,
c
i
)
)
∑
j
′
e
x
p
(
−
d
(
f
ϕ
(
x
)
,
c
j
′
)
)
p_{\phi}(y=r_i|x)=\frac{exp(-d(f_{\phi}(\mathbf{x}),\mathbf{c}_i))}{\sum_{j'}exp(-d(f_{\phi}(\mathbf{x}),\mathbf{c}_{j'}))}
pϕ(y=ri∣x)=∑j′exp(−d(fϕ(x),cj′))exp(−d(fϕ(x),ci))
J ( ϕ ) = − l o g p ϕ ( y = k ∣ x ) J(\phi)=-logp_{\phi}(y=k|x) J(ϕ)=−logpϕ(y=k∣x)
Few-Shot Text Classification with Induction Network
- 论文链接:https://arxiv.org/abs/1902.10482?context=cs.CL
- 开源代码:论文中说会公开代码和数据,目前还未找到
- 发表时间:2019年2月
- 该论文属于metric_based
- 论文中心思想:该论文是基于NLP的,包括三大模块:1)Encoder模块:利用带有self-attention的Bi-LSTM对输入的文本进行编码;2)Induction模块:每个sample经过模块1)得到sample-level representation, 该模块采用Dynamic Routing Induction,将sample-level 的representation转换为class-level representation,即求出每个类的feature(对应于上篇论文中的原型);3)Relation模块:计算每个query set中的样本和每个类的关系得分。
- 论文创新点:多数算法求每个类的class-level特征是取该类中所有样本特征的和或均值,这样noise样本会影响该类的特征表达;本论文提出的induction模块采用dynamic routing算法能够保护每个类的深度语义表达,同时减轻noise样本影响。
- 算法结构:
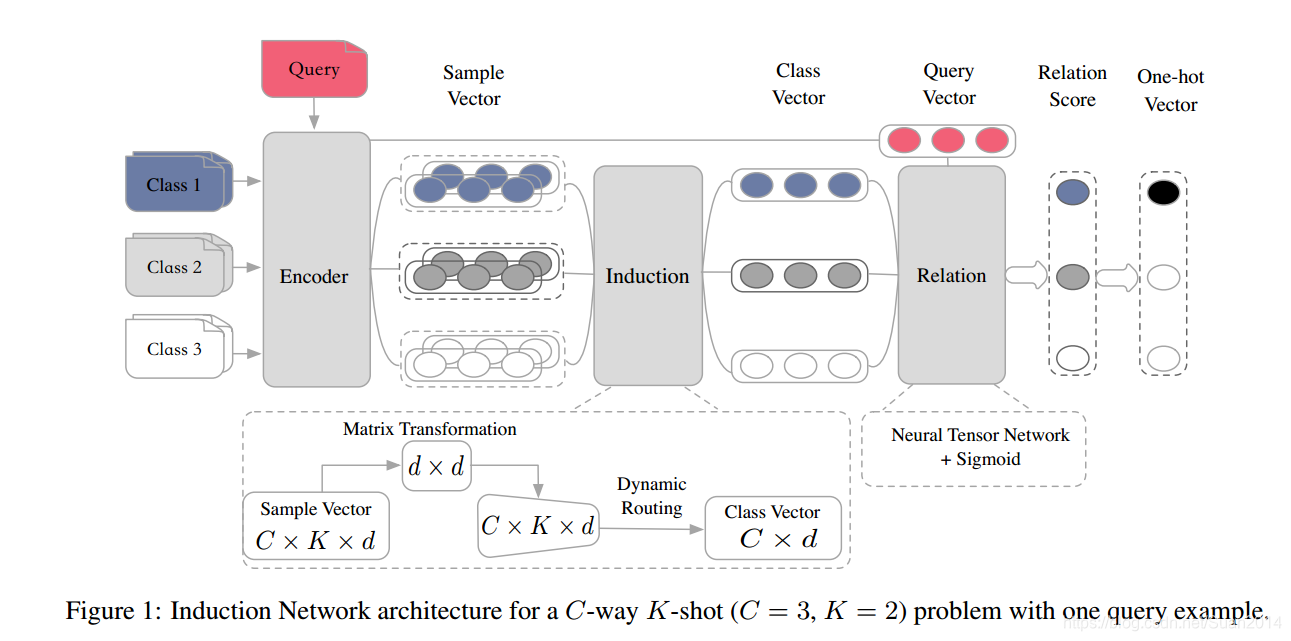

- loss函数:MSE
J = ∑ i = 1 C ∑ q = 1 n ( r i q − 1 ( i = = y q ) ) 2 J =\sum_{i=1}^C\sum_{q=1}^n(r_{iq}-\mathbf{1}(i==y_q))^2 J=i=1∑Cq=1∑n(riq−1(i==yq))2
i i i表示低 i i i类, q q q表示第 q q q个样本, r i q r_{iq} riq表示网络输出的得分, y q y_q yq表示第 q q q个样本的标签。
Learning to Compare: Relation Network for Few-Shot Learning
- 论文链接:https://arxiv.org/abs/1711.06025
- 开源代码:https://github.com/floodsung/LearningToCompare_FSL (Few-shot) https://github.com/lzrobots/LearningToCompare_ZSL (zero-shot)
- 发表时间:2018年3月
- 该论文属于metric_based
- 论文是针对Relation 模块进行创新的,详细请参看Learning to Compare: Relation Network for Few-Shot Learning论文笔记















 3582
3582











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











