






原文章 A Tutorial on Clustering Algorithms,包含以下部分:
本文为 K-means 翻译内容,后续内容请直接点击以上链接(☑为已完成内容)。
本文系Subson翻译,转载请注明。
K-means聚类
算法介绍
K-means是最简单的解决众所周知的聚类问题的无监督学习算法之一。通过设定一个必要的族簇数量(假设族簇数量为
k
)作为先验知识可以非常简单而已容易地将给定数据分类。其主要思想是定义
最终,这个算法的目的是最小化目标函数,即平方差方程。这个目标函数是
其中 ∥∥x(j)i−cj∥∥2 是所选择的数据点 x(j)i 和族簇中心 cj 之间的距离度量,是各自族簇中心的 n 个数据点的距离指标。
该算法由下列步骤组成:
- 将
K 个点放入空间作为族簇对象的代表。这些点代表初始的族簇圆心。- 将每一个对象分配给其最近的圆心的族簇。
- 当全部对象分配完毕,重新计算 K 个圆心的位置。
- 重复第2步和第3步直到圆心不再移动。这种对象分隔使得所采用的度量计算最小化。
尽管它被证明这个过程总是能够停止,K-means算法并不能一定找到最佳结构,即相应的全局目标函数最小解。该算法也对随机初始化族簇中心较为敏感。K-means算法可以多次运行以减小这个影响。
K-means是一个可以适用于多种问题领域的简单算法。正如我们将看到的,它是作用于模糊特征向量的很好的扩展。
示例
假设我们有
- 初始化均值 x1,x2,...,xk
- 执行下列步骤直到任何均值不再改变
- 用估计的均值分类样本到各族簇中
- 从
1
到
k 循环 i 执行下列代码 - 用族簇
i 的所有样本的均值代替 mi - 结束循环
- 结束循环
这里有一个例子显示两个族簇的均值 m1 和 m2 是如何移动到中心的。
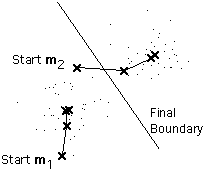
备注
这是简单版的K-means聚类过程。它展示的是以最小化到族簇中心距离的平方和来分隔
n
个样本到
- 初始化均值的方式不是指定的。一个普遍被接受的方法是随机选择样本的 k 值。
- 该过程的结果取决于均值的初始值,经常产生次优的划分。标准的解决方案是从不同的开始点尝试数值。
- 可能造成最接近族簇中心点
mi 的样本集合为空,所以 mi 并不能被更新。这种我们忽略的烦恼在实施过程中必须处理。 - 结果取决于使用的 ∥x−mi∥2 度量。一个被普遍采用的方案是通过标准差去标准化每个变量,尽管这种方法并不是总令人满意。
- 结果取决于 k 的值。
最后一个问题特别麻烦,即我们经常没有途径知道有多少个族簇存在。如上面的例子所示,采用同样的算法遵循3个均值的聚类应用于同样的数据,得到的结果相较于2个均值的聚类孰好孰坏?
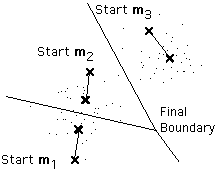
不幸的是没有一般理论化的解决方案用于找到任何给定数据集的最佳族簇数量。一个简单的方法是比较采用不同
后续章节待续。。。
本文系Subson翻译,转载请注明。















 1658
1658

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









