概述
ConcurrentHashMap 是将锁的范围细化来实现高效并发的。 基本策略是将数据结构分为一个一个 Segment(每一个都是一个并发可读的 hash table, 即分段锁)作为一个并发单元。 为了减少开销, 除了一处 Segment 是在构造器初始化的, 其他都延迟初始化(详见 ensureSegment)。 并使用 volatile 关键字来保证 Segment 延迟初始化的可见性问题。
HashMap 不是线程安全的, 故多线程情况下会出现 infinit loop。 HashTable 是线程安全的, 但是是用全局锁来保障, 效率很低。 所以 Doug Lea 并发专家研发了高效并发的 ConcurrentHashMap 来应对并发情况下的情景。 阅读本文前最好先看:
Java 内存模型 和
AtomicInteger 分析。
一. 术语定义
| 术语 | 英文 | 解释 |
|---|
| 哈希算法 | hash algorithm | 是一种将任意内容的输入转换成相同长度输出的加密方式,其输出被称为哈希值。 |
| 哈希表 | hash table | 根据设定的哈希函数H(key)和处理冲突方法将一组关键字映象到一个有限的地址区间上,并以关键字在地址区间中的象作为记录在表中的存储位置,这种表称为哈希表或散列,所得存储位置称为哈希地址或散列地址。 |
二. 数据结构
类图:
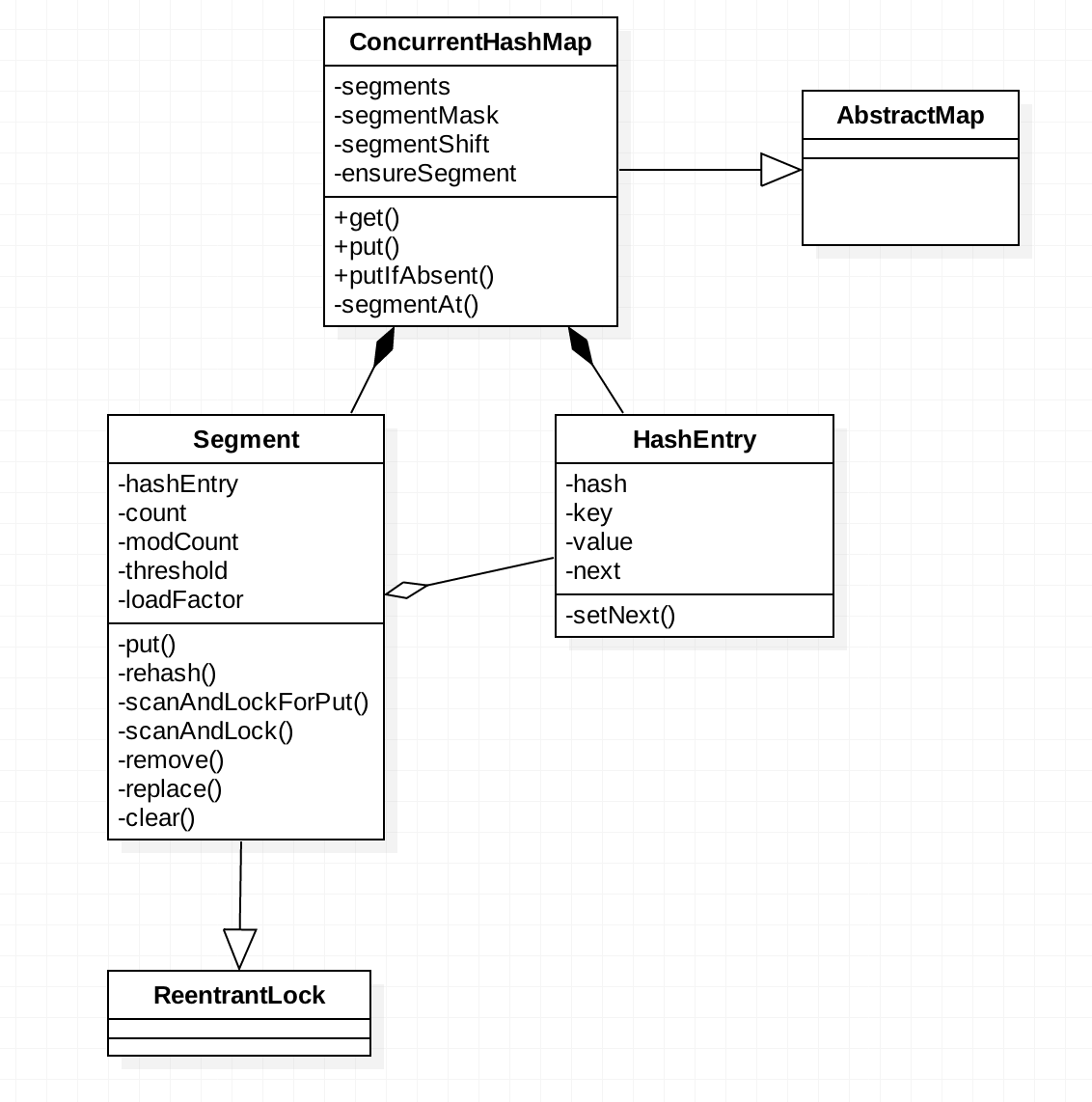
抽象结构图:
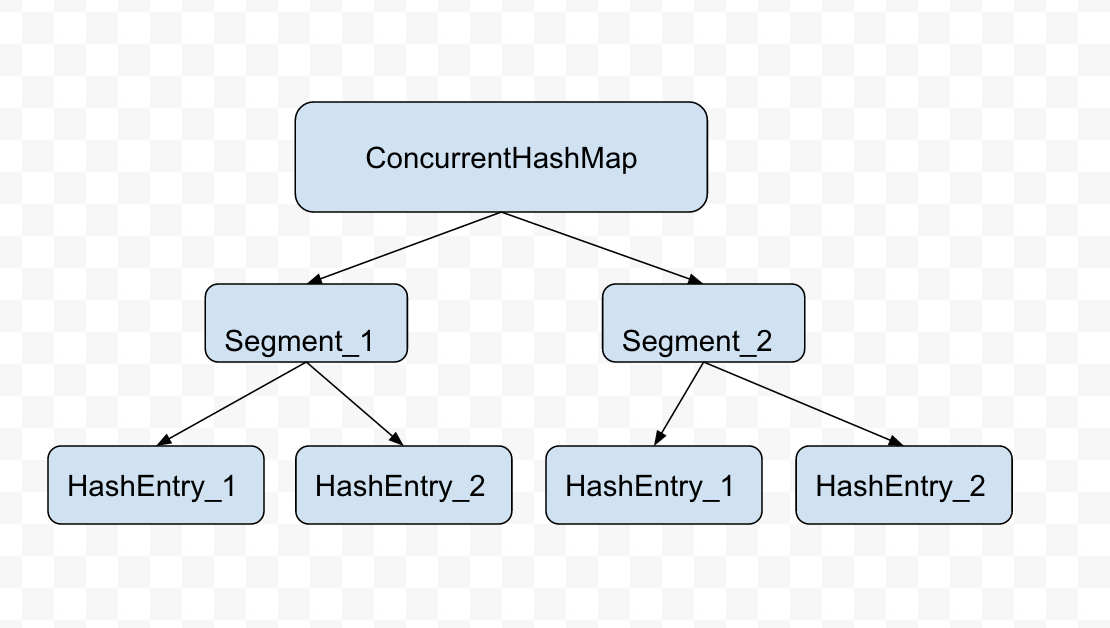
从上述类图和抽象结构图可以看出 ConcurrentHashMap 是由 Segment 数组结构和 HashEntry 数组结构组成。Segment 继承(Generalization)了可重入锁ReentrantLock,HashEntry 用于存储键值对数据。一个 ConcurrentHashMap 里 contains-a
(
Composition
)
一个 Segment []
,Segment 的结构和 HashMap 类似,是一种数组和链表结构, 一个 Segment 里 has-a (Aggregation
)一个 HashEntry 数组,每个 HashEntry 是一个链表结构的元素, 每个 Segment 锁定一个 HashEntry 数组里的元素, 当对 HashEntry 数组的数据进行 put 等修改操作时,必须先获得它对应的 Segment 锁。
三. 源码解析
内部类 Segment 类:
Segment 维护着条目列表状态一致性, 所以可以实现无锁读。 在表超出 threshold 进行 resize 的时候, 复制节点, 所以在做 resize 修改操作的时候, 还可以进行读操作(在旧 list 读)。 本类里只有变化操作的方法才需要加锁, 变化的方法利用一系列忙等控制来处理资源争用, 例如 scanAndLock 和
scanAndLockForPut 。 那些遍历去查找节点的 tryLocks() 方法, 主要是用来吸收 cached 不命中(在 hash tables 经常出现), 这样后续获取锁的遍历操作效率将会有不小提升。 我们可能不是真的需要使用找到的数据, 因为重新获得数据还需要加锁来保证更新操作的一致性, 但他们会更快地进行重定位。 此外, scanAndLockForPut 特地创建新数据用于没有数据被找到的 put 方法。
-
-
- static final int MAX_SCAN_RETRIES =
- Runtime.getRuntime().availableProcessors() > 1 ? 64 : 1;
-
-
-
-
-
- transient volatile HashEntry<K,V>[] table;
-
-
-
-
-
- transient int count;
-
-
-
-
- transient int modCount;
-
-
-
-
-
-
- transient int threshold;
-
-
-
-
-
-
-
- final float loadFactor;
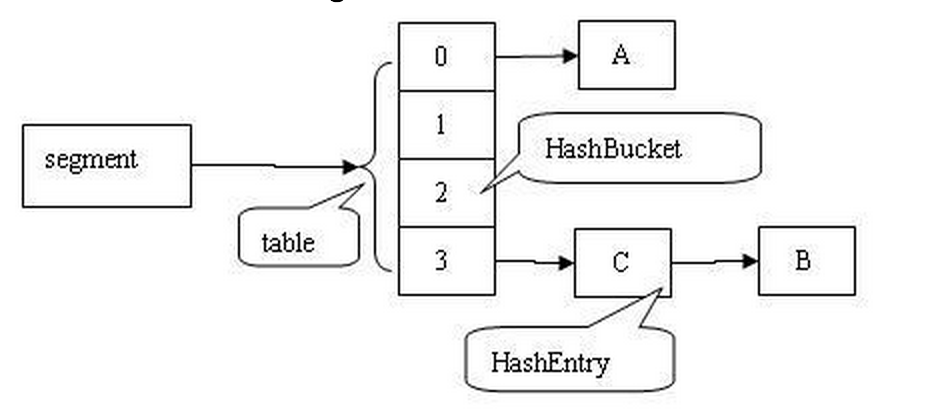
put 方法:
插入A, B, C后 Segment 示意图:
- final V put(K key, int hash, V value, boolean onlyIfAbsent) {
-
- HashEntry<K,V> node = tryLock() ? null :
- scanAndLockForPut(key, hash, value);
- V oldValue;
- try {
- HashEntry<K,V>[] tab = table;
- int index = (tab.length - 1) & hash;
-
- HashEntry<K,V> first = entryAt(tab, index);
- for (HashEntry<K,V> e = first;;) {
- if (e != null) {
- K k;
- if ((k = e.key) == key ||
- (e.hash == hash && key.equals(k))) {
-
- oldValue = e.value;
- if (!onlyIfAbsent) {
-
- e.value = value;
-
- ++modCount;
- }
- break;
- }
-
- e = e.next;
- }
- else {
- if (node != null)
- node.setNext(first);
- else
- node = new HashEntry<K,V>(hash, key, value, first);
- int c = count + 1;
-
- if (c > threshold && tab.length < MAXIMUM_CAPACITY)
- rehash(node);
- else
- setEntryAt(tab, index, node);
- ++modCount;
- count = c;
- oldValue = null;
- break;
- }
- }
- } finally {
-
- unlock();
- }
- return oldValue;
- }
rehash() 方法: 在新 table 中重新分类节点。 因为使用了 2 的幂指数扩展方式, bucket/bin 中的数据还是在原位, 即旧数据的索引位置不变或者偏移了 2 的幂指数距离。 可以重用旧节点减少不必要的节点生成。
-
-
-
- @SuppressWarnings("unchecked")
- private void rehash(HashEntry<K,V> node) {
-
- HashEntry<K,V>[] oldTable = table;
- int oldCapacity = oldTable.length;
- int newCapacity = oldCapacity << 1;
- threshold = (int)(newCapacity * loadFactor);
- HashEntry<K,V>[] newTable =
- (HashEntry<K,V>[]) new HashEntry[newCapacity];
- int sizeMask = newCapacity - 1;
- for (int i = 0; i < oldCapacity ; i++) {
- HashEntry<K,V> e = oldTable[i];
- if (e != null) {
- HashEntry<K,V> next = e.next;
- int idx = e.hash & sizeMask;
- if (next == null)
- newTable[idx] = e;
- else {
- HashEntry<K,V> lastRun = e;
- int lastIdx = idx;
- for (HashEntry<K,V> last = next;
- last != null;
- last = last.next) {
- int k = last.hash & sizeMask;
- if (k != lastIdx) {
- lastIdx = k;
- lastRun = last;
- }
- }
- newTable[lastIdx] = lastRun;
-
- for (HashEntry<K,V> p = e; p != lastRun; p = p.next) {
- V v = p.value;
- int h = p.hash;
- int k = h & sizeMask;
- HashEntry<K,V> n = newTable[k];
- newTable[k] = new HashEntry<K,V>(h, p.key, v, n);
- }
- }
- }
- }
- int nodeIndex = node.hash & sizeMask;
- node.setNext(newTable[nodeIndex]);
- newTable[nodeIndex] = node;
- table = newTable;
- }
内部类 HashEntry:链表结构
- static final class HashEntry<K,V> {
-
- final int hash;
- final K key;
-
- volatile V value;
- volatile HashEntry<K,V> next;
-
- HashEntry(int hash, K key, V value, HashEntry<K,V> next) {
- this.hash = hash;
- this.key = key;
- this.value = value;
- this.next = next;
- }
-
-
-
-
- final void setNext(HashEntry<K,V> n) {
- UNSAFE.putOrderedObject(this, nextOffset, n);
- }
-
-
- static final sun.misc.Unsafe UNSAFE;
- static final long nextOffset;
- static {
- try {
- UNSAFE = sun.misc.Unsafe.getUnsafe();
- Class k = HashEntry.class;
- nextOffset = UNSAFE.objectFieldOffset
- (k.getDeclaredField("next"));
- } catch (Exception e) {
- throw new Error(e);
- }
- }
- }
ConcurrentHashMap 类:
-
-
-
-
-
-
- static final int DEFAULT_INITIAL_CAPACITY = 16;
-
-
-
-
-
- static final float DEFAULT_LOAD_FACTOR = 0.75f;
-
-
-
-
-
- static final int DEFAULT_CONCURRENCY_LEVEL = 16;
-
-
-
-
-
-
-
- static final int MAXIMUM_CAPACITY = 1 << 30;
-
-
-
-
-
-
- static final int MIN_SEGMENT_TABLE_CAPACITY = 2;
-
-
-
-
-
- static final int MAX_SEGMENTS = 1 << 16;
-
-
-
-
-
-
-
- static final int RETRIES_BEFORE_LOCK = 2;
-
-
-
- final int segmentMask;
-
-
-
-
- final int segmentShift;
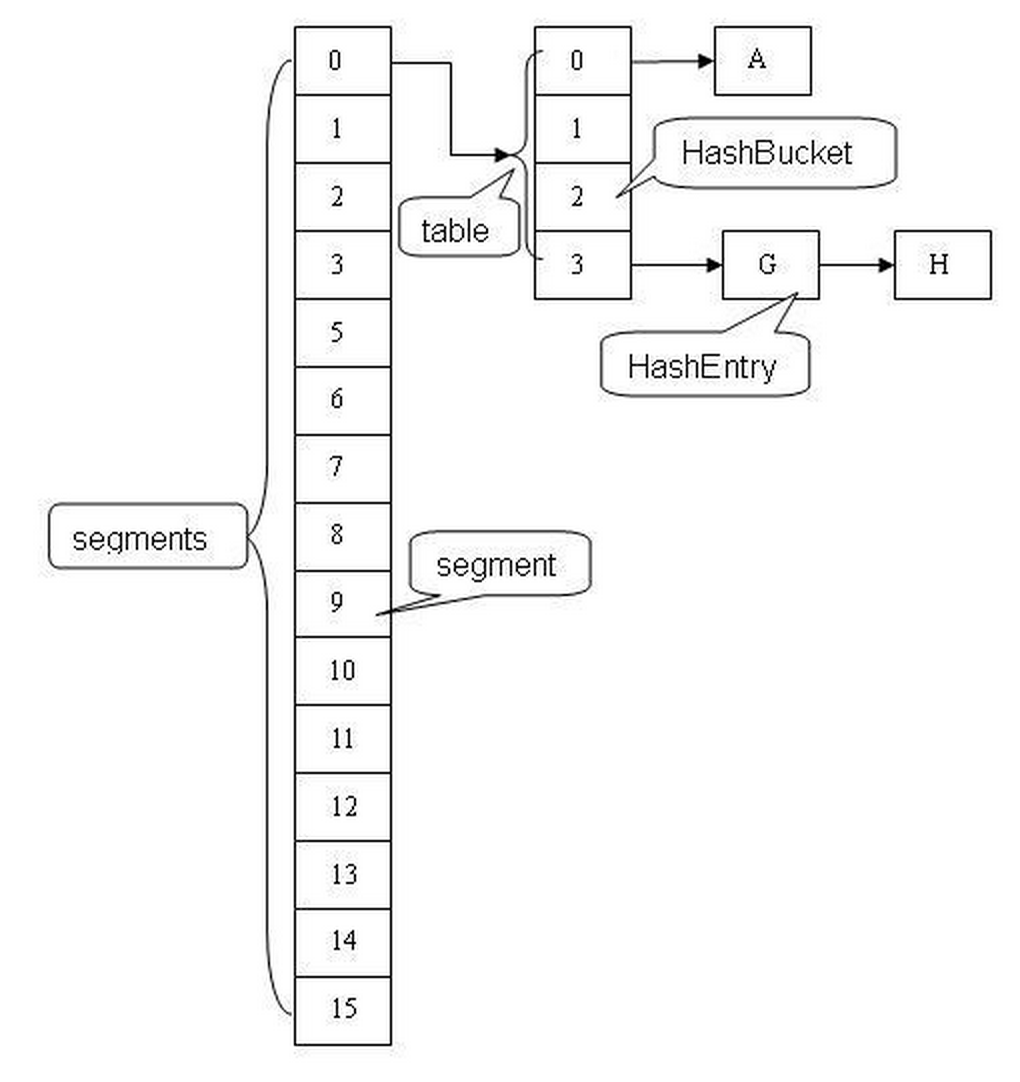
初始化 ConcurrentHashMap:
ConcurrentHashMap 结构图
- public ConcurrentHashMap(int initialCapacity,
- float loadFactor, int concurrencyLevel) {
- if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0)
- throw new IllegalArgumentException();
- if (concurrencyLevel > MAX_SEGMENTS)
- concurrencyLevel = MAX_SEGMENTS;
-
- int sshift = 0;
- int ssize = 1;
- while (ssize < concurrencyLevel) {
- ++sshift;
- ssize <<= 1;
- }
- this.segmentShift = 32 - sshift;
- this.segmentMask = ssize - 1;
- if (initialCapacity > MAXIMUM_CAPACITY)
- initialCapacity = MAXIMUM_CAPACITY;
- int c = initialCapacity / ssize;
- if (c * ssize < initialCapacity)
- ++c;
- int cap = MIN_SEGMENT_TABLE_CAPACITY;
- while (cap < c)
- cap <<= 1;
-
- Segment<K,V> s0 =
- new Segment<K,V>(loadFactor, (int)(cap * loadFactor),
- (HashEntry<K,V>[])new HashEntry[cap]);
- Segment<K,V>[] ss = (Segment<K,V>[])new Segment[ssize];
- UNSAFE.putOrderedObject(ss, SBASE, s0);
- this.segments = ss;
- }
由上面的代码可知segments数组的长度ssize通过concurrencyLevel计算得出。为了能通过按位与的哈希算法来定位segments数组的索引,必须保证segments数组的长度是2的N次方(power-of-two size),所以必须计算出一个是大于或等于concurrencyLevel的最小的2的N次方值来作为segments数组的长度。假如concurrencyLevel等于14,15或16,ssize都会等于16,即容器里锁的个数也是16。注意concurrencyLevel的最大大小是65535,意味着segments数组的长度最大为65536,对应的二进制是16位。
初始化segmentShift和segmentMask。这两个全局变量在定位segment时的哈希算法里需要使用,sshift等于ssize从1向左移位的次数,在默认情况下concurrencyLevel等于16,1需要向左移位移动4次,所以sshift等于4。segmentShift用于定位参与hash运算的位数,segmentShift等于32减sshift,所以等于28,这里之所以用32是因为ConcurrentHashMap里的hash()方法输出的最大数是32位的,后面的测试中我们可以看到这点。segmentMask是哈希运算的掩码,等于ssize减1,即15,掩码的二进制各个位的值都是1。因为ssize的最大长度是65536,所以segmentShift最大值是16,segmentMask最大值是65535,对应的二进制是16位,每个位都是1。
变量cap就是segment里HashEntry数组的长度,它等于initialCapacity除以ssize的倍数c,如果c大于1,就会取大于等于c的2的N次方值,所以cap不是1,就是2的N次方。segment的容量threshold=(int)cap*loadFactor,默认情况下initialCapacity等于16,loadfactor等于0.75,通过运算cap等于1,threshold等于零。
先写到这, 今天有点累了, ConcurrentHashMap 的 get, put 等方法下次更新...
四. 参考资料
JDK 1.6、 1.7 源码
《并发编程实战》























 574
574

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









