






这篇论文是log structured file system关键论文,后面的leveldb等都有借鉴其设计理念,因此在这里翻译一下。
1.Introduction
CPU的计算速度在过去十年里产生了迅猛的增长,与此同时,磁盘的访问速度却没有多大改观。这种趋势在未来一段时间都将持续,并且会导致越来越多的应用程序受限于磁盘带宽。为了减轻这种问题产生的影响,本文设计了一种称作为"日志式文件系统"的磁盘存储管理技术,它能够比当前文件系统更加高效的使用磁盘。
Log-structured 文件系统是基于文件缓存在内存中这样一种假设,并且随着内存大小的增加,缓存会越来越适应系统的读请求。因此,磁盘贷款将只受限于写速度。Log-structured 文件系统将所有新的信息顺序写入磁盘上称为log的数据结构中。这种方式通过评估所有的寻道操作从而显著的提高了系统的写性能。log的顺序属性也使得系统崩故障复操作更加快速,典型的现有Unix文件系统需要扫描整个磁盘来保证一致性,但是log-structured文件系统只需要检查log中的最近部分。
Logging的概念并不是新出来的,大量的现有文件系统已经使用log作为提高系统写和故障恢复速度的有效结构。但是,这些系统只是利用log作为临时存储,信息的永久性存储则是利用磁盘上的传统随机访问结构。相反,log-structured文件系统将数据永久性的存储在log中,磁盘上并没有别的数据结构。Log包含了索引信息,因此文件能够比当前文件系统更快速的读取出来。
要使得log-structured文件系统能够够高效的运行,需要确保系统一直有大量的空闲空间用于新的数据的写入。这也是设计log-structured文件系统最困难的事情。本文中我们使用了一种称为segement的技术,segment cleaner进程会从严重碎片化的segements中压缩live数据,从而持续性的产生新的空闲segement。我们在一个模拟器中测试了不同的清理策略,并且发现了一个基于耗费和收益的简单但是行之有效的策略:将鲜活的、经常修改的数据与老旧的、修改频率低的数据分开,并且在进行清理的时候差异性对待。
我们构建了一个称为Sprite LFS的log-structured原型系统,已经在Sprite 网络操作系统中投入使用。Benchmark证明Sprite LFS针对小文件的写速度比Unix文件系统要快得多。即使是针对其他的负载,例如包含读和大文件访问的负载,Sprite LFS能够获得不比Unix文件系统差的速度,除了在文件被随机写入后顺序读出的测试中略有不如。我们还测试了系统进行cleaning的性能开销,总的来说,Sprite LFS允许大约60-75%的磁盘带宽进行新的数据写入(剩下的用于cleaning)。与之相对应的是,Unix系统只能使用5-10%的磁盘带宽用于新的数据的写入,剩下的是用于寻道。
剩下的内容分为六个章节。第二节回顾了1990年代计算机文件系统设计的一些问题。第三节讨论了log-structured文件系统设计的一些选择,并且提出了Sprite LFS的结构,并着重关注系统的cleaning策略。第四节描述了Sprite LFS的故障恢复。第五节通过Benchmark对Sprite LFS进行评估,并对cleaning性能开销进行了长时间的测量。第六节对比了Sprite LFS和其他的文件系统,并在第七节进行总结。
2.Design for file Systems of the 1990's
文件系统的设计主要是被两种力量所支配:技术,它提供一系列的基础构建;负载,它决定了需要快速执行的一些列操作。本节总结了一些正在改变的技术并且描述了他们对于文件系统设计的影响。本节还描述了影响Sprite LFS设计的一些负载,并说明了现有的文件系统对于负载和技术变化所进行的错误处理。
2.1 Technoloy
文件系统设计有三个重要的影响因素:处理器、磁盘和主存。处理器的速度正以指数型曲线进行增长并在未来依然会延续这种增长趋势。这就给计算机系统的其他所有组件带来了压力,要求他们能够以同样的速率提高速度,才能不导致系统出现不平衡。
磁盘技术同样得到了快速的提高,但是这种提高主要是集中在磁盘的价格而不是磁盘的性能。磁盘的性能主要有两个方面组成:传输带宽和访问时间。虽然这些都在提高,但是其提高的速率远远低于CPU速度提高的速率。磁盘带宽可以通过磁盘阵列和多磁头的磁盘得到有效提高,但是访问时间却没有多大的提升,它主要受限于机械运动,而且这种限制很难得到改善。如果应用程序会产生一系列的小容量磁盘访问,那么这类应用程序在未来十年内都不会有明显的性能改善,即使CPU的速度得到了巨大的改善。
第三个技术点是主存,它的容量争议指数型速率增长。现代文件系统将最近使用的文件缓存在主存中,随着主存的增大,大容量的文件缓存成为可能。它给文件系统带来了两个主要的影响。首先,大容量的文件系统通过缓存更多的读请求,改变了负载与磁盘之间的交互。大部分的写请求最终需要反应到磁盘上,因此磁盘的带宽越来越受到写的限制。
第二个影响是大容量的额外那件缓存可以作为写缓冲,使得大量的块更新可以被聚集起来进行一次写。缓存能够提供更有效的写操作,例如对数据进行线性写,从而只需要一次寻道。当然,写缓存可能在故障出现的时候增加数据的丢失数量。就本文而言,我们假设故障发生的频率不是那么的高,而且丢失几秒或者几分钟的数据完全是在可接受的范围之内,对于那些要求更好的的故障恢复性能的应用程序,那么就需要使用非易失性存储作为写缓冲了。
2.2 Workloads
计算机应用程序有几类很常见的负载。高效处理办公与工程环境中的需求对文件系统的设计来说是最困难的。办公与工程应用程序趋向于访问较小的文件,多项研究表明这些文件大约只有几kb。 小的文件通常会产生较小的随机磁盘IO,这类文件的创建和删除通常是有更新文件系统的"metadata"(用于定位文件块和属性的数据结构)的时间所决定的。
那些由顺序访问大容量文件决定的负载,例如在超级计算环境中的例子,同样会产生有趣的问题,担不是对于文件系统本身。有大量的技术确保这样的文件能够顺序的写在磁盘上,因此I/O性能主要是由I/O带宽以及内存子系统而不是文件分配的策略所决定的。在设计log-structured文件系统的时候,我们主要关注小文件的访问,让硬件设计者来提高大容量文件的读写带宽。幸运的是,Sprite LFS使用的技术对于大容量文件来说同样有效。
2.3 Problems with existing file systems
当前的文件系统主要面临两个问题,使得它们无法协调处理90年代的技术发展和负载。首先,他们将信息分散在磁盘上,导致了太多较小访问。例如,Berkeley Unix快速文件系统(Unix FFS)能够高效的将每个文件顺序的放置在磁盘上,但是它将不同的文件进行了物理隔离。此外,文件爱你的属性(inode)与文件的内容分离开来了,对于包含文件名的文件夹也是类似的情况。至少需要5次独立I/O,每次I/O都包含寻道操作,1次在Unix FFS中创建文件,2次访问文件属性以及分别访问文件的数据、目录的数据以及目录的属性。在这样一个文件中写小文件,只有不超过5%的磁盘带宽用于新数据的写,剩下的时间用于磁盘寻道。
现有文件系统的第二个问题是它们都倾向于同步写:应用程序需要等待写操作完成,而不是在数据在后台写的时候同时进行计算。例如,虽然Unix FFS对数据进行异步写,但是文件系统的元数据结构如目录、inode等都是同步写的。对于拥有很多小文件的负载来说,磁盘带宽受限于元数据的同步写。同步写操作将应用程序的性能与磁盘的性能绑定起来了,使得它们无法从CPU速度提升中获得更好的性能。同样的,这种方式使得文件缓冲区无法使用。不幸的是,网络文件系统如NFS引入了新的同步策略,虽然简化了故障恢复操作,但是影响了写性能。
本文将Berkeley的Unix FFS系统作为当前文件系统的代表,并且将其与log-structured 文件系统做比较。之所以选择Unix FFS是因为它有比较好的文档,并且在多个流行的Unix 操作系统中使用。本节中提到的问题并不是Unix FFS独有的,当前大多数的文件系统都存在。
3.Log-structured File system
Log-structured File system 最基本的思路是在文件cache中缓存文件系统一系列的修改,然后把这些修改操作利用一次写的过程顺序的写入单个磁盘,从而提高西系统的写操作性能。写操作过程中利用的信息包括flie data blocks,attributes,index blocks,directories,以及其他所有用于管理整个文件系统的信息。对于用用许多较小文件的负载,a log-structured file system 将许多小容量传统文件进行的同步随机写操作转换成大容量的异步顺序传输,从而使得磁盘带宽的利用率接近100%。
虽然log-structured file system的基本思路比较简单,但是需要解决两个关键的问题从而获得可能的性能优势。首先是如何从log中恢复信息,这部分在section3.1里面有提到。第二个问题是如何管理磁盘上的空闲空间,从而使得在写入新数据的时候能够进行大量的空闲空间扩展。这个问题相对而言比较困难,在3.2-3.6里面有详细提到。表1Sprite LFS用来解决上述问题所使用到的磁盘数据结构,这些结构在稍后的章节里面有提到。
表1 sprite LFS使用的主要数据结构
| Data Structure | purpose |
| Inode | 定位文件块,包含存储保护位、更新时间等 |
| Inode map | 定位log中inode的位置,包含最近访问时间和版本号 |
| Indriect block | 定位大容量数据块 |
| Segement summary | 标识segment的内容(文件数量以及每个block的偏移量) |
| Segement usage table | 计算segments中存活的bytes数,并为segement中的数据存储的写 时间 |
| Super Block | 存储静态配置信息,包括segements的数量和大小 |
| Checkpoint region | 定位inode map、segment useage table所在的block,并标识log中上一个check point的位置 |
| Directory change log | 记录目录操作,从而保证inode 中的引用数量一致性 |
3.1 File location and reading
虽然"log structured"这个词可能意味着恢复信息需要顺序扫描整个log,但是这并不是Sprite LFS系统所需要的。我们的目标是达到或者超过Unix FFS文件系统的读性能。为了达到这个目的,SpriteLFS在log中输出index结构,从而允许随机访问。Sprite LFS 使用的基本结构和Unix FFS使用的基本一样:每个文件有一个inode 结构体,包含了文件的属性(类型、所有者以及权限等等)以及文件的前10个blocks的磁盘地址;对于超过10个文件块的文件,inode包含一个或者多个indriect blocks,indriect blocks包含更多的数据或者indirect blocks。一旦文件的inode被找到,Sprite LFS需要进行的磁盘I/O数量与Unix FFS是相同的。
在Unix FFS文件系统中,每个确切标识文件的inode都在磁盘上的固定位置,简单的计算就能得出文件inode的地址。相反,Sprite LFS并没有把inode节点放在固定的位置,他们被写入了log。Sprite LFS使用inode map来保存每个inode节点的当前位置。给定一个确定的文件号,inode map应该能够确定inode的磁盘地址。inode map 被分成块写入log;每个磁盘上有固定的检查点区域用来标识所有inode map节点的位置。幸运的是,inode节点都很小,因此可以缓存在主存中,inode map的查询几乎不需要进行磁盘的访问。
图1展示了Sprite LFS 和Unix FFS在不同的目录下创建两个文件之后的磁盘布局。虽然这两种布局拥有同样的逻辑结构,log-structured文件系统会形成更加紧凑的布局。因此,Sprite LFS在读性能与Unix FFS相仿的情况下,写性能要好得多。
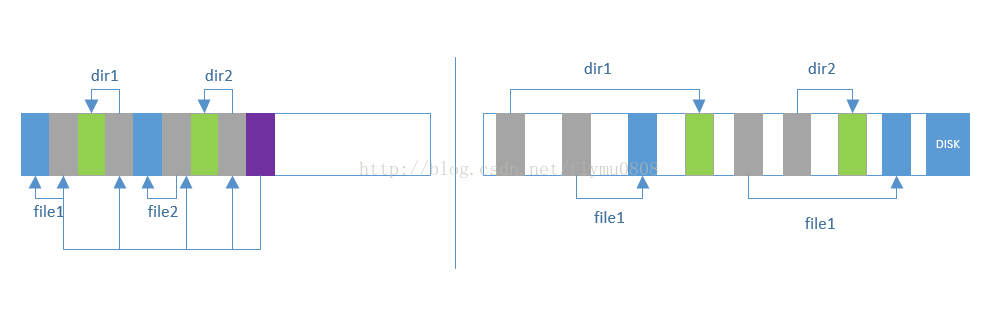
图1 Unix FFS与Sprite FFS 文件系统布局对比
3.2 Free space management:segments
设计log-structured文件系统最困难的事情是空闲空间的管理,从而保持大容量的空闲区域用于新的数据写入。初始情况下,磁盘的所有空闲空间都在同一区域中,但是随着时间的推移log会到达log的尾部,这时候,空闲区域会被分割成很多的区域,用来存储那些被重复写入和删除的文件的文件。
从这个点来说,文件系统有两个选择:threading和copying,如图2所示。第一个选择是将live data 留在远处,并且将日志穿插在空闲的区域中。不幸的是,这种穿插会导致日志严重的碎片化,从而导致大量持续性的写很难满足,log-structured文件系统也不会比传统的文件系统更快了。第二个选择是将live data从log中拷贝出来,从而能够留下大块的空余区域用于写。就本文而言,我们假定live data以一种比较紧凑的方式在log的写入头部;它能够被一道其他的log-structured文件系统中从而形成层次的日志,或者能够被移到其他完全不一样的文件系统或者档案中。拷贝的缺点是性能代价,尤其是对于一个长时间存活的文件;在最简单里的例子中,log循环的写磁盘文件,live data被拷贝会磁盘中,所有的长期存活的数据需要在日志每次写完磁盘的时候被拷贝。
Sprite LFS使用了一个Threading 和 copying相结合的方式。磁盘被分成了大容量的固定大小的区域,称为segements(怎么感觉有点像分页呢)。任何给定的segments都是从头开始顺序写到尾部,并且重写segement需要把所有数据拷贝出整个segement。但是,log是通过segment-segement来进行穿插的;如果系统内呢个够将长时间存在的数据聚聚在segements,这些segement就可以被跳过,里面的数据也不会被重复性的拷贝了。segment的大小选定为足够大,这样读或者写整个磁盘的时间要远远大于寻找segment开始位置的时间。这样使得不论对那个segment进行操作,整个segment的操作以磁盘满带宽进行了。Sprite LFS目前使用的segement大小为512kB或者1MB。
3.3 Segment cleaning mechanism
将live data 拷贝出segment的操作称为segment cleaning。在Sprite LFS中,这是一个简单的三步操作:读几个segment进内存,确认live data 并且将这些数据写入较少的几个干净segment中。当这个操作执行完了之后,这些读进来的segments都会被标记为clean,从而可以用来写入新的数据或者其他的cleaning操作。
segment cleaning操作需要判断segment中那些block是live的,这些block才需要被写到磁盘上。同样的,它还需要判断block属于哪个file,以及这个block在文件内的偏移地址,这些信息需要用于更新文件的inode节点,使它能够指向block的新的位置并进行更新。Sprite LFS通过为每一个segment写一个segment summary来解决这些问题。summary block能够分析写入segment中的信息;例如,每一个数据块的segment summary block包含有文件的数量以及这个块的块数量。如果多个log需要填充Segment,那么它可以包含多个Segment summary blocks。(当文件cache中缓存的blocks不够填充整个segements的时候,就可能产生Partial-segment写)Segment Summay blocks在写数据的时候只增加了一点开销,但是在故障恢复和清理的时候它们很有用。
Sprite LFS也使用Segment summary信息来区分live并blocks 和已经被删除或者被重新写的块。一旦某个块的identity已经知道,那么它的liveness可以通过检查文件的inode或者indirect blocks来确定是否存在合适的block pointer指向这个块。如果存在这样的block pointer,那么这个块就是live,如果不存在,那么这个块就是dead。Sprit LFS对这个检查方法进行了稍微的优化,它在inode map entry中为每个file保存一个版本号(version number),每次文件被删除或者被清空成0的时候,版本号就会增加。版本号和inode nubner就形成了文件内容的uid。segment summary block为每一个block记录这样的uid,如果block在segment summary中的uid与它在inode map中的uid版本号不一致,那么在进行清理的时候,就可以直接把它给清理掉而不用检查文件的inode了。
这种清理策略也意味着Sprite中没有标识空闲块的block list或者bitmap。除了减少了内存和磁盘空间,不是用这些数据结构同样是的故障恢复变得简单,因为不需要额外的代码来确保故障恢复之后的数据一致性。
3.4 Segment Cleaning Policies
根据上面提到的基本策略,需要强调4点策略:
(1)什么时候需要执行segment cleaner ? 有一些可选的策略可以使得它以很低的优先级运行在后台,夜晚或者磁盘空闲的时候。
(2) 一次性需要整理多少segment ? segment cleaning可以重新安排磁盘上的数据,一次性清理越多的segment,就有更多的机会去进行重新安排;
(3)那些segment需要被清理? 最直观的就是清理那些最为破碎的,但是这被证明并不是最好的策略;
(4)在数据写出的时候,live blocks应当如何组织? 一种可行的方案就是增加未来读写的局部性,例如,将同一个目录下的文件写如同一个segment中。另一中方案就是将这些块按照最近修改时间进行排序,并且将修改时间比较接近的数据写入同一个segment,我们称之为按年龄排序;














 744
744











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









