






摘要:本文以环境工程领域的污水处理厂实习为例,介绍了调用通义千问(qwen-plus)大模型API生成一份word版本的生产实习报告的过程,主要分为实现效果展示、调用大模型API生成实习报告的python代码、代码使用说明和代码设计思路四个部分。若仅需简单复用代码,可只阅读调用大模型API生成实习报告python代码、代码使用说明两个部分。本文提供python代码,可供使用。
0 实现效果展示
代码实现后将在与代码文件同一路径下生成一个word文档,在该文档中呈现了实习报告的主要内容,可用于后续修改。生成的word文档效果如图。

![]()
1 调用大模型API生成实习报告的python代码
from openai import OpenAI
import json
from tqdm import tqdm
from docx import Document
from docx.oxml.ns import qn
from docx.shared import Pt, RGBColor
question_list = ['污水厂实习的意义', '介绍福州洋里污水厂', '介绍污水处理中的AAO工艺', '介绍污水处理中的MBR工艺',\
'介绍污水处理中的反硝化深床滤池工艺', '介绍污水处理中的紫外消毒工艺', '污水厂生产实习体会']
# 问问题获取回答,问题应为str格式
def askget(question):
# 1-通过api从通义千问获取回答
client = OpenAI(
# 若没有配置环境变量,请用百炼API Key将下行替换为:api_key="sk-xxx",
api_key="",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
completion = client.chat.completions.create(
model="qwen-plus", # 此处以qwen-plus为例,可按需更换模型名称。模型列表:https://help.aliyun.com/zh/model-studio/getting-started/models
messages=[
{'role': 'system', 'content': 'You are a helpful assistant.'},
{'role': 'user', 'content': question}],
)
print(completion.model_dump_json())
# 2-将返回的json字符串转为字符串
# 将JSON字符串转换为Python对象(通常是字典或列表)
data = json.loads(completion.model_dump_json())
# 提取键值对
choices = data.get('choices')[0]
# 提取键值对
message = choices.get('message') # 使用get方法安全地获取值
# 如果需要访问嵌套字典中的值
content = message.get('content')
#print(f"Content: {content}")
print(content)
return content
# 3-组合内容
# 多次调用api并组合输出内容
content = ''
for i in tqdm(range(len(question_list))):
content = content+'\n\n'+question_list[i].replace('介绍', '')+'\n\n'
answer = askget(question_list[i]+',不要总结,采用学术性语言') # 调用函数
content = content+answer # 拼接字符串
# 去除输出中的井、星、杠
content = content.replace(r'#', '')
content = content.replace(r'*', '')
content = content.replace(r'-', '')
print(content)
# 4-将字符串写入word文档
# 创建一个新的Word文档
doc = Document()
# 设置默认字体为宋体
doc.styles['Normal'].font.name = u'宋体'
doc.styles['Normal']._element.rPr.rFonts.set(qn('w:eastAsia'), u'宋体')
# 设置字号为10.5磅
doc.styles['Normal'].font.size = Pt(10.5)
# 设置字体颜色为黑色
doc.styles['Normal'].font.color.rgb = RGBColor(0, 0, 0)
# 添加一个段落,内容为包含中文的字符串
content1 = doc.add_paragraph(content)
content1.paragraph_format.space_before = Pt(0) # 设置段前 0 磅
content1.paragraph_format.space_after = Pt(0) # 设置段后 0 磅
content1.paragraph_format.line_spacing = 1 # 设置行间距为 1
# 保存文档到指定路径
doc.save('example_v01.docx')
print("文档已成功创建并保存")2 代码使用说明
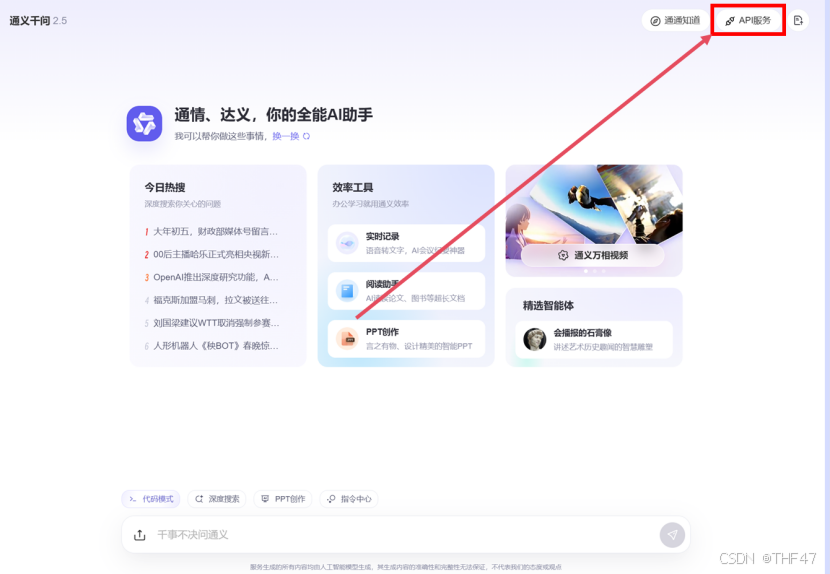
a. 打开通义千问通义tongyi.ai_你的全能AI助手-通义千问,并点击右上角的“API服务”。
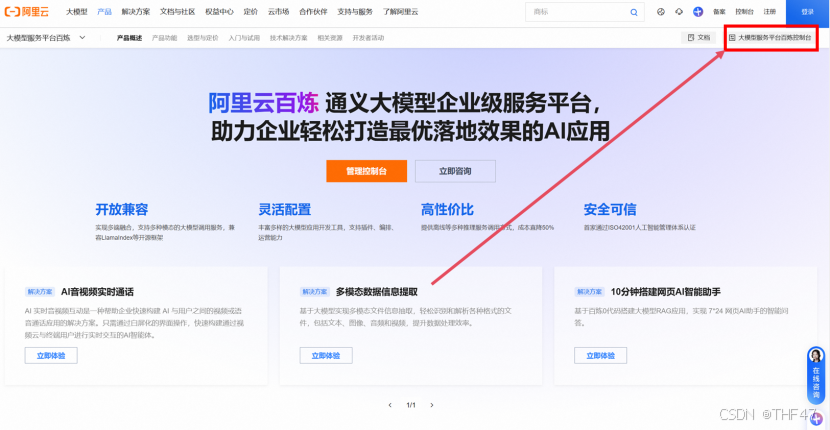
b. 点击“大模型服务平台百炼控制台”,此处可能需要先登录。
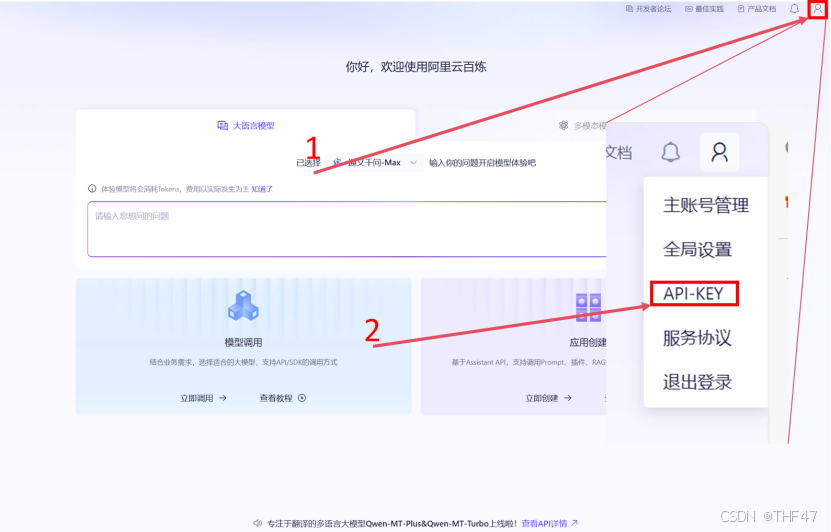
c. 打开控制台后点击右上角小人图标,再下拉菜单中点击“API-KEY”。
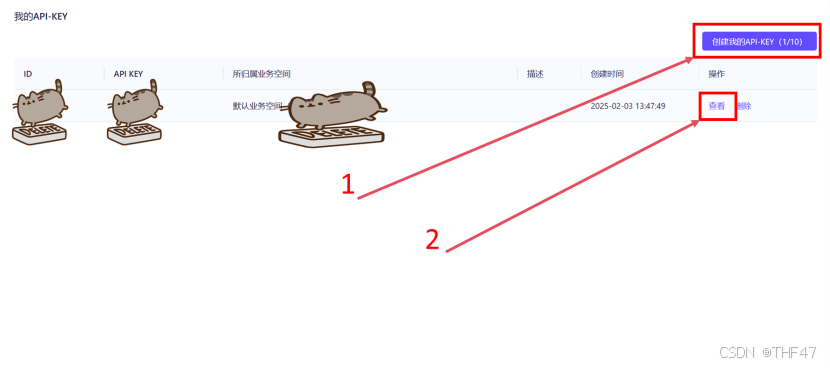
d. 打开API-KEY界面后,先点击右上角的“创建我的API-KEY”,在创建API-KEY后,点击操作下方的“查看”按钮,即可获得API-KEY,以“sk-”开头。
e. 将获得的API-KEY输入下图1箭头所示的双引号间,并可根据需求更改question_list中的问题。question_list列表中的问题可基于实习工厂的工艺流程确定,若一个工厂采用的工艺为粗格栅-进水泵房-细格栅-曝气沉砂池-SBR-混凝反应池-活性砂滤池-接触消毒池,则可对粗格栅、进水泵房、细格栅等每一个工艺单元分别提问。提问格式可为“介绍污水处理中的某工艺”。
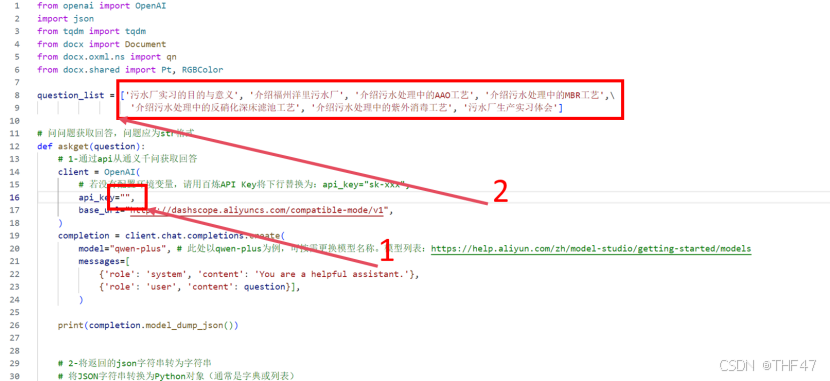
f. 在该代码运行位置的文件夹下出现一个名为“example_v01.docx”的word文档,文档中即为大模型生成的实习报告内容,可用于后续的修改和插入图片。
3 代码设计思路
一份简单的实习报告至少需要由4个部分组成,分别是实习的目的与意义、实习单位简介、生产工艺介绍和实习心得体会。还要求需要图文并茂,这里的解决方案是生成文字并手动插入相关图片。因此,我们需要调用AI分别撰写4个部分,其中生产工艺介绍需要详细描述,最好细化到每一个工艺单元。
我们使用了通义千问(qwen-plus)大模型进行报告的撰写,通过调用API实现对qwen-plus的交互,并通过对返回值的提取、处理和组合,获取较长的实习报告篇幅,并写入到word中,便于后续编辑。
a. 通过API从通义千问获取回答
这里将该过程封装为askget函数,该函数需输入要向大模型提的str格式的问题,这里需输入自己的api_key(见第2部分代码使用说明),可更换model参数为不同模型名称,如qwen-turbo、qwen-long等。
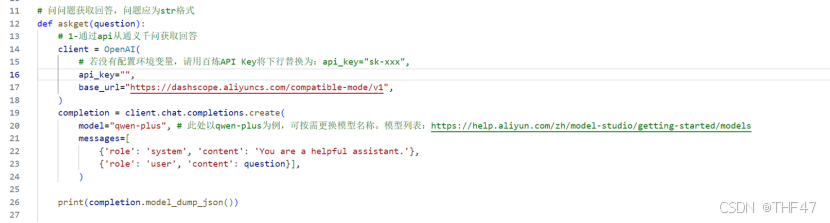
b. 将返回的json字符串转为字符串
观察API调用返回值格式,其是json类型,先将其转换为键值对,发现需要的内容在多层嵌套中,先提取choices键的值,在该列表第0个元素中再提取message键的值,最后在其中提取content键的值。


c. 组合内容
由于实习报告需由多个部分组成,采用分开提多个问题的方式进行报告的撰写。这里使用for循环多次调用前述的askget函数,将获得的内容进行拼接。考虑到大模型返回内容中存在“#”、“*”、“-”等标记,对这些标记进行去除。

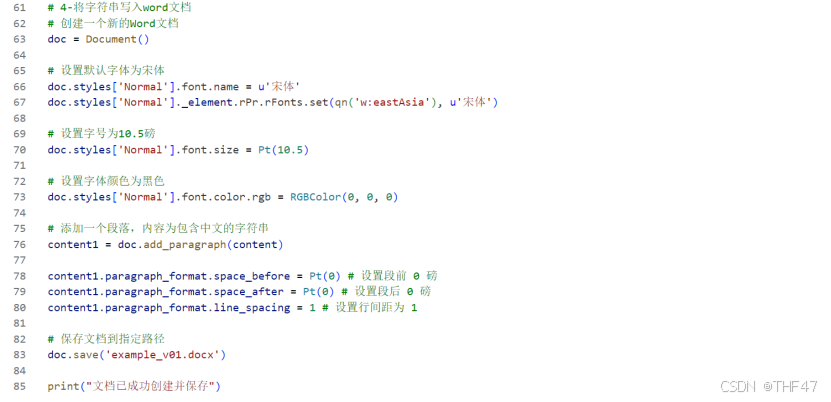
d. 将字符串写入word文档
由于word文档更易编辑,将组合完成的字符串内容输出到word文档。考虑到美观性和实用性,将word文档中字体设置为宋体,字号设置为10.5磅,字体颜色设置为黑色,段前段后均为0磅,行距设置为单倍行距。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









