










Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression
Zhaohui Zheng1, Ping Wang1, Wei Liu2, Jinze Li3, Rongguang Y e1, Dongwei Ren*2
1School of Mathematics, Tianjin University, China
2College of Intelligence and Computing, Tianjin University, China
3School of Information Technology and Cyber Security, People’s Public Security University of China
*Corresponding author: rendongweihit@gmail.com
原文链接:https://arxiv.org/abs/1911.08287
边界盒回归是目标检测的关键步骤。在现有的方法中,虽然N范数损失被广泛地应用于包围盒回归,但它不适合于评价度量,即在工会(IOU)上的交集。近年来,人们提出了IoU损失和广义IoU(GIoU)损失来衡量IoU度量,但仍存在收敛速度慢和回归不准确的问题。在本文中,我们提出了一个距离IoU(DIoU)损失,通过合并预测框和目标框之间的标准化距离,它在训练中比IoU和GIoU损失收敛得快。此外,本文还总结了边界盒回归中的三个几何因素,即重叠面积、中心点距离和纵横比,并在此基础上提出了一个完整的IoU(CIoU)损失,从而提高了收敛速度和性能。通过将DIoU和CIoU损失合并到最新的目标检测算法中,例如YOLO v3、SSD和更快的RCNN,我们不仅在IoU度量方面而且在GIoU度量方面取得了显著的性能提高。此外,DIoU可以很容易地采用非最大抑制(NMS)作为准则,进一步提高性能改善。源代码和经过训练的模型可以在https://github.com/Zzh-tju/DIoU上找到。
https://github.com/Zzh-tju/DIoU-SSD-pytorch
论文笔记:本文主要改进点就是损失函数的改进(回归策略上使用的损失函数),IoU损失和GIoU损失是衡量IoU的度量,但是它们收敛速度慢,回归不太准确,疑惑点:
1.收敛速度慢是有多慢。GIoU比DIoU慢,目标框和预测框没有覆盖的情况下,GIoU有惩罚,使得预测框向目标框移动。DIoU使用了距离度量损失,当目标框和预测框不重叠时就会有损失,通过预测框和目标框的最小化中心距离可以使得预测框向目标框移动。(DIoU损失可以直接最小化两个盒子的距离,从而比GIoU损失收敛得快得多。2。对于包含两个盒子的情况,或在水平和垂直方向上,DIoU损失可使回归非常快,而GIoU损失几乎已退化为IoU损失,即| C−A∪B |→0。)
IoU损失仅适用于与目标框重叠的情况。没有重叠的锚箱不会移动,因为∇B始终为0。
(3)GIoU损失可以较好地缓解不重叠案例的问题。从图4(b)可以看出,GIoU loss显著地扩大了盆地,即GIoU工作的区域。但在水平方向和垂直方向的情况下仍有较大的误差。这是因为GIoU loss中的惩罚项用于最小化| ![]() ,但
,但![]() 的面积通常很小或为0(当两个框具有包含关系时),然后GIoU几乎退化为IoU loss只要在适当的学习速率下运行足够的迭代,GIoU-loss就会收敛到很好的解,但收敛速度确实很慢。从几何上讲,从图1所示的回归步骤可以看出,GIoU实际上增加了预测盒的大小,使其与目标盒重叠,然后IoU项将使预测盒与目标盒匹配,从而产生非常缓慢的收敛。(有一个问题,难道GIoU和CIoU没有使得预测框和目标框匹配吗,你不是加入了IoU损失吗。)
的面积通常很小或为0(当两个框具有包含关系时),然后GIoU几乎退化为IoU loss只要在适当的学习速率下运行足够的迭代,GIoU-loss就会收敛到很好的解,但收敛速度确实很慢。从几何上讲,从图1所示的回归步骤可以看出,GIoU实际上增加了预测盒的大小,使其与目标盒重叠,然后IoU项将使预测盒与目标盒匹配,从而产生非常缓慢的收敛。(有一个问题,难道GIoU和CIoU没有使得预测框和目标框匹配吗,你不是加入了IoU损失吗。)
2.不准确的原因是什么?没有考虑纵横比
2.加入中心距离损失就可以改进收敛速度吗,距离度量的依据?3.DIoU和CIoU是用来做什么的?4.训练过程中度量的采用了什么。
文献说明。DIoU:距离损失,最小化距离。CIoU:最小化纵横比(目标重叠情况下的精确预测)
目标检测是计算机视觉任务中的关键问题之一,近几十年来受到了广泛的研究关注(Redmon等人。2016年;Redmon和Farhadi 2018年;Ren等人。2015年;他等。2017年;Y ang等人。2018年;Wang等人。2019年;2018年)。一般来说,现有的目标检测方法可以被分类为:单步检测,如YOLO系列(ReMon等人)。2016年;Redmon和Farhadi,2017年;2018年)和SSD(Liu等人。2016年;Fu等人。2017),两阶段检测,如R-CNN系列(Girshick等人。2014年;Girshick 2015年;Ren等人。2015年;他等。2017年),甚至多阶段检测,如Cascade R-CNN(Cai和V asconcelos 2018)。尽管有这些不同的检测框架,边界盒回归是预测矩形盒定位目标的关键步骤。

图1:GIoU损失(第一行)和DIoU损失(第二行)的边界框回归步骤。绿色和黑色分别表示目标框和锚定框。蓝色和红色分别表示GIoU损失和DIoU损失的预测框。GIoU损失通常增加预测盒的大小,使其与目标盒重叠,而DIoU损失则直接使中心点的归一化距离最小。
关于包围盒回归的评价指标,
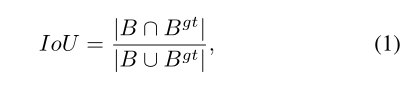 交并比(IoU)是最流行的度量。
交并比(IoU)是最流行的度量。
其中![]() 是真实框,
是真实框,![]() 是预测框。传统上,在B和B^gt的坐标上采用n norm(如n=1或2)loss来测量边界框之间的距离(Redmon等人。2016年;Girshick 2015年;Ren等人。2015年;他等。2017年;Bae 2019年)。然而,正如(Y u et al。2016年;Rezatofighi等人。2019年),n-范数损失不是获得最优IoU指标的合适选择。在(Rezatofighi等人。2019年),建议采用IoU损失来改进IoU指标,
是预测框。传统上,在B和B^gt的坐标上采用n norm(如n=1或2)loss来测量边界框之间的距离(Redmon等人。2016年;Girshick 2015年;Ren等人。2015年;他等。2017年;Bae 2019年)。然而,正如(Y u et al。2016年;Rezatofighi等人。2019年),n-范数损失不是获得最优IoU指标的合适选择。在(Rezatofighi等人。2019年),建议采用IoU损失来改进IoU指标,
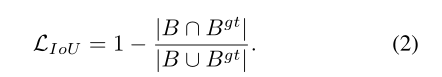
然而,IoU损失仅在边界框有重叠时才起作用,并且不会为非重叠情况提供任何移动梯度。然后是广义IoU损失(GIoU)(Rezatofighi等人。建议增加 一个罚则
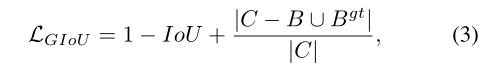
其中C是覆盖B和Bgt的最小盒子。由于引入了惩罚项,在不重叠的情况下,预测框将向目标框移动。
GIoU虽然可以解决非重叠情况下的梯度消失问题,但仍有一些局限性。通过模拟实验(见第。通过对IoU和GIoU损失的详细分析,可以对不同包围盒位置的GIoU损失性能进行评估。如图1所示,可以看出GIoU-loss首先打算增加预测框的大小,使其与目标框重叠,然后在Eqn中增加IoU项。(3)将最大化重叠框的重叠区域。从图2可以看出,对于包围盒,GIoU损失将完全退化为IoU损失。由于严重依赖IoU项,GIoU在经验上需要更多的迭代来收敛,特别是对于水平和垂直边界框(见图4)。在现有的检测算法中,GIoU-loss通常不能很好地收敛,导致检测不准确。
本文提出了边界盒回归的距离IoU损失。特别地,我们简单地在IoU损失上加上一个惩罚项,以直接最小化两个边界盒中心点之间的规范化距离,从而比GIoU损失更快地收敛。从图1中,可以部署DIoU损耗以直接最小化两个边界框之间的距离。在只有120次迭代的情况下,预测的盒子与目标盒子完全匹配,而GIoU即使经过400次迭代也不会收敛。此外,我们建议边界盒回归的良好损失应该考虑三个重要的几何度量,即重叠面积、中心点距离和长宽比,这三个度量长期以来被忽略了。结合这些几何测度,我们进一步提出了边界盒回归的一个完整的IoU损失,它比IoU和GIoU损失具有更快的收敛速度和更好的性能。所提出的损失可以很容易地并入最先进的目标检测算法中。此外,DIoU可以作为非最大抑制(NMS)的一个判据,不仅在抑制冗余盒时考虑了重叠区域,而且考虑了两个包围盒的中心点之间的距离,使得它对于闭塞的情况更加鲁棒。
为了评估我们提出的方法,将DIoU损失和CIoU损失合并到几个最新的检测算法中,包括YOLO v3(Redmon and Farhadi 2018)、SSD(Liu et al。以及更快的R-CNN(Ren等人。并在两个流行的基准数据集PASCAL VOC 2007(Everingham et al2010年)和2017年COCO女士(Lin等人。2014年)。工作贡献总结如下:1。本文提出了一种距离IoU损失,即DIoU损失,它比IoU和GIoU损失具有更快的收敛性。2。通过考虑重叠面积、中心点距离和纵横比三个几何度量,进一步提出了一个完整的IoU损失,即CIoU损失,较好地描述了矩形盒的回归三。DIoU部署在网管系统中,在抑制冗余盒方面比原来的网管系统更加健壮。四。所提出的方法可以很容易地融入到最先进的检测算法中,获得显著的性能提升。
相关工作
在这一部分中,我们简要地介绍了相关的工作,包括目标检测方法,边界盒回归的损失函数和非最大抑制。
目标检测
在(Song等人。2018)将中心轴线应用于行人检测。CornerNet(Law and Deng 2018)建议预测一对角来代替矩形框来定位物体。在RepPoints中(Y ang等人。2019年),通过预测几个点形成一个矩形盒。最近,FSAF(Zhu,He,and Savvides 2019)提出了无锚分支来解决在线特征选择中的非最优问题。目标检测也有一些损失函数,例如焦点损失(Lin等人。2017年),类平衡损失(Cui等人2019年),分类和边界盒回归的平衡损失(Pang等人。2019),以及梯度流平衡损失(Li、Liu和Wang 2019)。尽管如此,矩形盒的回归仍然是最先进的目标检测算法中最流行的方式(Redmon and Farhadi 2018;He et al。2017年;Fu等人。2017年;Liu等人。2016年;Tian等人。2019年)。
包围盒回归的损失函数
在包围盒回归中,常采用n-范数损失函数,但对尺度变化敏感。在YOLO v1中(Redmon等人。2016),采用w和h的平方根来减轻这种影响,而YOLO v3(Redmon和Farhadi 2018)使用2-wh。IoU损耗也用于自Unitbox(Y u et al。2016年),这是不变的规模。GIoU(Rezatofighi等人。2019)损失是为了解决非重叠情况下的梯度消失问题,但仍面临收敛速度慢和回归不准确的问题。相比之下,我们提出的DIoU和CIoU损失具有更快的收敛速度和更好的回归精度。

非最大抑制
NMS是大多数目标检测算法的最后一步,只要与最高得分框的重叠超过一个阈值,冗余检测框就会被删除。软NMS(Bodla等人。2017)通过连续函数w.r.t.IoU惩罚邻居的检测分数,产生比原始NMS更柔和和更强大的抑制。IoUNet(Jiang等人。2018年)引入一个新的网络分支预测本地化信心,以指导NMS。最近,自适应NMS(Liu,Huang,and Wang 2019)和较软的NMS(He et al。建议分别研究适当的阈值策略和加权平均策略。本文简单地将DIoU作为原始NMS的准则,在抑制冗余盒时,同时考虑了边界盒的重叠区域和两个中心点之间的距离
IoU和GIoU损失分析
首先,分析了原始IoU损失和GIoU损失的局限性。然而,仅从检测结果分析包围盒回归的过程是非常困难的,因为在不受控制的基准中,回归情况往往不全面,例如不同的距离、不同的尺度和不同的纵横比。相反,我们建议进行模拟实验,在实验中应综合考虑回归情况,然后可以很容易地分析给定损失函数的问题。
模拟实验
在模拟实验中,我们试图覆盖边界框之间在距离、比例和纵横比方面的大多数关系,如图3(a)所示。特别地,我们选择7个不同长宽比(1:4、1:3、1:2、1:1、2:1、3:1和4:1)的单元框(即每个框的面积为1)作为目标框。在不丧失一般性的情况下,7个目标盒的中心点固定在(10,10)。锚箱均匀分布在5000点。(一)距离:在以(10,10)为中心、半径为3的圆形区域内,均匀选择5000个点,放置7个标度、7个纵横比的锚箱。在这些情况下,包括重叠和非重叠框。(二)标度:每一点锚箱面积设为0.5、0.67、0.75、1、1.33、1.5、2。(三)纵横比:对于给定的点和比例尺,采用7个纵横比,即遵循与目标框相同的设置(即1:4、1:3、1:2、1:1、2:1、3:1和4:1)。所有5000×7×7锚箱应安装在每个目标箱上。综上所述,共有1715000=7×7×7×5000个回归案例。
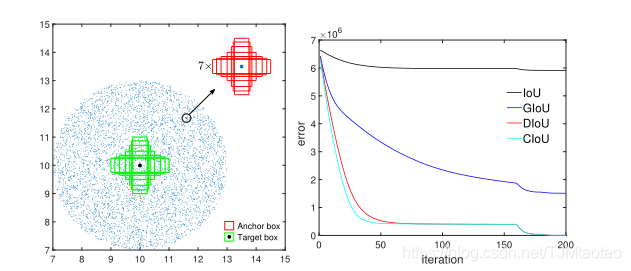
图3:模拟实验:(a)考虑不同距离、尺度和纵横比,采用1715000个回归实例;(b)迭代t时不同损失函数的回归误差和(即![]() 曲线
曲线
然后给出一个损失函数L,用梯度下降算法模拟每种情况下的包围盒回归过程。对于预测框Bi,可以通过
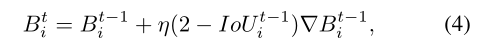
其中![]() 是迭代t时的预测框,
是迭代t时的预测框,![]() 表示损失的梯度
表示损失的梯度![]() 迭代t−1,而η是步长。值得注意的是,在我们的实现中,梯度乘以
迭代t−1,而η是步长。值得注意的是,在我们的实现中,梯度乘以![]() 以加速收敛。用“1-范数”(
以加速收敛。用“1-范数”(![]() )评价了边界盒回归的性能。对于每个损失函数,当达到迭代T=200时,模拟实验终止,误差曲线如图3(b)所示。
)评价了边界盒回归的性能。对于每个损失函数,当达到迭代T=200时,模拟实验终止,误差曲线如图3(b)所示。
IoU和GIoU损失的限制
在图4中,我们将迭代T时5000个分散点的最终回归误差可视化。从图4(a)很容易看出,IoU损失仅适用于与目标框重叠的情况。没有重叠的锚箱不会移动,因为∇B始终为0。
加上一个惩罚项作为Eqn。(3)GIoU损失可以较好地缓解不重叠案例的问题。从图4(b)可以看出,GIoU loss显著地扩大了盆地,即GIoU工作的区域。但在水平方向和垂直方向的情况下仍有较大的误差。这是因为GIoU loss中的惩罚项用于最小化| ![]() ,但
,但![]() 的面积通常很小或为0(当两个框具有包含关系时),然后GIoU几乎退化为IoU loss只要在适当的学习速率下运行足够的迭代,GIoU-loss就会收敛到很好的解,但收敛速度确实很慢。从几何上讲,从图1所示的回归步骤可以看出,GIoU实际上增加了预测盒的大小,使其与目标盒重叠,然后IoU项将使预测盒与目标盒匹配,从而产生非常缓慢的收敛。
的面积通常很小或为0(当两个框具有包含关系时),然后GIoU几乎退化为IoU loss只要在适当的学习速率下运行足够的迭代,GIoU-loss就会收敛到很好的解,但收敛速度确实很慢。从几何上讲,从图1所示的回归步骤可以看出,GIoU实际上增加了预测盒的大小,使其与目标盒重叠,然后IoU项将使预测盒与目标盒匹配,从而产生非常缓慢的收敛。
综上所述,对于非重叠情况,IoU损失收敛到坏解,而GIoU损失收敛缓慢,特别是对于水平和垂直方向的盒。而当引入目标检测管道时,IoU和GIoU的损失都不能保证回归的准确性。很自然地会问:首先,为了获得更快的收敛速度,直接最小化预测盒和目标盒之间的规范化距离是否可行?第二,在与目标框重叠甚至包含时,如何使回归更准确、更快?
提出的方法
一般来说,基于IoU的损失可以定义为
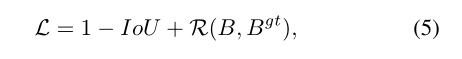
其中![]() 是预测框B和目标框
是预测框B和目标框![]() 的惩罚项。通过设计适当的惩罚条件,本部分提出了DIoU损失和CIoU损失来回答上述两个问题。
的惩罚项。通过设计适当的惩罚条件,本部分提出了DIoU损失和CIoU损失来回答上述两个问题。
距离IoU损失
为了回答第一个问题,我们建议最小化两个边界框中心点之间的规范化距离,惩罚项可以定义为
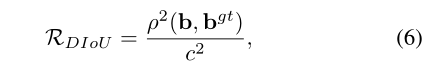
其中b和![]() 表示是b和
表示是b和![]() 的中心点,ρ(·)是欧几里德距离,c是覆盖这两个盒子的最小包围盒的对角线长度。然后DIoU损失函数可以定义为
的中心点,ρ(·)是欧几里德距离,c是覆盖这两个盒子的最小包围盒的对角线长度。然后DIoU损失函数可以定义为

如图5所示,DIoU loss的惩罚项直接最小化了两个中心点之间的距离,而GIoU loss的目标是减小![]() 的面积。
的面积。
与IoU和GIoU损失的比较
提出的![]() 损失继承了IoU和GIoU损失的一些思路
损失继承了IoU和GIoU损失的一些思路
一.DIoU损失对回归问题的规模仍然是不变的。
二.与GIoU-loss类似,DIoU-loss可以在与目标框不重叠时为边界框提供移动方向。
三.当两个边界框完全匹配时,LIoU=LGIoU=LDIoU=0。当两个盒子相隔很远时,LGIoU=LDIoU→2。
DIoU loss 比IoU loss 和GIoU loss 有许多优点,可以通过仿真实验进行评估。
一。如图1和图3所示,DIoU损失可以直接最小化两个盒子的距离,从而比GIoU损失收敛得快得多。2。对于包含两个盒子的情况,或在水平和垂直方向上,DIoU损失可使回归非常快,而GIoU损失几乎已退化为IoU损失,即| C−A∪B |→0。
Complete IoU Loss (CIoU loss)
然后,我们回答了第二个问题,提出边界盒回归的良好损失应该考虑三个重要的几何因素,即重叠面积、中心点距离和纵横比。通过统一坐标,IoU损失考虑重叠区域,而GIoU损失严重依赖IoU损失。我们提出的DIoU损失旨在同时考虑边界盒的重叠区域和中心点距离。然而,边界框纵横比的一致性也是一个重要的几何因素。因此,在DIoU损失的基础上,通过对长宽比的一致性施加影响,提出了CIoU损失的概念。
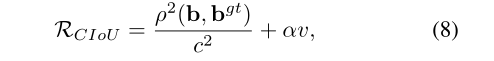
其中α是一个正的权衡参数,v测量长宽比的一致性,

那么损失函数可以定义为
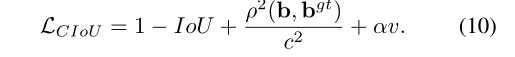
权衡参数α定义为
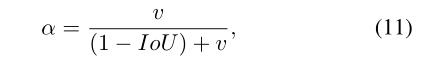
其中重叠区域因子在回归中具有更高的优先权,特别是在非重叠情况下。最后,CIoU损失的优化与DIoU损失的优化相同,只是需要指定v w.r.t.w和h的梯度,

对于在[0,1]范围内的h和w情形,支配子![]() 通常是一个小值,这可能产生梯度爆炸。因此,在我们的实现中,为了稳定收敛,简单地去掉了控制因子
通常是一个小值,这可能产生梯度爆炸。因此,在我们的实现中,为了稳定收敛,简单地去掉了控制因子![]() ,用1代替步长
,用1代替步长![]() ,梯度方向仍然与Eqn一致。(12)。
,梯度方向仍然与Eqn一致。(12)。
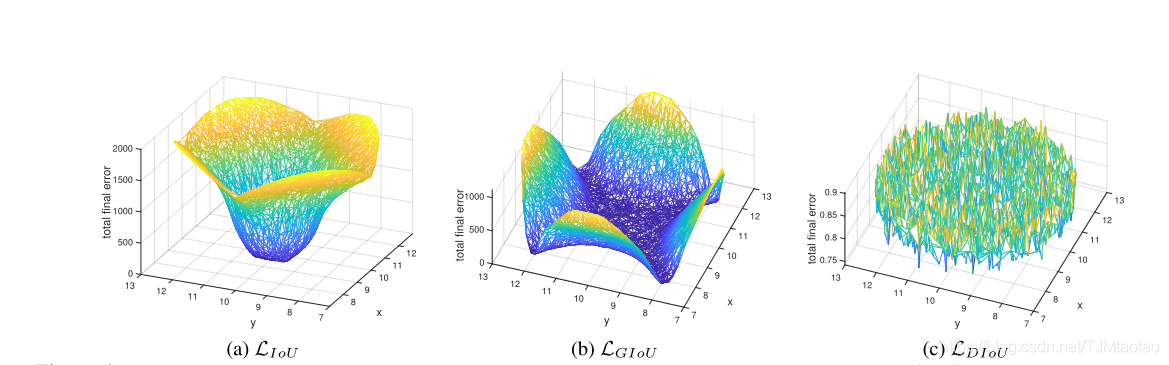
图4:最终迭代T时IoU、GIoU和DIoU损失的回归误差可视化,即。。E(T,n)表示每个坐标n。我们注意到(a)和(b)中的盆地对应于良好的回归情况。可以看出,对于不重叠的情况,IoU损失有很大的误差,对于水平和垂直的情况,GIoU损失有很大的误差,而我们的DIoU损失在任何地方都会导致非常小的回归误差。
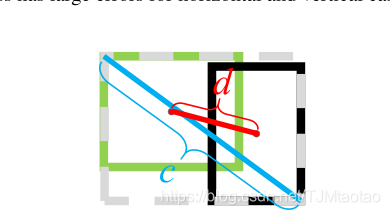
图5:边界盒回归的DIoU损失,其中中心点之间的标准化距离可以直接最小化。c为最小包围盒覆盖两个盒子的对角线长度,![]() 为两个盒子中心点的距离。
为两个盒子中心点的距离。
使用DIoU的非最大抑制
在原始的NMS中,IoU度量被用来抑制冗余的检测盒,其中重叠区域是唯一的因素,通常会对有遮挡的情况产生假抑制。我们认为DIoU是一个更好的NMS准则,因为在抑制准则中不仅要考虑重叠区域,还要考虑两个盒子之间的中心点距离。对于得分最高的预测框M,DIoU NMS可以正式定义为
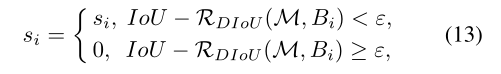
其中,通过同时考虑IoU和两个框的中心点之间的距离来移除框Bi,Si是分类得分,ε是NMS阈值。我们建议,两个中心点较远的盒子可能会定位不同的对象,不应移除。而且,该系统非常灵活,可以集成到只有几行代码的任何对象检测管道中。
实验结果
在本节中,介绍两个流行的基准,包括PASCAL VOC(Everingham等人。2010年)和COCO女士(Lin等人。2014年),我们通过将其纳入最先进的目标检测算法(包括一级检测算法(即YOLO v3和SSD)和两级算法(即更快的R-CNN)来评估我们提出的DIoU和CIoU损失。所有的源代码和我们训练过的模型都将公开提供。
YOLO v3 on PASCAL VOC
PASCAL VOC(Everingham等人。是最流行的目标检测数据集之一。YOLO v3使用DIoU和CIoU损失与IoU和GIoU损失进行PASCAL VOC培训。我们使用VOC 07+12(VOC 2007 trainval和VOC 2012 trainval的结合)作为训练集,包含来自20个类的16551个图像。测试集为VOC 2007测试,由4952幅图像组成。骨干网为Darknet608。我们完全遵循从(Rezatofighi等人。2019),最大迭代设置为50K,每个损失的性能已在表1中报告。我们使用相同的性能度量,即AP(跨越不同IoU阈值的10个mAP的平均值)=(AP50+AP55+。. . +AP95)/10和AP75(地图@0.75)。我们还报告了使用GIoU度量的评估结果。
表1:使用LIoU(基线)、LGIoU、LDIOU和LCIoU训练的YOLOv3(Redmon和Farhadi 2018)的定量比较。(D)表示使用DIoU NMS。结果报告在PASCAL-VOC 2007测试集上。
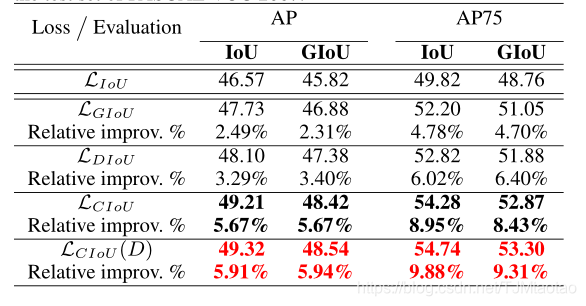
如表1所示,GIoU作为IoU的一个通用版本,确实实现了一定程度的性能提升。而以IoU作为评价指标,DIoU损耗可以提高性能,其增益分别为3.29%和6.02%AP75。CIoU损失考虑了两个包围盒的三个重要几何因素,带来了惊人的性能增益,即5.67%的AP和8.95%的AP75。从图6来看,
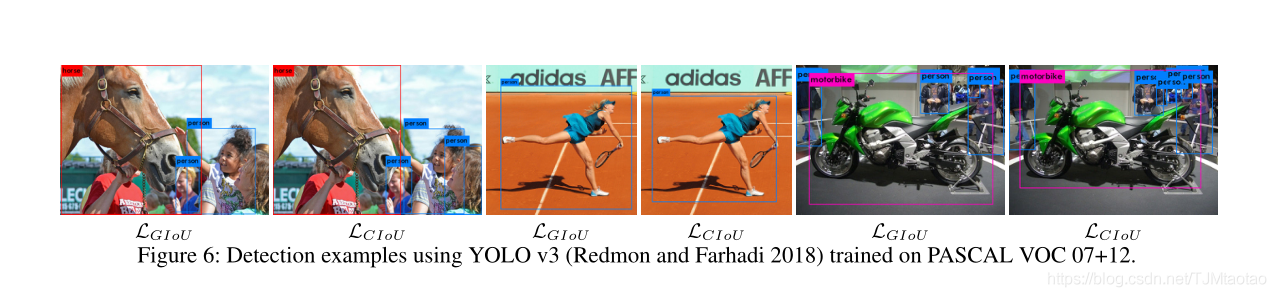
我们可以了解到检测框通过CIoU损失比GIoU损失更准确。最后,CIoU损失与DIoU NMS相结合,使AP和AP75分别提高了5.91%和9.88%。在GIoU度量方面,我们也可以得出相同的结论,验证了所提出方法的有效性。我们注意到GIoU度量实际上与IoU度量一致,因此我们只报告以下实验的IoU度量
SSD on PASCAL VOC
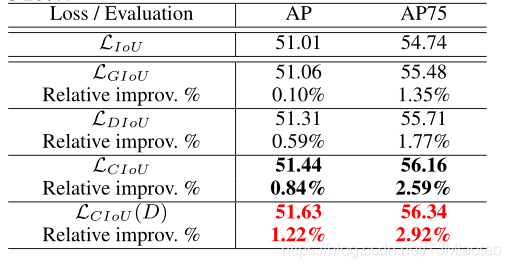
我们使用另一种流行的单级SSD方法进行进一步的评价实验。采用了SSD2的最新PyTorch实现。训练集和测试集在PASCAL VOC上与YOLO v3共享相同的设置。按照默认的训练协议,最大迭代设置为120K。骨干网为ResNet-50FPN。默认的包围盒回归损失是平滑的1-范数,与基于IoU的损失有不同的大小。因此,回归损失和分类损失之间应该有一个更合适的权衡权。我们观察到,对于密集锚定算法,适当增加回归损失可以提高性能。因此,为了进行公平比较,我们将这些基于IoU的损失的回归损失权重定为5。然后我们使用IoU、GIoU、DIoU和CIoU损失来训练模型。表2给出了定量比较,其中报告了IoU度量的AP和AP75。对于SSD,我们可以看到与IoU和GIoU损失相比,DIoU和CIoU损失的持续改善。
表2:SSD的定量比较(Liu等人。2016)使用Liou(基线)、LGIoU、Ldiouandlcou进行培训。(D)表示使用DIoU NMS。结果报告在PASCAL-VOC 2007测试集上。
Faster R-CNN on MS COCO
我们还对另一个更困难和更复杂的数据集MS COCO 2017(Lin等人。2014年)
使用更快的R-CNN3。MS-COCO是一个大规模的数据集,包含超过118K个用于训练的图像和5K个用于评估的图像。遵循(Rezatofighi等人。2019年),我们使用DIoU和CIoU损失与IoU和GIoU损失进行了比较,对模型进行了培训。骨干网为ResNet-50-FPN。除AP和AP75指标外,还包括大、中、小尺度对象的评价指标。对于回归损失的权衡权重,我们将所有损失的权重设置为12,以便进行公平比较。表3报告了定量比较。
快速R-CNN是一种具有密集锚箱的检测算法,在初始情况下通常具有较高的IoU水平。从几何学上讲,R-CNN回归速度较快的情形很可能出现在图4的盆地中,其中IoU、GIoU和DIoU损失都有很好的表现。因此,如表3所示,GIoU损失的收益比基线IoU损失的收益很小。但是,我们的DIoU和CIoU损失仍然比IoU和GIoU损失在AP、AP75、APmedium和APlarge方面有助于提高性能。尤其是CIoU亏损带来的收益非常显著。从图7可以很容易地找到比GIoU loss更精确的CIoU loss检测盒。有人可能已经注意到,就APsmall而言,CIoU损失略低于原始的IoU损失,而DIoU损失优于所有其他损失。也就是说,宽高比的一致性可能不影响小对象的回归精度。事实上,对于小目标,中心点距离比纵横比更重要是合理的,并且纵横比可能会削弱两个长方体之间归一化距离的影响。然而,CIoU的损失对大中型物体的效果更好,对小的物体,DIoU-NMS可以减轻不良影响
Discussion on DIoU-NMS
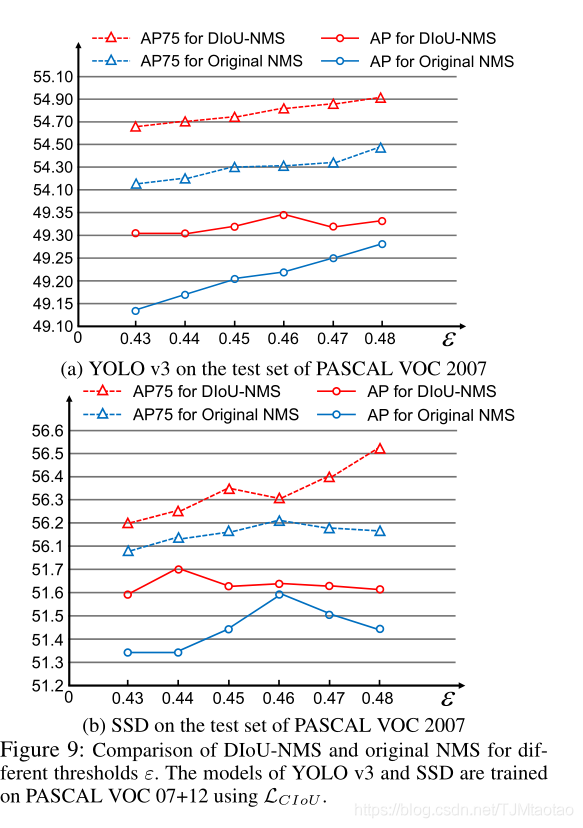
在表1、表2和表3中,我们报告了CIoU损失与原始NMS(LCIoU)和DIoU NMS(LCIoU(D))合作的结果,其中阈值遵循原始NMS的默认设置,即对于YOLO v3和SSD,ε=0.45;对于更快的R-CNN,ε=0.50。可以发现,在大多数情况下,DIoUNMS比原来的NMS有更进一步的性能改进。图8显示,DIoU NMS可以更好地保留正确的检测框,其中YOLO v3训练的PASCAL VOC被用来检测MS-COCO上的对象。为了进一步验证DIoU NMS相对于原始NMS的优越性,我们进行了原始NMS和DIoU NMS与yolov3和ssdtrainingouloss相结合的比较实验,给出了原始NMS和DIoU NMS在较宽阈值范围内的比较结果[0.43,0.48]。从图9可以看出,对于每个阈值,DIoU NMS都优于原始NMS。此外,值得注意的是,即使是最差性能的DIoU NMS也至少比原始NMS的最佳性能具有可比性或更好的性能。也就是说,即使不仔细调整阈值ε,我们的DIoU NMS通常也能比原始NMS表现更好。

Conclusion
本文提出了边界盒回归的两个损失,即DIoU损失和CIoU损失,以及抑制冗余检测盒的DIoUNMS。通过直接最小化两个中心点的归一化距离,DIoU损失比GIoU损失能获得更快的收敛速度。CIoU损失考虑了重叠面积、中心点距离和纵横比三个几何性质,具有更快的收敛速度和更好的性能。提出的损耗和DIoU NMS可以很容易地并入任何目标检测流水线,并在基准上取得优异的效果。
感谢国家自然科学基金(编号:91746107、61801326)和中国人民公安大学基础科研项目运行费(编号:2018JKF617、2019JKF111)对本工作的部分资助。我们也感谢左王蒙教授、宋占杰教授和王军教授的宝贵建议和帮助。
References
Bae, S.-H. 2019. Object detection based on region decomposition
and assembly. In The AAAI Conference on Artificial Intelligence.
Bodla, N.; Singh, B.; Chellappa, R.; and Davis, L. S. 2017. Soft-
nms – improving object detection with one line of code. In The
IEEE International Conference on Computer Vision (ICCV).
Cai, Z., and V asconcelos, N. 2018. Cascade r-cnn: Delving into
high quality object detection. In The IEEE Conference on Com-
puter Vision and Pattern Recognition (CVPR).
Cui, Y .; Jia, M.; Lin, T.-Y .; Song, Y .; and Belongie, S. 2019. Class-
balanced loss based on effective number of samples. In The IEEE
Conference on Computer Vision and Pattern Recognition (CVPR).
Everingham, M.; V an Gool, L.; Williams, C. K. I.; Winn, J.; and
Zisserman, A. 2010. The pascal visual object classes (voc) chal-
lenge. International Journal of Computer Vision 88(2):303–338.
Fu, C.-Y .; Liu, W.; Ranga, A.; Tyagi, A.; and Berg, A. C. 2017.
DSSD: Deconvolutional single shot detector. arXiv:1701.06659.
Girshick, R.; Donahue, J.; Darrell, T.; and Malik, J. 2014. Rich fea-
ture hierarchies for accurate object detection and semantic segmen-
tation. In The IEEE Conference on Computer Vision and Pattern
Recognition (CVPR).
Girshick, R. 2015. Fast r-cnn. In The IEEE International Confer-
ence on Computer Vision (ICCV).
He, K.; Gkioxari, G.; Dollar, P .; and Girshick, R. 2017. Mask r-
cnn. In The IEEE International Conference on Computer Vision
(ICCV).
He, Y .; Zhu, C.; Wang, J.; Savvides, M.; and Zhang, X. 2019.
Bounding box regression with uncertainty for accurate object de-
tection. In The IEEE Conference on Computer Vision and Pattern
Recognition (CVPR).
Jiang, B.; Luo, R.; Mao, J.; Xiao, T.; and Jiang, Y . 2018. Acqui-
sition of localization confidence for accurate object detection. In
The European Conference on Computer Vision (ECCV).
Law, H., and Deng, J. 2018. Cornernet: Detecting objects as
paired keypoints. In The European Conference on Computer Vi-
sion (ECCV).
Li, B.; Liu, Y .; and Wang, X. 2019. Gradient harmonized single-
stage detector. In The AAAI Conference on Artificial Intelligence.
Lin, T.-Y .; Maire, M.; Belongie, S.; Hays, J.; Perona, P .; Ramanan,
D.; Dollár, P .; and Zitnick, C. L. 2014. Microsoft coco: Common
objects in context. In The European Conference on Computer Vi-
sion (ECCV).
Lin, T.-Y .; Goyal, P .; Girshick, R.; He, K.; and Dollar, P . 2017.
Focal loss for dense object detection. In The IEEE International
Conference on Computer Vision (ICCV).
Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y .;
and Berg, A. C. 2016. Ssd: Single shot multibox detector. In The
European Conference on Computer Vision (ECCV).
Liu, S.; Huang, D.; and Wang, Y . 2019. Adaptive nms: Refin-
ing pedestrian detection in a crowd. In The IEEE Conference on
Computer Vision and Pattern Recognition (CVPR).
Pang, J.; Chen, K.; Shi, J.; Feng, H.; Ouyang, W.; and Lin, D. 2019.
Libra r-cnn: Towards balanced learning for object detection. In
The IEEE Conference on Computer Vision and Pattern Recognition
(CVPR).
Redmon, J., and Farhadi, A. 2017. Y olo9000: Better, faster,
stronger. In The IEEE Conference on Computer Vision and Pat-
tern Recognition (CVPR).
Redmon, J., and Farhadi, A. 2018. Y olov3: An incremental im-
provement. arXiv:1804.02767.
Redmon, J.; Divvala, S.; Girshick, R.; and Farhadi, A. 2016. Y ou
only look once: Unified, real-time object detection. In The IEEE
Conference on Computer Vision and Pattern Recognition (CVPR).
Ren, S.; He, K.; Girshick, R.; and Sun, J. 2015. Faster r-cnn:
Towards real-time object detection with region proposal networks.
In Advances in Neural Information Processing Systems 28.
Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; and
Savarese, S. 2019. Generalized intersection over union: A metric
and a loss for bounding box regression. In The IEEE Conference
on Computer Vision and Pattern Recognition (CVPR).
Song, T.; Sun, L.; Xie, D.; Sun, H.; and Pu, S. 2018. Small-scale
pedestrian detection based on topological line localization and tem-
poral feature aggregation. In The European Conference on Com-
puter Vision (ECCV).
Tian, Z.; Shen, C.; Chen, H.; and He, T. 2019. FCOS: Fully con-
volutional one-stage object detection. In The IEEE International
Conference on Computer Vision (ICCV).
Wang, H.; Wang, Q.; Gao, M.; Li, P .; and Zuo, W. 2018. Multi-
scale location-aware kernel representation for object detection. In
The IEEE Conference on Computer Vision and Pattern Recognition
(CVPR).
Wang, H.; Wang, Q.; Yang, F.; Zhang, W.; and Zuo, W. 2019.
Data augmentation for object detection via progressive and selec-
tive instance-switching. arXiv:1906.00358.
Yang, T.; Zhang, X.; Li, Z.; Zhang, W.; and Sun, J. 2018. Metaan-
chor: Learning to detect objects with customized anchors. In Ad-
vances in Neural Information Processing Systems.
Yang, Z.; Liu, S.; Hu, H.; Wang, L.; and Lin, S. 2019. Reppoints:
Point set representation for object detection. In The IEEE Interna-
tional Conference on Computer Vision (ICCV).
Y u, J.; Jiang, Y .; Wang, Z.; Cao, Z.; and Huang, T. 2016. Unitbox:
An advanced object detection network. In Proceedings of the ACM
International Conference on Multimedia.
Zhu, C.; He, Y .; and Savvides, M. 2019. Feature selective anchor-
free module for single-shot object detection. In The IEEE Confer-
ence on Computer Vision and Pattern Recognition (CVPR).














 972
972











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









