







本文主要介绍了生成式AI的相关技术,特别是卷积神经网络(CNN)在图像识别领域的应用。本文为该系列第二篇,

引言
如果看明白了上一篇文章对神经网络和深度学习的介绍,再来逐步深入了解AI相关的概念和原理应该就相对容易了。
希望上一篇文章能给大家一点印象:AI并没有想象中复杂。AI能处理海量信息,但是它并没有人类难以理解、异常复杂的机制。因为只有机制相对简单,消耗的能源才能少,计算的速度才能快,处理的信息才能够多。自然界也一样,如果大脑的机制比现在更复杂一些,估计脑子要烧掉。
废话不多说,上一篇文章我们看到了,最基础的神经网络可以用来识别手写数字;同时也发现如果神经网络“学”的不好,对问题的一般规律没有抽象对,就会出现过拟合,过拟合往往跟数据和模型两个因素有关。本篇文章我们会讲图像识别领域有哪些经验来应对过拟合,也会讲神经网络和深度学习如何扩展到自然语言处理等其它领域。

卷积神经网络
上文提到,神经网络可以用来进行图像识别。既然是图像识别,那么我们是否可以结合计算机图形学的已知手段,来提升深度学习的效果呢?答案是肯定的。卷积神经网络(Convolutional Neural Network)就是这样一种网络,通过结合图形学方法,大大优化了图像识别的效果和效率。
▐ 卷积神经网络原理
如果要给卷积神经网络的过程和原理打个比方,设想一下小朋友们是如何画出一个人的。当要求小朋友画人时,他们是没法画出那么多细节的。小朋友只会画火柴人:通过线条画出轮廓(比如弧线、直角),通过轮廓组成形状(比如弧线连在一起组成头部、线+直角组成身体),通过形状组成物体(比如头部在上方、身体在中间、手脚在四周)。尽管最后的作品相当简单,但却抓住了人物的核心特征,我们仍能辨认出它是人的画像。
卷积神经网络识别图像的过程和原理也类似,也是一个多步的过程,比如先卷积找到线条,池化再卷积找到轮廓,池化再卷积找到形状,最后再通过形状组合来识别出图中是一个人:
捕捉特征 - 卷积操作(convolve):卷积层通过类似于图像处理中的滤镜,扫描整个图像以强调物体的边缘和纹理等基础特征。它可以看作“绘制线条”这一步,捕捉出图像中的局部特征,以作进一步识别。
简化并强调 - 池化(pooling):在卷积提炼出的特征之后,池化层帮助降低特征数据的大小,这同时简化了图像的复杂性和计算的需求。池化层的作用就像是在绘画中刻意忽略一些不太重要的细节,以突出轮廓和整体结构。
重复这一过程,提升抽象程度:卷积神经网络往往不止一次卷积和池化操作。通过一系列重复的卷积和池化,网络逐渐从简单特征中筛选并组合出更为复杂的形状和模式,类似于小朋友从线条到形状再到完整人物的绘制过程。
特征合成 - 全连接层:就如同小朋友们最终会把头部、身体及四肢放到合适的位置来完成一个人的图画,卷积神经网络在多层次抽象出的特征基础上,利用全连接层进行最终的整合和分类工作。全连接层通过考虑整个图像级的特征,并学习它们之间的复杂关系,从而完成从特征到最终目标识别(如识别出图中的人)的过程。全链接层大家很熟悉,就是上文提到的由 dense layer 组成的神经网络。
那么,相对于前面的神经网络,卷积神经网络关键做了哪些事情,提升了图像识别的效果和效率?
经过多轮卷积操作,后面的全连接层(同前文的神经网络)需要处理的对象,由“现实语义”不明显的像素、颜色,变成了边缘、轮廓、纹理等具有一定“现实语义”的特征,极大提升了图像识别的准确度。
卷积操作使全连接层要处理的最小单元提升了一层(就好像你写代码不是在写一行一行语句,而是用链将原子能力编排起来),此外池化操作也相对缩小了要处理的图像,这两者理论上能起到提升效率的作用(和其它相近准确度的手段相比)。
▐ 卷积神经网络中的图形学手段—滤镜
那么,卷积神经网络究竟结合了那种图形学手段呢?我们可以看看卷积神经网络中的卷积核(kernel),图形学中称为滤镜。熟悉photoshop或者GIMP的同学一定知道,比如下面的4种滤镜(图中的3x3向量):
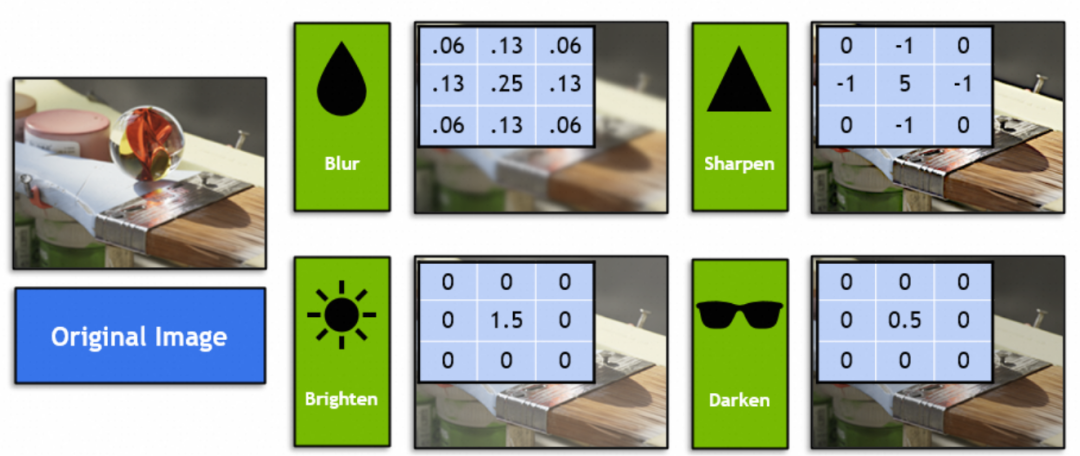
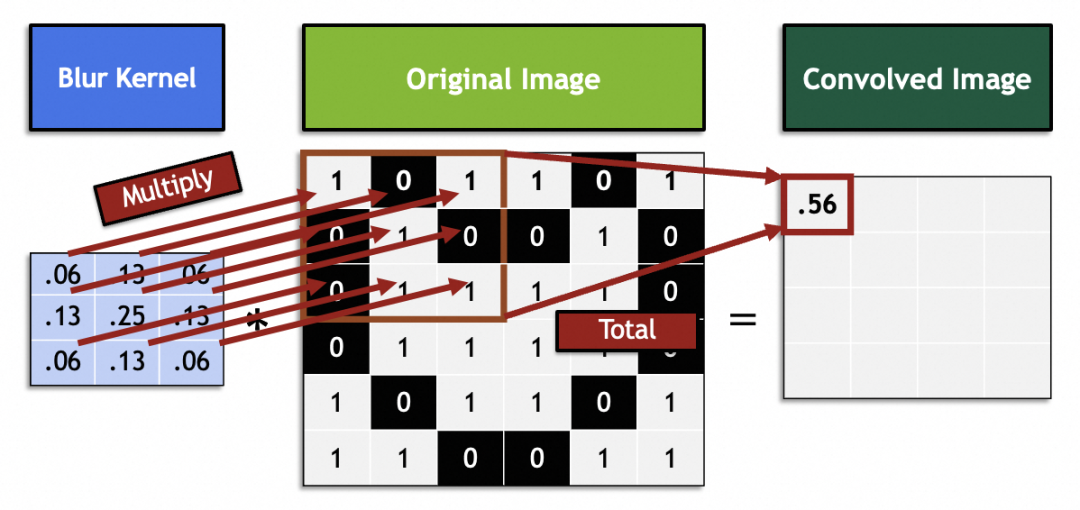
滤镜在数学里就是线性代数向量运算:原图中每3x3向量和滤镜的3x3向量相乘求和。例如图中这个滤镜向量通过将相邻9个像素糅合到中间一点实现了模糊化:
经验数据:卷积神经网络里,选用3x3大小的卷积核就能取得很好的效果。
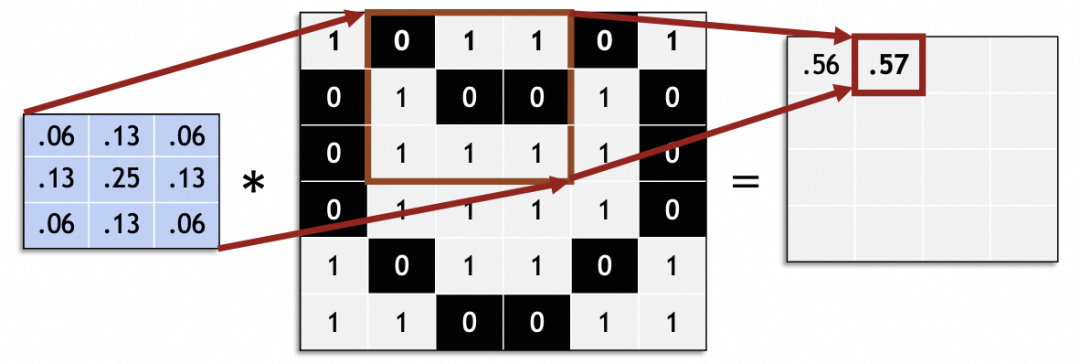
通过滑动处理完整个原图,生成新的图片:
卷积神经网络里,滑动步长(stride)一般为1,非1值存在原图片大小无法整除stride等问题。
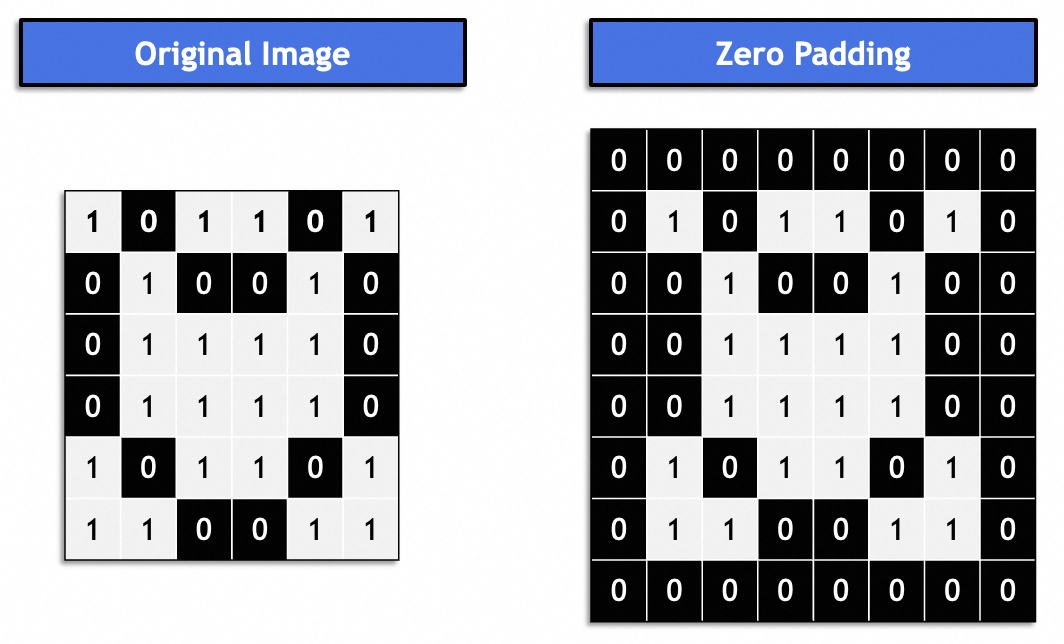
我们可以看出,结果图比原图要小,不断变化的大小不利于连续处理,一般通过padding来解决:
一般是“same padding”,结果图和原图保持一致。一般用0填充。
那么,卷积核或者滤镜究竟用来解决什么问题呢?我们可以看一下下面的卷积核,他们通过特定的向量值,使原图中的竖边和横边被强化了。如图所示,卷积核确实可以用来提取原图中的特征:

最后,图形学中的滤镜如何应用到神经网络里呢?
首先,卷积核向量和原图向量相乘求和(再激活),和神经元参数和输入相乘求和再激活类似,卷积核完全可以用神经网络里的神经元来表达。
其次,和上面给出的模糊、锐化、横纵边滤镜已知向量值不同,卷积核的向量值是可训练、训练出来的,是用来动态捕获输入特征的,和神经元参数的用法一致。
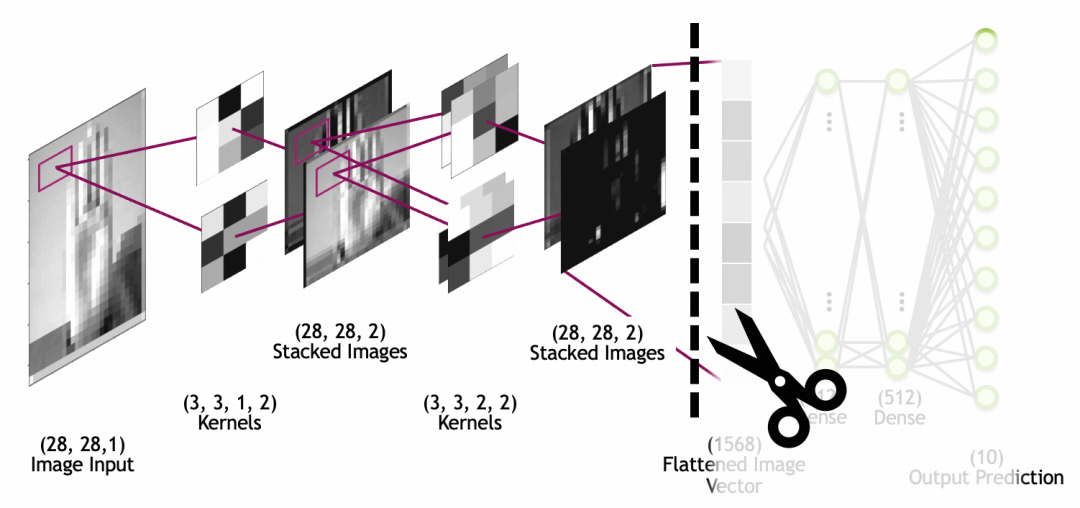
实际上,一个卷积核就是卷积层的一个神经元。和全连接层神经元类似,它的参数也是输入权重+偏置常量,其中,输入权重的个数等同于输入的个数,因为输入的图像是堆叠的图像,所以输入权重的个数为x * y * n,偏置常量固定为1个,总共是x * y * n + 1个。如图这个2叠、3x3的kernel,它的参数个数就是 3 * 3 * 2 + 1 = 19。
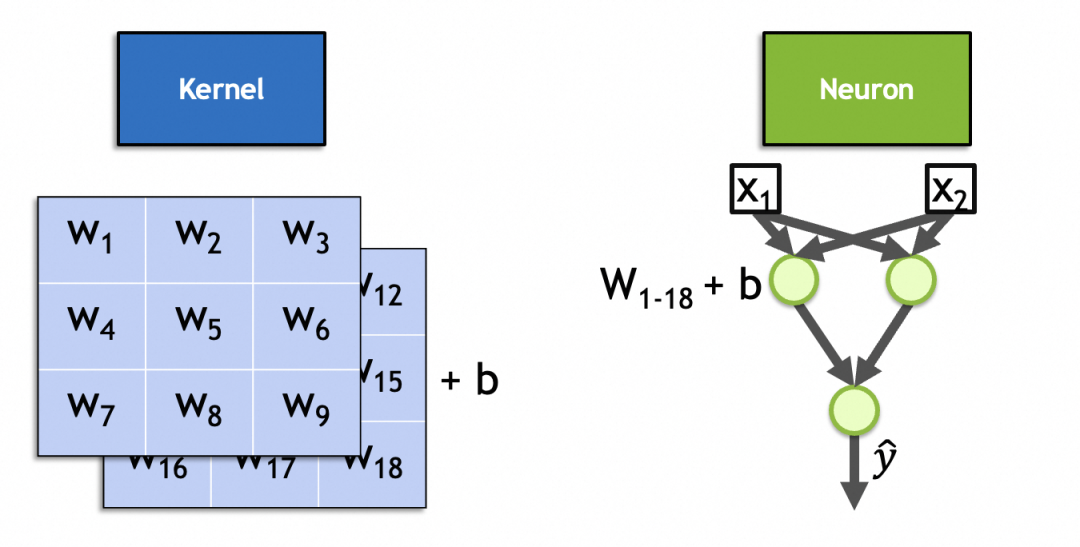
▐ 卷积神经网络计算过程
卷积神经网络的计算和前文神经网络一样,前向传播、反向传播,不赘述。
下图中,image input是输入图像,28x28大小,1叠(1个灰阶图层);kernels是卷积层,注意stacked images不是网络层,而是卷积层的输出;图中最后一个stacked images,经过flatten层打平成一维数组(图中的flattened image vector),供后面的全连接层网络使用(全连接层上文已讲过)。
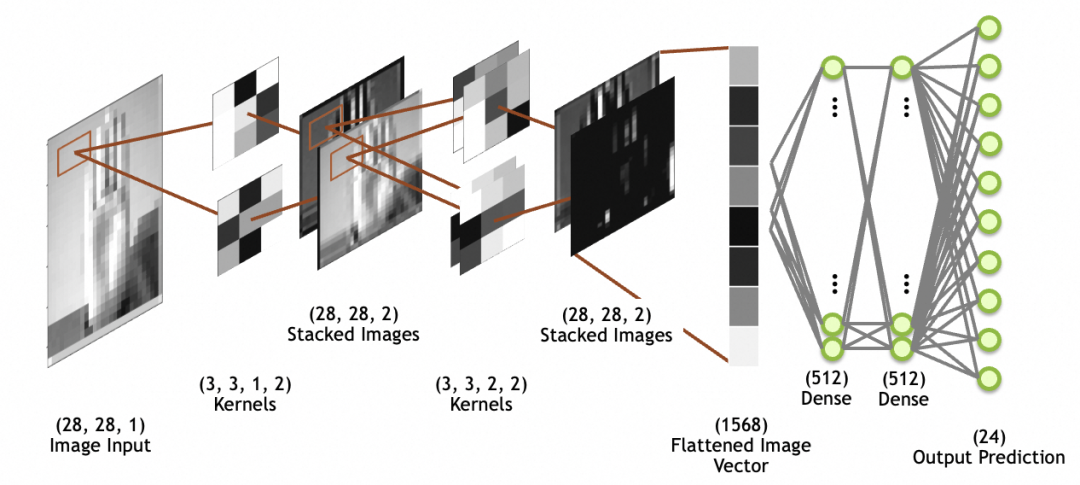
卷积
这里重点看一下卷积层,卷积层前向传播是和输入的堆叠图像计算得出新的堆叠图像,反向传播是通过偏导数调整自身的参数。
注意,和前文全连接层(Dense)神经元输出是一个数值不同,卷积核神经元每次相乘求和激活得到的是一个数,结合两个方向不断滑动最后能得到一个二维图。
下图中,中间是卷积层,左边是输入,右边是输出。
输入是x * y * N的堆叠图像。其中,x=28,y=28(28 * 28 * N)。
卷积层每个神经元因为要和输入相乘,所以也是N叠,假设神经元采用3 * 3大小,则每个神经元是3 * 3 * N。
输出经过padding,每叠大小和输入保持一致,28 * 28。
输出堆叠图像的每一叠为输入堆叠图像x单个神经元的结果,所以叠数和卷积层神经元个数一致。假设卷积层有M个神经元,则输出堆叠图像为28 * 28 * M。
这里强调一下,卷积层每个神经元的叠数=输入图像的叠数。输出图像的叠数=卷积层神经元的个数。
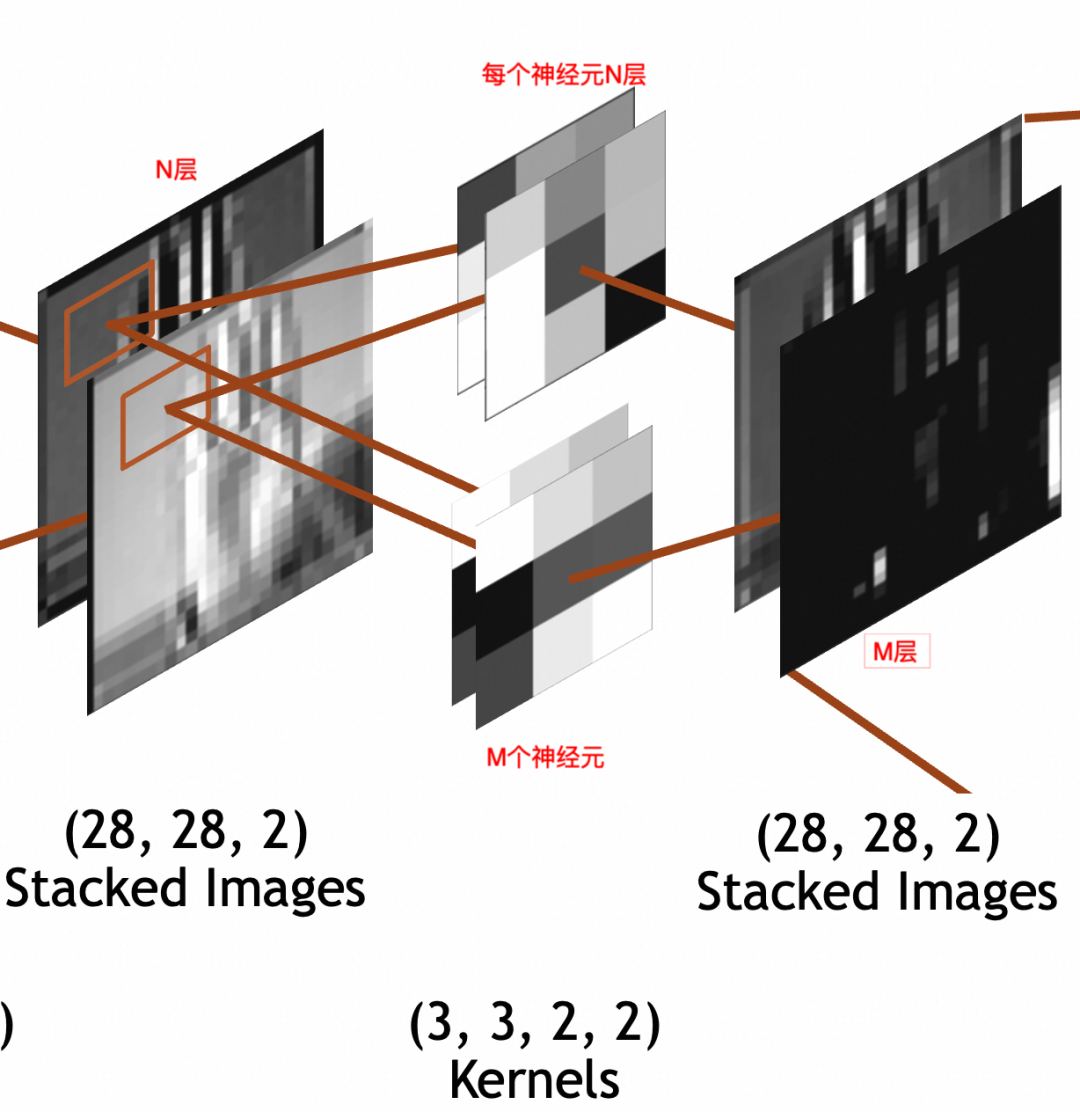
最后看一下神经元参数个数。3 * 3 * N的卷积核,每次要和N叠输入图像的3 * 3部分相乘,所以权重参数(weights)个数为3 * 3 * N,此外还通过一个偏置(bias)整体左右移。所以总参数个数为3 * 3 * N + 1,激活结果计算公式还是和上文普通神经元一样output = activation_function(W * X + b)。
为了神经网络整体处理方便,网络的输入图像、中间的堆叠图像都被统一成了
x * y * Z三维数组结构,但是两者关于叠/层的语义是不同的。输入图像的语义是图像的图层,不管是灰阶图像的1层,RGB的3层,还是RGBA的4层,是有现实关联性的。堆叠图像的各层分别是输入图像和单个神经元计算的结果,是一个特征,相互之间没有关联性,比如一层可能是纵边特征,另一层可能是横边特征。
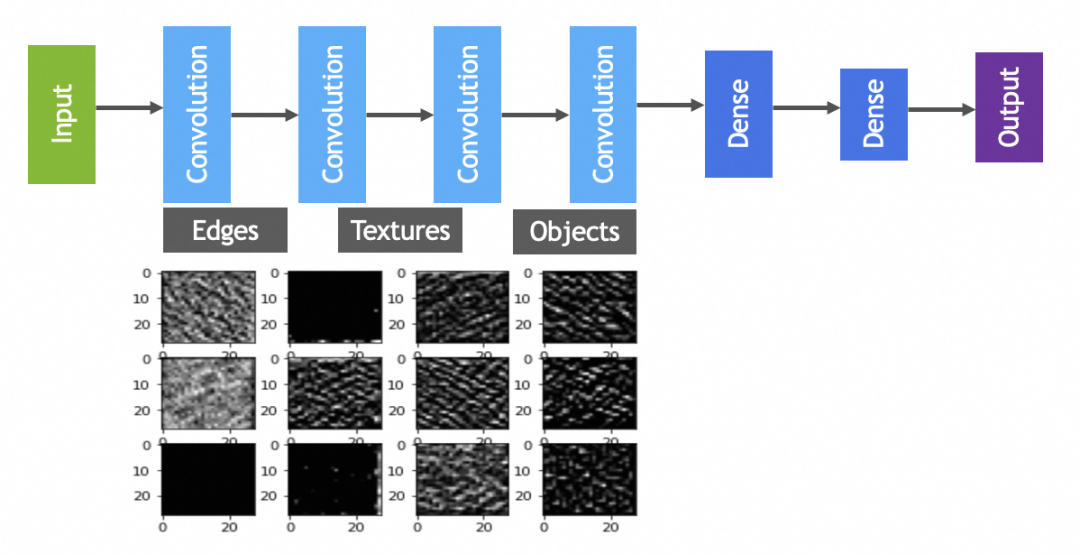
讲原理时已经提到过,一般会有多轮卷积,主要目的分别是从原图提取最小的特征,从最小特征中提取中等特征,……,如下图所示:
池化
池化层的作用,主要是通过缩小图像,丢弃次要特征,保留主要特征:
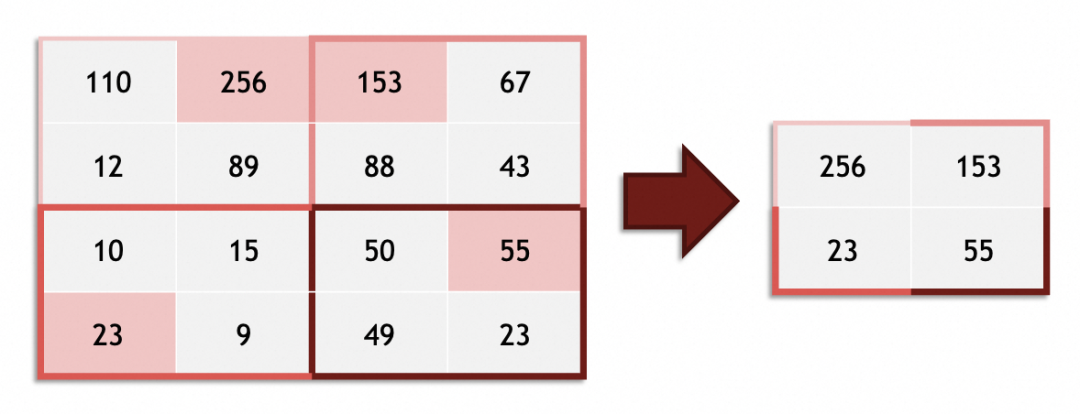
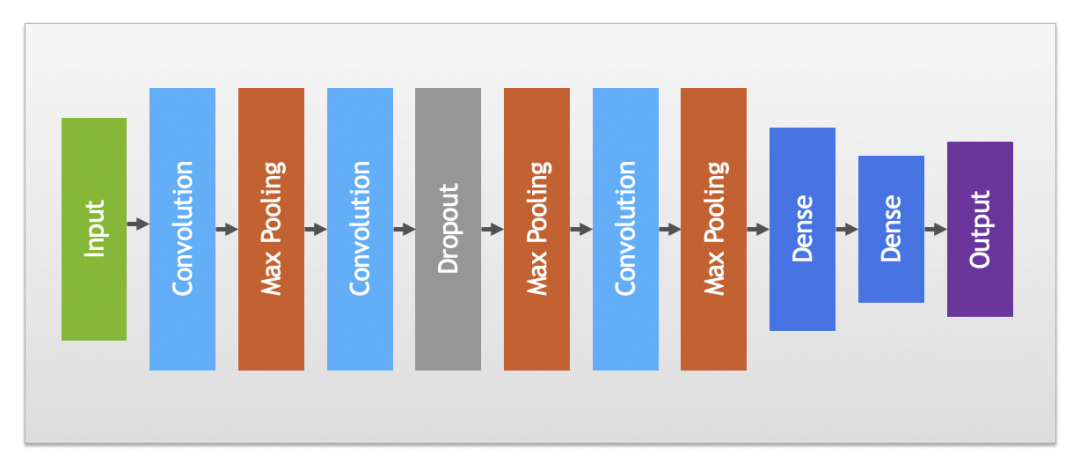
实践中卷积和池化层一般会搭配使用,完整卷积神经网络如下图:
其它
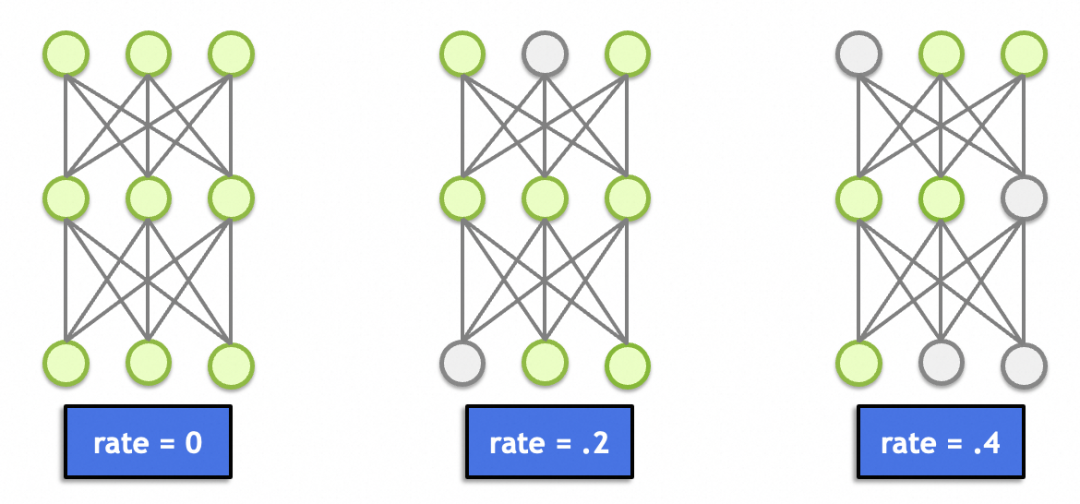
这里面还有一个丢弃层(Dropout),这个理论上跟图形学、图像处理没啥关系。主要作用是随机丢弃一定比例节点的输入(置0),避免因为节点过多(总参数过多、记忆能力太强)导致记忆效应,产生过拟合。
▐ 卷积神经网络实例讲解
本文卷积神经网络讲解的实例是对美国手语的识别,因为是手语照片,相对上文手写文字的案例来讲干扰因素过多,比如背景、衣服、掌纹等,所以采用普通神经网络过拟合比较严重。后面可以看到,改用卷积神经网络后,结果提升了不少。
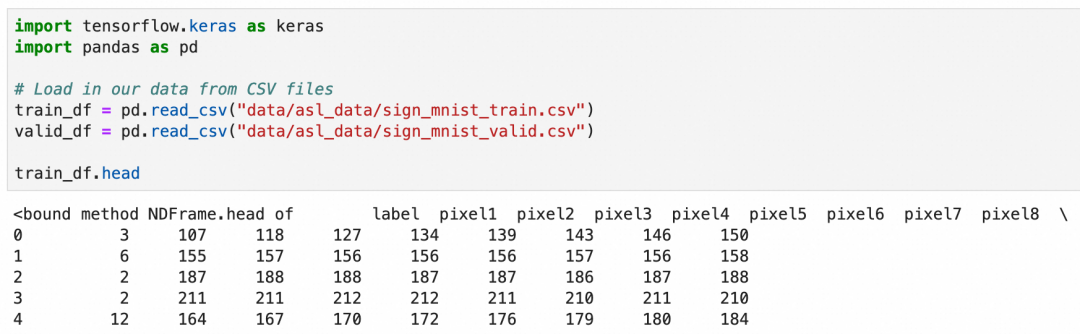
美国手语一共26个字母,其中2个字母带动作,这里只识别24个静止的字母。这次的数据集是使用csv文件存储的,可以加载后查看一下数据概貌:
csv文件一共785列,第一列是label,值是1-24,表示24种字母。第2到785列分别存放的灰阶值,值是0-255,表示从黑到白的颜色。
处理一下加载的值,将标签存入y_train和y_valid,784个像素值保留到x_train和x_valid:
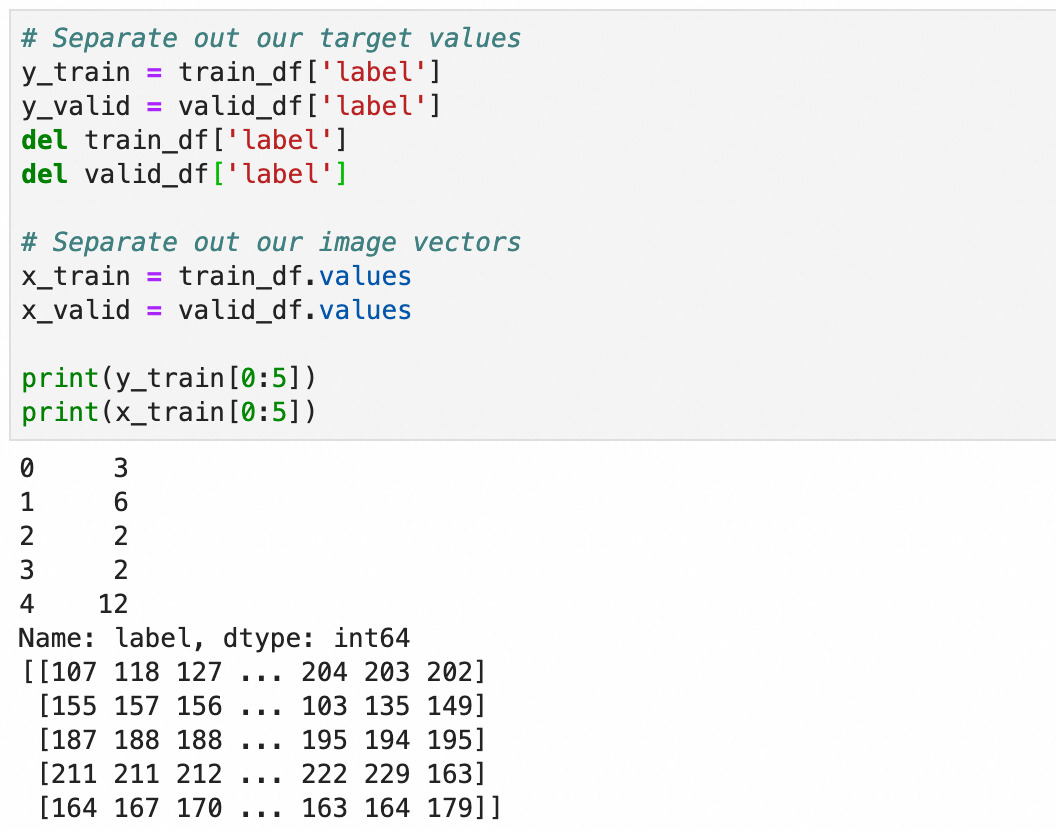
和上文一致,将y转成one-hot编码,用于分类算法,x转成0.0-1.0之间的浮点数:
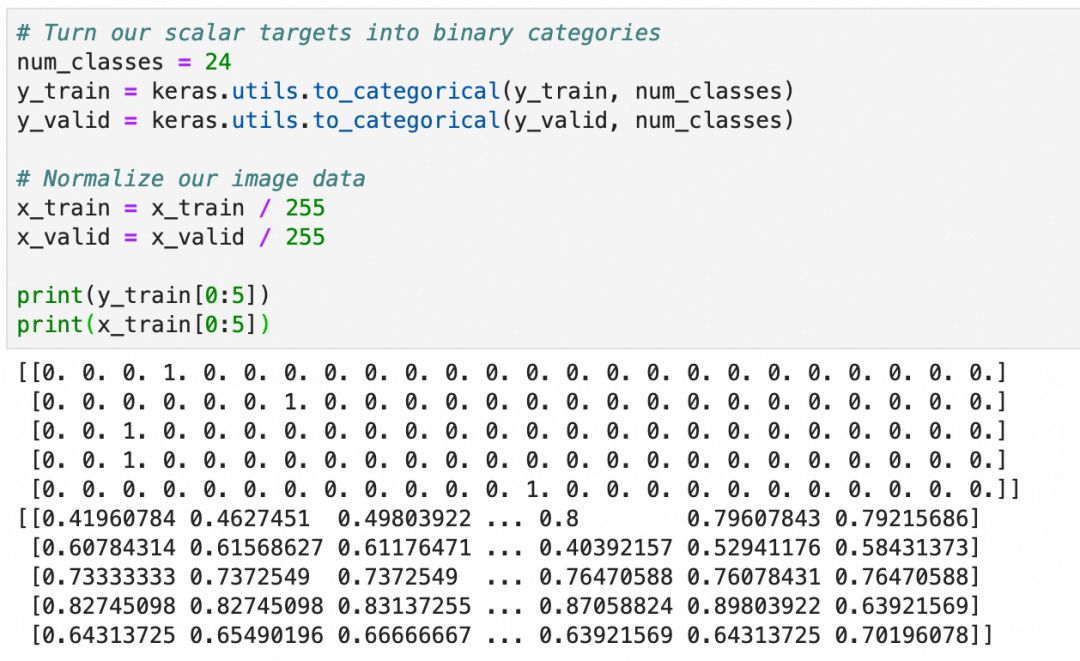
图像是用2维数组存储 ({图像个数}, {784个像素值}),需要转成4维数组。第1维为图像个数保持不动,中间2维为图片大小28*28,最后一维此时只有1个灰阶值。神经网络计算过程中,随着特征抽取、存储的变多,最后一维的大小会增加。


下面是我们希望采用的卷积神经网络结构:
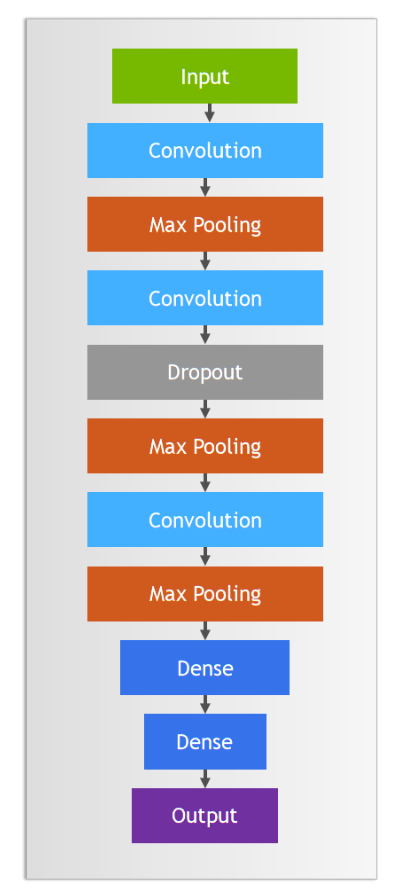
构建语句,其中:
Conv2D(75, (3, 3), stride=1, padding="same", activation="relu", input_shape=(28, 28, 1))创建一个卷积层,输入是28*28*1,75个神经元,每层大小3*3,因为输入是1层,所以每个神经元只有1层。BatchNormalization()创建一个批量标准化层,标准化上层输出平均激活值接近于0,激活值的标准差接近于1。MaxPool2D((2, 2), strides=2, padding="same")创建一个池化层,每2*2像素保留1像素,即长宽各缩小1倍。Dropout(0.2)创建一个丢弃层,丢弃20%输入。

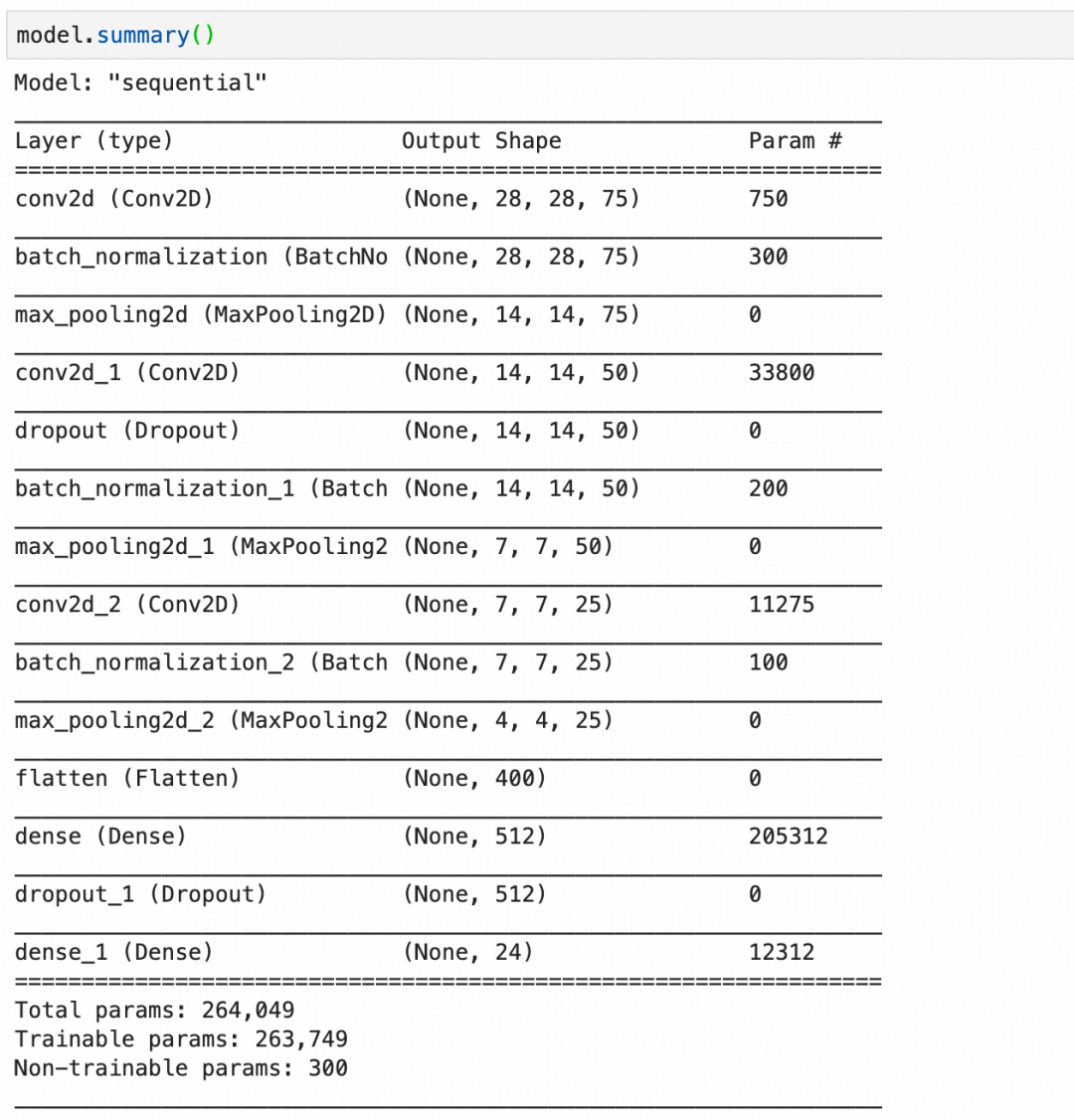
最后看看参数的计算:
第1层,卷积层,75个神经元,每个神经元 3*3*1+1 个参数,一共750个参数。
第2层,批量标准化层,75层输入,每层4个参数,其中2个可训练参数:缩放和偏移,还有2个不可训练参数,存储本批数据的统计值。一共300个参数。
第3层,池化层,池化层都是运算,没有参数。
第4层,卷积层,50个神经元,每个神经元3*3*75+1个参数(每个神经元有75层,分别对应输入的75层),一共33800个参数。
第5层,丢弃层,丢弃层只有运算,没有参数。
第11层,flatten层,只有转化,没有参数。
最后,总的参数个数里,有300个不可训练参数,这是由3个批量标准化层的不可训练参数加在一起构成。
最后采用和上文网络一样的分类用损失函数:

本卷积神经网络校验集的准确度最后能到92%左右,算是比较好的结果:
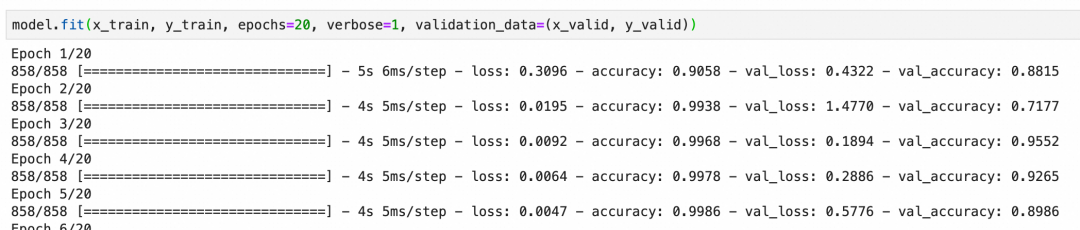
另外,在分享上一篇文章时,有同学问过,神经网络的产出是什么。
产出肯定不是这里跑出来的正确率,神经网络的产出是模型的结构和训练后的参数。这个模型能够用来处理更多的数据,训练后的模型本身就是产出。

数据增强
上面一章我们看了如何通过优化模型来降低过拟合,下面我们来看看如何通过数据增强来提升整体准确度。
数据增强通俗的理解就是通过丰富训练集数据、增加样本数量,减少模型对具体实例的“记忆”、增加模型抽象一般规律的能力。比如我们要训练识别狗的图片,能提供的训练样本当然是越全越好,即需要很多正例(比如金毛、边牧等不同品种的狗),也需要尽可能多的反例(比如猫、狼)。
道理很好理解,但是准备足够多样的训练样本是一件很费事的事情。数据增强是深度学习框架提供的一套工具,通过对现有训练集进行细微变化,比如(适度的)缩放、旋转、位移等等,来批量生产新的训练样本。
需要注意的是,需要根据数据集的特征来决定要进行怎样的变化,比如上一章的手语图片,样本是可以左右翻转的,因为左撇子的手势刚好左右翻转,但是垂直翻转则没有意义;同理,上文中的手写数字,则既不能垂直翻转,也不能左右翻转。
另外,样本的变化也要注意范围,因为网络接收的图片尺寸从一开始就是确定的,这些变化不会改变接收图片的尺寸。比如图片放大缩小,超出图片大小的部分会被裁剪,缺失的部分会被填充。所以,需要考虑变化后的图片是否还有意义,比如手语图片过分放大,放大到只剩一根手指,细节部分是清晰了,但是整体已经完全看不出所代表的手语字母了。
本章不涉及原理,因为这符合人们的一般理解。重点讲一下数据增强的过程:
第1步,还是上一章所用的训练集和模型不变。
train_df = pd.read_csv(...)
...
model = Sequential()
model.add(...)
...
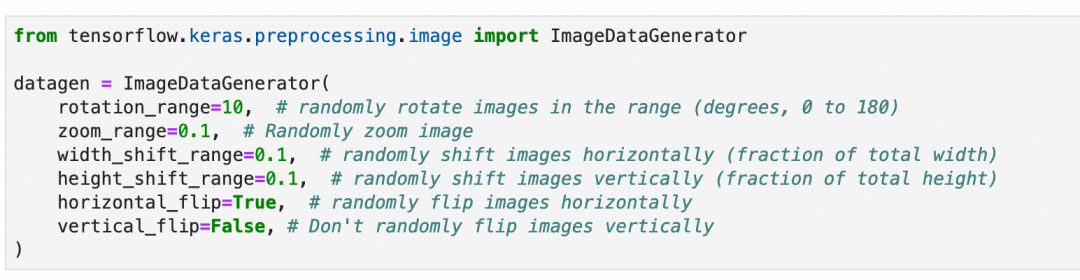
model.compile(...)第2步,准备数据增强用的图像数据生成器:随机旋转10度、缩放10%、左右上下位移10%以内,随机水平翻转,但不垂直翻转。
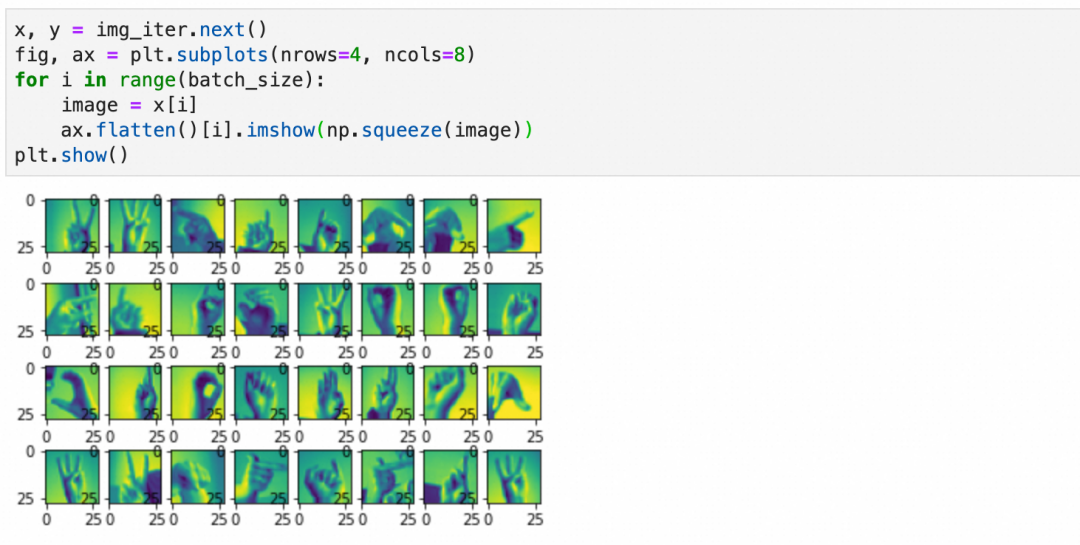
第3步,设置分批生成数据的大小:设置每批生成32张图片。

上面得到的是一个生成数据的迭代器,可以可视化一下第一批数据的样子:
第4步(可选),“训练”数据生成器:
对训练样本的变化除了上面提到的旋转、缩放、位移等,还有基于原训练样本统计值的变化(本案例没用到)。
这一步是统计整个原训练样本,并记录必要的统计信息到数据生成器。

第5步,用数据生成器进行训练:
和上一章案例直接使用原始样本不同model.fit(x_train, y_train, epochs=20, verbose=1, validation_data=(x_valid, y_valid))。这里使用数据生成器生成的内容。
还是20个周期,但是每个周期里训练的样本数等于steps_per_epoch * batch_size,基于丰富度和训练时长兼顾考虑,这里采用steps_per_epoch=len(x_train)/batch_size,每周期样本数和原训练集差不多(但是都是经过数据生成器,随机变化过后的新样本)。
最后结果可以看出,准确度很快就上去了,数据增强有非常明显的效果。


迁移学习和模型微调
最后聊一下迁移学习(transfer learning)和微调(fine-tuning)。
▐ 迁移学习
迁移学习就是通过将已经训练好的模型的一部分摘出来,重新和其它网络层组成新的网络,从而复用网络能力和提升网络效果的过程。
比如,我们可以拿google已经训练好的,进行动物分类的模型,拿来识别自家的猫主子,做一个自动猫门。
为什么要这么做?简单的说就是你自己的训练集不够,你给自家猫拍一千张照片来从头训练一个模型,也可能把外面的流浪猫放进来,因为你缺少足够的正负样本。
因为篇幅原因,这里不详细展开,只讲一下关键步骤。细节可以参考Transfer learning and fine-tuning官方教程:
第1步,摘取预训练模型的前半段(卷积层+池化层),去掉后半部分(include_top=False)。
第2步,拼接模型的后半段为新的、未经训练的全连接层。
第3步,设置前半部分参数不动(trainable=False),拿新的正负样本训练模型的后半段。
你会发现,有了预训练模型的前半段,很快就可以取得不错的结果。
这里我们也可以得出结论,网络前半段的参数,包含了比较通用的特征,比如一般的猫狗,网络后半段则包含了比较具体的特征,比如你家的猫主子。
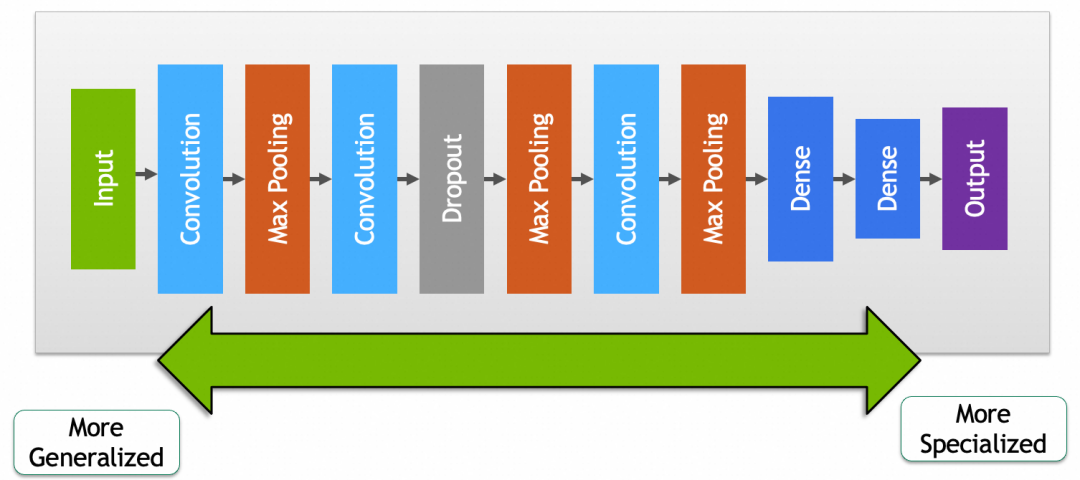
▐ 微调
如果复用网络后,发现效果没有特别满意,可能是因为预训练模型和你要求解的问题没有完全匹配,或者现有模型参数里缺少一些针对性的特征。微调就是通过稍微调整一下预训练模型部分的参数,提升被复用网络效果的过程。
微调的过程很简单,前面3步保持不变,增加下面的步骤:
第4步,设置前半部分参数可训练(trainable=True),同时设置训练步长为一个非常小的值。
第5步,继续训练几个周期,这样整个网络的参数,包括预训练的前半段,和你新加入的后半段,都会按新的数据进行调整,针对特定问题的结果也会更好。
这里要注意两点:
第4步训练步长一定要小,这样每次参数的变化非常小,尽可能的保持预训练模型中的参数(一般特征)。
第3步一定要训练完成,即后半部分已经基于新数据训练过。否则,如果后半部分参数很随机,反向传播时,就算训练步长非常小,前半部分的参数也会发生非常大的波动,导致模型的基础特征被破坏。

结语
高级神经网络不仅包括卷积神经网络,还涵盖了循环神经网络。卷积神经网络主要应用于图像识别的领域,而循环神经网络则广泛用于处理自然语言。随着Transformer模型的出现,自然语言处理的技术有了新的发展。关于自然语言处理的更多细节,将在后续关于Transformer原理的文章中详细介绍,故在此不作过多阐述。
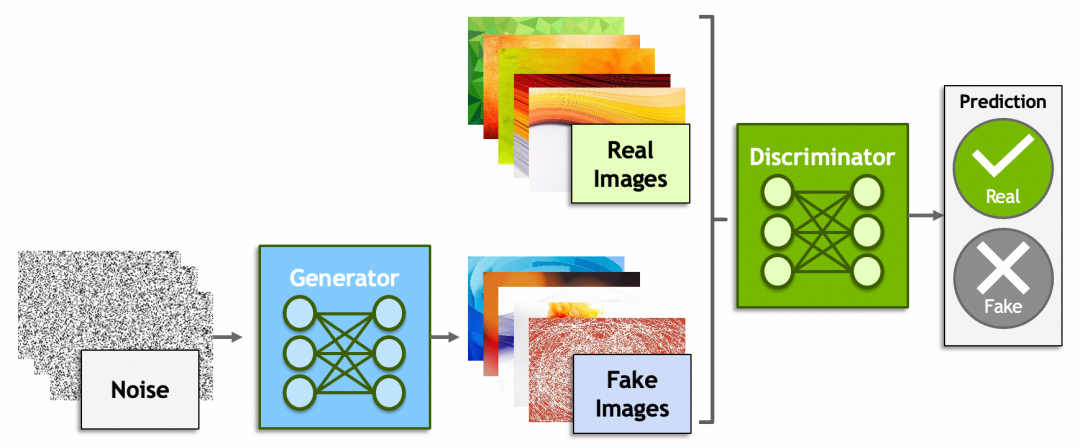
除了神经网络,深度学习里还有一些概念比较有意思,比如生成式对抗网络(Generative Adversarial Networks)、强化学习(Reinforcement Learning)。
生成式对抗网络一方是生成器(Generator)从一堆噪音里生成出假的图片,企图骗过鉴别器(Discriminator);而另一方鉴别器则尽可能的识别出真假图片。原理上还是脱离不了之前讲过的内容,鉴别器会给出一个分数,生成器会根据这个分数反向传播,修改由噪音生成图片的参数。
还记得“前GPT时代”,2022年Google研究员Blake Lemoine爆料AI有自我意识,被公司开除的新闻吗[捂脸哭]?谁说ChatGPT、MidJourney、Sora不是一些骗过了研究员、非常成功的生成式对抗网络呢?然而另一方面,就像【中文房间】描述的问题一样,哪里才是生成式对抗和真正理解的边界?大模型究竟能不能走向通用人工智能?
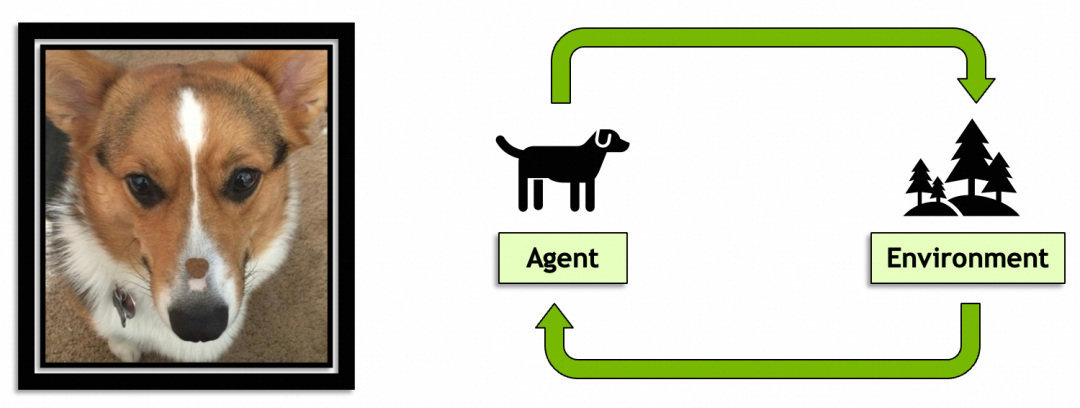
后一个概念,强化学习就是AI从环境中学习的过程和能力,目前机器人领域用得比较多。个人认为这个概念有意思是因为它是通向通用人工智能的必经之路,预计未来会扮演比较重要的角色。
本系列头两篇文章到这里就结束了,希望能激起大家学习AI原理的好奇心和勇气。个人水平有限,如果文章有什么问题,欢迎留言探讨。

团队介绍
天猫国际是中国领先的进口电商平台, 也是阿里巴巴-淘天集团电商技术体系中链路最完整且最为复杂的技术产品之一,也是淘天集团拥有最完整业务形态(平台+直营、跨境、大贸、免税等多业务模式)的业务。在这里我们参与到阿里电商体系的绝大部分核心系统(导购、商家、商品、交易、营销、履约等),同时借助区块链、大数据、AI算法等前沿技术助力业务高速增长。作为贴近业务前沿的技术团队,我们对于电商行业特性、跨境市场研究、未来交易趋势以及未来技术布局等都有着深度的理解。
¤ 拓展阅读 ¤
















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









