







专栏C++学习笔记
《C++ Primer》学习笔记/习题答案 总目录
——————————————————————————————————————————————————————
📚💻 Cpp-Prime5 + Cpp-Primer-Plus6 源代码和课后题
第4章 - 优先级和关系运算符
练习4.1
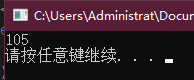
表达式 5 + 10 * 20 / 2 的求值结果是多少?
解:
在算术运算符中,乘法和除法的优先级相同,且均高于加减法的优先级。因此上式的计算结果等价于 5 + ((10 * 20) / 2),= 105,在编程环境中很容易验证这一点。
#include <iostream>
using namespace std;
int main()
{
cout << 5 + ((10 * 20) / 2) << endl;
system("pause");
return 0;
}
练习4.2
根据4.12节中的表,在下述表达式的合理位置添加括号,使得添加括号后运算对象的组合顺序与添加括号前一致。
(a) *vec.begin()
(b) *vec.begin() + 1
解:
运算符优先级表——《C++ Primer》学习笔记(四):优先级和关系运算符。
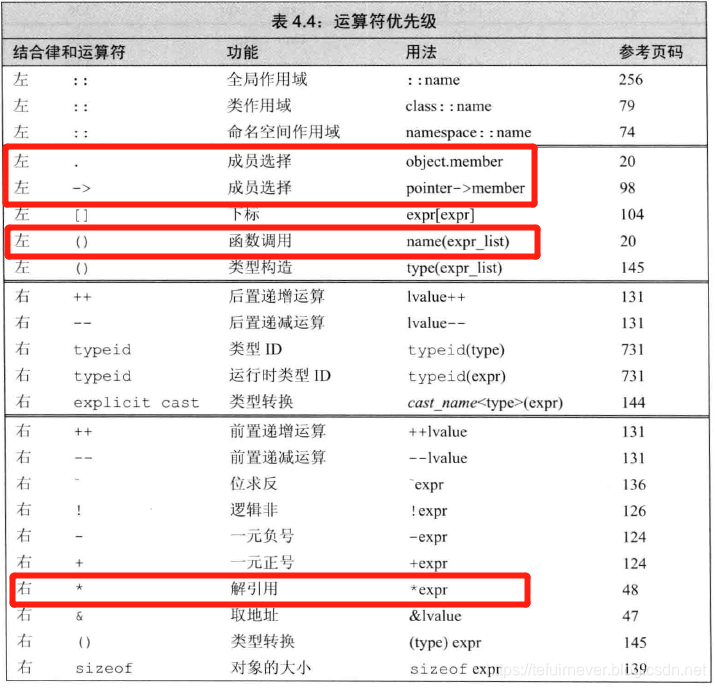
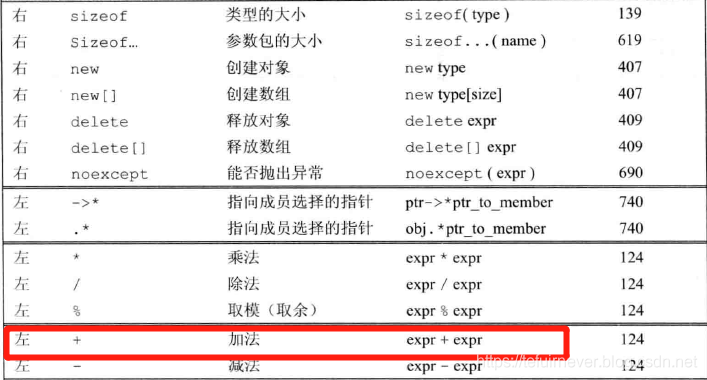
优先级最高的是成员选择运算符和函数调用运算符,其次是解引用运算符,最后是加法运算符。因此等价后的式子是:
*(vec.begin())
(*(vec.begin())) + 1
可以通过一个程序验证一下:
#include <iostream>
#include <vector>
#include <ctime>
#include <cstdlib>
using namespace std;
int main()
{
vector<int> vec;
srand((unsigned)time(NULL));
cout << "系统自动为向量生成一组元素。。。。。。" << endl;
for (int i = 0; i != 10; i++)
vec.push_back(rand() % 100);
cout << "生成的向量数据是:" << endl;
for (auto c : vec)
cout << c << " ";
cout << endl;
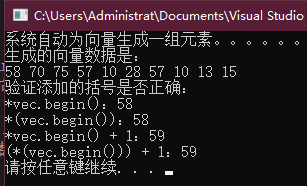
cout << "验证添加的括号是否正确:" << endl;
cout << "*vec.begin():" << *vec.begin() << endl;
cout << "*(vec.begin()):" << *(vec.begin()) << endl;
cout << "*vec.begin() + 1:" << *vec.begin() + 1 << endl;
cout << "(*(vec.begin())) + 1:" << (*(vec.begin())) + 1 << endl;
system("pause");
return 0;
}
练习4.3
C++语言没有明确规定大多数二元运算符的求值顺序,给编译器优化留下了余地。这种策略实际上是在代码生成效率和程序潜在缺陷之间进行了权衡,你认为这可以接受吗?请说出你的理由。
解:
C++语言只规定了非常少的二元运算符(逻辑与运算符、逻辑或运算符、逗号运算符)的求值顺序,其他绝大多数二元运算符的求值顺序没有明确规定。这样提高了代码生成的效率,但是可能引发潜在的缺陷。
关键是缺陷的风险有多大?我们知道,对于没有指定执行顺序的运算符来说,如果表达式指向并修改了同一个对象,将会引发错误并产生未定义的行为;而如果运算对象彼此无关,它们既不会改变同一对象的状态,也不执行IO任务,则函数的调用顺序不受限制。
故在一定程度上是可以接受的,前提是在编写程序时注意以下两点:
- 一是当拿不准的时候,最好用括号来让表达式的组合关系复合程序逻辑的要求;
- 二是一旦改变了某个运算对象的值,在表达式的其他地方就不要再使用这个运算对象了。
练习4.4
在下面的表达式中添加括号,说明其求值过程及最终结果。编写程序编译该(不加括号的)表达式并输出结果验证之前的推断。
12 / 3 * 4 + 5 * 15 + 24 % 4 / 2
解:
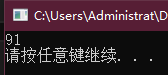
添加括号之后的形式是 ((12 / 3) * 4) + (5 * 15) + ((24 % 4) / 2) = 16 + 75 + 0,= 91。
#include <iostream>
using namespace std;
int main()
{
cout << "12 / 3 * 4 + 5 * 15 + 24 % 4 / 2" << endl;
system("pause");
return 0;
}
练习4.5
写出下列表达式的求值结果。
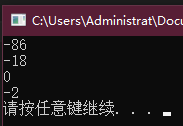
-30 * 3 + 21 / 5 // -90+4 = -86
-30 + 3 * 21 / 5 // -30+63/5 = -30+12 = -18
30 / 3 * 21 % 5 // 10*21%5 = 210%5 = 0
-30 / 3 * 21 % 4 // -10*21%4 = -210%4 = -2
#include <iostream>
using namespace std;
int main()
{
cout << -30 * 3 + 21 / 5 << endl;
cout << -30 + 3 * 21 / 5 << endl;
cout << 30 / 3 * 21 % 5 << endl;
cout << -30 / 3 * 21 % 4 << endl;
system("pause");
return 0;
}
练习4.6
写出一条表达式用于确定一个整数是奇数还是偶数。
解:
假设该整数名为 i。
if (i % 2 == 0) /* ... */
或者
if (i & 0x1) /* ... */
练习4.7
溢出是何含义?写出三条将导致溢出的表达式。
解:
溢出是一种常见的算术运算错误。因为在计算机中存储某种类型的内存空间有限,所以该类型的表示能力(范围)也是有限的,当计算的结果值超出这个范围时,就会产生未定义的数值,这种错误成为 溢出。
假定编译器规定 int 占32位,则:
#include <iostream>
using namespace std;
int main()
{
short svalue = 32767;
unsigned uivalue = 0;
unsigned short usvalue = 65535;
cout << ++svalue << endl;
cout << --uivalue << endl;
cout << ++usvalue << endl;
system("pause");
return 0;
}
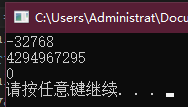
显然与我们的预期不相符,是溢出之后产生的错误结果。
练习4.8
说明在逻辑与、逻辑或及相等性运算符中运算对象的求值顺序。
解:
对于逻辑与运算符来说,当且仅当两个运算对象都为真时结果为真;对于逻辑或运算符来说,只要两个运算对象中的一个位真结果就为真。
逻辑与运算符和逻辑或运算符都是先求左侧运算对象的值再求右侧运算对象的值,当且仅当左侧运算对象无法确定表达式的结果时才会计算右侧运算对象的值。这种策略就是 短路求值。其策略是:
- 对于逻辑与运算符来说,当且仅当左侧运算对象为真时才计算右侧运算对象;
- 对于逻辑或运算符来说,当且仅当左侧运算对象为假时才计算右侧运算对象。
值得注意的是,逻辑与运算符和逻辑或运算符是 C++ 中仅有的几个规定了求值顺序的运算符。相等性运算符的两个运算对象都需要求值,C++没有规定其求值顺序。
练习4.9
解释在下面的 if 语句中条件部分的判断过程。
const char *cp = "Hello World";
if (cp && *cp)
解:
cp 是指向字符串的指针,因此上式的条件部分含义是首先检查指针 cp 是否有效。
- 如果
cp为空指针或无效指针,则条件不满足。 - 如果
cp有效,即cp指向了内存中的某个有效地址,继续解引用指针cp并检查所指的对象是否为空字符\0,- 如果
cp所指的对象不是空字符则条件满足; - 否则不满足。
- 如果
在本例中,显然初始状态下 cp 指向了字符串的首字符,是有效地;同时当前 cp 所指的对象是字符 H,不是空字符,所以 if 的条件部分为真。
练习4.10
为 while 循环写一个条件,使其从标准输入中读取整数,遇到 42 时停止。
解:
最简洁的形式是:
int i;
while(cin >> i && i != 42)
该语句首先检查从输入流读取数据是否正常,然后判断当前读入的数字是否是42,遇到42则条件不满足,退出循环。
还有一种形式也可以实现同样的目的:
int i;
while(cin >> i)
{
if(num == 42)
break;
// 其他操作
}
练习4.11
书写一条表达式用于测试4个值a、b、c、d的关系,确保a大于b、b大于c、c大于d。
解:
a>b && b>c && c>d
练习4.12
假设 i、j 和 k 是三个整数,说明表达式 i != j < k 的含义。
解:
C++规定 <、<=、>、>= 的优先级高于 == 和 !=,因此上式的求值过程等同于 i != (j < k),即先比较 j 和 k 的大小,得到的结果是一个布尔值(1或0);然后判断 i 的值与之是否相等,最终的结果为 bool 值。
练习4.13
在下述语句中,当赋值完成后 i 和 d 的值分别是多少?
int i; double d;
//(a)
d = i = 3.5;
//(b)
i = d = 3.5;
记住两点:
- 第一,如果赋值运算符左右两个运算对象的类型不同,则右侧运算对象转换左侧运算对象的类型;
- 第二,赋值运算符满足右结合律。
(a)的含义是先把3.5赋值给整数 i,此时发生了自动类型转换,小数部分被舍弃,i 的值为3;接着 i 的值再赋给双精度浮点数 d,所以 d 的值也是3。
(b)的含义是先把3.5赋值给双精度浮点数 d,因此 d 的值是3.5;接着 d 的值再赋给整数 i,此时发生了自动类型转换,小数部分被舍弃,i 的值为3。
练习4.14
执行下述 if 语句后将发生什么情况?
if (42 = i) // ...
if (i = 42) // ...
第一条语句发生编译错误,因为赋值运算符的左侧运算对象必须是左值,字面值常量42显然不是左值,不能作为左侧运算对象。
第二条语句从语法上来说是正确的,但是与程序的原意不符。程序的原意是判断 i 的值是否是42,应该写成 i==42;而 i==42 的意思是把42赋值给 i,然后判断 i 的值是否为真。因为所有非0整数转换成布尔值时都对应 true,所以该条件是恒为真的。
练习4.15
下面的赋值是非法的,为什么?应该如何修改?
double dval; int ival; int *pi;
dval = ival = pi = 0;
解:
该赋值语句是非法的,虽然连续赋值的形式本身没有错,但是参加赋值的几个变量类型不同。其中,dval 是双精度浮点数,ival 是整数,pi 是整型指针。
自右向左分析赋值操作的含义,pi=0 表示 pi 是一个空指针,接下来 ival=pi 试图把整型指针的值赋给整数,这是不符合语法规范的操作,无法编译通过。
稍作调整,改后如下:
double dval; int ival; int *pi;
dval = ival = 0;
pi = 0;
练习4.16
尽管下面的语句合法,但它们实际执行的行为可能和预期并不一样,为什么?应该如何修改?
if (p = getPtr() != 0)
if (i = 1024)
解:
if ((p=getPtr()) != 0)
if (i == 1024)
练习4.17
说明前置递增运算符和后置递增运算符的区别。
解:
递增和递减运算符有两种形式:前置版本和后置版本。
- 前置版本首先将运算对象加1(或减1),然后把改变后的对象作为求值结果;
- 后置版本也将运算对象加1(或减1),但是求值结果是运算对象改变之前那个值的副本。
这两种运算符必须作用于左值运算对象。前置版本将对象本身作为左值返回;后置版本则将对象原始值的副本作为右值返回。
我们的建议是,除非必须,否则不用递增(递减)运算符的后置版本。
- 前置版本的递增运算符避免了不必要的工作,它把值加1后直接返回改变了的运算对象。
- 与之相比,后置版本需要将原始值存储下来以便于这个未修改的内容。如果我们不需要修改之前的值,那么后置版本的操作就是一种浪费。
对于整数和指针类型来说,编译器可能对这种额外的工作进行了一定的优化;但是对于相对复杂的迭代器类型来说,这种额外的工作就消耗巨大了。建议养成使用 前置版本 的习惯,这样不仅不需要担心性能问题,而且更重要的是写出的代码会更符合编程人员的初衷。
练习4.18
如果132页那个输出 vector 对象元素的 while 循环使用前置递增运算符,将得到什么结果?
解:
如果在一条表达式中出现了递增运算符,则其计算规律是:
- ++在前,先加1,后参与运算;
- ++在后,先参与运算,后加1。
两个错误结果:
- 一是无法输出
vector对象的第一个元素; - 二是当所有元素都不为负,移动到最后一个元素的地方,程序试图继续向前移动迭代器,并解引用一个根本不存在的元素。
练习4.19
假设ptr的类型是指向 int 的指针、vec 的类型是 vector、ival 的类型是 int,说明下面的表达式是何含义?如果有表达式不正确,为什么?应该如何修改?
(a) ptr != 0 && *ptr++
(b) ival++ && ival
(c) vec[ival++] <= vec[ival]
解:
(a)的含义是先判定指针 ptr 是否为空,如果不为空,继续判断指针 ptr 所指的整数是否为非0数。如果非0,则该表达式的最终求值结果为真;否则为假。最后把指针 ptr 向后移动一位。该表达式从语法上分析是合法的,但是最后的指针移位操作不一定有意义。如果 ptr 所指的是整型数组中的某个元素,则 ptr 可以按照预期移动到下一个元素。如果 ptr 所指的只是一个独立的整数变量,则移动指针操作将产生未定义的结果。
(b)的含义是先检查 ival 的值是否非0,如果非0继续检查(ival+1)的值是否非0。只有当两个值都是非0值时,表达式的求值结果为真;否则为假。如果二元运算符的两个运算对象涉及同一个对象并改变对象的值,则这是一种不好的程序写法,应该改写,所以按照程序的原意,本式应该改写成 ival && (ival + 1)。
©的含义是比较 vec[ival] 和 vec[ival+1] 的大小,如果前者较小则求值结果为真,否则为假。与(b)式一样,本式也出现了二元运算符的两个运算对象涉及同一个对象并改变对象的值的情况,应该改写为 vec[ival] <= vec[ival+1]。
练习4.20
假设 iter 的类型是 vector::iterator,说明下面的表达式是否合法。如果合法,表达式的含义是什么?如果不合法,错在何处?
(a) *iter++;
(b) (*iter)++;
(c) *iter.empty();
(d) iter->empty();
(e) ++*iter;
(f) iter++->empty();
解:
(a)是合法的。后置递增运算符的优先级高于解引用运算符,其含义是解引用当前迭代器所处位置的对象内容,然后把迭代器的位置向前移动一位。
(b)是不合法的。解引用 iter 得到 vector 对象当前的元素,结果是一个 string,显然 string 没有后置递增操作。
©是不合法的。解引用运算符的优先级低于点运算符,所以该式先计算 iter.empty(),而迭代器并没有定义 empty 函数,所以无法通过编译。
(d)是合法的。iter->empty(); 等价于 (*iter).empty();。解引用迭代器得到迭代器当前所指的元素,结果是一个 string,显然字符串可以判断是否为空。
(e)是不合法的。先解引用 iter,得到迭代器当前所指的元素,结果是一个 string,显然 string 没有后置递增操作。
(f)是合法的。iter->empty(); 等价于 (*iter).empty();。含义是解引用迭代器当前位置的对象内容,得到一个字符串,判断该字符串是否为空,然后把迭代器向后移动一位。
练习4.21
编写一段程序,使用条件运算符从vector中找到哪些元素的值是奇数,然后将这些奇数值翻倍。
解:
#include <iostream>
#include <vector>
#include <ctime>
#include <cstdlib>
using namespace std;
int main()
{
vector<int> vInt;
const int sz = 10;
srand((unsigned)time(NULL));
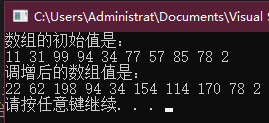
cout << "数组的初始值是:" << endl;
for (int i = 0; i != sz; ++i)
{
vInt.push_back(rand() % 100);
cout << vInt[i] << " ";
}
cout << endl;
for (auto &val : vInt)
val = (val % 2 != 0) ? val * 2 : val;
cout << "调增后的数组值是:" << endl;
for (auto it = vInt.cbegin(); it != vInt.cend(); ++it)
cout << *it << " ";
cout << endl;
system("pause");
return 0;
}
练习4.22
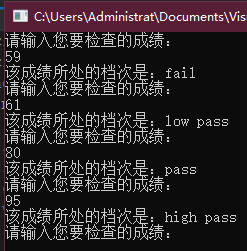
本节的示例程序将成绩划分为 high pass、pass 和 fail 三种,扩展该程序使其进一步将 60 分到 75 分之间的成绩设定为 low pass。要求程序包含两个版本:一个版本只使用条件运算符;另一个版本使用1个或多个 if 语句。哪个版本的程序更容易理解呢?为什么?
解:
#include <iostream>
#include <string>
using namespace std;
int main()
{
string finalgrade;
int grade;
cout << "请输入您要检查的成绩:" << endl;
while (cin >> grade && grade >= 0 && grade <= 100)
{
finalgrade = (grade > 90) ? "high pass"
: (grade > 75) ? "pass"
: (grade > 60) ? "low pass" : "fail";
cout << "该成绩所处的档次是:" << finalgrade << endl;
cout << "请输入您要检查的成绩:" << endl;
}
system("pause");
return 0;
}
#include <iostream>
#include <string>
using namespace std;
int main()
{
string finalgrade;
int grade;
cout << "请输入您要检查的成绩:" << endl;
while (cin >> grade && grade >= 0 && grade <= 100)
{
if (grade > 90)
finalgrade = "high pass";
else if (grade > 75)
finalgrade = "pass";
else if (grade > 60)
finalgrade = "low pass";
else
finalgrade = "fail";
cout << "该成绩所处的档次是:" << finalgrade << endl;
cout << "请输入您要检查的成绩:" << endl;
}
system("pause");
return 0;
}
练习4.23
因为运算符的优先级问题,下面这条表达式无法通过编译。根据4.12节中的表指出它的问题在哪里?应该如何修改?
string s = "word";
string pl = s + s[s.size() - 1] == 's' ? "" : "s" ;
解:
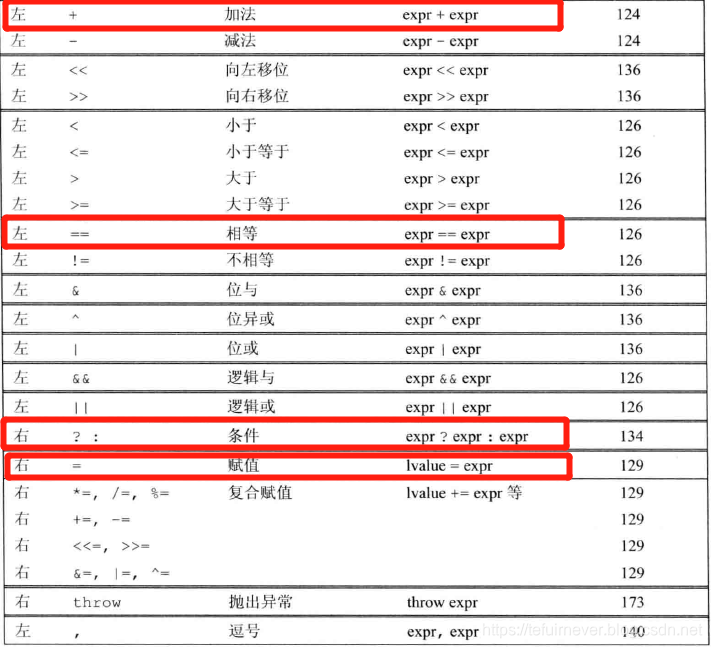
题中几个运算符的优先级次序从高到低是加法运算符、相等运算符、条件运算符和赋值运算符,因此式子的求值过程是先把 s 和 s[s.size-1() - 1] 相加得到一个新字符串,然后该字符串与字符 's' 比较是否相等,这是一个非法操作,并且与程序的原意不符。
要想实现程序的原意,即先判断字符串 s 的最后一个字符是否是 's',如果是,什么也不做;如果不是,在 s 的末尾添加一个字符 's',我们应该添加括号强制限定运算符的执行顺序。
string pl = s + (s[s.size() - 1] == 's' ? "" : "s") ;
练习4.24
本节的示例程序将成绩划分为 high pass、pass、和 fail 三种,它的依据是条件运算符满足右结合律。假如条件运算符满足的是左结合律,求值的过程将是怎样的?
解:
finalgrade = (grade > 90) ? "high pass"
: (grade < 60) ? "fail" : "pass";
如果条件运算符满足的是左结合律。那么
finalgrade = ((grade > 90) ? "high pass" : (grade < 60)) ? "fail" : "pass";
先考察 grade > 90 是否成立,如果成立,第一个条件表达式的值为 "high";如果不成立,第一个条件表达式的值为 grade < 60。这条语句是无法编译通过的,因为条件运算符要求两个结果表达式的类型相同或者可以互相转化。即使假设语法上通过,也就是说,第一个条件表达式的求值结果分为3中,分别是 "high pass"、1和0。接下来根据第一个条件表达式的值求解第二个条件表达式,求值结果是 "fail" 或 "pass"。这个求值过程显然与我们的期望是不符的。
练习4.25
如果一台机器上 int 占32位、char 占8位,用的是 Latin-1 字符集,其中字符 'q' 的二进制形式是 01110001,那么表达式 ~'q' << 6 的值是什么?
解:
在位运算符中,运算符 ~ 的优先级高于 <<,因此先对 q 按位求反,因为位运算符的运算对象应该是整数类型,所以字符 q 首先转换为整数类型。char 占8位而 int 占32位,所以字符 q 转换后得到 00000000 00000000 00000000 01110001,按位求反得到 11111111 11111111 11111111 10001110;接着执行移位操作,得到 11111111 11111111 11100011 10000000。
C++规定整数按照其补码形式存储,对上式求补,得到 10000000 00000000 00011100 100000000,即最终结果的二进制形式,转换成十进制形式是-7296。
练习4.26
在本节关于测验成绩的例子中,如果使用 unsigned int 作为 quiz1 的类型会发生什么情况?
解:
原书中使用 unsigned long 作为 quizl 的数据类型是恰当的,因为C++规定 unsigned long 在内存中至少占32位,这样就足够存放30个学生的信息了。
如果使用 unsigned int 作为 quizl 的数据类型,则由于C++规定 unsigned int 所占空间的最小值是16,所以在很多机器环境中,该数据类型不足以存放全部学生的信息,从而造成了信息丢失,无法完成题目要求的任务。
练习4.27
下列表达式的结果是什么?
unsigned long ul1 = 3, ul2 = 7;
(a) ul1 & ul2
(b) ul1 | ul2
(c) ul1 && ul2
(d) ul1 || ul2
解:
ul1 转换为二进制形式是:00000000 00000000 00000000 00000011,ul2 转换为二进制形式是:00000000 00000000 00000000 00000111。各个式子的求值结果分别是:
(a)按位与,结果是:00000000 00000000 00000000 00000011,即3。
(b)按位或,结果是:00000000 00000000 00000000 00000111,即7。
©逻辑与,所有非0整数对应的布尔值都是 true,所以该式等价于 true && true,结果是 true。
(d)逻辑或,所有非0整数对应的布尔值都是 true,所以该式等价于 true || true,结果是 true。
练习4.28
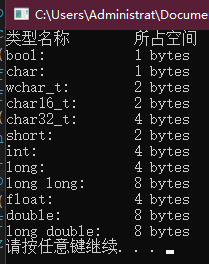
编写一段程序,输出每一种内置类型所占空间的大小。
解:
#include <iostream>
using namespace std;
int main()
{
cout << "类型名称\t" << "所占空间" << endl;
cout << "bool:\t\t" << sizeof(bool) << " bytes" << endl << endl;
cout << "char:\t\t" << sizeof(char) << " bytes" << endl;
cout << "wchar_t:\t" << sizeof(wchar_t) << " bytes" << endl;
cout << "char16_t:\t" << sizeof(char16_t) << " bytes" << endl;
cout << "char32_t:\t" << sizeof(char32_t) << " bytes" << endl << endl;
cout << "short:\t\t" << sizeof(short) << " bytes" << endl;
cout << "int:\t\t" << sizeof(int) << " bytes" << endl;
cout << "long:\t\t" << sizeof(long) << " bytes" << endl;
cout << "long long:\t" << sizeof(long long) << " bytes" << endl << endl;
cout << "float:\t\t" << sizeof(float) << " bytes" << endl;
cout << "double:\t\t" << sizeof(double) << " bytes" << endl;
cout << "long double:\t" << sizeof(long double) << " bytes" << endl << endl;
system("pause");
return 0;
}
练习4.29
推断下面代码的输出结果并说明理由。实际运行这段程序,结果和你想象的一样吗?如不一样,为什么?
int x[10]; int *p = x;
cout << sizeof(x)/sizeof(*x) << endl;
cout << sizeof(p)/sizeof(*p) << endl;
解:
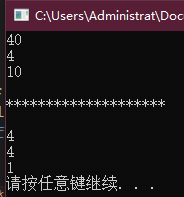
sizeof(x) 的运算对象 x 是数组的名字,求值结果是整个数组所占空间的大小,等价于对数组中所有的元素各执行一次 sizeof 运算并对所得结果求和。尤其注意,sizeof 运算符不会把数组转换成指针来处理。在本例中,x 是一个 int 数组且包含10个元素,所以 sizeof(x) 的求值结果是10个 int 值所占的内存空间总和。
sizeof(*x) 的运算对象 *x 是一条解引用表达式,此处的 x 既是数组的名称,也表示指向数组首元素的指针,解引用该指针得到指针所指的内容,在这里是一个 int。所以 sizeof(*x) 在这里等价于 sizeif(int),即 int 所占的内存空间。
sizeof(x)/sizeof(*x) 可以理解为数组 x 所占的全部空间除以其中一个元素所占的空间,得到的结果应该是数组 x 的元素总数。实际上,因为C++的内置数组并没有定义成员函数 size(),所以通常无法直接得到数组的容量。本题的方法是计算得到数组容量的一种常规方法。
sizeof(p) 的运算对象 p 是一个指针,求值结果是指针所占的空间大小。
sizeof(*p) 的运算对象 *p 是指针所指的对象,即 int 变量 x,所以求值结果是 int 值所占的空间大小。
#include <iostream>
using namespace std;
int main()
{
int x[10];
int *p = x;
cout << sizeof(x) << endl;
cout << sizeof(*x) << endl;
cout << sizeof(x) / sizeof(*x) << endl;
cout << endl;
cout << "********************" << endl;
cout << endl;
cout << sizeof(p) << endl;
cout << sizeof(*p) << endl;
cout << sizeof(p) / sizeof(*p) << endl;
system("pause");
return 0;
}
练习4.30
根据4.12节中的表,在下述表达式的适当位置加上括号,使得加上括号之后的表达式的含义与原来的含义相同。
(a) sizeof x + y
(b) sizeof p->mem[i]
(c) sizeof a < b
(d) sizeof f()
解:
(a)的含义是先求变量 x 所占空间的大小,然后与变量 y 的值相加;因为 sizeof 运算符的优先级高于加法运算符的优先级,所以如果想求表达式 x+y 所占的内存空间,应该改为 sizeof(x + y)。
(b)的含义是先定位到指针 p 所指的对象,然后求该对象中名为 mem 的数组成员第 i 个元素的尺寸。因为成员选择运算符的优先级高于 sizeof 的优先级,所以不需要添加括号。
©的含义是先求变量 a 在内存中所占空间的大小,再把求得的值与变量 b 的值比较。因为 sizeof 的优先级高于关系运算符的优先级,所以如果想求表达式 a<b 所占对的内存空间,应该改为 sizeof(a < b)。
(d)的含义是求函数 f() 返回值所占内存空间的大小,因为函数调用运算符的优先级高于 sizeof 的优先级,所以不需要添加括号。
练习4.31
本节的程序使用了前置版本的递增运算符和递减运算符,解释为什么要用前置版本而不用后置版本。要想使用后置版本的递增递减运算符需要做哪些改动?使用后置版本重写本节的程序。
解:
就本题而言,使用前置版本和后置版本是一样的,这是因为递增递减运算符与真正使用这两个变量的语句位于不同的表达式中,所以不会有什么影响。
vector<int>::size_type cnt = ivec.size();
// 将从size到1的值赋给ivec的元素
for (vector<int>::size_type ix = 0; ix != ivec.size(); ix++, cnt--)
ivec[ix] = cnt;
在4.5节(132页)已经说过了,除非必须,否则不用递增(递减)运算符的后置版本。前置版本的递增运算符避免了不必要的工作,它把值加1后直接返回改变了的运算对象。与之相比,后置版本需要将原始值存储下来以便于返回这个未修改的内容。如果我们不需要修改之前的值,那么后置版本的操作就是一种浪费。
因此,就本题而言,使用前置版本是更好地选择。
练习4.32
解释下面这个循环的含义。
constexpr int size = 5;
int ia[size] = { 1, 2, 3, 4, 5 };
for (int *ptr = ia, ix = 0;
ix != size && ptr != ia + size;
++ix, ++ptr) { /* ... */ }
解:
首先定义一个常量表达式 size,它的值是5;接着以 size 作为维度创建一个整型数组 ia,5个元素分别是1~5。
for 语句头包括三部分:
- 第一部分定义整型指针指向数组
ia的首元素,并且定义了一个整数ix,赋给它初值0; - 第二部分判断循环终止的条件,当
ix没有达到size同时指针ptr没有指向数组最后一个元素的下一位置时,执行循环体; - 第三部分令变量
ix和指针ptr分别执行递增操作。
练习4.33
根据4.12节中的表说明下面这条表达式的含义。
someValue ? ++x, ++y : --x, --y
解:
C++规定条件运算符的优先级高于逗号运算符,所以 someValue ? ++x, ++y : --x, --y 实际上等价于 (someValue ? ++x, ++y : --x), --y。它的求值过程是:
- 首先判断
someValue是否为真,- 如果为真,依次执行
++x和++y,最后执行--y; - 如果为假,执行
--x和--y。
- 如果为真,依次执行
下面是检验上述推断的实例程序:
#include <iostream>
using namespace std;
int main()
{
int x = 10, y = 20;
// 检验条件为真的情况
bool someValue = true;
someValue ? ++x, ++y : --x, --y;
cout << x << endl;
cout << y << endl;
cout << someValue << endl;
cout << endl;
cout << "********************" << endl;
cout << endl;
x = 10, y = 20;
// 检验条件为假的情况
someValue = false;
someValue ? ++x, ++y : --x, --y;
cout << x << endl;
cout << y << endl;
cout << someValue << endl;
system("pause");
return 0;
}
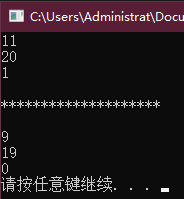
- 当
someValue取值为true时,依次执行++x、++y、--y,也就是说,x的值加1变为11,y的值先加1后减1保持不变,还是20. - 当
someValue取值为true时,依次执行--x、--y,x和y的值各减少1变为9和19。
练习4.34
根据本节给出的变量定义,说明在下面的表达式中将发生什么样的类型转换:
(a) if (fval)
(b) dval = fval + ival;
(c) dval + ival * cval;
需要注意每种运算符遵循的是左结合律还是右结合律。
解:
(a)if 语句的条件应该是布尔值,因此 float 型变量 fval 自动转换为 bool 类型,转换规则是所有非0值转换为 true,0转换为 false。
(b)ival 转换为 float,与 fval 相加的结果进一步转换为 double 类型。
©cval 执行整型提升转换为 int,与 ival 相乘后所得的结果转换为 double 类型,最后再与 dval 相加。
练习4.35
假设有如下的定义:
char cval;
int ival;
unsigned int ui;
float fval;
double dval;
请回答在下面的表达式中发生了隐式类型转换吗?如果有,指出来。
(a) cval = 'a' + 3;
(b) fval = ui - ival * 1.0;
(c) dval = ui * fval;
(d) cval = ival + fval + dval;
解:
(a)字符 'a' 转换为 int ,然后与 3 相加的结果再转换为 char 并赋给 cval。
(b)ival 转换为 double,与1.0相乘的结果也是 double 类型,ui 转换为 double 后与乘法得到的结果相减,最终的结果转换为 float 并赋给 fval。
©ui 转换为 float,与 fval 相乘的结果转换为 double 类型并赋给 dval。
(d)ival 转换为 float,与 fval 相加后的结果转换为 double 类型,再与 dval 相加后结果转换为 char 类型。
练习4.36
假设 i 是 int 类型,d 是 double 类型,书写表达式 i*=d 使其执行整数类型的乘法而非浮点类型的乘法。
解:
使用 static_cast 把 double 类型的变量 d 强制转换成 int 类型,就可以令 i*=d 执行整数类型的乘法。
i *= static_cast<int>(d);
练习4.37
用命名的强制类型转换改写下列旧式的转换语句。
int i; double d; const string *ps; char *pc; void *pv;
(a) pv = (void*)ps;
(b) i = int(*pc);
(c) pv = &d;
(d) pc = (char*)pv;
解:
(a) pv = static_cast<void*>(const_cast<string*>(ps));
(b) i = static_cast<int>(*pc);
© pv = static_cast<void*>(&d);
(d) pc = static_cast<char*>(pv);
练习4.38
说明下面这条表达式的含义。
double slope = static_cast<double>(j/i);
解:
将 j/i 的结果值转换为 double,然后赋值给 slope。
请注意,如果 i 和 j 的类型都是 int,则 j/i 的求值结果仍然是 int,即使除不尽也只保留商的整数部分,最后再转换成 double 类型。
如果想要更多的资源,欢迎关注 @我是管小亮,文字强迫症MAX~
回复【福利】即可获取我为你准备的大礼,包括C++,编程四大件,NLP,深度学习等等的资料。
想看更多文(段)章(子),欢迎关注微信公众号「程序员管小亮」~

















 256
256











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











