






概述
本文主要包含了Hive的细节设计和体系结构。
Figure 1(CSDN图太小了,建议大家放大看)
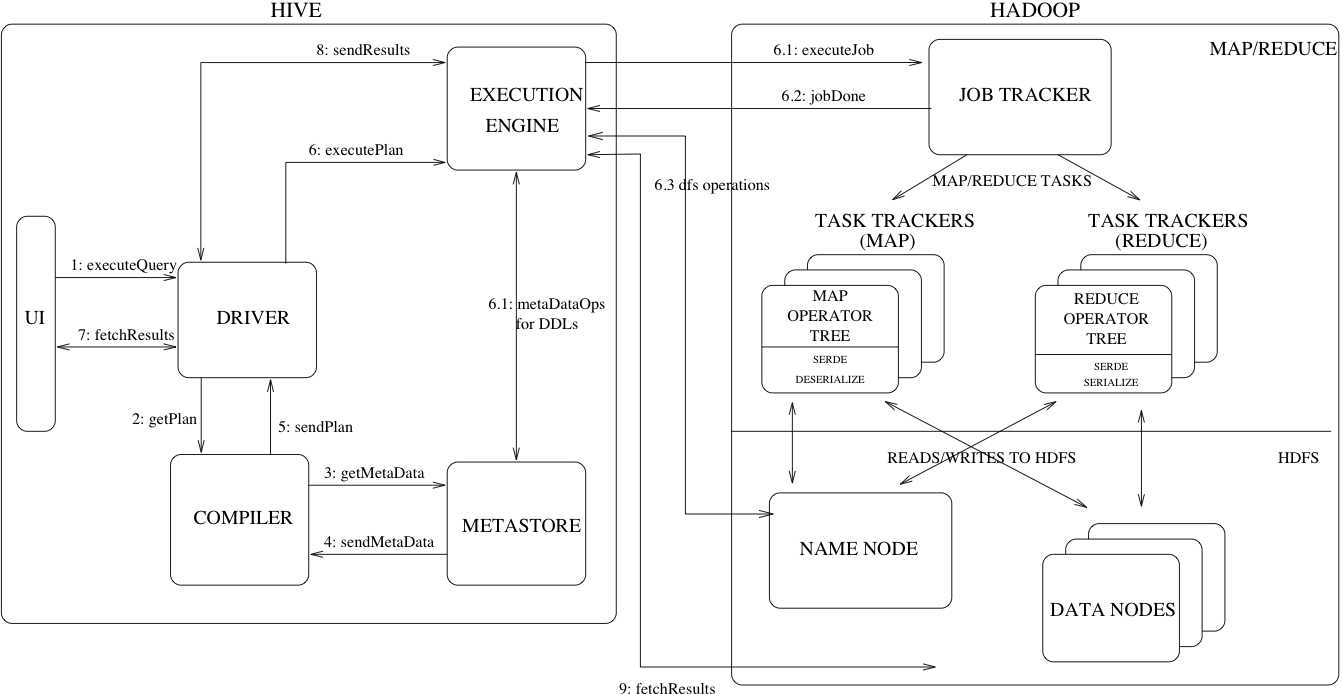
Hive Architecture
在图一中描述了使用Hive的主要组件和Hadoop进行交互。如图所示,Hive的主要组件包括:
- UI 用户提交查询和其他系统进行操作的用户接口。在2011年的时候该系统就有了一个命令行接口和一个基于GUI开发的web接口
- Driver - 该组件用于接收查询。该组件实现了会话映射、提供执行、获取APIs模型以及JDBC/ODBC接口的意图。
- Compiler - 该组件用于解析查询,在不同的查询模块和查询表达式进行语义分析,最终从元数据中找出表和分区的元数据信息并生成最终的执行计划。
- Metastore - 该组件用于存储各种表和分区的信息,包括了列和类型信息、用于在相应HDFS存储数据的地方进行读取和写入数据的序列化和反序列化器。
- Execution Engine - 执行引擎。该组件主要完成执行由编译器生成的执行计划。该计划是一个DAG的阶段。该引擎管理在不同阶段的计划和执行之间所依赖的系统组件。
图一中还展示了一个典型的查询是如何流经该系统的。首先UI调用执行接口的驱动程序(stage 1)。驱动程序创建一个会话用于查询和发送查询到编译器生成一个执行计划(stage 2)。编译器从metastore获取必要的元数据(stage 3 ,4)。这些元数据被用来进行在查询表达式中的查询树上进行类型检查和基于查询语句的谓词进行分区裁剪。由编译器(stage 5)生成的计划是一个DAG阶段,每个阶段都是一个map/reduce job、元数据操作或一个在HDFS上的操作。在map/reduce阶段,该计划包含了map操作树(操作树是在map中进行执行的)和reduce操作树(对于那些需要进行reduce的操作)。执行引擎提交需要的组件(stage 6, 6.1, 6.2和6.3)。在每个task(mapper/reducer)相关的反序列化器把表或中间输出用于从HDFS读取记录,这些通常是通过相关的操作树(mapper/reduce)进行的。一旦生成了输出结果。它将通过串行器写入临时的HDFS文件(如果这个阶段发生在mapper阶段则就不需要reduce了,因为直接通过mapper落地),临时文件的作用是为后续的mapper/reducer计划提供数据。对于DML操作最终的临时文件都将被移动到表中。这种方案被用来确保不会取到脏数据(文件重名名在HDFS是一个原子操作)。对于查询,该临时文件的内容被查询引擎直接从HDFS进行读取然后被相关驱动调取(stage 7、 8 、9)
Hive Data Model
数据在Hive中的组织形式有:
- 表 - 类似于关系数据库中的表。表可以被过滤、投影(projected)、连接和拼接(union操作)。另外一个表的所有数据都存储在HDFS的一个目录中。Hive还支持,当你提供适当的路径通过DDL语句来创建基于HDFS文件或者目录的外部表。
- 分区 - 这是一种根据“分区列”的值对表进行粗略划分的机制,使用分区可以加快数据分片(slice)的查询速度。分区允许根据查询谓词进行数据修剪(谓词过滤)。
- Bucket - 表或分区可以进一步的分为“桶”(bucket)。它会为数据提供额外的结构以获取更搞笑的查询处理。例如,通过根据用户ID进行分桶,我们可以在所有用户集合的随机样本上进行基于用户查询的快速计算。
Metastore
Motivation(动机)
元数据提供了两个往往被数据仓库忽略的重要概念:数据抽取和数据发现。在Hive中没有提供数据的抽象(其实就是表的DDL信息嘛)。用户必须提供数据格式信息、提取以及加载的查询。在Hive中,给出的这些信息在创建表和表重用的时候被引用。这非常类似于传统数据库。第二个功能是数据发现,用户能够在特定的数据仓库中发现和探索相关数据。其他工具也能够使用基于该元数据公开的信息来提高数据的可用性。Hive通过提供一个元数据资料库来实现这两种功能,这个元数据库是与Hive的查询系统紧密集成的,使数据和元数据是同步完成的。
Metadata Objects
- Database - 表的命名空间。
- Table -在元数据中表信息包含了列、表的用户、存储信息以及SerDe信息。SerDe元数据包含了实现的序列化和反序列化解析器所需要的信息,所有的这些信息都是在创建表的过程中产生的。
- Partition - 每个分区都可以有自己的列和SerDe以及存储信息。这有利于在不影响以前分区架构的前提下进行调整。
Metastore Architecture
元数据是一个对象存储在一个数据库或者备份文件中,其实就是要配置成本地的还是配置成基于数据库存储元数据的,基于数据库存储的意味着这些信息可以支持多个客户端使用。
Metastore Interface
Hive的元数据提供了一个Thrift接口来操作和查询hive中的元数据。
Hive Query Language
Hive查询提供了一种类似SQL的查询语句,这种灵活的查询架构是以牺牲转换造成的性能下降
Compiler
- Parser - 将一个查询字符串转换成一个解析树来表示
- Semantic Analyser - 语义分析器。转换分析树(Paser)到内部查询表示。隐式转换,
- Logical Plan Generator - 逻辑计划生成器。转换内部查询为逻辑计划。并且支持关系代数操作符、加入过滤器、JOIN操作等优化
- Query Plan Generator - 将逻辑计划生成器生成的语句正实的生成一系列的map-reducer任务。
Optimizer(优化)
这块是不断被改进的。例如,列裁剪、谓词下推等等















 1317
1317

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









