







2019年7月30-31日,第五届互联网安全领袖峰会(CSS 2019)在北京开幕。作为前沿技术安全研究团队代表,Tencent Blade Team两位高级安全研究员受邀登台,探讨如何挖掘语法解析器规则漏洞。
许多基础软件中都包含有语法解析部分,一旦出现规则漏洞影响,范围极大,而这块领域的安全研究相对较为缺乏,此次Tencent Blade Team对如何挖掘语法解析器规则漏洞做了从理论到实战的详细分析,并提出了如何编写安全的规则建议。
Tencent Blade Team由腾讯安全平台部成立,专注于物联网,AI,移动互联网,云技术,区块链等技术领域的前瞻性安全研究,积累了大量成果,包括发现首个谷歌TensorFlow AI框架漏洞、远程操控智能家居与商业楼宇、破解亚马逊智能音箱Echo、Google Home,发现SQLite Magellan漏洞等,多次受邀参加Blackhat、DEF CON、CSS等海内外顶级安全会议。
8月7号-11号,Tencent Blade Team也会前往美国拉斯维加斯参加BlachHat和DEFCON,一共有五场分享,涉及3个前沿议题:GoogleHome破解及麦哲伦漏洞利用,首次揭秘远程攻破高通Wi-Fi及Modem系统,远程利用高通硬件视频解码器漏洞,欢迎各位小伙伴关注。
以下为此次Tencent Blade Team挖掘语法解析器规则漏洞的现场分享,内容有删减,如有偏颇,敬请指正:

大家好,我们是来自Tencent Blade Team安全研究员,这是我们第二次来CSS分享议题,今天的分享主要分为以下六块内容:
- 研究背景、研究现状;
- 语法解析器概述,包括攻击面等;
- 如何人工挖掘语法规则的漏洞;
- 使用结构化fuzzer进行漏洞挖掘;
- 我们有关的研究成果;
- 如何编写安全的规则
首先,先来介绍我们研究语法解析器安全的背景:
一、研究背景及现状

不少基础软件的关键功能里,都能看到语法解析器的身影,例如SQLite,Chrome,PHP等,如果语法解析器存在安全问题,影响面很广,而语法解析器的安全问题,大家可能关注不多,容易被忽略。
二、语法解析器概述接下来我们来了解一些关于语法解析器的基础知识。

右边的图是一个简单的编译流程图,在早期,编写编译器相当耗时,直到Lex和YACC的诞生,有了它们,开发者只需要关注如何设计词法和语法规则,剩下的解析器代码都由它们来生成处理,大大提高了程序编译解析器开发的效率。
我们的议题重点关注Lex&YACC和LEMON Parser Generator。
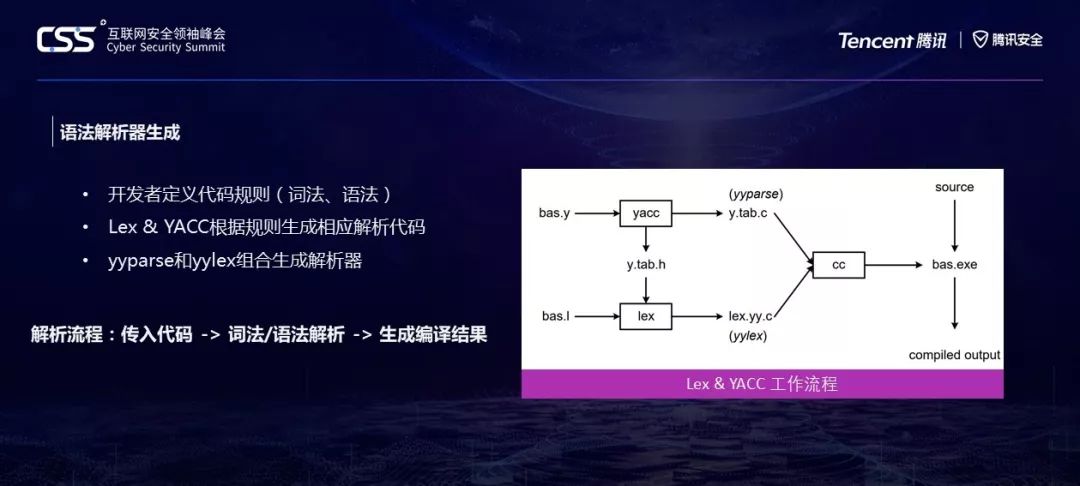
在Lex YACC解析器中,生成解析器的流程如右图所示。给定一段代码,由该解析器进行词法/语法解析,生成最终的结果。
介绍了有关语法解析器的基础知识,接下来分析其中的安全风险。
三、如何人工挖掘语法规则的漏洞
首先是Lex和YACC历史漏洞不多,但词法/语法规则是由开发者定义的,虽然Lex 和YACC的代码不多,漏洞较少,但规则就好比我们开发的插件,如果插件有问题,这个软件也存在安全风险。因此规则上引入的漏洞是我们关注的重点。
我们主要是对GLSL和SQL语法解析器进行了研究,目标确认了两个CVE和一些其他类型的多个crash。我们希望能够给大家提供一个新的攻击面和思路,以此抛砖引玉。

正如右图所示,黄色部分表示可能被攻击的攻击面,分别对应四个处理程序(Lex,YACC,yylex,yyparse)。但在实际攻击场景,规则其实早已定义好,规则在程序中相当于常量。所以,只有对yylex和yyparse的输入代码才是真正的攻击面,这其中包括:编译器的生成代码以及开发者引入的规则代码。我们重点关注规则代码。

正如右上图的一个片段,解析器代码风格迥异,直接审计有些尴尬。由于我们更关心用户规则引入的代码,因此只需重点看switch分支的代码,或者直接分析. l和. y后缀的规则文件进行漏洞挖掘。
接下来,我们以一个漏洞代码为例,介绍根据规则找漏洞的方法。
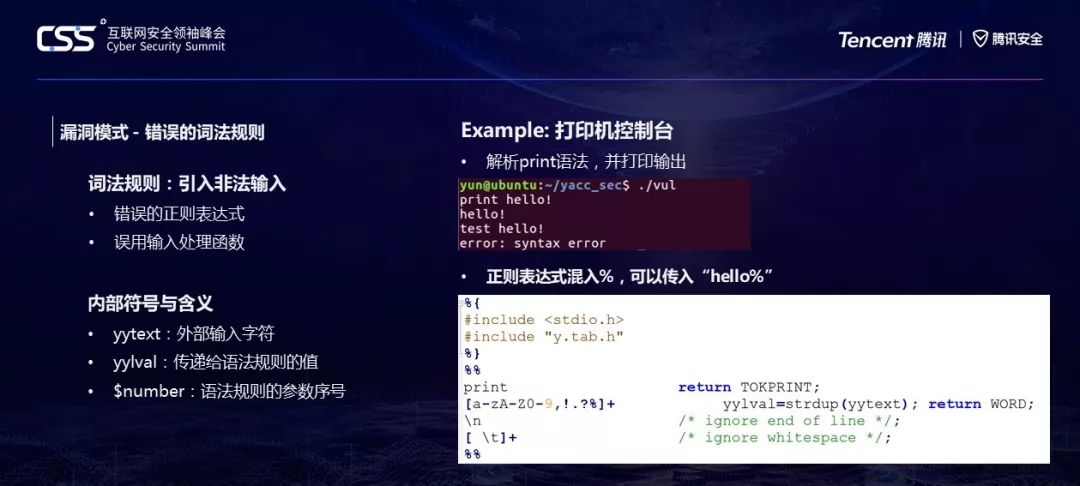
首先,我们先看右上图,这是这个测试程序。该程序解析输入的print语法,把print后面的内容打印输出,否则提示语法错误。
再来看词法规则,词法规则是对输入文本的第一层过滤,处理完后会把内容传递给语法解析器(yyparse),这其中可能会存在以下问题:
1 错误的正则表达式,使得本该非法的字符传递给给了语法解析器;
2 错误使用输入的处理函数,可能会把类型转错传递给语法解析器。

正如右上图代码所示,print_console这个规则里,会把WORD(词素)传递到printf函数里($2表示为WORD),那么在第一步词法分析中,非法的输入hello%已经被当做WORD(词素),并且传递到了$2的位置。再加上语法规则代码里直接通过不规范的printf输出。那么两者结合起来,这就是一个标准的格式化漏洞,能够通过这个程序泄露出内存数据。
实际上,相比传统漏洞代码,语法规则从逻辑上看,malloc mencpy等内存操作的逻辑相对较少。所以可以尝试挖掘类型混淆漏洞。
下面部分,我们给大家介绍怎么用结构化模糊测试去挖掘语法规则漏洞。
四、使用结构化fuzzer进行漏洞挖掘
Fuzz是最常见的漏洞挖掘方式,目前常见的Fuzzer基本都是基于灰盒和白盒测试的。而这几年fuzzer也逐渐从傻瓜化变得智能化。但是最近又提出了一个概念,结构化。为什么要结构化呢?

哪些程序适合使用这种模糊测试方案呢?
第一个就是:这个程序应当是高度结构化的。如果是那种单纯处理数据,而不进行Parse(解析)的处理程序,就不太适用于结构化fuzz。另一个,是基于文本的,像C语言的代码、SQL语句,它们是以单词为单位的,这和传统的Fuzz以字节为单位有所不同,所以更适合用结构化Fuzz。我们接下来要讲的SQLite、SwiftShader、ANGLE之类的,都是符合这个条件的。
五、已有研究

谷歌的实现是基于libprotobuf-mutator 又叫LPM,或者LPMFuzzer。它进一步用protobuf的格式,作出了一组通用的框架,来衍生出对其使用组件的一系列的fuzz,比如对SQLite的fuzz。在Blade Team去年报告了SQLite漏洞以后,可以看到谷歌把SQLite的代码都加强了很多。
但为什么谷歌不把所有的Fuzz都改成结构化相关的呢?答案就在这里,SQLite的Fuzzer在谷歌的工程里,翻一下就可以看到。代码有2700行,非常大。这个写起来想必也是十分耗费精力。而如果被测工具有了新的语法,Fuzzer就得同步更新,也就是说,通过用C++代码定义语法,Fuzzer逐渐失去了它的灵活性,但是Fuzzer会变得非常专注。这个长期维护的人力,很有可能就是谷歌不愿意通篇全部替换的原因。
另一种,则是类似Csmith这种生成式Fuzzer,其他例子还有Mozilla的jsfunfuzz,以及我之前模仿写的一个lucky-js-fuzzer,它们都会基于一定规则生成符合目标程序的指令,从而减少因为无效指令带来的测试效率的损失。
而我们的方案,则是用简单的操作,把被测目标拆分,降低结构化fuzz的难度,同时,又融合生成式Fuzzer的语句的生成方案。最后,不重复造轮子,比如Sanitizer,比如突变算法,还用原来的。我们做出来了一个介于Csmith和谷歌之间的,简单的实现方案,我们会开源其中一个Fuzzer,后面会给出URL。
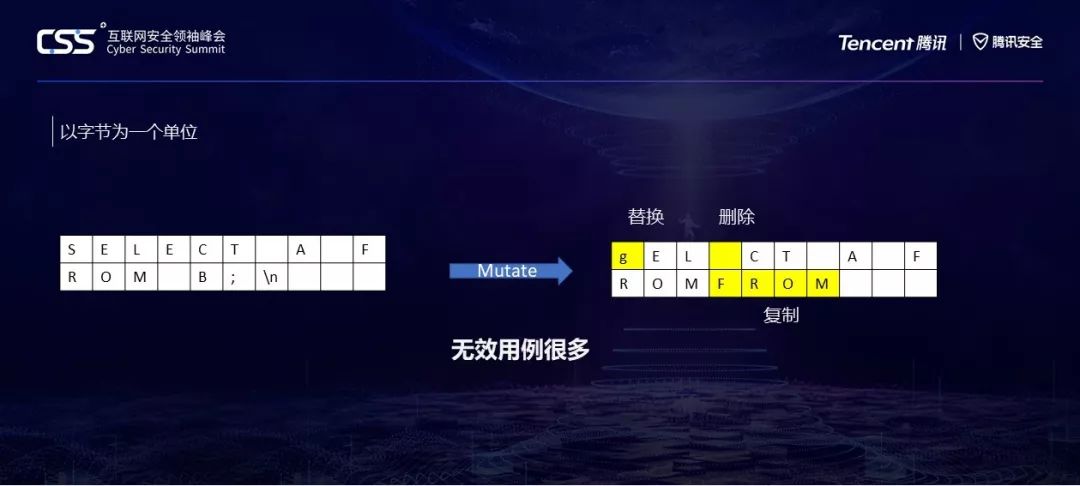
这个就是libfuzzer原本的突变方式,在没有什么特殊的指导的情况下,它可能会以比特为单位进行增删修改,这可能会产生大量无效用例。对SQL之类的,效率很低。

这是另一个版本,按照语素为单位,不过大家应该很快就能看出来,这和词典模式几乎没什么区别,只是我们做了一个形如虚拟机一样的东西,实现了一套我们自己的字节码定义,很像x86-CPU的那种变长字节码的感觉。这样,我们一来可以减少测试数据的长度,可以按照语素为单位来变换输出的内容。
相当于Fuzz引擎提供原始字节码,通过翻译,翻译出对应的语句,再去Fuzz,通过这种方式来跑,对比直接按字符为单位,空跑效率大概提升了40%多。当然,长时间以后收敛在一个比较接近的位置上。不过,这个情况下仍然能继续优化。

这一页展示的是用字节码定义整个语义的策略,可以看到,用语义为单位,会导致字节码变得十分长,但是也带来一个好处就是,Fuzz引擎的突变,更多的可能是改变语句内部的一些结构,但结果可能仍然是有效、完整的语句概率十分大。
而上一张我们说到的情况则仍然可能产生大量无效语句。不过用语义去Fuzz有什么问题呢?对,就是复杂度的问题。你可以看到SELECT FROM仅仅这一句,就有大量可能,如果让我们去开发程序,给每种不同的完整语句定义字节码,那几乎是一个不可能完成的任务。
所以我们在定义语义的时候,从关键字处,按语义将其拆分成最简化的句子,后续的内容采用类似生成式Fuzz的方案,尽量让它们能够在某个范围内成为一整条语句。这里语义的递归的逻辑就交给Fuzzer的突变引擎去随机弄就好了。
最终我们混合了上一页的策略、以及刚刚我们说的以语义为单位的Fuzz两种策略,做出了一套结构化Fuzz的东西。这套系统有个好处就是,你不需要费劲去搜集那么多初始样本,只要空跑或者随便给个什么文件当初始用例,就可以跑出来比普通的基于样本+词典更好的效果。
Tencent Blade Team去年在对Google Home进行研究的时候,顺便也对GPU进程做了个Fuzz,然后就发现SwiftShader可能是一个比较好的入口,我们当时做了很简单的一个结构化的模糊测试,很快我们就抓到了这样一个漏洞。
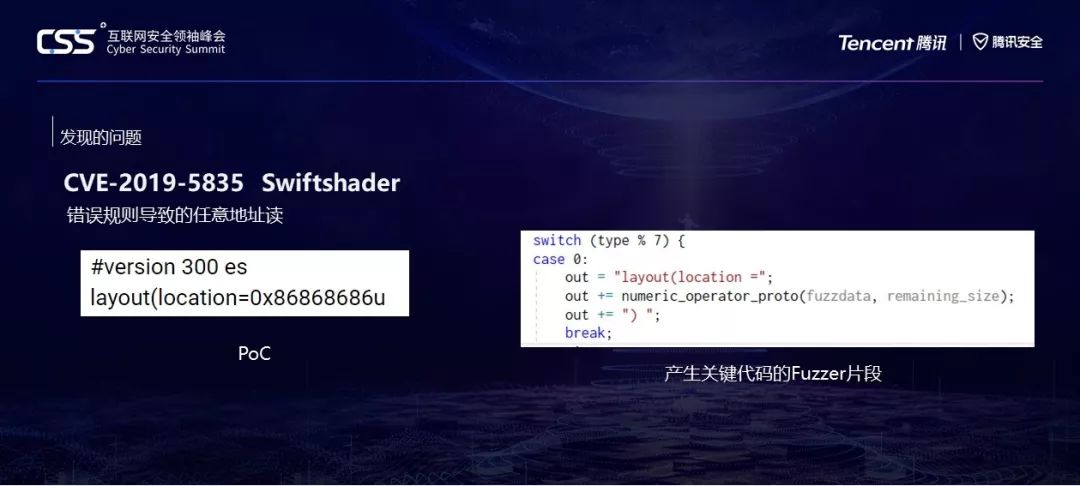
右边是生成它的具体Fuzzer代码。这样一个PoC有什么玄机呢,让我们继续往后看。
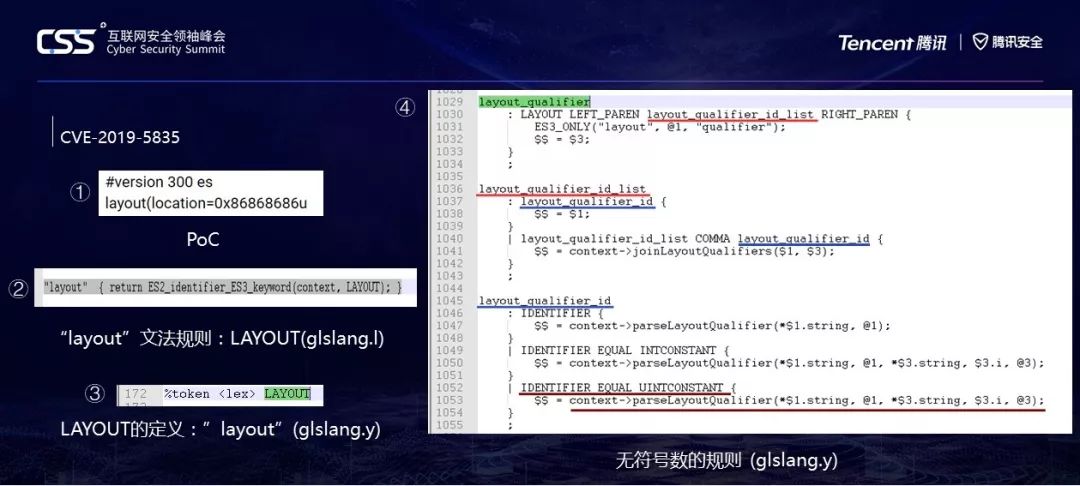
POC在第一张图中。那么为什么会导致这样的问题呢,让我们阅读一下layout相关的语法规则。GLSL的语法类似于C语言,也就是说,在一个数字后面加上u,这个数字就代表一个无符号数。
让我们先看第二个图,在文法规则中,我们看到,在只要版本号符合要求,layout即被定义为大写的LAYOUT。然后,在第三张图中,我们可以看到.Y中引用了大写的LAYOUT文法。再看第四张图,在glslang.y中,layout的规则定义为layout_qualifier,第1030行,即: LAYOUT 左括号 layout_qualifier_id_list 右括号。
不过这里要说明一下,因为它是从左往右一个token 一个token扫描的,所以我们最简PoC不写右括号也没事,因为在到右括号之前代码就出问题了。
这里大写的都是常量文本字符串,所以看第一个小写的,画红色横线的layout_qualifier_id_list,它的定义有两种,一种是直接layout_qualifier_id,一种是list 逗号 id。id的定义我用蓝色横线画出来了。
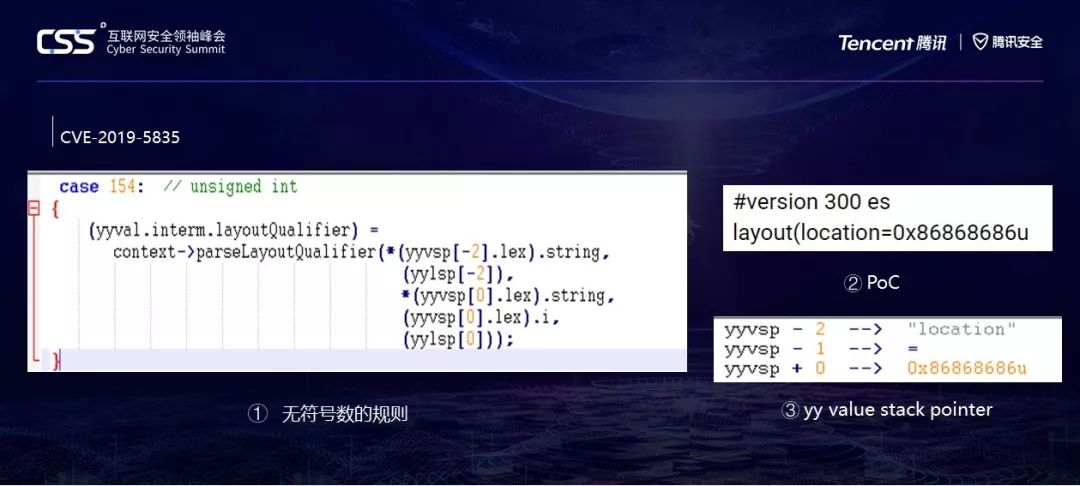
让我们看一下它生成出的 C文件,case 154对应无符号数规则。这里还需要介绍一下yyvsp和yylsp的概念。Yy就是yacc的那个y,大家可以读一下它的代码,他们写的时候并不是十分规范,大量使用了全局变量,我猜测这个yy是为了避免生成的代码。
和它自己的代码冲突而加上的一个模拟C++namespace的东西,如果觉得看着很碍眼,可以在阅读的时候把yy全部删掉。VSP,Value Stack Pointer,值栈指针;LSP,Location Stack Pointer,位置栈指针。它处理单词时,VSP永远指向正在处理的token。所以不难理解,现在它扫描到8686u,所以-1的位置就是等号,-2的位置就是location。
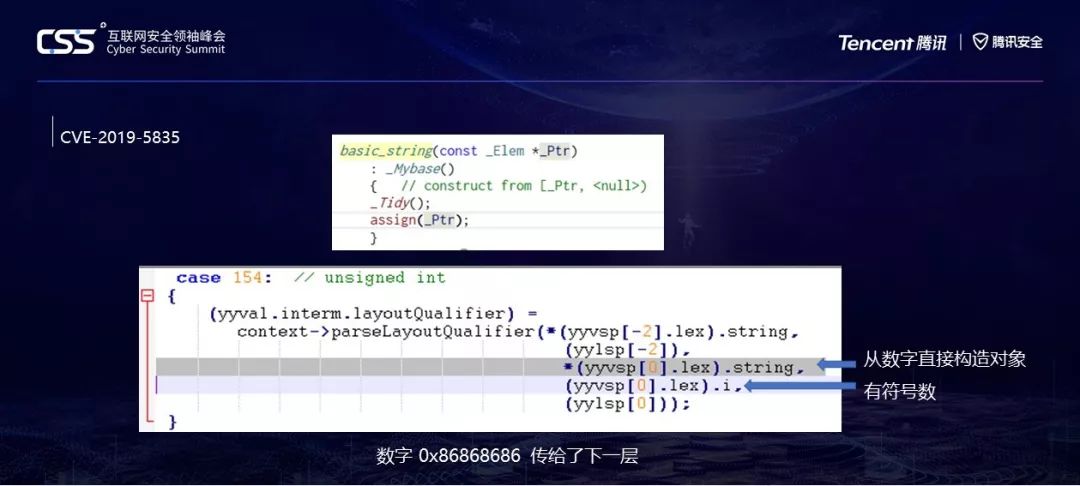
让我们看看最感兴趣的第三个参数,这也是他明显写错的地方。*Yyvsp[0],取出来的是数字,然后它将这个数字直接转为了String,这个.string的定义是Tstring对象,一个base_string,如果你传给它的是一个数字,它会把它当成const char*,也就是一个指针!
而第四个参数则直接取出数字传入下一层。
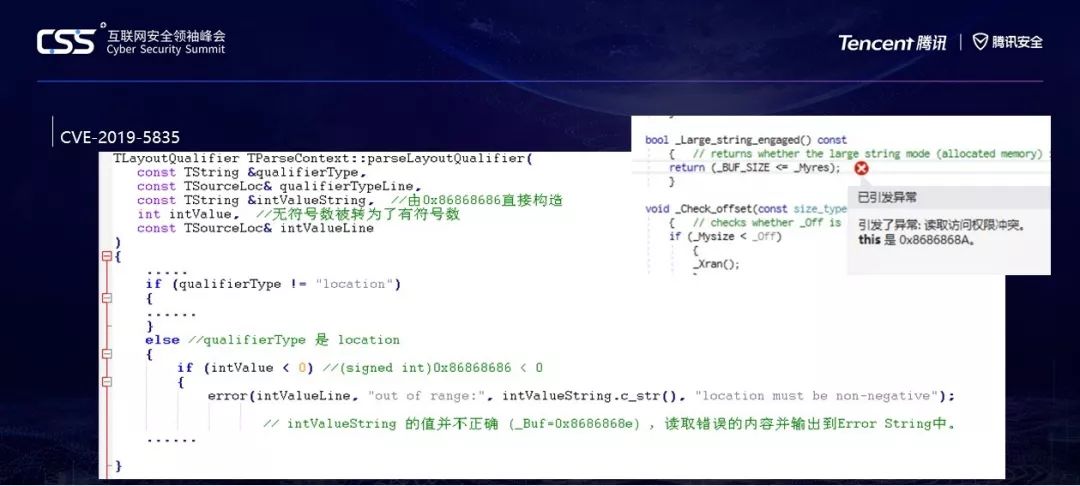
让我们对照代码看看出了什么问题。Tstring由0x86868686直接构造,也就是这个Tstring对象指向的是0x86868686这个地址,这里已经有一个错误了。
还有哪里有错误?我们可以看到,之前有符号数和无符号数共用了一个parseLayoutQualifier,而它的第四个参数是int ,有符号数。无符号数传入后,直接变成了有符号数。但为什么有符号数的情况下不会触发呢?
答案就在下面的if处,这里intValue因为是有符号数,而无符号数0x86868686的最高位是1,转换符号以后,变成了一个小于0的数,所以这个if被它自己这个强制符号转换给绕过去了。而下面立刻会调用error输出错误语句,这个错误语句中,直接调用了intValueString.c_str(),还记得intValueString现在是指向0x86868686的吗?所以在这里直接读取它的内容时,触发一次存取违例或者SIGSEGV。
右上角是我在VS里面调的,因为c_str()实际上会偏移几个字节,所以这里你看到的是868A或者868E等等,都正常,和平台相关。
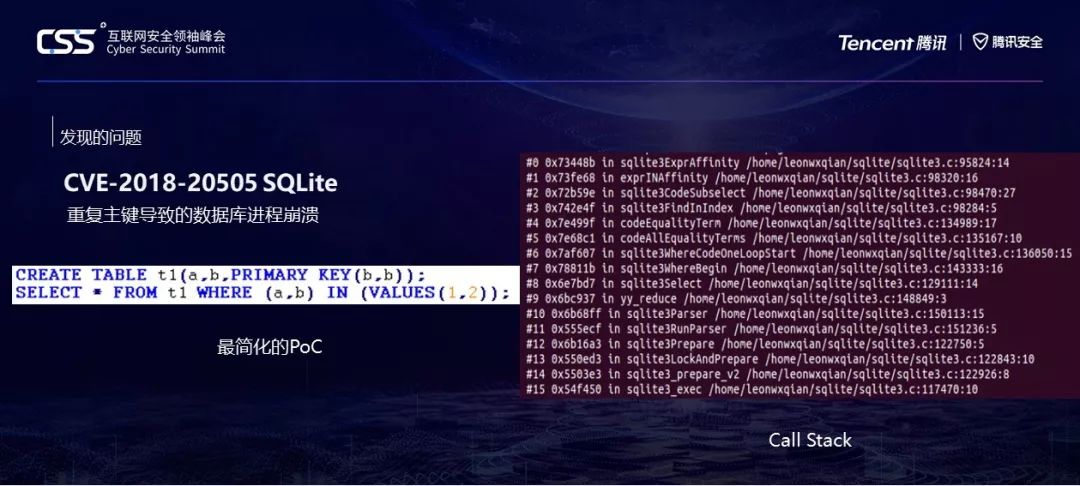
另一个则是SQLite的问题,这个是去年发现的,去年我们发现了麦哲伦漏洞,其实它一共有5个漏洞,一半是靠Fuzz出来的,一半是靠人工看出来的。虽然在数据库系统上可以远程导致崩溃也是个严重问题,不过这个20505呢,严格意义上说它比另外4个弱很多。
SQLite使用了Lemon Parser,它和Yacc&Lex很像,但是又不互相兼容,不过在右边Call Stack中大家一样能看到中间有个yy_reduce,最后它还是用了yy_这个标准开头。
左边的是这个问题的最简化的代码,大家如果写过SQL的话,很快就能发现这里有个诡异的地方,就是PRIMARY KEY里面有两个一样的主键。但是明显SQLite在这个地方把它放行了,在下一行去查询的时候,崩在右边这个位置。
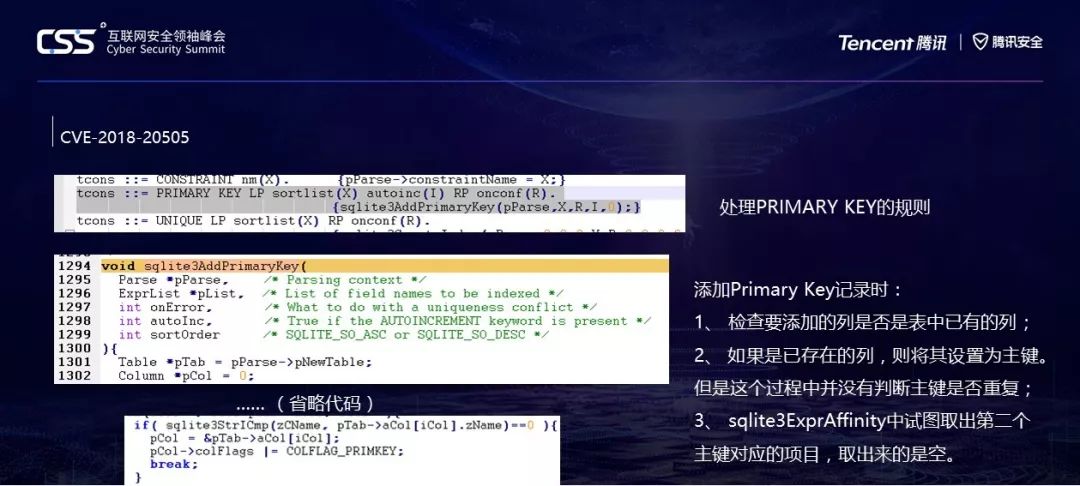
这个漏洞可以看到主键处理的规则是:RIMARY KEY 左括号 列表 是否有自增 右括号 ON CONFLICT 冲突时怎么做,然后,直接调用sqlite3AddPrimaryKey。这个函数逻辑是添加主键的时候,先检查要添加的列是否是表中已有的列;
如果是已存在的列,则将其设置为主键。但是这个过程中并没有判断主键是否重复;这样,里面就有两个主键,但是第二个主键添加的时候,因为列表里已经有一个同样的主键,于是它虽然成了主键,但是却指向一个空位置。
在执行搜索的时候,sqlite3ExprAffinity中试图取出第二个主键对应的项目,取出来的是空。就导致了这个CRASH。
SQLite官方的修复是在添加完表以后,把这种主键从数据库里清理出去。但我其实更觉得重复主键的时候就应该直接报错。
后续,我们也会把我们对GLSL的Fuzz工具开源:
GLSL Fuzzer (for Swiftshader / ANGLE , etc.)
https://github.com/tencentbladeteam/css_2019_tools/glsl_fuzzer.cpp
YACC规则转词典文件工具
https://github.com/tencentbladeteam/css_2019_tools/yacc_to_dict.cpp
大家可以把它用在Fuzz各个GLSL相关的地方,比如SwiftShader,ANGLE之类的地方。
六、如何编写安全的规则
最后,我们简单介绍一下如何编写安全的规则。
1.避免类型混用
规则定义中,可能存在大量的类型转换(显式的和隐式的),需要对每种情况都做好单元测试,以防漏掉某个规则产生混用。
避免一个规则对应多种类型的变量,C系列是强类型的语言,尤其是从Java移植过来的代码,更要检验是否存在某个规则过于宽泛。
规则定义中也存在类似边界情况的问题,比如某些值未被规则包括,或者某些特殊情况会产生异常问题,这些都要考虑在内。
在嵌套调用时,值可能会以不同类型的状态传递。另外,值有可能以智能指针之类的形式传递,在处理多层嵌套调用时,一定要仔细检查结果是否正确。
感谢大家的聆听,我们在8月7号-11号也会前往美国拉斯维加斯参加Blackhat和DEFCON,一共有五场分享,涉及3个前沿议题:GoogleHome破解及麦哲伦漏洞利用,首次揭秘远程攻破高通Wi-Fi及Modem系统,远程利用高通硬件视频解码器漏洞,也欢迎给大家关注blade的官网:blade.tencent.com,或者通过邮箱:blade@tencent.com和我们交流!















 4880
4880











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









