







Bag-of-Features(BOF)
Bag-of-words模型 BOW是信息检索领域常用的文档表示方法。在信息检索中,BOW模型假定对于一个文档,忽略它的单词顺序和语法、句法等要素,将其仅仅看作是若干个词汇的集合,文档中每个单词的出现都是独立的,不依赖于其它单词是否出现。也就是说,文档中任意一个位置出现的任何单词,都不受该文档语意影响而独立选择的。
图像可以视为一种文档对象,图像中不同的局部区域或其特征可看做构成图像的词汇,其中相近的区域或其特征可以视作为一个词。这样,就能够把文本检索及分类的方法用到图像分类及检索中去。
Bag-of-Features模型仿照文本检索领域的Bag-of-Words方法,把每幅图像描述为一个局部区域/关键点(Patches/Key Points)特征的无序集合。使用某种聚类算法(如K-means)将局部特征进行聚类,每个聚类中心被看作是词典中的一个视觉词汇(Visual Word),相当于文本检索中的词,视觉词汇由聚类中心对应特征形成的码字(code word)来表示(可看当为一种特征量化过程)。所有视觉词汇形成一个视觉词典(Visual Vocabulary),对应一个码书(code book),即码字的集合,词典中所含词的个数反映了词典的大小。图像中的每个特征都将被映射到视觉词典的某个词上,这种映射可以通过计算特征间的距离去实现,然后统计每个视觉词的出现与否或次数,图像可描述为一个维数相同的直方图向量,即Bag-of-Features。
如下图:
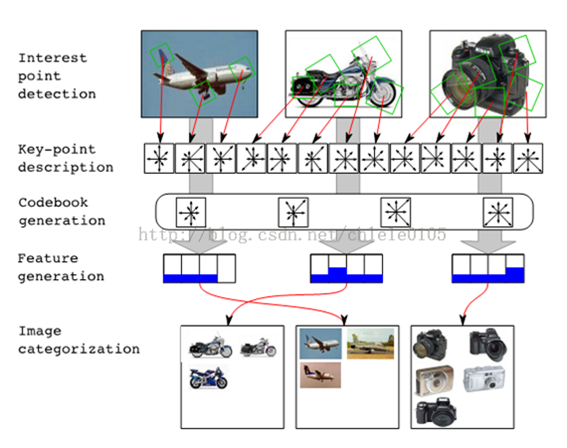
本文只是简单总结,博文Bag of Features (BOF)图像检索算法讲得超详细超美:
http://blog.csdn.net/chlele0105/article/details/9633397#comments
连图都是盗人家的,⊙﹏⊙b汗















 5845
5845











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









