







跟我一起机器学习系列文章将首发于公众号:月来客栈,欢迎文末扫码关注!
1 引例
经过前面的介绍,我们已经学习过了三个分类算法模型,包括逻辑回归、K近邻和朴素贝叶斯。今天我们来开始学习下一个分类算法模型决策树(Decision Tree)。一说到决策树其实很多人或多或少都已经用过,只是自己还不知道罢了。例如最简单的决策树就是通过输入年龄,判读其是否为成年人,即if age >= 18 return True,想想自己是不是经常用到这样的语句?
关于什么是决策树,我们先来看这么一个例子。假如我错过了某次世界杯,赛后我问一个知道比赛结果的人“哪支球队是冠军”?但这家伙并不愿意直接告诉我,而是让我猜,并且每猜一次,他要收一元钱才肯告诉我是否猜对了,那现在的问题是我要掏多少钱才能知道谁是冠军呢[1]?
现在我可以把球队编上号,从1到16,然后提问:“冠军球队在1-8号中吗?”,假如他告诉我猜对了,我会接着问:“冠军在1-4号中吗?”,假如他告诉我才错了,那么我自然知道冠军在5-8号中。这样只需要四次,我就能知道哪支球队是冠军。而这背后所隐藏着的其实就是决策树,我们用更为直观的图来展示上面的过程:
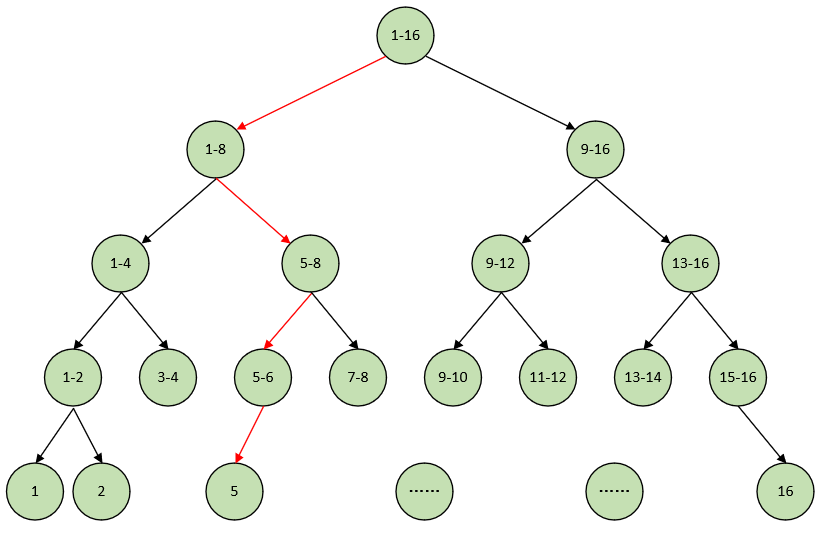
由此我们得出,决策树就是降低信息不确定性的过程,你甚至可以将其看成是一个if-then规则的集合。如上图,一开始有16种可能性,接着变成8种,这意味着我们每次决策都能得到更多的信息,减少更多的不确定性。
现在的问题是:为什么要这样来划分(球队)? 对于熟悉足球的人来说,这样的决策树似乎略显多余。因为只有少部分的球队有夺冠的希望,而大多数都是没可能夺冠的。因此在一开始的时候就将几个热门的可能夺冠的球队分在一起,将剩余的放在一起,整个决策的效率可能就提高了一个量级。
比如最有可能夺冠的是1,2,3,4这四个球队,其余夺冠的可能性远远小于这四个。那么一开始就可以将球队分成1-4和5-16。如果是在1-4中,那么后面很快就能知道谁是冠军;退一万步,假如真是在5-16,你同样可以将其按照这样的思路在下一步做决策的时候划分成最有可能和最不可能的两个部分。
于是我们发现:如何划分球队变成了建立这棵决策树的关键。即:若存在一种划分,能够使得数据的“不确定性”减少得越多(谁不可能夺冠),就意味着该划分能获取更多的信息,而我们就更倾向于采取这样的划分。因此采用不同的划分就会得到不同的决策树。现在的问题就是**如何来构建一棵“好”的决策树呢?**要想回答这个问题,我们先来解决如何描述的“信息”这个问题。
2 信息的度量
关于如何定量的来描述信息,几千年来都没有人给出很好的解答。直到1948年,香农在他著名的论文“通信的数学原理”中提出了信息熵(information entropy) 的概念,才解决了信息的度量问题,并且量化出信息的作用。
2.1 信息熵
一条信息的信息量与其不确定性有着直接的关系。比如说,我们要搞清楚一件非常非常不确定的事,就需要了解大量的信息。相反,如果已经对某件事了解较多,则不需要太多的信息就能把它搞清楚。所以从这个角度来看可以认为,信息量就等于不确定性的多少。我们经常说,一句话包含有多少信息,其实就是指它不确定性的多与少
于是,引例中第一种划分方式的不确定性(信息量)就等于“4块钱”,因为我花4块钱就可以解决这个不确定性。当然,香农用的不是钱,而是用“比特”(bit)这个概念来度量信息量,一个字节就是8比特。在上面引例的第一种情况中,“谁是冠军”这条消息的信息量就是4比特。那4比特是怎么计算来的呢?第二种情况的信息量又是多少呢?
香农指出,它的准确信息量应该是:
H
=
−
(
p
1
⋅
log
p
1
+
p
2
⋅
log
p
2
+
⋯
+
p
16
⋅
log
p
16
)
(1)
H = -(p_1\cdot\log p_1+p_2\cdot\log p_2+\cdots+p_{16}\cdot\log p_{16})\tag{1}
H=−(p1⋅logp1+p2⋅logp2+⋯+p16⋅logp16)(1)
其中
log
\log
log表示以2为底的对数,
p
1
,
p
2
,
.
.
.
,
p
16
p_1,p_2,...,p_{16}
p1,p2,...,p16分别是这16支球队夺冠的概率。香农把它称为“信息熵(Entropy),一般用符号
H
\mathrm{H}
H表示,单位是比特。由于第一种情况我们假设的是16支球队夺冠概率相同,因此对应的信息熵就是4比特。并且等概率时的信息熵最大,即引例中的信息量不可能大于4.
对于任意一个随机变量
X
X
X(比如得冠军的球队),它的熵定义如下[2]:
H
(
X
)
=
−
∑
x
∈
X
P
(
x
)
log
P
(
x
)
,
其中log 表示以2为底的对数
(2)
H(X) = -\sum_{x\in X}P(x)\log P(x),\;\text{其中log 表示以2为底的对数 }\tag{2}
H(X)=−x∈X∑P(x)logP(x),其中log 表示以2为底的对数 (2)
举个例子:比如在2分类问题中:设
P
(
y
=
0
)
=
p
,
P
(
y
=
1
)
=
1
−
p
,
0
≤
p
≤
1
P(y=0)=p,P(y=1)=1-p,\;0\leq p\leq1
P(y=0)=p,P(y=1)=1−p,0≤p≤1
那么此时的信息熵
H
(
y
)
H(y)
H(y)即为:
H
(
y
)
=
−
(
p
log
p
+
(
1
−
p
)
log
(
1
−
p
)
)
(3)
H(y)=-(p\log p+(1-p)\log(1-p))\tag{3}
H(y)=−(plogp+(1−p)log(1−p))(3)
其图像如下

我们可以看到,当概率均等( p = 1 − p = 0.5 p=1-p=0.5 p=1−p=0.5)时信息熵最大,也就是说此时的不确定性最大,要把它搞清楚所需要的信息量也就越大。而且这也很符合我们的常识,双方获胜的概率相等时不确定性最大。
2.2 条件熵
在谈条件熵(condition entropy) 之前,我们先来看看信息的作用。一个事物(那只球队会得冠),其内部会存有随机性,也就是不确定性,我们假定其为 U U U。从外部消除这个不确定性唯一的办法就是引入信息 I I I(我来猜,另一个人给我反馈),而需要引入的信息量取决于这个不确定性的大小,即 I > U I>U I>U才行。当 I < U I<U I<U时,这些信息可以消除一部分不确定性,也就是说新的不确定性 U ′ = U − I U^{\prime}=U-I U′=U−I。反之,如果没有信息的引入,那么任何人都无法消除不确定性[1]。而所谓条件熵,说得简单点就是在给定某种条件(有用信息) I I I下,事物 U U U的熵,即 H ( U ∣ I ) H(U|I) H(U∣I)。此处暂时不引入条件熵的确切数学定义,等谈到如何生成决策树的时候再表。
2.3 信息增益
我们在引例中说过:若一种划分能使数据的“不确定性”减少得越多,就意味着该种划分能获取更多的信息,而我们就更倾向于采取这样的划分。也是就说,存在某个事物
I
I
I,它使得
H
(
U
∣
I
)
H(U|I)
H(U∣I)要尽可能的小,即当引入信息
I
I
I之后
U
U
U的熵变小了。而**信息增益(information gain)**则定义为:
g
(
U
∣
D
)
=
H
(
U
)
−
H
(
U
∣
I
)
(4)
g(U|D)=H(U)-H(U|I)\tag{4}
g(U∣D)=H(U)−H(U∣I)(4)
3 总结
在本篇文章中,笔者通过一个足球夺冠的示例介绍了决策树的核心思想。并且在前面的引例中我们谈到,“采用不同的划分就会得到不同的决策树”,而我们所希望得到的就是在每一次划分的时候都采取最优的方式,即局部最优解。这样每一步划分都能够使得当前的信息增益达到最大。因此,构建决策树的核心思想就是:每次划分时,要选择使得信息增益最大的划分方式,以此来递归构建决策树。在接下来的文章中,笔者将开始正式接受决策树的构建与剪枝等。本次内容就到此结束,感谢阅读!
若有任何疑问与见解,请发邮件至moon-hotel@hotmail.com并附上文章链接,青山不改,绿水长流,月来客栈见!
引用
[1]《数学之美》吴军
[2] 《统计机器学习(第二版)》李航,公众号回复“统计学习方法”即可获得电子版与讲义
[3]《Python与机器学习实战》何宇健
[4] 示例代码:关注公众号回复“示例代码”即可直接获取!















 2620
2620











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









