







一. 时间复杂度
时间复杂度用来检验某个算法处理一定量的数据要花多长时间。
这个表示法用一个函数来描述算法处理给定的数据需要多少次运算。
重要的不是数据量,而是当数据量增加时运算如何增加。时间复杂度不会给出确切的运算次数,但是给出的是一种理念。

图中可以看到不同类型的复杂度的演变过程,我用了对数尺来建这个图。具体点儿说,数据量以很快的速度从1条增长到10亿条。我们可得到如下结论:
- 绿:O(1)或者叫常数阶复杂度,保持为常数(要不人家就不会叫常数阶复杂度了)。
- 红:O(log(n))对数阶复杂度,即使在十亿级数据量时也很低。
- 粉:最糟糕的复杂度是 O(n^2),平方阶复杂度,运算数快速膨胀。
- 黑和蓝:另外两种复杂度(的运算数也是)快速增长。
例子
数据量低时,O(1) 和 O(n^2)的区别可以忽略不计。比如,你有个算法要处理2000条元素。
- O(1) 算法会消耗 1 次运算
- O(log(n)) 算法会消耗 7 次运算
- O(n) 算法会消耗 2000 次运算
- O(n*log(n)) 算法会消耗 14,000 次运算
- O(n^2) 算法会消耗 4,000,000 次运算
O(1) 和 O(n^2) 的区别似乎很大(4百万),但你最多损失 2 毫秒,只是一眨眼的功夫。确实,当今处理器每秒可处理上亿次的运算。这就是为什么性能和优化在很多IT项目中不是问题。
我说过,面临海量数据的时候,了解这个概念依然很重要。如果这一次算法需要处理 1,000,000 条元素(这对数据库来说也不算大)。
- O(1) 算法会消耗 1 次运算
- O(log(n)) 算法会消耗 14 次运算
- O(n) 算法会消耗 1,000,000 次运算
- O(n*log(n)) 算法会消耗 14,000,000 次运算
- O(n^2) 算法会消耗 1,000,000,000,000 次运算
我没有具体算过,但我要说,用O(n^2) 算法的话你有时间喝杯咖啡(甚至再续一杯!)。如果在数据量后面加个0,那你就可以去睡大觉了。
二. 归并排序
合并排序有助于我们以后理解数据库常见的联接操作,即合并联接
合并
与很多有用的算法类似,合并排序基于这样一个技巧:将 2 个大小为 N/2 的已排序序列合并为一个 N 元素已排序序列仅需要 N 次操作。这个方法叫做合并。
我们用个简单的例子来看看这是什么意思:

通过此图你可以看到,在 2 个 4元素序列里你只需要迭代一次,就能构建最终的8元素已排序序列,因为两个4元素序列已经排好序了:
1) 在两个序列中,比较当前元素(当前=头一次出现的第一个)
2) 然后取出最小的元素放进8元素序列中
3) 找到(两个)序列的下一个元素,(比较后)取出最小的
重复1、2、3步骤,直到其中一个序列中的最后一个元素
然后取出另一个序列剩余的元素放入8元素序列中。
这个方法之所以有效,是因为两个4元素序列都已经排好序,你不需要再『回到』序列中查找比较。
合并排序是把问题拆分为小问题,通过解决小问题来解决最初的问题(注:这种算法叫分治法,即『分而治之、各个击破』)。如果你不懂,不用担心,我第一次接触时也不懂。如果能帮助你理解的话,我认为这个算法是个两步算法:
- 拆分阶段,将序列分为更小的序列
- 排序阶段,把小的序列合在一起(使用合并算法)来构成更大的序列
拆分阶段

在拆分阶段过程中,使用3个步骤将序列分为一元序列。步骤数量的值是 log(N) (因为 N=8, log(N)=3)。
排序阶段

在排序阶段,你从一元序列开始。在每一个步骤中,你应用多次合并操作,成本一共是 N=8 次运算。
第一步,4 次合并,每次成本是 2 次运算。
第二步,2 次合并,每次成本是 4 次运算。
第三步,1 次合并,成本是 8 次运算。
因为有 log(N) 个步骤,整体成本是 N*log(N) 次运算。
三. 阵列,树和哈希表
阵列
二维阵列是最简单的数据结构。一个表可以看作是个阵列,比如:
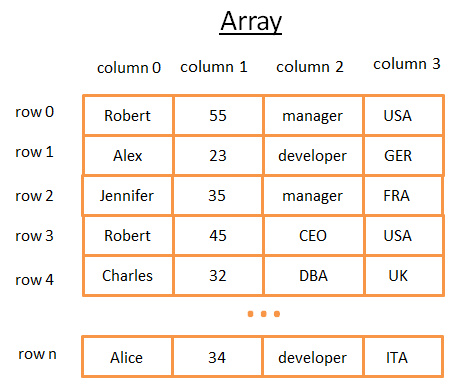
这个二维阵列是带有行与列的表:
- 每个行代表一个主体
- 列用来描述主体的特征
- 每个列保存某一种类型对数据(整数、字符串、日期……)
虽然用这个方法保存和视觉化数据很棒,但是当你要查找特定的值它就很糟糕了。 举个例子,如果你要找到所有在 UK 工作的人,你必须查看每一行以判断该行是否属于 UK 。这会造成 N 次运算的成本(N 等于行数),还不赖嘛,但是有没有更快的方法呢?这时候树就可以登场了(或开始起作用了)
树和数据库索引
二叉查找树是带有特殊属性的二叉树,每个节点的关键字必须:
- 比保存在左子树的任何键值都要大
- 比保存在右子树的任何键值都要小
B+树索引
查找一个特定值这个树挺好用,但是当你需要查找两个值之间的多个元素时,就会有大麻烦了。你的成本将是 O(N),因为你必须查找树的每一个节点,以判断它是否处于那 2 个值之间(例如,对树使用中序遍历)。而且这个操作不是磁盘I/O有利的,因为你必须读取整个树。我们需要找到高效的范围查询方法。为了解决这个问题,现代数据库使用了一种修订版的树,叫做B+树。在一个B+树里:
- 只有最底层的节点(叶子节点)才保存信息(相关表的行位置)
- 其它节点只是在搜索中用来指引到正确节点的。
哈希表
我们最后一个重要的数据结构是哈希表。当你想快速查找值时,哈希表是非常有用的。而且,理解哈希表会帮助我们接下来理解一个数据库常见的联接操作,叫做『哈希联接』。这个数据结构也被数据库用来保存一些内部的东西(比如锁表或者缓冲池,我们在下文会研究这两个概念)。
哈希表这种数据结构可以用关键字来快速找到一个元素。为了构建一个哈希表,你需要定义:
元素的关键字
- 关键字的哈希函数。关键字计算出来的哈希值给出了元素的位置(叫做哈希桶)。
- 关键字比较函数。一旦你找到正确的哈希桶,你必须用比较函数在桶内找到你要的元素。

这个哈希表有10个哈希桶。因为我懒,我只给出5个桶,但是我知道你很聪明,所以我让你想象其它的5个桶。我用的哈希函数是关键字对10取模,也就是我只保留元素关键字的最后一位,用来查找它的哈希桶:
- 如果元素最后一位是 0,则进入哈希桶0
- 如果元素最后一位是 1,则进入哈希桶1
- 如果元素最后一位是 2,则进入哈希桶2
比方说你要找元素 78:
哈希表计算 78 的哈希码,等于 8。
查找哈希桶 8,找到的第一个元素是 78。
返回元素 78。
查询仅耗费了 2 次运算(1次计算哈希值,另一次在哈希桶中查找元素)。
现在,比方说你要找元素 59:
哈希表计算 59 的哈希码,等于9。
查找哈希桶 9,第一个找到的元素是 99。因为 99 不等于 59, 那么 99 不是正确的元素。
用同样的逻辑,查找第二个元素(9),第三个(79),……,最后一个(29)。
元素不存在。
搜索耗费了 7 次运算。















 122
122

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









