







Storm基本概念
Hadoop等离线批量处理主要针对数据挖掘、数据分析、数据统计、BI分析等。而Storm等分布式实时计算系统可以支持一些在线的业务系统、分布式RPC、ETL等等。Storm不做任何的数据存储,一般将消息队列作为数据源,数据库作为结果输出的目的地。
Storm支持水平扩展。在Storm集群中真正运行topology的主要有三个实体:工作进程、线程和任务。Storm集群中的每台机器上都可以运行多个工作进程,每个工作进程又可以创建多个线程,每个线程可以执行多个任务,任务是真正进行数据处理的实体。
Storm具有高容错性,保证每个消息都会得到处理。spout发出的消息后续可能会触发产生成千上万条信息,可以将其理解为消息树,其中spout发出的消息为树根,Storm会跟踪这跟消息树的处理情况,只有当这颗消息树中的所有消息都被处理了,Storm才会认为spout发出的这个消息已经被“完全处理”。如果这颗消息树中的任何一个消息处理失败,或处理超时,那么spout会重新发送消息。
Storm用于实时计算,Hadoop用于离线计算;Storm处理的数据保存在内存中,源源不断,Hadoop处理的数据保存在文件系统中,一批一批;Storm的数据通过网络传输进来,Hadoop的数据保存在磁盘中。
Storm体系架构
编程模型
DataSource;外部数据源
Spout:接受外部数据源的组件,将外部数据源转化成Storm内部的数据,以Tuple为基本的传输单元下发给Bolt
Bolt:接受Spout发送的数据或上游的eBolt发送的数据,根据业务逻辑进行处理,发送给下一个Bolt或者存储到某种介质上,介质可以是Redis,也可以是MySQL等等。
Tuple:Storm内部中数据传输的基本单元,里面封装了一个List对象,用来保存数据。
StreamGrouping:数据分组策略。例如:ShuffleGrouping(Random函数),Non Grouping(Random函数),Field Grouping(Hash函数),Local or ShuffleGrouping本地 或随机,优先本地。
并发度
用户指定的一个任务,可以被多个线程执行,并发度的数量等于线程的数量。一个任务的多个线程会被运行在多个Worker上(JVM),有一种类似于平均算法的负载均衡策略。尽可能减少网络IO,其与Hadoop中的MapReduce中的本地计算道理相似。
根据上游的数据量来设置Spout的并发度;根据业务复杂度和execute方法执行时间来设置Bolt并发度;根据集群的可用资源来配置,一般情况下70%的资源使用率;Worker的数量理论上根据程序并发度总的Task数量来均分,在实际的业务场景中,需要进行反复调试才能确定。
架构
Nimbus:任务分配
Supervisor:接受任务,并启动worker,worker的数量根据端口号确定。
Worker:执行任务的具体组件(就是一个JVM),可以执行两种类型的任务:Spout或者Bolt任务。
Task:Task=线程=executor,一个Task属于一个Spout或者B欧力特并发任务。
ZooKeeper:保存任务分配的信息、心跳信息、元数据信息。
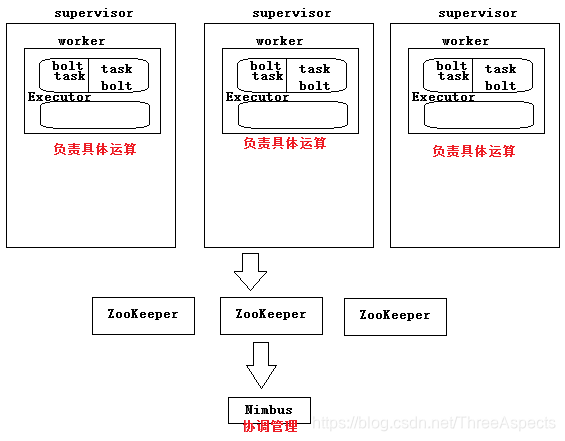
Nimbus和Supervisor之间的所有协调工作都是通过ZooKeeper集群完成。Nimbus进程和Supervisor进程都是快速失败且无状态的。所有的状态要么在Zookeeper中,要么在本地磁盘上。
一个topology(拓扑) 是 spouts(拓扑的消息源) 和 bolts(拓扑的处理逻辑单元) 组成的图,通过 stream groupings(流的分组策略) 将图中的spouts和bolts连接起来。一个消息流是一个没有边界的 tuple(消息元组) 序列,通过对stream中tuple序列中每个字段命名来定义stream。所有的消息处理逻辑被封装在bolts里面,如过滤、聚合、查询数据库等。
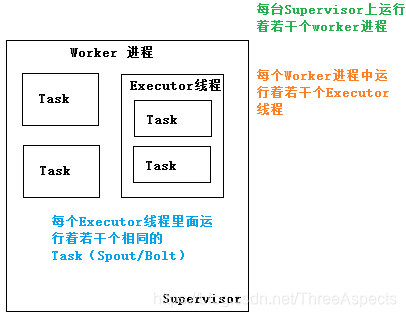
一个topology可能会在一个或者多个worker(工作进程)里面执行。每个worker是一个物理JVM并且执行整个topology的一部分。每一个spout和bolt会被当做很多task在整个集群里执行。每一个executor对应到一个线程,在这个线程上运行多个task。stream grouping定义了怎么从一对task发射tuple到另一堆task。
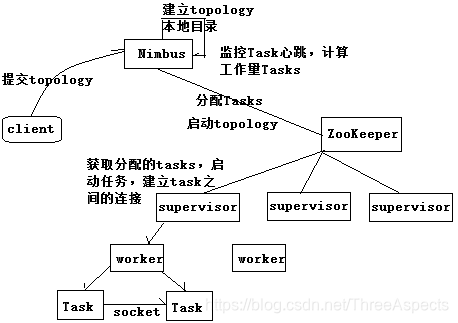
在Storm的集群里面有两种节点:控制节点(master node)和工作节点(worker node)。控制节点上面运行一个叫Nimbus后台程序,它的作用类似Hadoop里的JobTracker。Nimbus负责在集群里面分发代码,分配计算任务给机器,并监控状态。每一个工作节点上面运行一个叫做Supervisor的节点。Supervisor会监听分配给它那台机器的工作,根据需要启动、关闭工作进程(worker)。每一个工作进程执行一个topology的一个子集;一个运行的topology由运行在很多机器上的很多工作进程组成。Supervisor(worker进程)类似于Hadoop中的NodeManager(YarnChild)。topology与MapReduce区别在于:MapReduce最终会结束,topology会永远运行(除非手动kill)。
topology运行机制
一个Worker只属于一个topology,每个Worker中中运行的Task只能属于这个topology;反之,一个topology运行在多个Worker上。一个topology要求的Worker数量如果不被满足,集群在任务分配时,根据现有的Worker先运行topology;如果当前集群中Worker数量为0,那么最新提交的topology将只会被标识active,不会运行,只有当集群有了空闲资源之后,才会被运行。
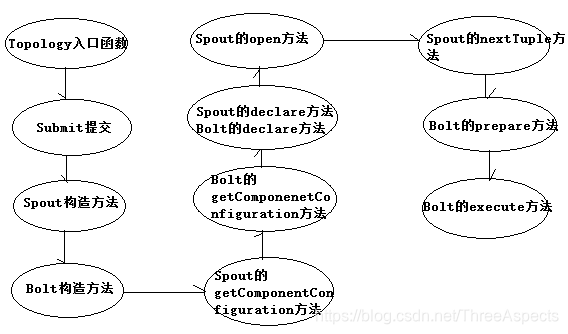
Storm提交之后,会把代码首先存放到Nimbus节点的inbox目录。在设定topology所关联的spouts和bolts时,可以同时设置当前spout和bolt的executor和task数目。每个组件(spout/bolt)的构造方法和declareOutputFields方法都只会被调用一次。open方法、prepare方法的调用是多次的。入口函数中设定的setSpout或setBolt里的并行度参数指的是executor的数目,是负责运行组建中的task的线程的数目,这个数目决定上述方法被调用次数。nextTuple方法、execute方法是一直运行的,nextTuple方法不断发射tuple,bolt的execute不断接受tuple进行处理。在提交一个topology之后,Storm就会创建spout/bolt实例并序列化。之后,将序列化的component发送给所有的任务所在的机器(Supervisor节点),在每一个任务上反序列化component。
任务分配好之后,Nimbes节点会将任务的信息提交到ZooKeeper集群,同时ZooKeeper集群中会有workerbeats节点,存储当前topology的所有worker进程的心跳信息。Supervisor节点会不断地轮询ZooKeeper集群,在ZooKeeper的assignments节点中保存了所有topology的任务分配信息、代码存储目录、任务之间的关联关系等,supervisor通过轮询此节点的内容,来领取自己的任务,启动worker进程运行。一个topology运行之后,就会不断地通过spouts来发送stream流,通过bolts来不断处理接收到的stream流。
Stream grouping
stream grouping是用来定义一个stream应该如何分配数据给bolts。Shuffle Grouping——随机分组,随机派发stream里面的tuple,保证每个bolt接收到的tuple数目大致相同。Fields Grouping——按字段分组,比如按userid分组,具有相同userid的tuple会被分到相同的bolts里的一个task,而不同的userid则会被分配到不同的bolts里的task。All Grouping——广播发送,对于每一个tuple,所有的bolts都会受到。Global Grouping——全局分组,这个tuple被分配到strom中的一个bolt的其中一个task。Non Grouping——不分组,即stream不关心到底谁会收到tuple。目前这种分组和Shuffle grouping是一样的效果,不同的是storm会把这个bolt放到这个bolt的订阅者同一个线程里面去执行。
流式计算与离线计算
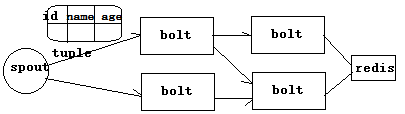
流式计算一般架构如图。

其中,Flume用来获取数据,Kafka用来临时保存数据,Storm用来计算数据,Redis是个内存数据库,用来保存数据。
离线计算:批量获取数据、批量传输数据、周期性计算数据、数据展示。例如:Sqoop批量导入数据、HDFS批量存储数据、MapReduce批量计算数据、Hive批量计算数据。














 2475
2475











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









