






这篇文章提出了一种新的正则化方法,称为ShakeDrop正则化,旨在解决深度神经网络中的过拟合问题,特别是针对ResNet及其改进版本(如Wide ResNet、PyramidNet和ResNeXt)。以下是文章的主要内容总结:
-
背景与动机:
-
深度神经网络(如ResNet及其变体)在图像分类等任务中取得了显著进展,但过拟合问题仍然存在。
-
现有的正则化方法(如Shake-Shake)虽然有效,但仅适用于特定的网络架构(如ResNeXt),且训练过程可能不稳定。
-
-
提出的方法:
-
ShakeDrop正则化:一种新的正则化方法,结合了Shake-Shake和RandomDrop的思想,适用于更广泛的网络架构(如ResNet、Wide ResNet和PyramidNet)。
-
ShakeDrop通过在训练过程中引入随机扰动来增强模型的泛化能力,并通过引入训练稳定器来缓解训练不稳定的问题。
-
-
方法细节:
-
ShakeDrop在训练过程中对前向和反向传播的计算引入随机扰动,并通过概率开关控制扰动的强度。
-
通过实验确定了ShakeDrop的最佳参数范围(如 αα 和 ββ 的取值范围)和更新规则。
-
-
实验与结果:
-
在CIFAR、ImageNet和COCO数据集上进行了广泛的实验,验证了ShakeDrop的有效性。
-
实验结果表明,ShakeDrop在大多数情况下优于现有的正则化方法(如Shake-Shake和RandomDrop),尤其是在深层网络中表现更为显著。
-
ShakeDrop还可以与其他正则化方法(如mixup)结合使用,进一步提升模型性能。
-
-
结论:
-
ShakeDrop是一种有效的正则化方法,适用于多种网络架构,能够显著提高模型的泛化能力。
-
通过实验验证了ShakeDrop在不同数据集和任务中的优越性,尤其是在深层网络中表现更为突出。
-
ShakeDrop通过引入随机扰动和训练稳定机制,成功解决了现有正则化方法的局限性,并在多个基准数据集上取得了优异的性能这里是自己的论文阅读记录,感兴趣的话可以参考一下,如果需要阅读原文的话可以看这里,如下所示:

摘要
过拟合是深度神经网络中的一个关键问题,即使在最新的网络架构中也是如此。本文中,为了缓解ResNet及其改进版本(如Wide ResNet、PyramidNet和ResNeXt)的过拟合效应,我们提出了一种新的正则化方法,称为ShakeDrop正则化。ShakeDrop受到Shake-Shake的启发,Shake-Shake是一种有效的正则化方法,但仅适用于ResNeXt。ShakeDrop比Shake-Shake更有效,并且不仅适用于ResNeXt,还适用于ResNet、Wide ResNet和PyramidNet。一个关键点是实现训练的稳定性。由于有效的正则化通常会导致训练不稳定,我们引入了一种训练稳定器,这是对现有正则化器的一种非常规使用。通过各种条件下的实验,我们展示了ShakeDrop在哪些条件下表现良好。
关键词: 过拟合,ShakeDrop正则化,深度ResNet,PyramidNet,ResNeXt,Wide ResNet,图像分类,神经网络
1 引言
近年来,深度神经网络在通用物体识别方面取得了显著进展。自从ResNet [11] 通过引入构建块使得使用超过百层的深度卷积神经网络(CNN)成为可能以来,其改进版本如Wide ResNet [36]、PyramidNet [8, 9] 和 ResNeXt [33] 不断刷新最低错误率的记录。
然而,这些基础网络架构的发展并不足以减少由于过拟合导致的泛化误差(即训练误差和测试误差之间的差异)。为了改善测试误差,研究者提出了多种正则化方法,这些方法通过向CNN引入额外信息来减少过拟合 [23]。广泛使用的正则化方法包括数据增强 [18]、随机梯度下降(SGD)[37]、权重衰减 [20]、批归一化(BN)[15]、标签平滑 [28]、对抗训练 [6]、mixup [29, 30, 31, 38] 和 dropout [26, 32]。尽管使用了这些正则化方法,泛化误差仍然较大,因此研究者一直在研究更有效的正则化方法。
最近,一种名为Shake-Shake正则化 [4, 5] 的有效正则化方法取得了最低的测试误差。这是一种有趣的方法,在训练过程中,它使用随机变量干扰前向传播的计算,并使用另一个随机变量干扰反向传播的计算。其有效性通过在ResNeXt上应用的实验得到了验证(此后,这种组合称为“ResNeXt + Shake-Shake”),该实验在CIFAR-10/100数据集上取得了最低的错误率 [17]。然而,Shake-Shake有两个缺点:(i) 它仅适用于ResNeXt,(ii) 其有效性的原因尚未明确。
本文解决了这两个问题。对于问题(i),我们提出了一种新的强大的正则化方法,称为ShakeDrop正则化,它比Shake-Shake更有效。其主要优势在于它不仅适用于ResNeXt(此后称为三分支架构),还适用于ResNet、Wide ResNet和PyramidNet(此后称为双分支架构)。主要难点在于克服训练不稳定性。我们通过提出一种新的稳定机制来解决这个问题,该机制适用于难以训练的网络。对于问题(ii),在推导ShakeDrop的过程中,我们提供了对Shake-Shake的直观解释。此外,我们还展示了ShakeDrop的工作原理。通过使用各种基础网络架构和参数的实验,我们展示了ShakeDrop成功工作的条件。
本文是ICLR研讨会论文 [35] 的扩展版本。
2 ResNet家族的正则化方法
在本节中,我们介绍了两种用于ResNet家族的正则化方法,这两种方法都用于推导出本文提出的方法。
Shake-Shake正则化 [4, 5] 是一种适用于ResNeXt的有效正则化方法。如图1(a)所示。ResNeXt的基本构建块具有三分支架构,其公式为:

RandomDrop正则化(也称为Stochastic Depth和ResDrop)[14] 是一种最初为ResNet提出的正则化方法,也应用于PyramidNet [34]。如图1(b)所示。ResNet的基本构建块具有双分支架构,其公式为:

RandomDrop可以看作是dropout [26] 的简化版本。主要区别在于RandomDrop丢弃的是层,而dropout丢弃的是元素。
3 提出的方法
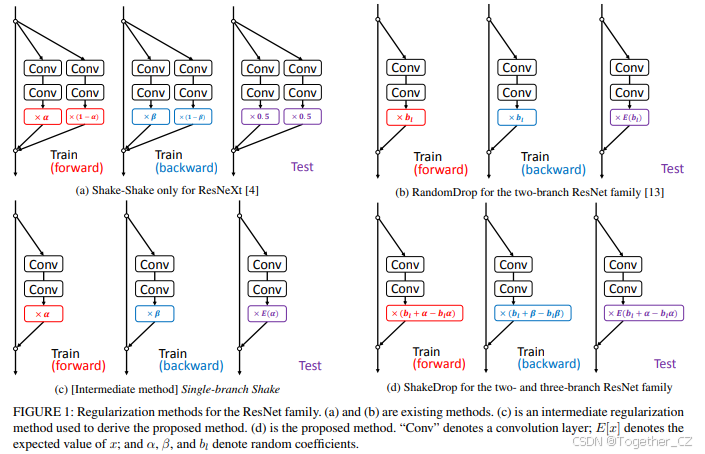
ShakeDrop正则化
提出的ShakeDrop如图1(d)所示,其公式为:

ShakeDrop的推导
1) Shake-Shake正则化的解释
我们提供了对Shake-Shake的直观解释;据我们所知,这尚未被提供。如公式(2)(和图1(a))所示,在前向传播中,Shake-Shake使用随机权重 α 对两个残差分支的输出(即 F1(x) 和 F2(x))进行插值。DeVries和Taylor [2] 证明了在特征空间中对两个数据进行插值可以合成合理的增强数据;因此,Shake-Shake前向传播中的插值可以解释为合成合理的增强数据。使用随机权重 α 使我们能够生成许多不同的增强数据。相比之下,在反向传播中,使用不同的随机权重 β 来干扰参数的更新,这有望通过增强SGD的效果来防止参数陷入局部最小值 [16]。
2) 单分支Shake正则化
Shake-Shake的正则化机制依赖于两个或更多残差分支;因此,它仅适用于三分支网络架构(即ResNeXt)。为了在双分支架构(即ResNet、Wide ResNet和PyramidNet)上实现类似于Shake-Shake的正则化,我们需要一种不同于前向传播中插值的机制,该机制可以在特征空间中合成增强数据。事实上,DeVries和Taylor [2] 不仅证明了插值,还证明了在特征空间中添加噪声可以生成合理的增强数据。因此,我们借鉴Shake-Shake的思想,对残差分支的输出(即公式(3)中的 F(x))应用随机扰动;即:
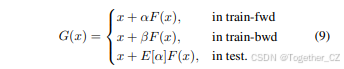
我们将这种正则化方法称为单分支Shake。如图1(c)所示。单分支Shake预期与Shake-Shake一样有效。然而,它在实际应用中效果不佳。例如,在我们的初步实验中,我们将其应用于110层的PyramidNet,使用 α∈[0,1]和 β∈[0,1],遵循Shake-Shake的设置。然而,在CIFAR-100数据集上的结果非常差(错误率为77.99%)。
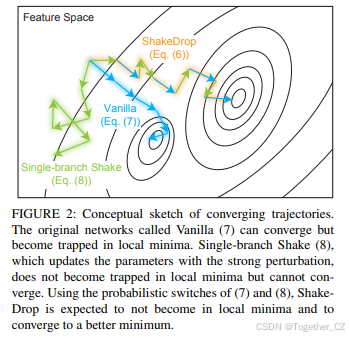
3) 训练稳定化
在本节中,我们探讨了单分支Shake失败的原因。一个自然的猜测是Shake-Shake具有单分支Shake所没有的稳定机制。该机制是“两个残差分支”。我们提出了一个论点来验证这一点。如第II节所述,在训练过程中,Shake-Shake使得两个分支的梯度分别是正确计算梯度的 β/α倍和 (1−β)/(1−α) 倍。因此,当 α 接近0或1时,它可能会导致训练无法收敛(破坏训练),因为它可能使梯度变得过大。然而,Shake-Shake的两个残差分支起到了故障保护系统的作用;即,即使一个分支的系数很大,另一个分支的系数也会保持较小。因此,至少在一个分支上的训练不会被破坏。而单分支Shake没有这样的故障保护系统。
从上述讨论中可以看出,单分支Shake的失败是由于扰动过强且缺乏稳定机制。由于减弱扰动只会减弱正则化的效果,我们需要一种方法在强扰动下稳定不稳定的学习。
我们提出使用RandomDrop的机制来解决这个问题。RandomDrop旨在使网络看起来更浅,以避免梯度消失、特征重用减少和训练时间过长的问题。在我们的场景中,RandomDrop的原始使用并没有积极效果,因为强扰动网络的较浅版本(例如,“PyramidNet + 单分支Shake”的较浅版本)也会受到强扰动的影响。因此,我们将RandomDrop的机制用作以下两种网络架构的概率开关:
-
原始网络(例如PyramidNet),对应于公式(7),
-
受到强扰动影响的网络(例如“PyramidNet + 单分支Shake”),对应于公式(8)。
通过混合这两种网络,如图2所示,预期当选择原始网络时,学习能够正确推进;当选择受到强扰动的网络时,学习会受到干扰。
为了获得良好的性能,这两种网络应该很好地平衡,这由参数 pL 控制。我们将在第IV节中讨论这个问题。
与现有正则化方法的关系
在本节中,我们讨论了ShakeDrop与现有正则化方法之间的关系。其中,SGD和权重衰减是深度神经网络训练中常用的技术。尽管它们并非专门为正则化设计,但研究者指出它们具有泛化效果 [20, 37]。BN [15] 是一种强大的正则化技术,近年来广泛应用于网络架构中。ShakeDrop是对这些正则化方法的补充。
ShakeDrop与RandomDrop [14] 和dropout [26, 32] 有以下两点不同:它们不会显式生成新数据,也不会基于噪声梯度更新网络参数。当 α=β=0 时,ShakeDrop与RandomDrop一致。
一些方法通过生成新数据进行正则化。它们总结在表1中。数据增强 [18] 和对抗训练 [6] 在(输入)数据空间中合成数据。它们的不同之处在于生成数据的方式。前者使用手动设计的方法,如随机裁剪和水平翻转,而后者自动生成应用于训练的数据以提高泛化性能。标签平滑 [28] 为现有数据生成(或更改)标签。上述方法使用单个样本生成新数据。相比之下,一些方法需要多个样本来生成新数据。Mixup [38]、BC学习 [30] 和RICAP [29] 通过插值两个或更多数据生成新数据及其对应的类别标签。尽管它们在数据空间中生成新数据,但流形mixup [31] 也在特征空间中生成新数据。与ShakeDrop相比,ShakeDrop使用单个样本在特征空间中生成数据,除了Shake-Shake外,没有其他正则化方法属于同一类别。
需要注意的是,正则化方法的选择并不总是互斥的。我们已经成功地将ShakeDrop与mixup结合使用(见第V-D节)。尽管同一类别的正则化方法可能不能一起使用(例如“mixup和BC学习”以及“ShakeDrop和Shake-Shake”),但不同类别的正则化方法可以一起使用。因此,开发某一类别中的最佳方法是有意义的。
4 初步实验

α 和 β 的范围
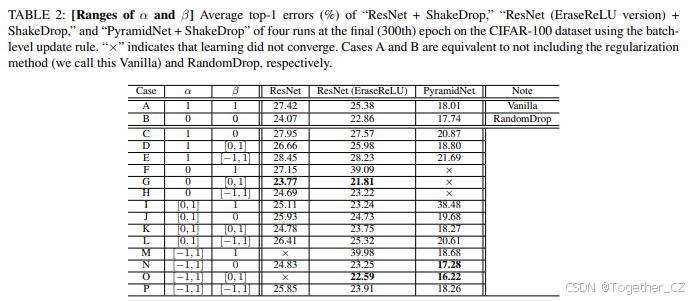
通过实验探索了 α 和 β 的最佳参数范围。我们将ShakeDrop应用于三种网络架构:ResNet、ResNet(EraseReLU版本)和PyramidNet。在EraseReLU版本中,构建块底部的ReLU被移除 [3]。需要注意的是,EraseReLU对PyramidNet没有影响,因为PyramidNet的构建块底部没有ReLU。
表2显示了我们测试的 α 和 β 的代表性参数范围及其结果。案例A和B分别对应于原始网络(即没有正则化)和RandomDrop。在所有三种网络架构中,案例B优于案例A。我们分别考虑这三种网络架构的结果。
-
PyramidNet 在三种网络架构中取得了最低的错误率。只有案例N和O优于案例B。其中,案例O表现最佳。
-
ResNet 的表现与PyramidNet不同:在PyramidNet上表现最佳的案例O在ResNet上无法收敛。只有案例G优于案例B。
-
ResNet(EraseReLU版本) 兼具PyramidNet和ResNet的特点;即案例O和G都优于案例B。案例G表现最佳。
通过第V节中各种基础网络架构的实验,我们发现案例O在“EraseReLU”架构上有效,而案例G在非“EraseReLU”架构上有效。
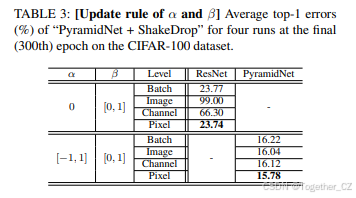
α 和 β 的更新规则
从批次、图像、通道和像素级别找到了 α 和 β 的最佳更新规则。ShakeDrop决定在每个构建块上是否丢弃。与Dropout和RandomDrop不同,即使决定丢弃某个构建块,我们仍然可以选择如何确定 α 和 β。也就是说,α 和 β 可以为每个批次并行绘制,每个图像在批次中并行绘制,每个通道或每个元素绘制。
在实验中,使用了第IV-A节中找到的最佳 α 和 β(即ResNet的 α=0 和 β∈[0,1],以及PyramidNet的 α∈[−1,1] 和 β∈[0,1])。表3显示,像素级别对ResNet和PyramidNet都是最佳的。
用于分析ShakeDrop行为的 (α,β) 组合
尽管我们成功找到了 α 和 β 的有效范围及其更新规则,但我们仍然不理解是什么机制有助于提高ShakeDrop的泛化性能。一个原因是 α 和 β 是随机变量。因此,在训练结束时,我们可以获得一个使用各种观察到的 α 和 β 值训练的网络。这使得理解机制变得更加困难。
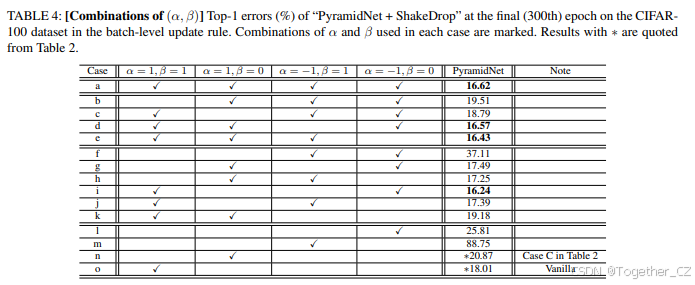
因此,在本节中,我们探索了 (α,β) 的有效组合。(α,β) 的组合定义如下:从PyramidNet的最佳范围 α∈[−1,1] 和 β∈[0,1] 中,通过取范围的端点,我们得到一组 (α,β) 对:{(1,1),(1,0),(−1,1),(−1,0)}。然后,我们检查其所有组合,如表4所示。直观地说,当 bl=0 时,不是从范围内绘制 α 和 β,而是从池中等概率选择一个 (α,β) 对。
表4显示了 (α,β)的组合及其在PyramidNet上的结果。与表2中的最佳结果(即案例O;16.22%)相比,表4中的结果几乎相当。特别是,表4中的最佳结果(即案例i;16.24%)几乎相同。这表明在某些范围内随机绘制 α 和 β 并不是提高错误率的主要因素。

由于这是 α=−1 和 β=0 的组合,它们的综合效果会发生。根据上述 α=−1 的情况,前向传播的计算受到扰动,其影响传播到后续层。在反向传播中,根据 β=0 的情况,只有选择层的网络参数不会更新。这可以避免由负 α 引起的破坏性更新。因此,(−1,0) 预期是有效的。案例i和l包含 (−1,0),前者是最佳案例。
通过扩展上述讨论,我们可以使用 α=0 和 β∈[0,1] 来解释ShakeDrop的行为,这在ResNet上最为有效。当 α=0 时,在前向传播中,选择层的输出与输入相同。在反向传播中,网络参数的更新量受到 β 的扰动。
5 实验
在CIFAR数据集上的比较
将提出的ShakeDrop与RandomDrop和Shake-Shake以及原始网络(无正则化)在ResNet、Wide ResNet、ResNeXt和PyramidNet上进行了比较。实现细节见附录A。
表5显示了CIFAR数据集 [17] 上的条件和实验结果。在表中,方法名称后跟其构建块的组件。我们使用了第IV节中找到的ShakeDrop参数;即原始网络使用 α=0,β∈[0,1],残差分支以BN结尾的修改网络(例如EraseReLU版本)使用 α∈[−1,1],β∈[0,1]。在ResNet和双分支ResNeXt中,除了原始形式外,还检查了EraseReLU版本。在Wide ResNet中,BN被添加到残差分支的末尾,以便残差分支以BN结尾。在三分支ResNeXt中,我们检查了两种应用RandomDrop和ShakeDrop的方法,分别称为“类型A”和“类型B”。“类型A”和“类型B”表示正则化单元分别在残差分支的加法单元之后和之前插入;即在训练阶段的前向传播中,类型A由

表5显示,ShakeDrop不仅可以应用于三分支架构(ResNeXt),还可以应用于双分支架构(ResNet、Wide ResNet和PyramidNet),并且ShakeDrop在大多数情况下优于RandomDrop和Shake-Shake。在带有BN的Wide ResNet中,尽管ShakeDrop与原始网络相比提高了错误率,但与RandomDrop相比没有提高。这是因为该网络只有28层。如RandomDrop论文 [14] 所示,RandomDrop在浅层网络上效果较差,在深层网络上效果更好。我们在ShakeDrop中观察到了相同的现象,并且ShakeDrop比RandomDrop更敏感。详见第V-E节。
在ImageNet数据集上的比较
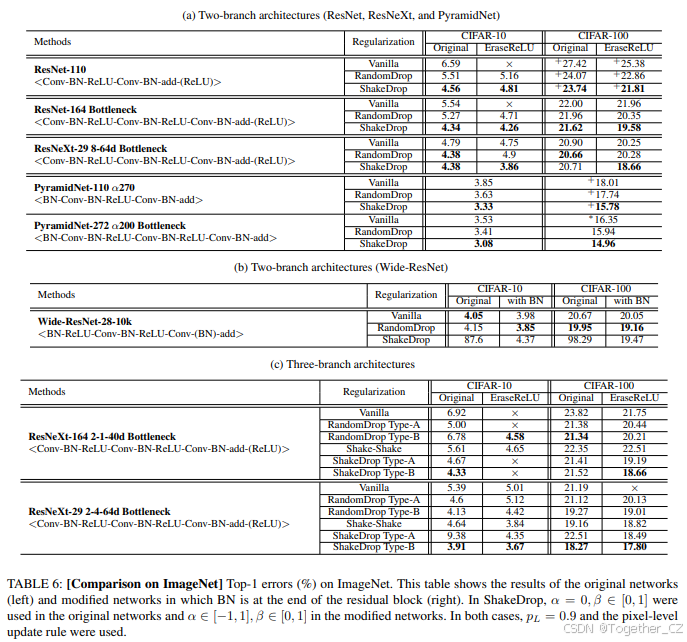
我们还在ImageNet分类数据集 [19] 上使用152层的ResNet、ResNeXt和PyramidNet进行了实验。实现细节见附录A。我们使用了在CIFAR数据集上找到的最佳参数,除了 pL。我们通过实验选择了 pL=0.9。
表6显示了实验结果。与CIFAR案例相反,EraseReLU版本比原始网络差,这不支持EraseReLU论文 [3] 的说法。在ResNet和ResNeXt中,无论是原始版本还是EraseReLU版本,ShakeDrop都明显优于RandomDrop和原始网络(ShakeDrop在原始网络中比原始网络提高了0.84%和0.15%)。在PyramidNet中,ShakeDrop优于原始网络(ShakeDrop比原始网络提高了0.60%)和RandomDrop(ShakeDrop比RandomDrop提高了0.29%)。因此,在ResNet、ResNeXt和PyramidNet上,ShakeDrop明显优于RandomDrop和原始网络。
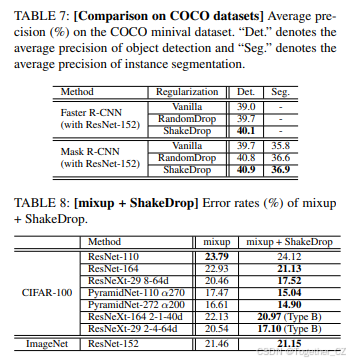
在COCO数据集上的比较
根据第V-A和V-B节的结果,我们认为ShakeDrop促进了特征提取的泛化性,并在COCO数据集 [22] 上评估了泛化性。我们使用了Faster R-CNN和Mask R-CNN,并使用了第V-B节中ImageNet预训练的152层原始版本ResNet。实现细节见附录A。
表7显示了实验结果。在Faster R-CNN和Mask R-CNN上,ShakeDrop明显优于RandomDrop和原始网络。因此,ShakeDrop不仅促进了图像分类的特征提取泛化性,还促进了检测和实例分割的泛化性。
与mixup的同时使用
如第III-C节所述,我们已成功将ShakeDrop与mixup结合使用。表8显示了结果。在大多数情况下,ShakeDrop进一步提高了应用mixup的基础神经网络的错误率。这表明ShakeDrop不是其他正则化方法(如mixup)的竞争对手,而是“合作者”。
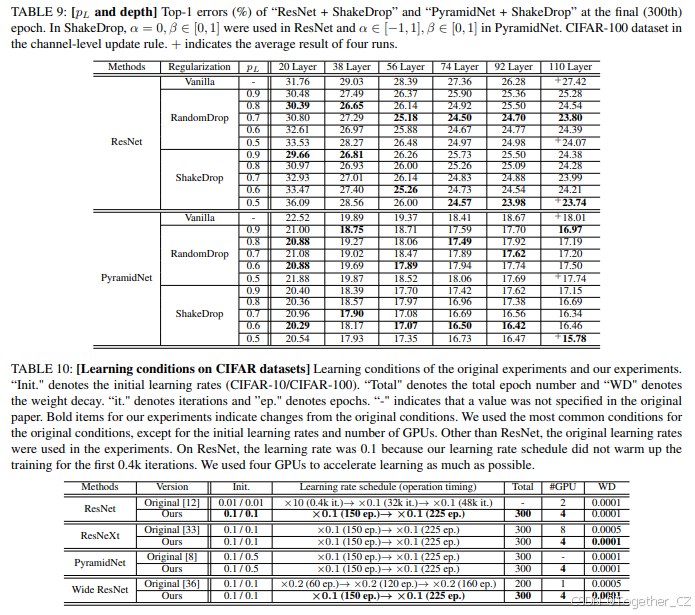
网络深度与最佳 pL 的关系
如第II节所述,实验发现RandomDrop在更深层的网络上更有效(见 [14] 中图8右侧的图)。我们在ShakeDrop和RandomDrop上进行了类似的实验,以比较它们对网络深度的敏感性。
表9显示,错误率随 pL 和网络深度的变化而变化。具有较大 pL 的ShakeDrop在较浅的网络中往往更有效。在关于RandomDrop的 pL 与泛化性能关系的实验研究 [14] 中获得了相同的观察结果。我们建议在较浅的网络架构中使用较大的 pL。
6 结论
我们提出了一种新的随机正则化方法,称为ShakeDrop,原则上可以应用于ResNet家族。通过在CIFAR和ImageNet数据集上的实验,我们确认在大多数情况下,ShakeDrop优于同一类别的现有正则化方法,即Shake-Shake和RandomDrop。
附录A 实验条件

CIFAR数据集
CIFAR数据集 [17] 的输入图像按以下方式处理。原始图像为32×32像素,经过颜色归一化后,以50%的概率水平翻转。然后,它们被零填充为40×40像素,并随机裁剪为32×32像素的图像。在PyramidNet上,初始学习率在CIFAR-10上设置为0.1,在CIFAR-100上设置为0.5,遵循PyramidNet论文 [8]。除PyramidNet外,初始学习率设置为0.1。初始学习率在整个学习过程(300个epoch)的第150个epoch和第225个epoch分别衰减0.1倍。此外,使用了0.0001的权重衰减、0.9的动量和128的批量大小,并在四个GPU上运行。“MSRA” [10] 被用作滤波器参数初始化器。我们在没有任何集成技术的情况下评估了top-1错误。遵循RandomDrop论文 [14],使用了线性衰减参数 pL=0.5。ShakeDrop使用了 α=0,β=[0,1](原始)和 α=[−1,1],β=[0,1](ResNet和ResNeXt的EraseReLU版本、带有BN的Wide ResNet和PyramidNet)的参数,并使用了像素级更新规则。
ImageNet数据集
ImageNet [1] 的输入图像按以下方式处理。原始图像使用随机纵横比 [27] 进行扭曲,并随机裁剪为224×224像素的图像。然后,图像以50%的概率水平翻转,并添加标准颜色噪声 [19]。在PyramidNet上,初始学习率设置为0.5。初始学习率在整个学习过程(120个epoch)的第60、90和105个epoch分别衰减0.1倍,遵循 [8]。此外,使用了128的批量大小,并在八个GPU上运行。除PyramidNet外,初始学习率设置为0.1。初始学习率在整个学习过程(90个epoch)的第30、60和80个epoch分别衰减0.1倍,遵循 [7]。此外,使用了256的批量大小,并在八个GPU上运行。使用了0.0001的权重衰减和0.9的动量。“MSRA” [10] 被用作滤波器参数初始化器。我们在没有任何集成技术的情况下评估了从图像中心裁剪的224×224像素的单张图像的top-1错误,该图像被调整为较短边为256。使用了线性衰减参数 pL=0.9。ShakeDrop使用了 α=0,β=[0,1](原始)和 α=[−1,1],β=[0,1](ResNet和ResNeXt的EraseReLU版本以及PyramidNet)的参数,并使用了像素级更新规则。
COCO数据集
COCO [22] 的输入图像按以下方式处理。我们在80k训练集和35k验证子集的并集上训练模型,并在剩余的5k验证子集上评估模型。我们使用ResNet-152作为骨干网络,使用FPN [21] 作为预测网络。为了使用ResNet-152作为特征提取器,我们使用了期望值 ![]() 而不是ShakeDrop正则化。根据ImageNet数据集的实验条件,原始图像使用ImageNet数据集图像的平均值和标准差进行颜色归一化。初始学习率设置为0.2。初始学习率在整个学习过程(90,000次迭代)的第60,000和80,000次迭代分别衰减0.1倍。此外,使用了16的批量大小,并在八个GPU上运行。使用了0.0001的权重衰减。其他实验条件根据_maskrcnn-benchmark_8 设置。
而不是ShakeDrop正则化。根据ImageNet数据集的实验条件,原始图像使用ImageNet数据集图像的平均值和标准差进行颜色归一化。初始学习率设置为0.2。初始学习率在整个学习过程(90,000次迭代)的第60,000和80,000次迭代分别衰减0.1倍。此外,使用了16的批量大小,并在八个GPU上运行。使用了0.0001的权重衰减。其他实验条件根据_maskrcnn-benchmark_8 设置。



















 26
26

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











