



在当今社会,随着科技生产力的飞速发展,汽车早已成为人们日常出行不可或缺的交通工具。它不仅极大地提高了人们的出行效率,也为生活带来了诸多便利。然而,随着汽车保有量的不断增加,交通安全问题也日益凸显。疲劳驾驶和分心驾驶是导致交通事故的两大隐形杀手,它们严重威胁着司机和他人的生命安全。幸运的是,随着人工智能技术的蓬勃发展,我们有了应对这些安全隐患的新利器。疲劳驾驶和分心驾驶的危害不言而喻。长时间驾驶会使司机身体和精神处于高度紧张状态,反应速度和判断能力会逐渐下降,极易引发交通事故。而分心驾驶,如接打电话、玩手机、整理妆容等行为,会让司机的注意力从道路上转移,大大增加了事故发生的概率。据统计,每年因疲劳驾驶或分心驾驶导致的交通事故数量惊人,这不仅给无数家庭带来了痛苦,也给社会造成了巨大的损失。
然而,科技的进步总是在为人类的安全保驾护航。如今,人工智能技术已经渗透到我们生活的方方面面,汽车驾驶领域也不例外。借助车载内置安装的多摄像头,我们可以实时捕捉司机驾驶过程中的画面。这些摄像头就像是汽车的“眼睛”,能够全方位地观察司机的一举一动。而基于人工智能的检测识别预警模型,则是汽车的“大脑”,能够对这些画面进行智能分析识别。当司机出现疲劳驾驶或分心驾驶的迹象时,如频繁眨眼、打哈欠、目光偏离前方、操作仪表等行为,预警模型能够迅速捕捉到这些异常信号,并进行精准判定。一旦判定当前状态为疲劳驾驶或分心驾驶,系统会立即发出预警信息,提醒司机集中精神或尽快行驶到安全区域休息。这种预警机制不仅能够及时发现潜在的安全隐患,还能在关键时刻挽救生命。人工智能技术在车辆驾驶场景中的应用,不仅仅局限于疲劳驾驶和分心驾驶的检测。它还可以通过分析道路状况、交通流量等信息,为司机提供更安全、更高效的驾驶建议。例如,当遇到复杂路况时,系统可以提前预警并建议司机减速慢行;当发现前方有危险时,系统可以及时提醒司机采取避让措施。这些智能化的功能,让驾驶变得更加安全、便捷。
本文正是在这样的思考背景下,想要探索尝试从实验性质的角度出来构建分心驾驶智能化检测识别系统,在前文中我们已经进行了相关的开发实践,感兴趣的话可以自行移步阅读即可:
《AI赋能守护行车安全新防线,基于YOLOv5全系列【n/s/m/l/x】参数模型开发构建驾驶车辆场景下驾驶员疲劳分心驾驶行为智能检测预警系统》
《AI赋能守护行车安全新防线,基于YOLOv7全系列【tiny/l/x】参数模型开发构建驾驶车辆场景下驾驶员疲劳分心驾驶行为智能检测预警系统》
《AI赋能守护行车安全新防线,基于YOLOv8全系列【n/s/m/l/x】参数模型开发构建驾驶车辆场景下驾驶员疲劳分心驾驶行为智能检测预警系统》
《AI赋能守护行车安全新防线,基于YOLOv9全系列【yolov9/t/s/m/c/e】参数模型开发构建驾驶车辆场景下驾驶员疲劳分心驾驶行为智能检测预警系统》
《AI赋能守护行车安全新防线,基于YOLOv10全系列【n/s/m/b/l/x】参数模型开发构建驾驶车辆场景下驾驶员疲劳分心驾驶行为智能检测预警系统》
《AI赋能守护行车安全新防线,基于YOLOv11全系列【n/s/m/l/x】参数模型开发构建驾驶车辆场景下驾驶员疲劳分心驾驶行为智能检测预警系统》
《AI赋能守护行车安全新防线,基于最新以注意力为核心的YOLOv12全系列【n/s/m/l/x】参数模型开发构建驾驶车辆场景下驾驶员疲劳分心驾驶行为智能检测预警系统》
本文正是在这样的思考背景下想要从实验性质的角度出发,尝试应用嵌入式端超轻量级的LeYOLO系列的参数模型来开发构建轻量级的检测识别分析系统,首先看下实例效果:
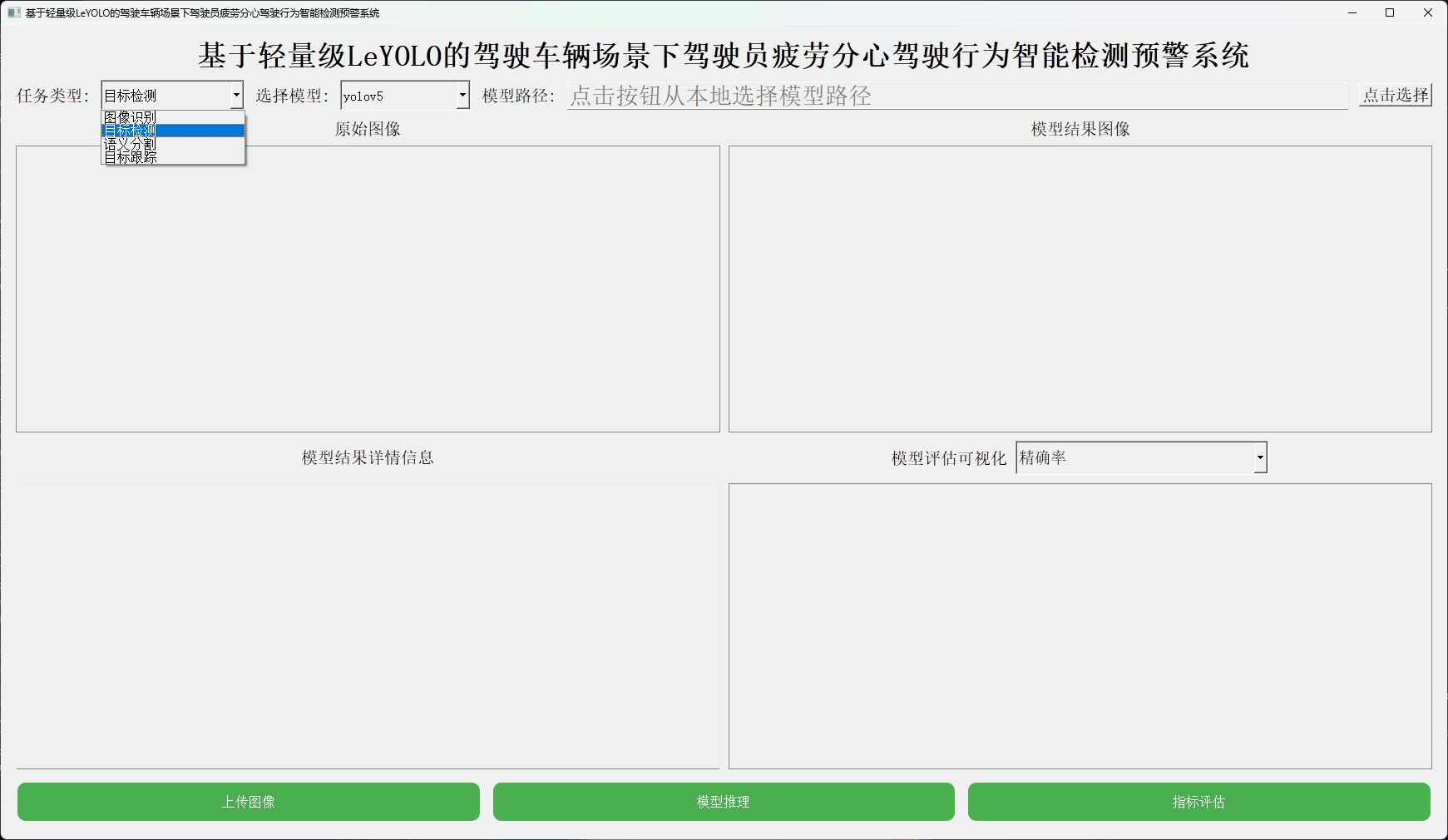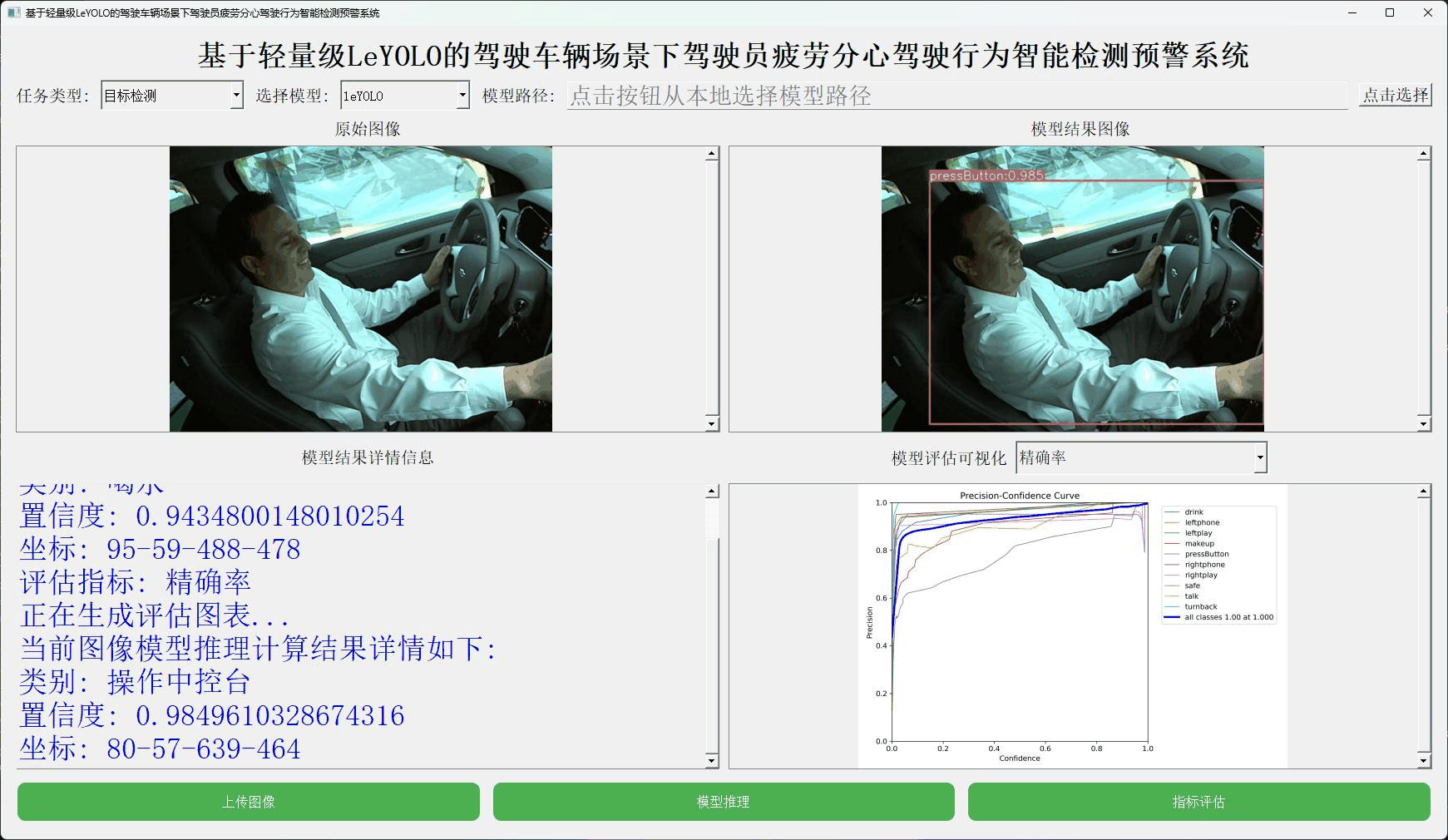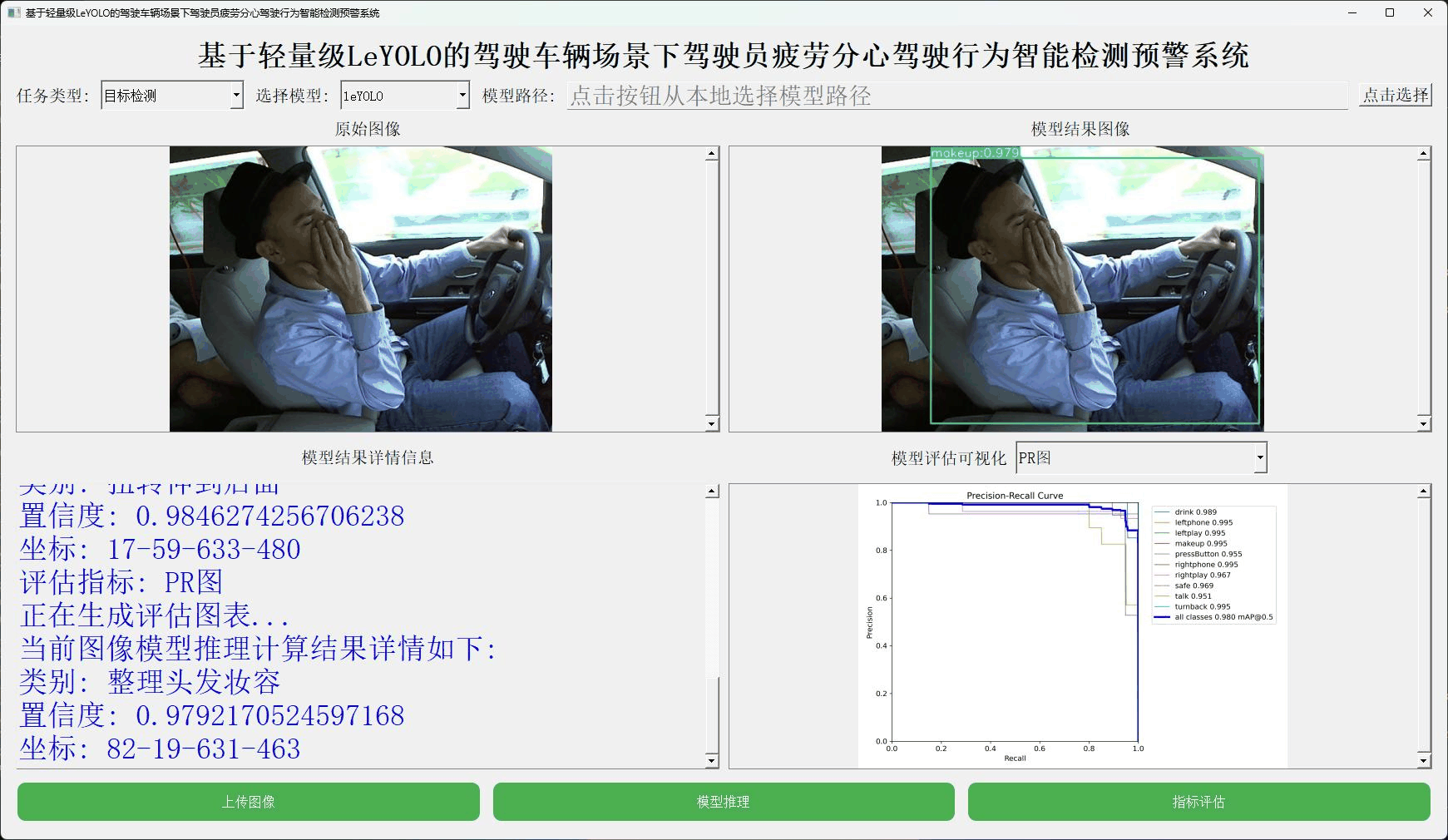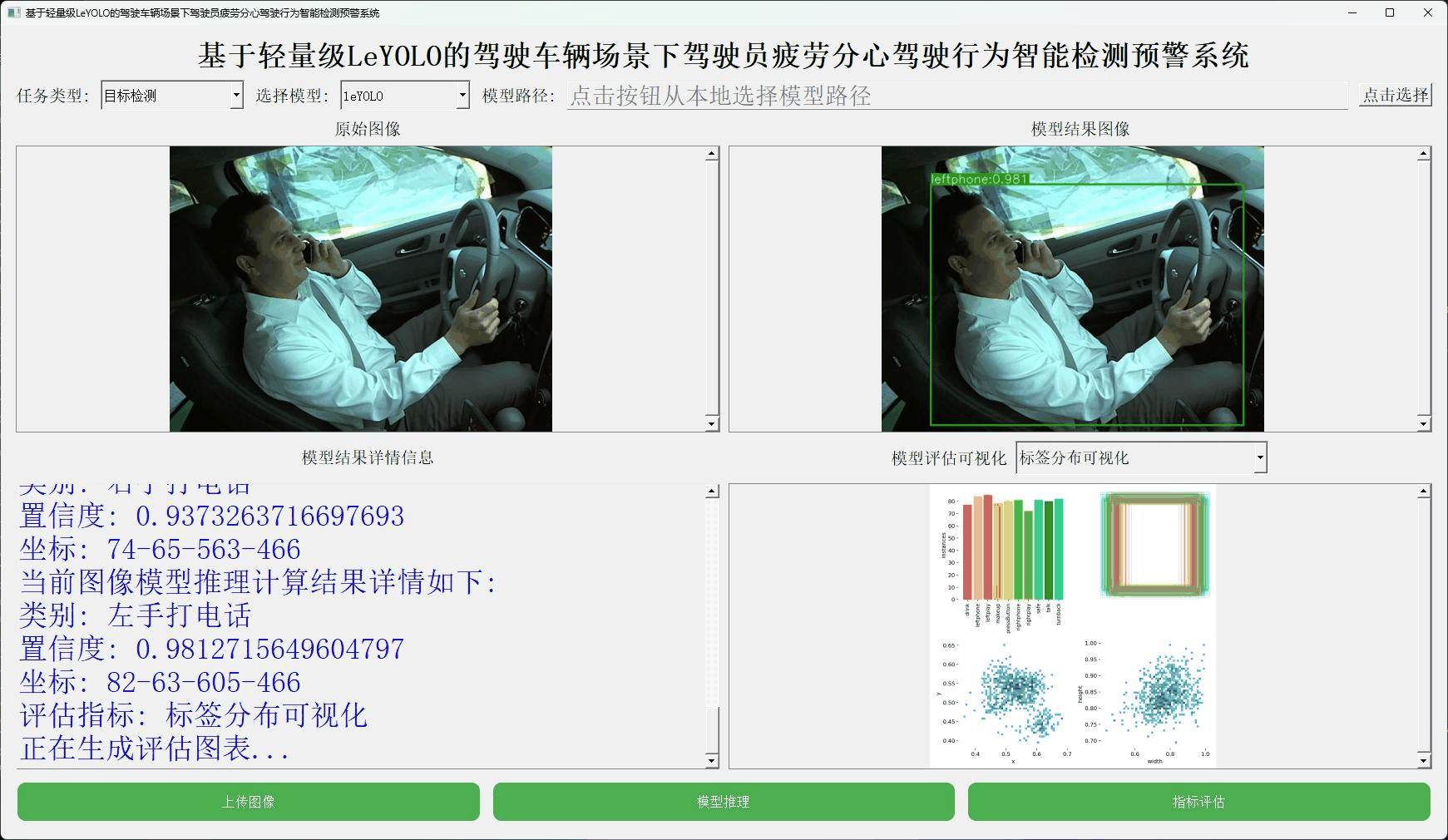
接下来看下实例数据:
深度神经网络中的计算效率对于目标检测至关重要,尤其是在新模型将速度优先于高效计算(FLOP)的情况下。这种演变在某种程度上已经落后于嵌入式和面向移动的AI对象检测应用程序。这里重点讨论了基于FLOP的高效目标检测计算的神经网络结构的设计选择,并提出了几种优化方法来提高基于YLO的模型的效率。
首先,介绍了一种基于反向瓶颈和信息瓶颈原理的有效主干扩展方法。其次,提出了快速金字塔结构网络(FPAN),旨在促进快速多尺度特征共享,同时减少计算资源。最后提出了一个解耦的网络中网络(DNiN)检测头的设计,以提供快速而轻量级的计算分类和回归任务。
在这些优化的基础上,利用更高效的主干,为对象检测和以YOLO为中心的模型(称为LeYOLO)提供了一种新的缩放范例。在各种资源限制下始终优于现有模型,实现了前所未有的准确性和失败率。值得注意的是,LeYOLO Small在COCO val上仅以4.5次失败(G)获得了38.2%的竞争性mAP分数,与最新最先进的YOLOv9微小模型相比,计算量减少了42%,同时实现了类似的精度。我们的新型模型系列实现了以前未达到的浮点精度比,提供了从超低神经网络配置(<1 GFLOP)到高效但要求苛刻的目标检测设置(>4 GFLOP)的可扩展性,对于0.66、1.47、2.53、4.51、5.8和8.4浮点(G),具有25.2、31.3、35.2、38.2、39.3和41 mAP。
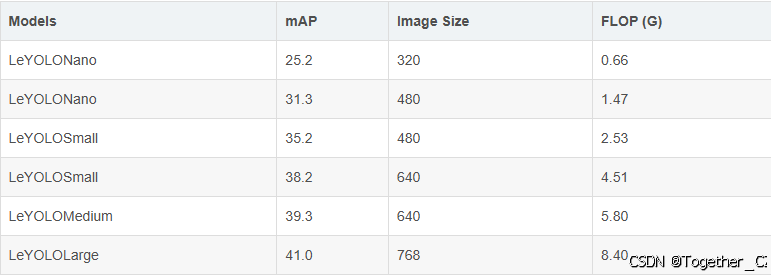
一共提供了n、s、m和l四款不同参数量级的模型。
这里我们保持完全相同的实验参数设置来进行四款模型的开发训练,等待训练完成之后我们来整体进行各项指标的对比分析。
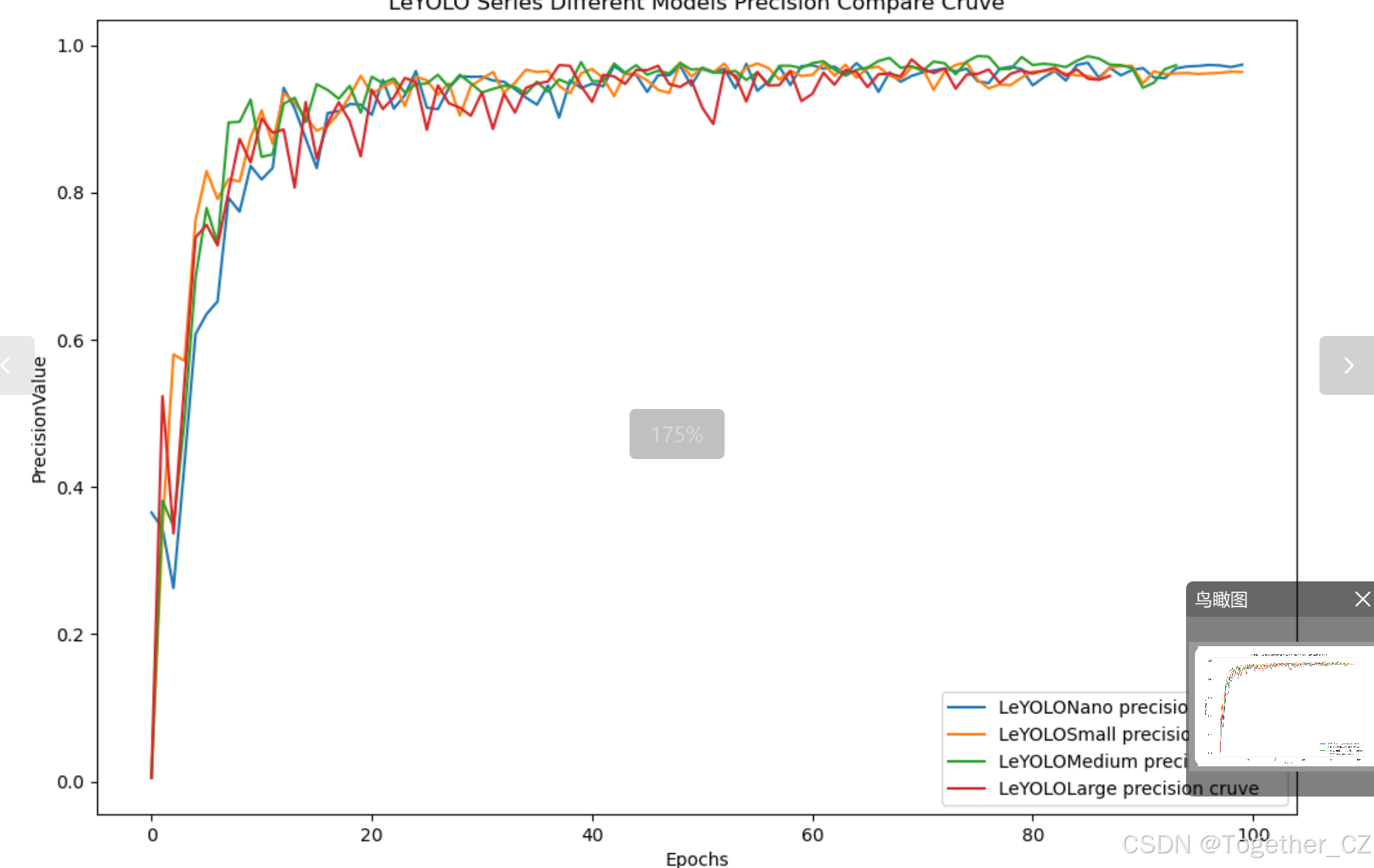
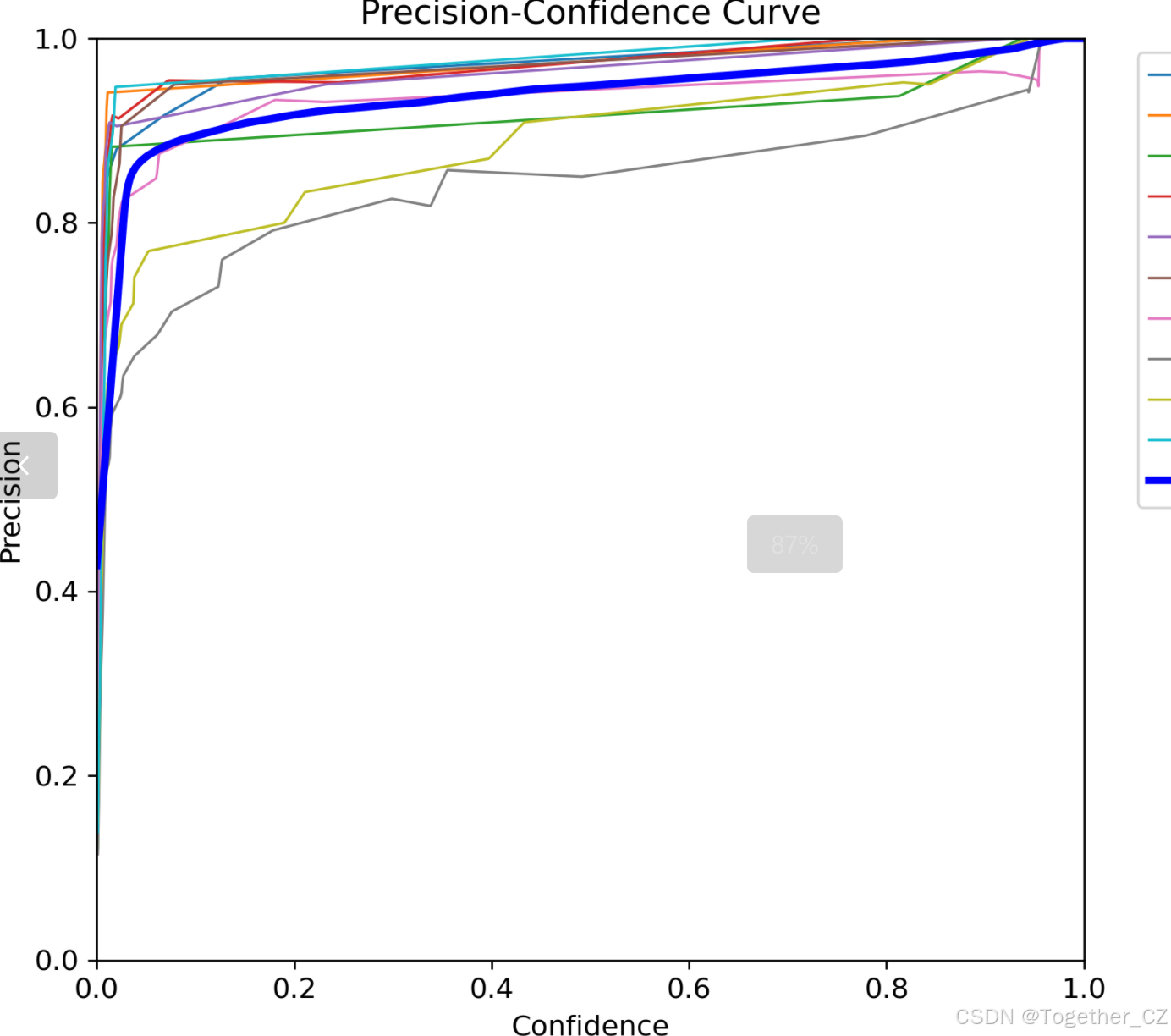
【Precision曲线】
精确率曲线(Precision Curve)是一种用于评估二分类模型在不同阈值下的精确率性能的可视化工具。它通过绘制不同阈值下的精确率和召回率之间的关系图来帮助我们了解模型在不同阈值下的表现。
精确率(Precision)是指被正确预测为正例的样本数占所有预测为正例的样本数的比例。召回率(Recall)是指被正确预测为正例的样本数占所有实际为正例的样本数的比例。
绘制精确率曲线的步骤如下:
使用不同的阈值将预测概率转换为二进制类别标签。通常,当预测概率大于阈值时,样本被分类为正例,否则分类为负例。
对于每个阈值,计算相应的精确率和召回率。
将每个阈值下的精确率和召回率绘制在同一个图表上,形成精确率曲线。
根据精确率曲线的形状和变化趋势,可以选择适当的阈值以达到所需的性能要求。
通过观察精确率曲线,我们可以根据需求确定最佳的阈值,以平衡精确率和召回率。较高的精确率意味着较少的误报,而较高的召回率则表示较少的漏报。根据具体的业务需求和成本权衡,可以在曲线上选择合适的操作点或阈值。
精确率曲线通常与召回率曲线(Recall Curve)一起使用,以提供更全面的分类器性能分析,并帮助评估和比较不同模型的性能。
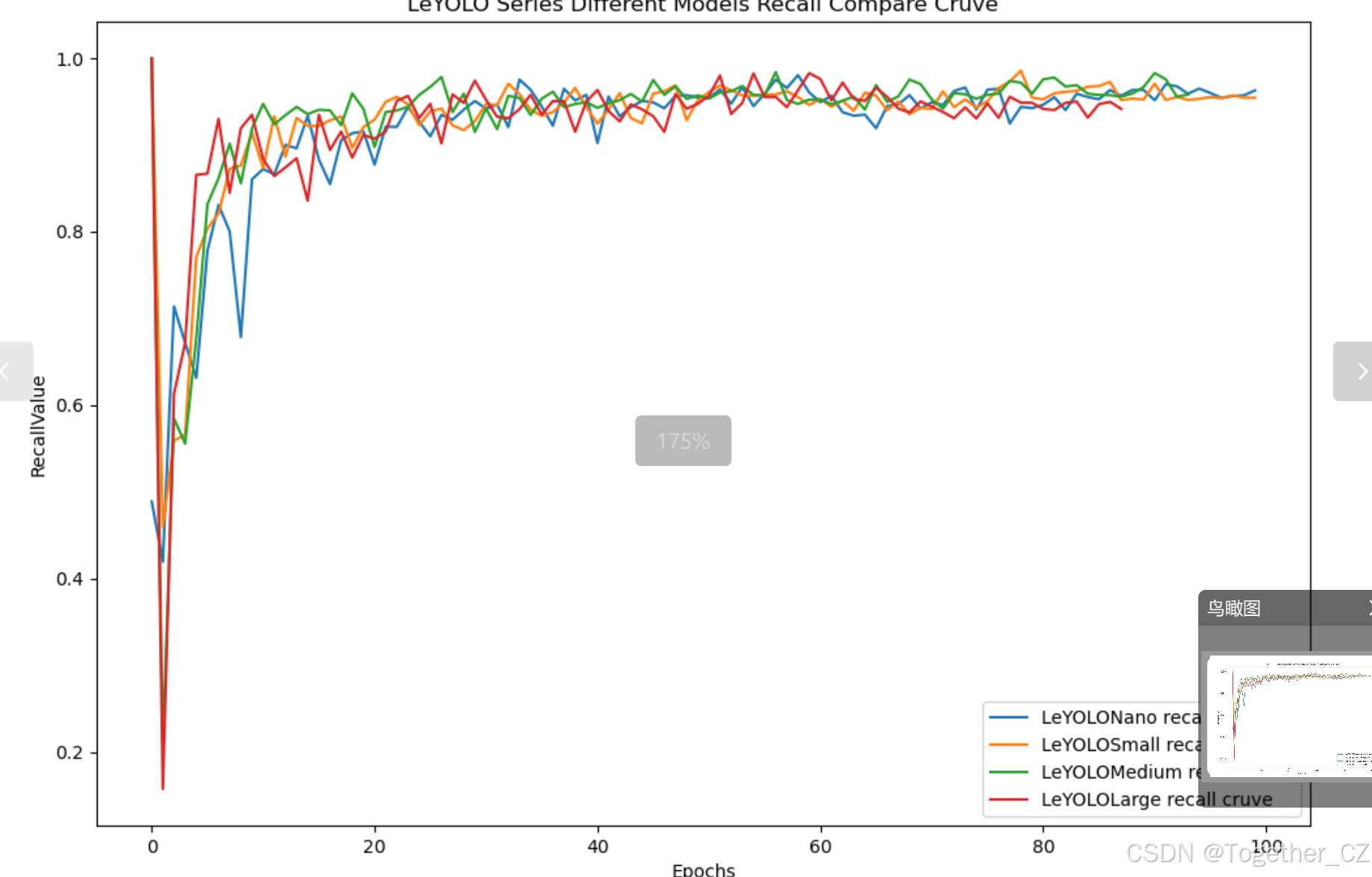
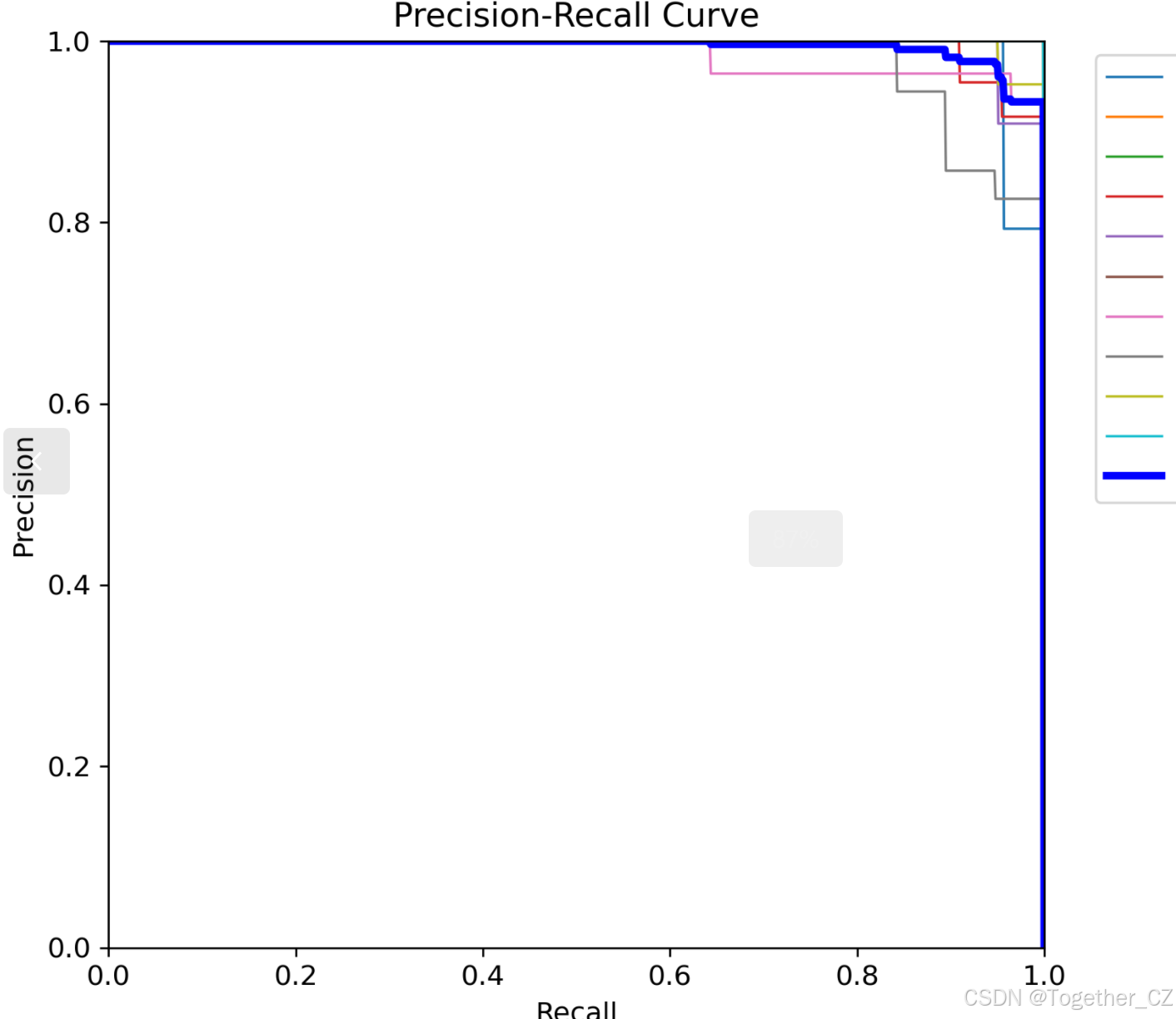
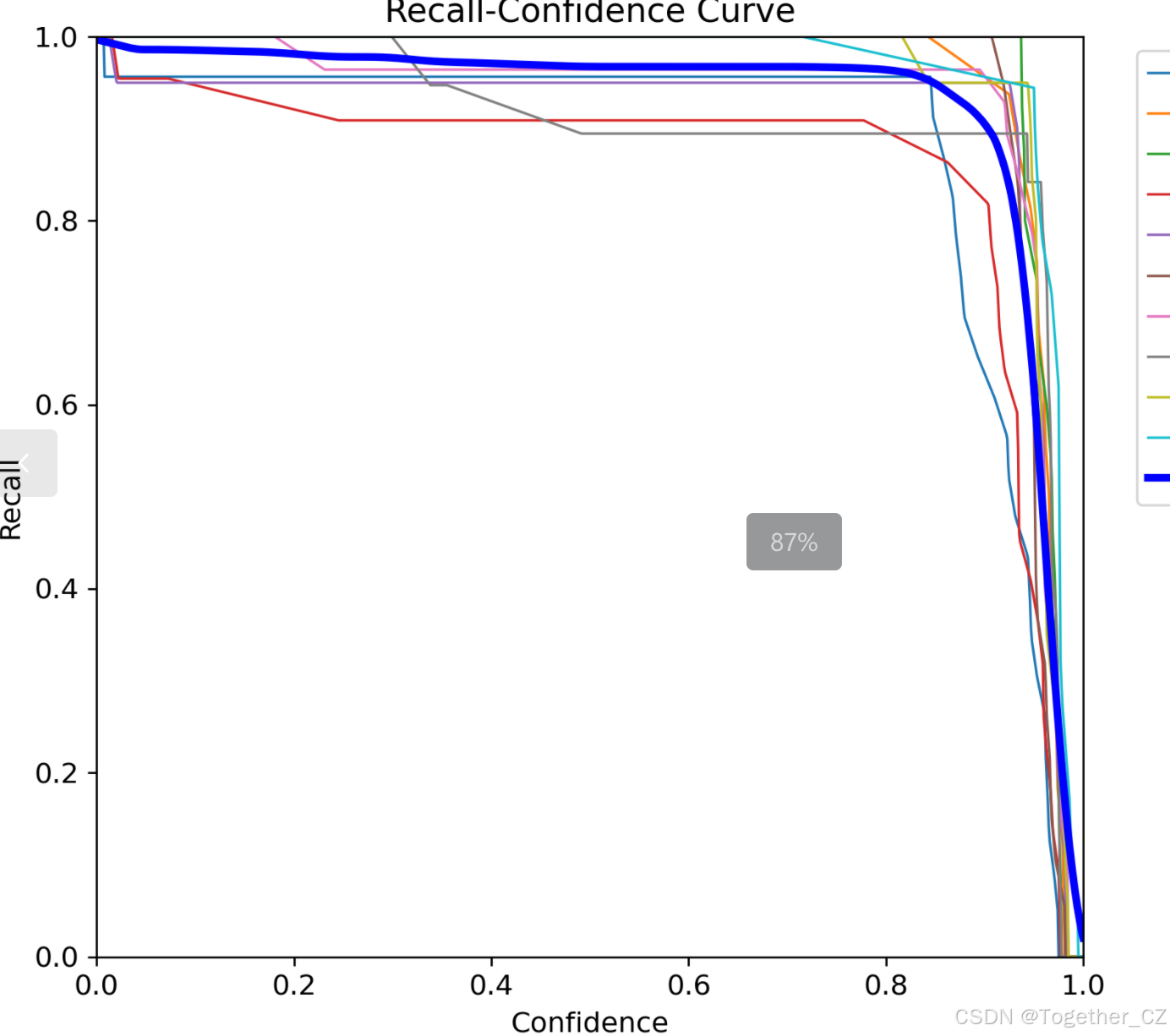
【Recall曲线】
召回率曲线(Recall Curve)是一种用于评估二分类模型在不同阈值下的召回率性能的可视化工具。它通过绘制不同阈值下的召回率和对应的精确率之间的关系图来帮助我们了解模型在不同阈值下的表现。
召回率(Recall)是指被正确预测为正例的样本数占所有实际为正例的样本数的比例。召回率也被称为灵敏度(Sensitivity)或真正例率(True Positive Rate)。
绘制召回率曲线的步骤如下:
使用不同的阈值将预测概率转换为二进制类别标签。通常,当预测概率大于阈值时,样本被分类为正例,否则分类为负例。
对于每个阈值,计算相应的召回率和对应的精确率。
将每个阈值下的召回率和精确率绘制在同一个图表上,形成召回率曲线。
根据召回率曲线的形状和变化趋势,可以选择适当的阈值以达到所需的性能要求。
通过观察召回率曲线,我们可以根据需求确定最佳的阈值,以平衡召回率和精确率。较高的召回率表示较少的漏报,而较高的精确率意味着较少的误报。根据具体的业务需求和成本权衡,可以在曲线上选择合适的操作点或阈值。
召回率曲线通常与精确率曲线(Precision Curve)一起使用,以提供更全面的分类器性能分析,并帮助评估和比较不同模型的性能。
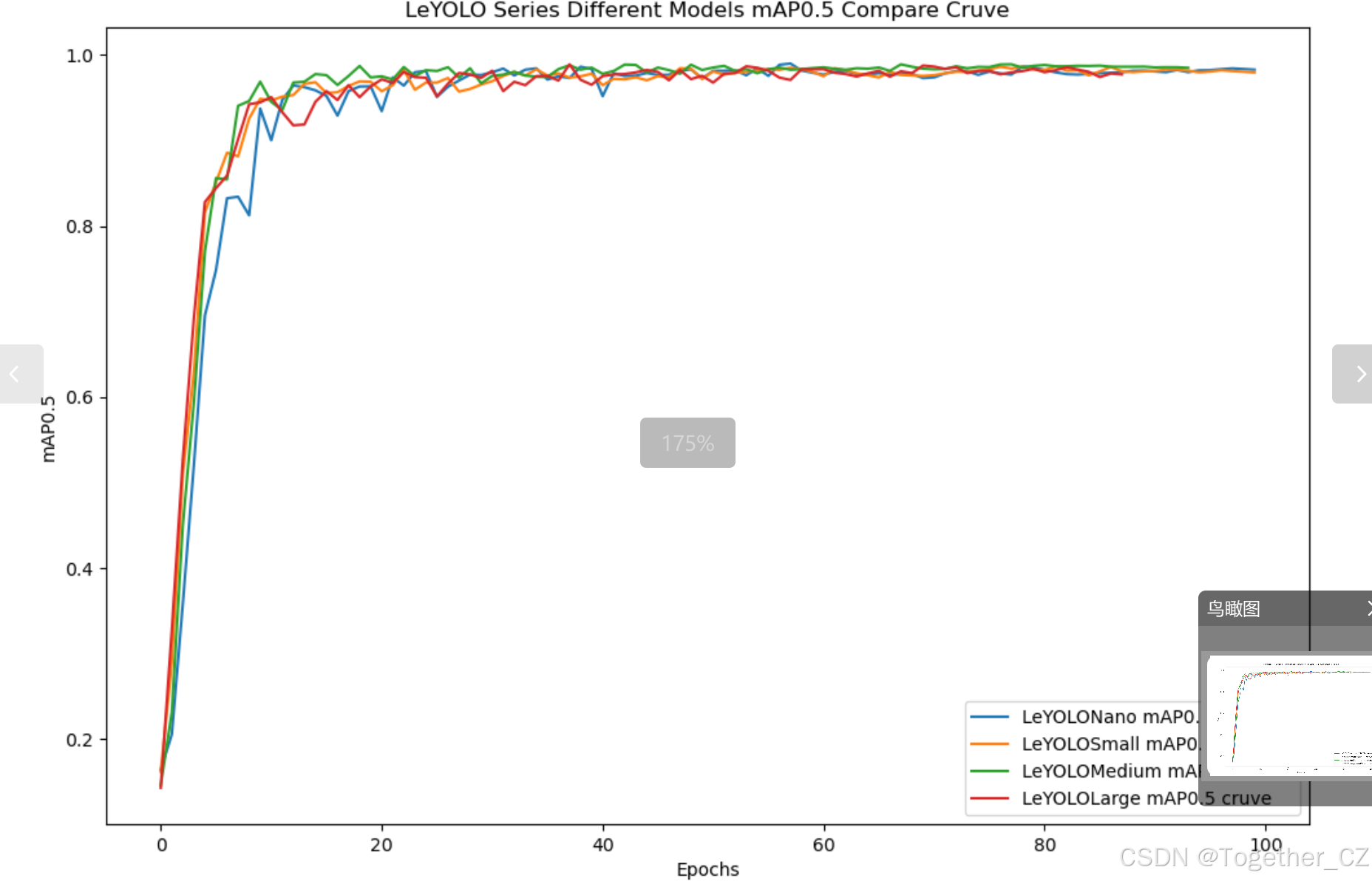
【mAP0.5】
mAP0.5,也被称为mAP@0.5或AP50,指的是当Intersection over Union(IoU)阈值为0.5时的平均精度(mean Average Precision)。IoU是一个用于衡量预测边界框与真实边界框之间重叠程度的指标,其值范围在0到1之间。当IoU值为0.5时,意味着预测框与真实框至少有50%的重叠部分。
在计算mAP0.5时,首先会为每个类别计算所有图片的AP(Average Precision),然后将所有类别的AP值求平均,得到mAP0.5。AP是Precision-Recall Curve曲线下面的面积,这个面积越大,说明AP的值越大,类别的检测精度就越高。
mAP0.5主要关注模型在IoU阈值为0.5时的性能,当mAP0.5的值很高时,说明算法能够准确检测到物体的位置,并且将其与真实标注框的IoU值超过了阈值0.5。
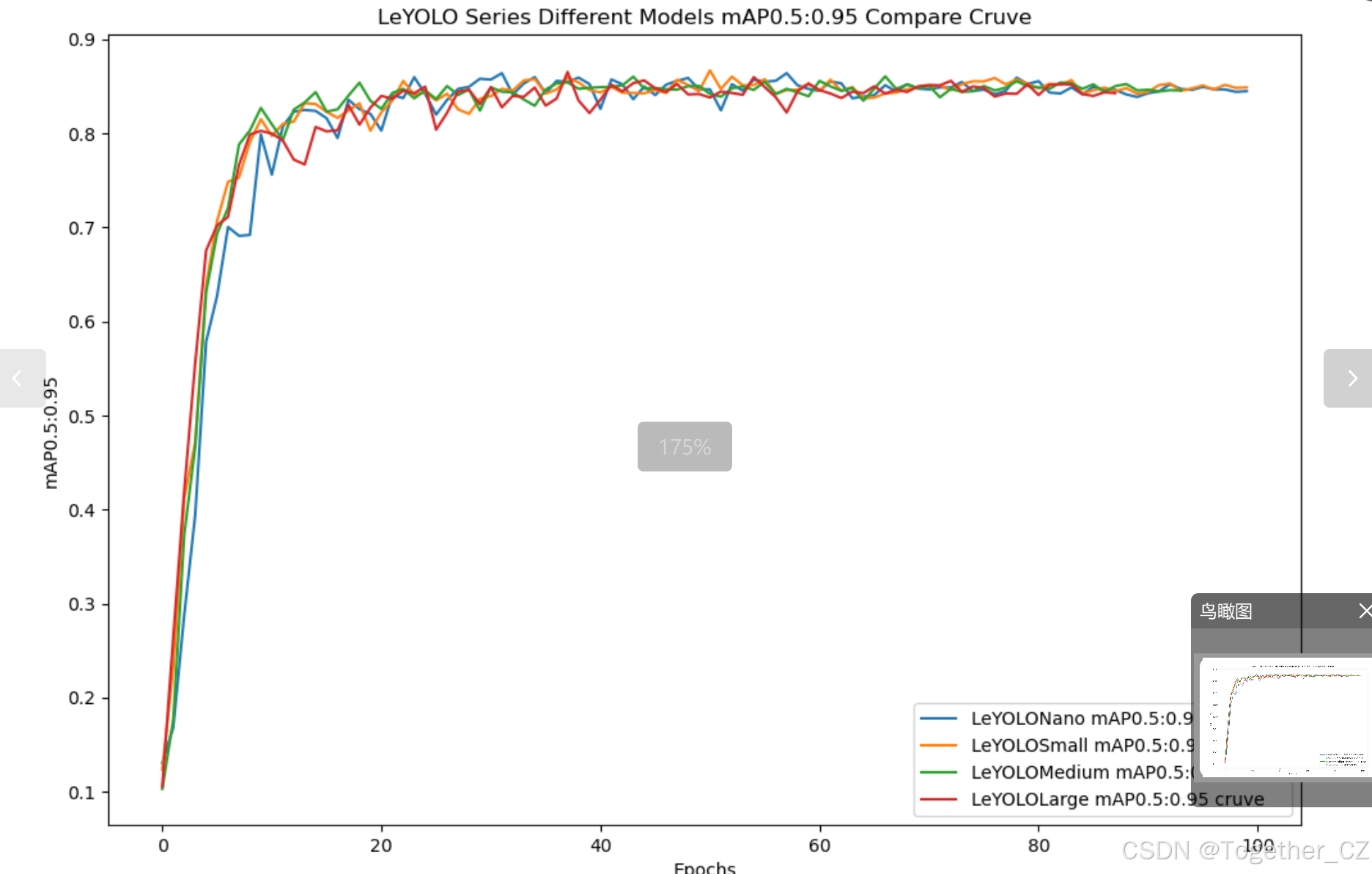
【mAP0.5:0.95】
mAP0.5:0.95,也被称为mAP@[0.5:0.95]或AP@[0.5:0.95],表示在IoU阈值从0.5到0.95变化时,取各个阈值对应的mAP的平均值。具体来说,它会在IoU阈值从0.5开始,以0.05为步长,逐步增加到0.95,并在每个阈值下计算mAP,然后将这些mAP值求平均。
这个指标考虑了多个IoU阈值下的平均精度,从而更全面、更准确地评估模型性能。当mAP0.5:0.95的值很高时,说明算法在不同阈值下的检测结果均非常准确,覆盖面广,可以适应不同的场景和应用需求。
对于一些需求比较高的场合,比如安全监控等领域,需要保证高的准确率和召回率,这时mAP0.5:0.95可能更适合作为模型的评价标准。
综上所述,mAP0.5和mAP0.5:0.95都是用于评估目标检测模型性能的重要指标,但它们的关注点有所不同。mAP0.5主要关注模型在IoU阈值为0.5时的性能,而mAP0.5:0.95则考虑了多个IoU阈值下的平均精度,从而更全面、更准确地评估模型性能。
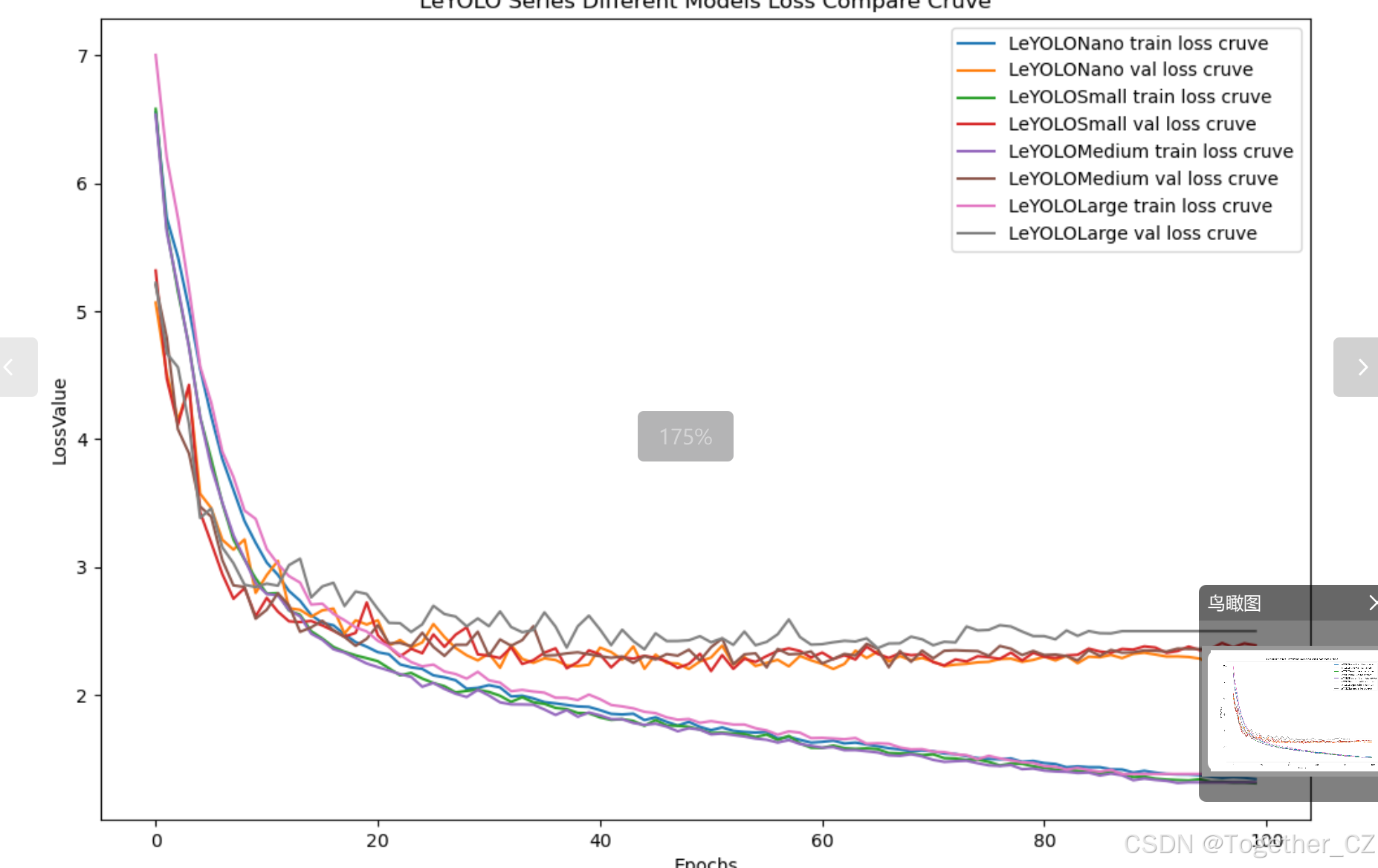
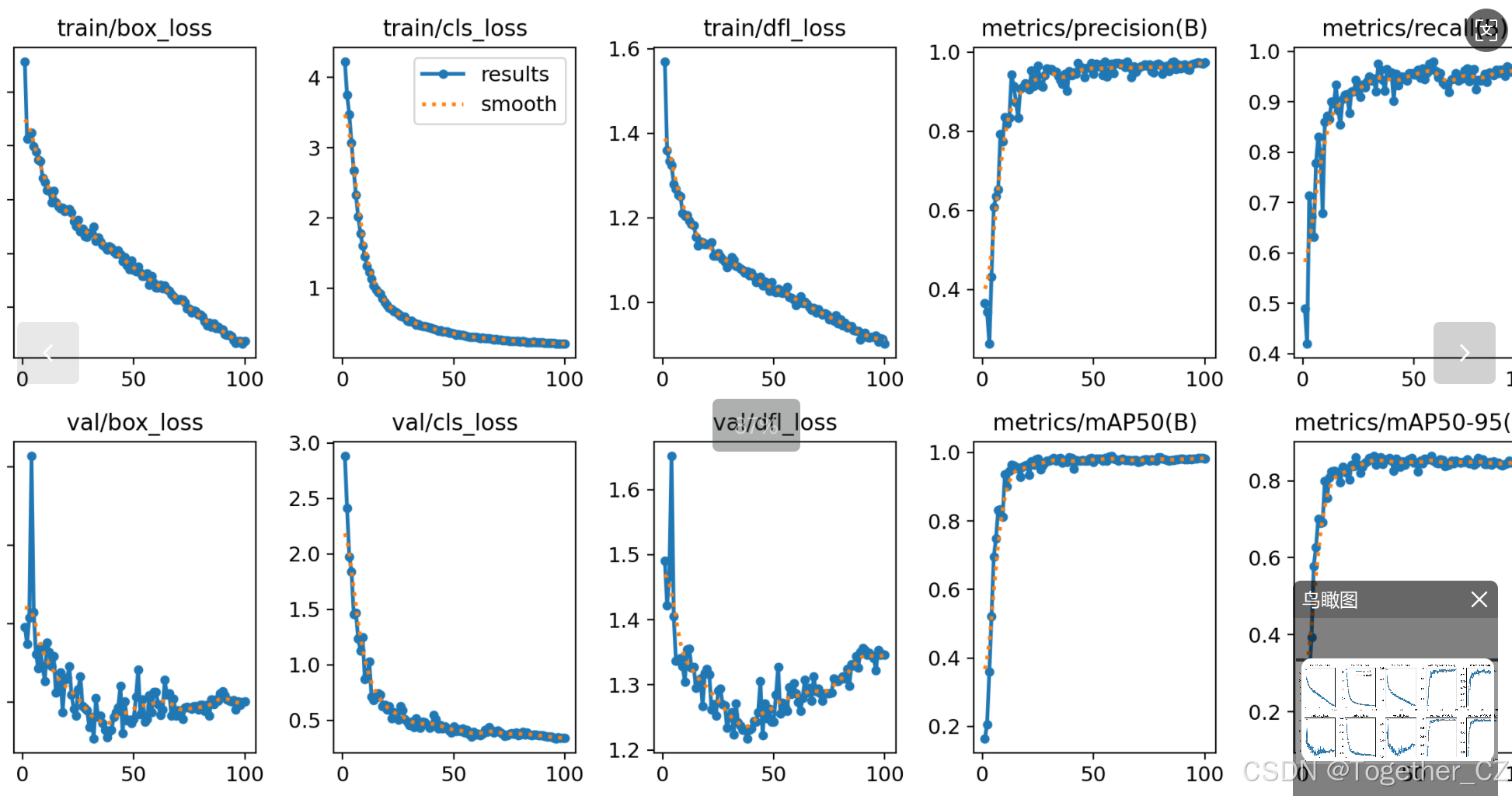
【loss曲线】
在深度学习的训练过程中,loss函数用于衡量模型预测结果与实际标签之间的差异。loss曲线则是通过记录每个epoch(或者迭代步数)的loss值,并将其以图形化的方式展现出来,以便我们更好地理解和分析模型的训练过程。
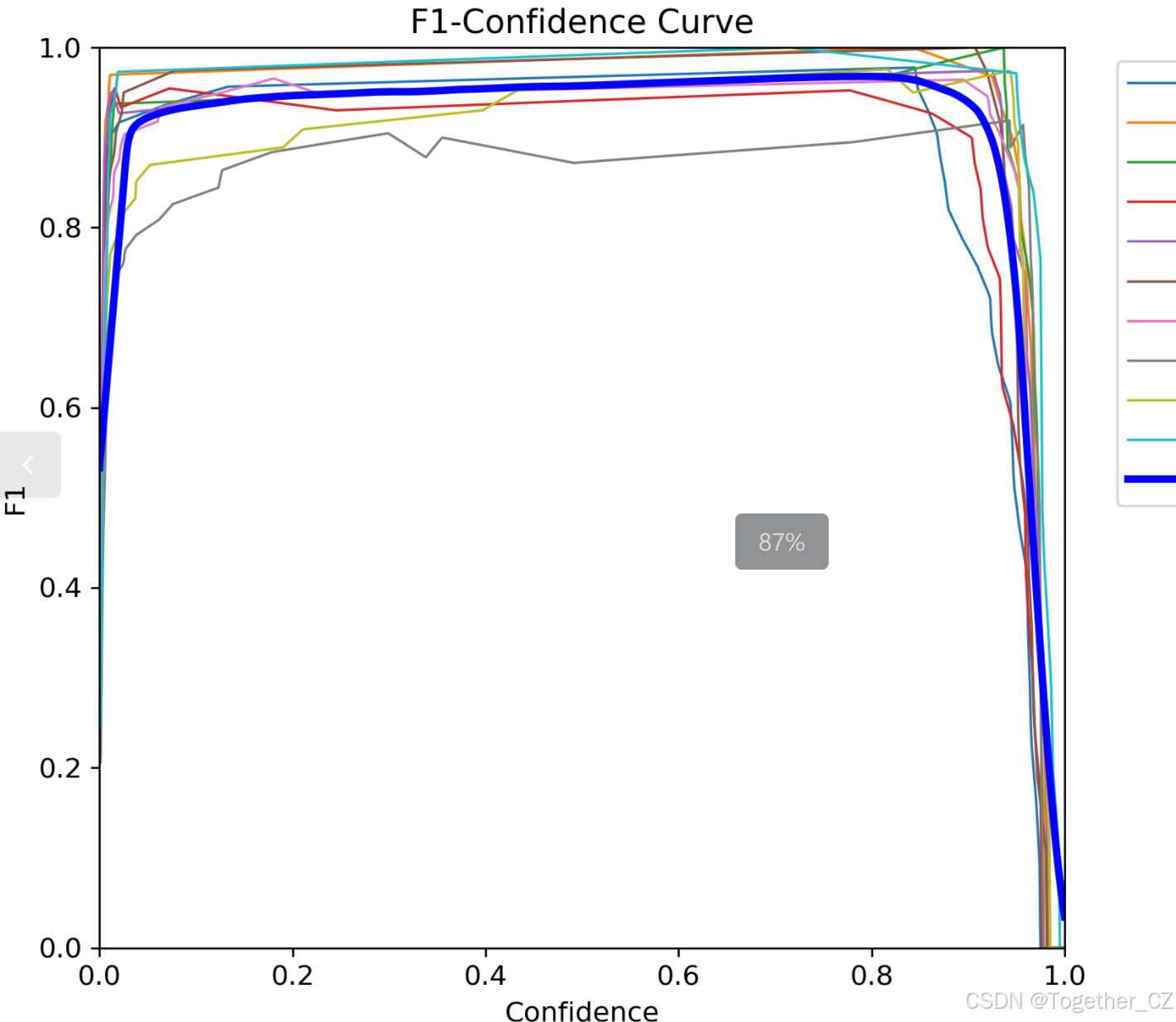
【F1值曲线】
F1值曲线是一种用于评估二分类模型在不同阈值下的性能的可视化工具。它通过绘制不同阈值下的精确率(Precision)、召回率(Recall)和F1分数的关系图来帮助我们理解模型的整体性能。
F1分数是精确率和召回率的调和平均值,它综合考虑了两者的性能指标。F1值曲线可以帮助我们确定在不同精确率和召回率之间找到一个平衡点,以选择最佳的阈值。
绘制F1值曲线的步骤如下:
使用不同的阈值将预测概率转换为二进制类别标签。通常,当预测概率大于阈值时,样本被分类为正例,否则分类为负例。
对于每个阈值,计算相应的精确率、召回率和F1分数。
将每个阈值下的精确率、召回率和F1分数绘制在同一个图表上,形成F1值曲线。
根据F1值曲线的形状和变化趋势,可以选择适当的阈值以达到所需的性能要求。
F1值曲线通常与接收者操作特征曲线(ROC曲线)一起使用,以帮助评估和比较不同模型的性能。它们提供了更全面的分类器性能分析,可以根据具体应用场景来选择合适的模型和阈值设置。
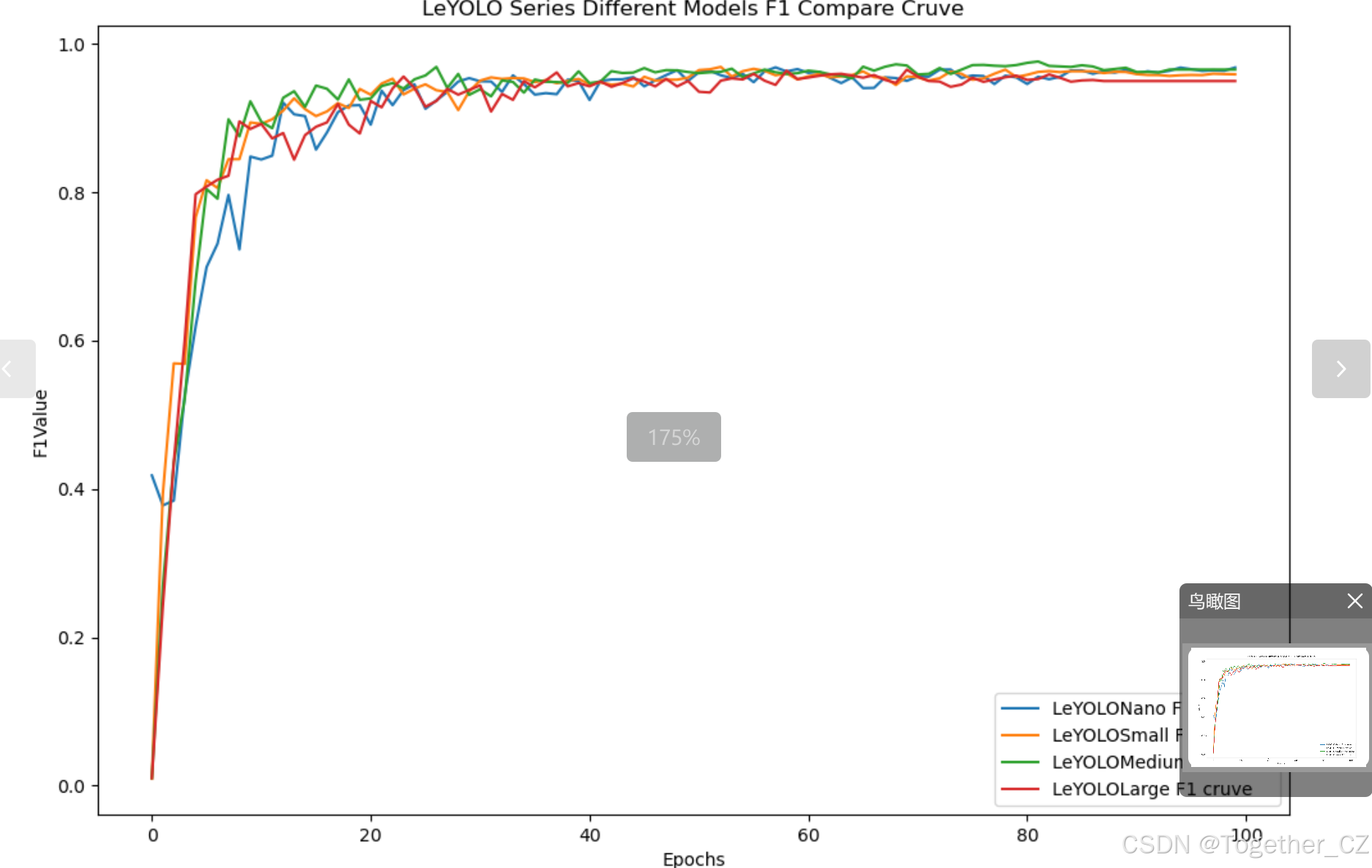
整体对比分析来看:不难发现五款不同参数量级的模型最终达到了较为相似的结果,没有拉开非常大的差距,这里综合参数量考虑我们最终选定了s系列的模型来作为线上的推理计算模型。
接下来看下s系列模型的详细情况。
【离线推理实例】

【Batch实例】

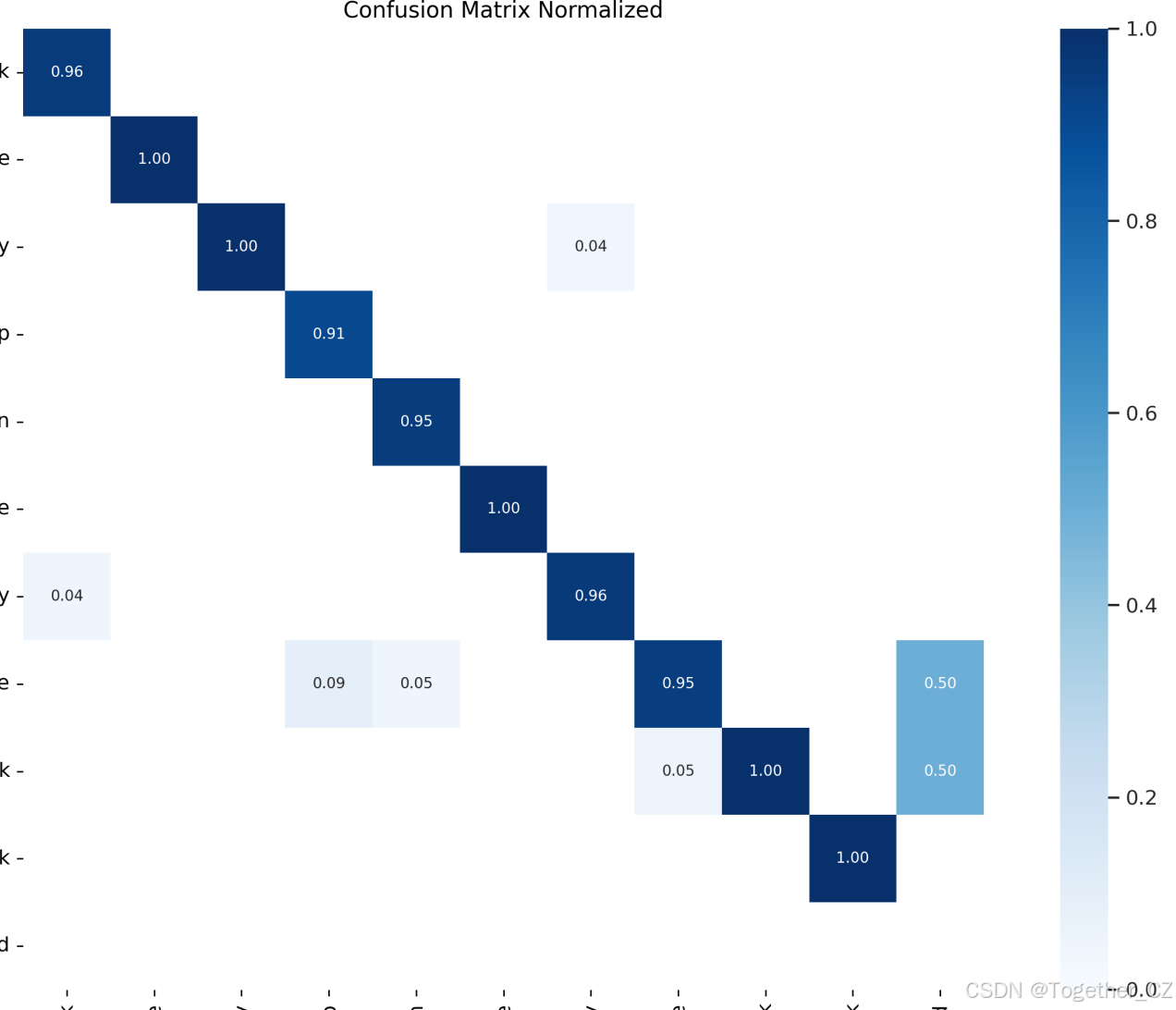
【混淆矩阵】
【F1值曲线】
【Precision曲线】
【PR曲线】
【Recall曲线】
【训练可视化】
人工智能技术在车辆驾驶领域的应用也面临着一些挑战。例如,如何确保预警模型的准确性和可靠性,避免误报或漏报;如何保护司机的隐私,确保摄像头捕捉的画面不被滥用;以及如何让司机更好地接受和信任这些新技术等。但这些问题并不能阻挡人工智能技术在交通安全领域的发展,随着技术的不断进步和完善,这些问题都将逐步得到解决。总之,人工智能技术为交通安全带来了新的希望和机遇。它通过智能化的检测识别预警模型,为司机提供了一道坚实的安全防线。我们有理由相信,在人工智能的助力下,未来的汽车驾驶将更加安全、智能。让我们共同期待这一天的到来,也希望每一位司机都能时刻牢记交通安全,珍爱生命,文明驾驶。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











