转自:http://blog.csdn.net/orlandowww/article/details/53897634?utm_source=itdadao&utm_medium=referral
1、关于aspect level的情感分析
给定一个句子和句子中出现的某个aspect,aspect-level 情感分析的目标是分析出这个句子在给定aspect上的情感倾向。
例如:great food but the service was dreadful! 在aspect “food”上,情感倾向为正,在aspect “service”上情感倾向为负。Aspect level的情感分析相对于document level来说粒度更细。
2、关于attention model
使用传统的神经网络模型能够捕捉背景信息,但是不能明确的区分对某个aspect更重要的上下文信息。为了解决这个问题,引入attention捕获对于判断不同aspect的情感倾向较重要的信息。
3、模型的示意图
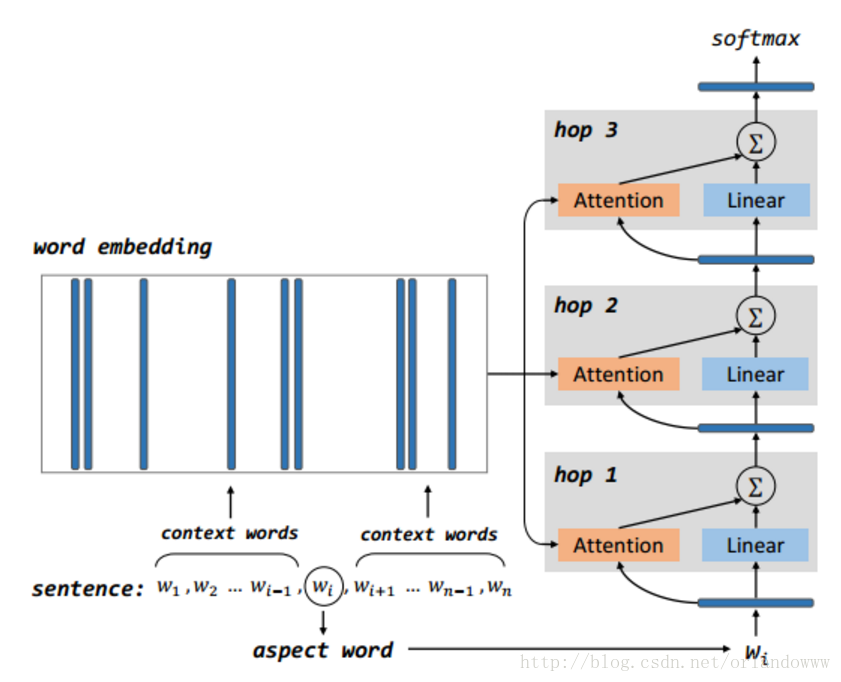
- 模型包括多个computational layers,每个computational layer包括一个attention layer和一个linear layer。
- 第一个computational layer,attention layer的输入是aspect vector,输出memory中的比较重要的部分,linear layer的输入是aspect vector。第一个computational layer的attention layer和linear layer的输出结果求和作为下一个computational layer的输入。
- 其它computational layer执行同样的操作,上一层的输出作为输入,通过attention机制获取memory中较重要的信息,与线性层得到的结果求和作为下一层的输入。
- 最后一层的输出作为结合aspect信息的sentence representation,作为aspect-level情感分类的特征,送到softmax。
4、深度学习框架Keras
Keras是一个高层神经网络库,Keras由纯Python编写而成并基Tensorflow或Theano。Keras 为支持快速实验而生,能够把idea迅速转换为结果。
5、大概流程
读取数据集 –> 分词 –> 将所有词排序并标号 –> 词嵌入 –> Attention Model –> 编译 –> 训练+测试
6、参数设置
- 句子最大长度:80
- 词向量维度:300
- 梯度下降batch:32
- 总迭代次数: 5
实验代码:
import csv
import jieba
jieba.load_userdict('wordDict.txt')
import pandas as pd
from keras.preprocessing import sequence
from keras.utils import np_utils
from keras.models import *
from keras.optimizers import *
from keras.layers.core import *
from keras.layers import Input,merge, TimeDistributed
from keras.layers.core import Dense, Dropout, Activation, Flatten
from keras.layers.embeddings import Embedding
from keras.regularizers import l2
from keras import backend as K
np.random.seed(1337)
def readtrain():
with open('allTrain_includeView.csv', 'rb') as csvfile:
reader = csv.reader(csvfile)
column1 = [row for row in reader]
content_train = [i[1] for i in column1[1:]]
view_train = [i[2] for i in column1[1:]]
opinion_train = [i[3] for i in column1[1:]]
print '训练集有 %s 条句子' % len(content_train)
train = [content_train, view_train, opinion_train]
return train
def changeListCode(b):
a = []
for i in b:
a.append(i.decode('utf8'))
return a
def segmentWord2(cont):
c = []
for i in cont:
a = list(jieba.cut(i))
c.append(a)
return c
def transLabel(labels):
for i in range(len(labels)):
if labels[i] == 'pos':
labels[i] = 2
elif labels[i] == 'neu':
labels[i] = 1
elif labels[i] == 'neg':
labels[i] = 0
else: print "label无效:",labels[i]
return labels
train = readtrain()
content = segmentWord2(train[0])
view = changeListCode(train[1])
opinion = transLabel(train[2])
w = []
for i in content:
w.extend(i)
for i in view:
w.append(i)
def get_aspect(X):
ans = X[:, 0, :]
return ans
def get_context(X):
ans = X[:, 1:, :]
return ans
def get_R(X):
Y, alpha = X[0], X[1]
ans = K.T.batched_dot(Y, alpha)
return ans
maxlen = 81
epochs = 5
batch = 32
emb = 300
print('Preprocessing...')
dict = pd.DataFrame(pd.Series(w).value_counts())
del w
dict['id'] = list(range(1, len(dict) + 1))
get_sent = lambda x: list(dict['id'][x])
sent = pd.Series(content).apply(get_sent)
for i in range(len(content)):
a = dict['id'][view[i]]
sent[i].insert(0,a)
sent = list(sequence.pad_sequences(sent, maxlen=maxlen))
train_content = np.array(sent)
train_opinion = np.array(opinion)
train_opinion1 = np_utils.to_categorical(train_opinion, 3)
print('Build model...')
main_input = Input(shape=(maxlen,), dtype='int32', name='main_input')
x = Embedding(output_dim=emb, input_dim=len(dict)+1, input_length=maxlen, name='x')(main_input)
drop_out = Dropout(0.1, name='dropout')(x)
w_aspect = Lambda(get_aspect, output_shape=(emb,), name="w_aspect")(drop_out)
w_context = Lambda(get_context, output_shape=(maxlen-1,emb), name="w_context")(drop_out)
w_aspect = Dense(emb, W_regularizer=l2(0.01), name="w_aspect_1")(w_aspect)
w_aspects = RepeatVector(maxlen-1, name="w_aspects1")(w_aspect)
merged = merge([w_context, w_aspects], name='merged1', mode='concat')
distributed = TimeDistributed(Dense(1, W_regularizer=l2(0.01), activation='tanh'), name="distributed1")(merged)
flat_alpha = Flatten(name="flat_alpha1")(distributed)
alpha = Dense(maxlen-1, activation='softmax', name="alpha1")(flat_alpha)
w_context_trans = Permute((2, 1), name="w_context_trans1")(w_context)
r_ = merge([w_context_trans, alpha], output_shape=(emb, 1), name="r_1", mode=get_R)
r = Reshape((emb,), name="r1")(r_)
w_aspect_linear = Dense(emb, W_regularizer=l2(0.01), activation='linear')(w_aspect)
merged = merge([r, w_aspect_linear], mode='sum')
w_aspect = Dense(emb, W_regularizer=l2(0.01), name="w_aspect_2")(merged)
w_aspects = RepeatVector(maxlen-1, name="w_aspects2")(w_aspect)
merged = merge([w_context, w_aspects], name='merged2', mode='concat')
distributed = TimeDistributed(Dense(1, W_regularizer=l2(0.01), activation='tanh'), name="distributed2")(merged)
flat_alpha = Flatten(name="flat_alpha2")(distributed)
alpha = Dense(maxlen-1, activation='softmax', name="alpha2")(flat_alpha)
w_context_trans = Permute((2, 1), name="w_context_trans2")(w_context)
r_ = merge([w_context_trans, alpha], output_shape=(emb, 1), name="r_2", mode=get_R)
r = Reshape((emb,), name="r2")(r_)
w_aspect_linear = Dense(emb, W_regularizer=l2(0.01), activation='linear')(w_aspect)
merged = merge([r, w_aspect_linear], mode='sum')
w_aspect = Dense(emb, W_regularizer=l2(0.01), name="w_aspect_3")(merged)
w_aspects = RepeatVector(maxlen-1, name="w_aspects3")(w_aspect)
merged = merge([w_context, w_aspects], name='merged3', mode='concat')
distributed = TimeDistributed(Dense(1, W_regularizer=l2(0.01), activation='tanh'), name="distributed3")(merged)
flat_alpha = Flatten(name="flat_alpha3")(distributed)
alpha = Dense(maxlen-1, activation='softmax', name="alpha3")(flat_alpha)
w_context_trans = Permute((2, 1), name="w_context_trans3")(w_context)
r_ = merge([w_context_trans, alpha], output_shape=(emb, 1), name="r_3", mode=get_R)
r = Reshape((emb,), name="r3")(r_)
w_aspect_linear = Dense(emb, W_regularizer=l2(0.01), activation='linear')(w_aspect)
merged = merge([r, w_aspect_linear], mode='sum')
h_ = Activation('tanh')(merged)
out = Dense(3, activation='softmax')(h_)
output = out
model = Model(input=[main_input], output=output)
model.compile(loss='categorical_crossentropy',
optimizer=adam(),
metrics=['accuracy'])
print('Train...')
model.fit(train_content, train_opinion1,
batch_size=batch, nb_epoch=epochs,
validation_split=0.1)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
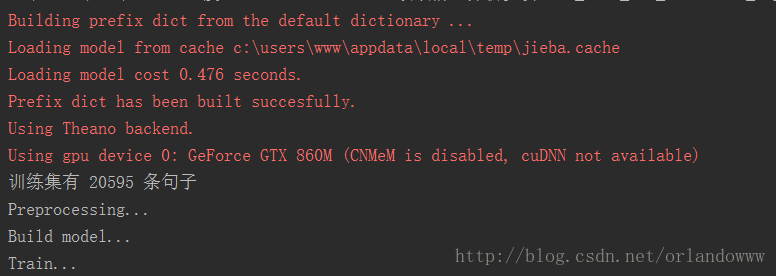
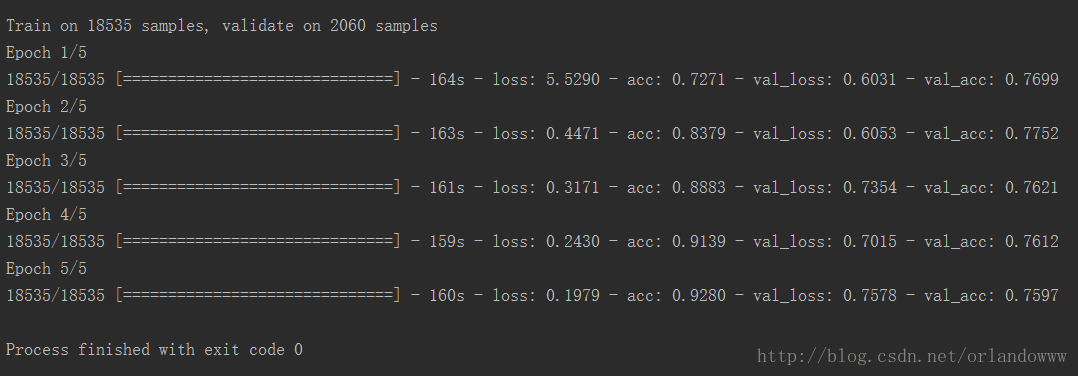
实验输出:
注:
通过实验,发现单独使用CNN、 LSTM、fasttext做文本情感分析的效果不如引入Attention的Model效果好,可见如今Attention如此火爆也是有原因的。
























 3174
3174











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









