




说在前面
最近遇到了这样一个场景,需要将很多的txt文件转成pdf文件,一个一个手动转换不仅累、效率还不高,于是便写了这么一个插件来解放自己,可以一键批量进行自动转换~
功能说明
这个插件的核心目标是「降低 txt 转 pdf 的操作成本」,支持单文件转换和多文件批量转换。
1. 单文件转换
针对「偶尔需要转换单个 txt 文件」的场景,支持手动选择指定的.txt文件,自定义输出PDF的保存目录。转换后的PDF会自动添加标题、段落缩进、页眉(文件名)和页脚(页码),排版符合中文阅读习惯,无需后续手动调整格式。
2. 多文件批量转换
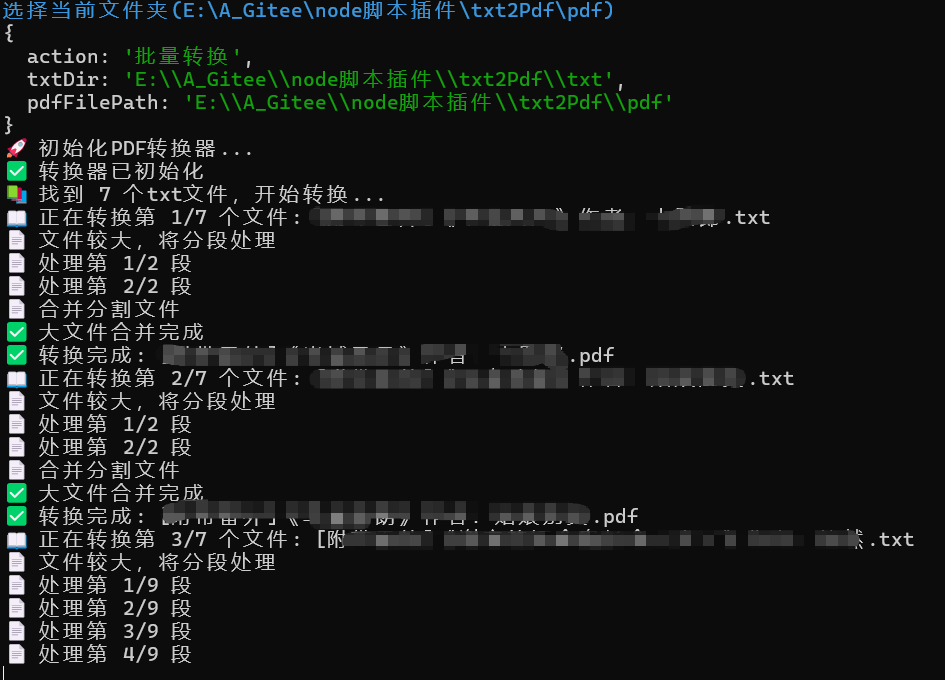
针对「大量txt文件需要统一处理」的场景,只需选择存放txt文件的目录,插件会自动扫描目录下所有.txt文件(忽略其他格式),按文件名顺序批量转换,并将所有PDF输出到指定目录。
功能实现
1. 命令行交互:获取用户配置
通过命令行获取关键信息:是转换单个文件还是批量转换?文件/目录在哪里?PDF要存到哪里?这里用到了@jyeontu/j-inquirer(基于inquirer的增强库),支持可视化选择文件和目录,比手动输入路径更直观。
实现逻辑分为两步:
- 第一步:选择转换模式
弹出选项列表,让用户选择「单文件转换」或「批量转换」,不同模式对应不同的后续交互——单文件需要选具体的.txt文件,批量转换需要选存放txt的目录。

- 第二步:获取路径信息
根据选择的模式,动态生成路径选择项:单文件模式显示「文件选择器」,批量模式显示「目录选择器」,最后统一让用户选择PDF的输出目录。
关键代码片段(简化版):
const getConfig = async () => {
// 选择转换模式
const actionType = await new inquirer([
{ type: "list", name: "action", message: "请选择操作", choices: ["单文件转换", "批量转换"] }
]).prompt();
// 动态生成路径选择项
const options = [];
if (actionType.action === "单文件转换") {
options.push({
type: "file", name: "txtFilePath", message: "选择txt文件", dirname: process.cwd(), pathType: "absolute"
});
} else {
options.push({
type: "folder", name: "txtDir", message: "选择txt目录", dirname: process.cwd(), pathType: "absolute"
});
}
// 统一选择PDF输出目录
options.push({
type: "folder", name: "pdfFilePath", message: "选择PDF输出目录", dirname: process.cwd(), pathType: "absolute"
});
const answers = await new inquirer(options).prompt();
return { ...actionType, ...answers };
};
交互效果类似这样:
? 请选择操作: 批量转换
? 选择txt目录: E:\文档\txt文件
? 选择PDF输出目录: E:\文档\PDF文件
用户只需通过键盘上下键和回车键,就能完成所有配置,无需记忆复杂命令。
2. 文件转换:txt转pdf的核心逻辑
txt转pdf的核心挑战是「保留排版样式」——直接将文本内容写入PDF会导致格式混乱(比如没有段落、没有缩进),因此采用「HTML中间层」方案:先将txt内容转换为带样式的HTML,再用html-pdf-node将HTML渲染为PDF。
整个转换流程分为3步:
- 第一步:读取txt内容
用fs-extra的readFile方法异步读取txt文件,同时指定编码为utf-8,确保中文内容不会乱码。
const content = await fs.readFile(txtFilePath, 'utf-8');
- 第二步:生成带样式的HTML
将txt中的换行符拆分为段落,过滤空行,添加中文排版样式(首行缩进2字符、行高1.8、字体为微软雅黑),同时加入标题、页眉页脚占位符。
比如将txt中的"第一部分:项目概述\n\n这是项目的基本介绍。"转换为:
<div class="title">项目概述</div>
<p style="text-indent:2em;">第一部分:项目概述</p>
<p style="text-indent:2em;">这是项目的基本介绍。</p>
- 第三步:HTML渲染为PDF
用html-pdf-node加载HTML文件(先创建临时HTML文件,避免内存溢出),配置PDF参数:A4格式、2cm边距、显示页眉页脚,最后将渲染后的PDF缓冲区写入指定路径。
关键代码片段(简化版):
async convertSmallFile(content, fileName, pdfFilePath) {
// 生成HTML
const htmlContent = this.generateHTML(content, fileName);
const tempHtmlPath = path.join(__dirname, "temp.html");
await fs.writeFile(tempHtmlPath, htmlContent);
try {
// 配置PDF选项
const options = {
format: "A4",
margin: { top: "2cm", right: "2cm", bottom: "2cm", left: "2cm" },
headerTemplate: `<div style="text-align:center; color:#666;">${fileName}</div>`,
footerTemplate: `<div style="text-align:center; color:#666;">第 <span class="pageNumber"></span> 页</div>`
};
// 渲染PDF
const buffer = await htmlpdf.generatepdf({ url: `file://${tempHtmlPath}` }, options);
await fs.writeFile(pdfFilePath, buffer);
} finally {
// 清理临时文件
await fs.remove(tempHtmlPath);
}
}
3. 大文件分割:避免内存溢出
如果遇到几千页的大文件(比如中长篇小说),直接转换会导致Node.js内存溢出(默认单进程内存限制较低)。因此需要添加「大文件分段处理」逻辑:当txt文件字符数超过50万时,自动拆分为多个片段,每个片段生成独立的「部分PDF」,最后合并为单个文件。
- 第一步:按换行符拆分文本
将txt内容按\n拆分为行数组,确保每个片段的末尾都是完整的行。 - 第二步:控制片段大小
循环将行添加到当前片段,当当前片段字符数接近30万(阈值)时,保存当前片段并开始新片段。 - 第三步:生成片段PDF
每个片段生成对应的PDF(文件名带_part1、_part2后缀),同时记录片段路径,为后续合并做准备。
关键代码片段(简化版):
splitContent(content, maxLength) {
const segments = [];
const lines = content.split("\n");
let currentSegment = "";
for (const line of lines) {
if ((currentSegment + line + "\n").length > maxLength && currentSegment) {
segments.push(currentSegment.trim());
currentSegment = line + "\n";
} else {
currentSegment += line + "\n";
}
}
if (currentSegment.trim()) segments.push(currentSegment.trim());
return segments;
}
4. 文件合并:将分段PDF整合成一个
分段生成的「部分PDF」需要合并为单个文件,才符合用户的使用习惯。这里用到了pdf-lib(轻量级PDF处理库),支持加载、复制、合并PDF页面,且兼容性良好。
合并逻辑分为3步:
- 第一步:检查是否存在已生成的片段
先判断所有「部分PDF」是否已存在(比如上次转换到一半中断了),如果全部存在,直接合并无需重新生成,实现「断点续转」。 - 第二步:复制PDF页面
创建一个空的PDF文档,循环加载每个「部分PDF」,复制其中的所有页面到空文档中。 - 第三步:保存合并后的PDF
将合并后的PDF写入最终路径,同时删除所有「部分PDF」,避免冗余文件残留。
关键代码片段(简化版):
async mergeExistingParts(partFiles, outputPath) {
const mergedpdf = await PDFLib.PDFDocument.create();
for (const partFile of partFiles) {
const partBuffer = await fs.readFile(partFile);
const partpdf = await PDFLib.PDFDocument.load(partBuffer);
// 复制页面到合并文档
const copiedPages = await mergedpdf.copyPages(partpdf, partpdf.getPageIndices());
copiedPages.forEach(page => mergedpdf.addPage(page));
}
// 保存合并结果
const mergedBytes = await mergedpdf.save();
await fs.writeFile(outputPath, mergedBytes);
// 清理部分文件
partFiles.forEach(file => fs.remove(file));
}
工具使用
目前该工具已经打包发布到npm上,可以直接使用命令安装。
安装
npm install -g jyeontu
目前该工具中集成了很多实用的功能,具体可以输入命令jyeontu -h查看。

使用
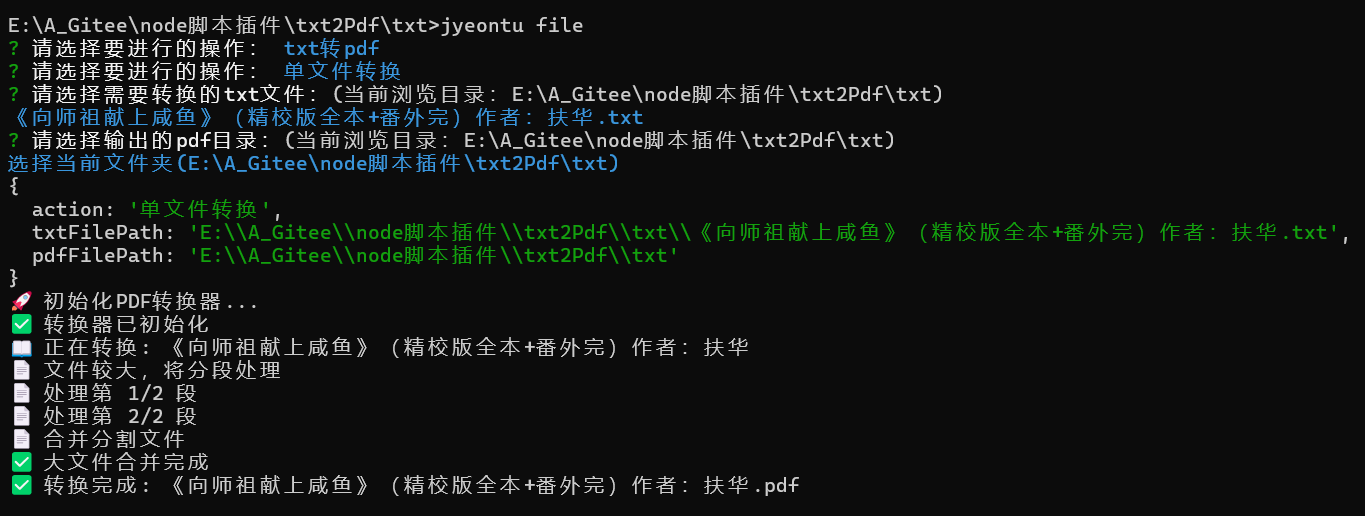
需要使用 txt转pdf功能可以按以下步骤操作。
jyeontu file

选择txt转pdf

后续根据提示进行操作即可~
源码地址
这个工具的完整源码已开源,支持直接克隆使用,也欢迎大家提Issue或PR改进功能~
Gitee
https://gitee.com/zheng_yongtao/jyeontu-cli.git
GitHub
https://github.com/yongtaozheng/jyeontu-cli.git
- 🌟 觉得有帮助的可以点个 star~ 你的支持是我持续优化的动力~
- 🖊 发现bug或有优化建议?欢迎在Issue中指出,也可以直接提PR,一起完善工具~
- 📬 有新的功能想法?可以通过仓库Issue或公众号联系我~
公众号
关注公众号『 前端也能这么有趣 』,获取更多有趣内容~
发送 加群 还能加入前端交流群,和大家一起讨论技术、分享经验,偶尔也能摸鱼聊天~
说在后面
🎉 这里是 JYeontu,现在是一名前端工程师,有空会刷刷算法题,平时喜欢打羽毛球 🏸 ,平时也喜欢写些东西,既为自己记录 📋,也希望可以对大家有那么一丢丢的帮助,写的不好望多多谅解 🙇,写错的地方望指出,定会认真改进 😊,偶尔也会在自己的公众号『前端也能这么有趣』发一些比较有趣的文章,有兴趣的也可以关注下。在此谢谢大家的支持,我们下文再见 🙌。


















 2144
2144

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











