









在之前的练习 “开始使用Elasticsearch (2)”,我们描述了如何使用 match_phrase 来搜索结果,并保证每个词的顺序是一样的。在今天的文章中,我们来讲一下 match_phrase_prefix。这个在一些自动补全的搜索中还是蛮有用的。使用它进行搜索,它返回的结果包含所提供文字的顺序,并严格按照所给的顺序。 提供的文本的最后一个词被视为 prefix,与该词开头的任何单词匹配。比如,我们在 google 网站进行搜索:
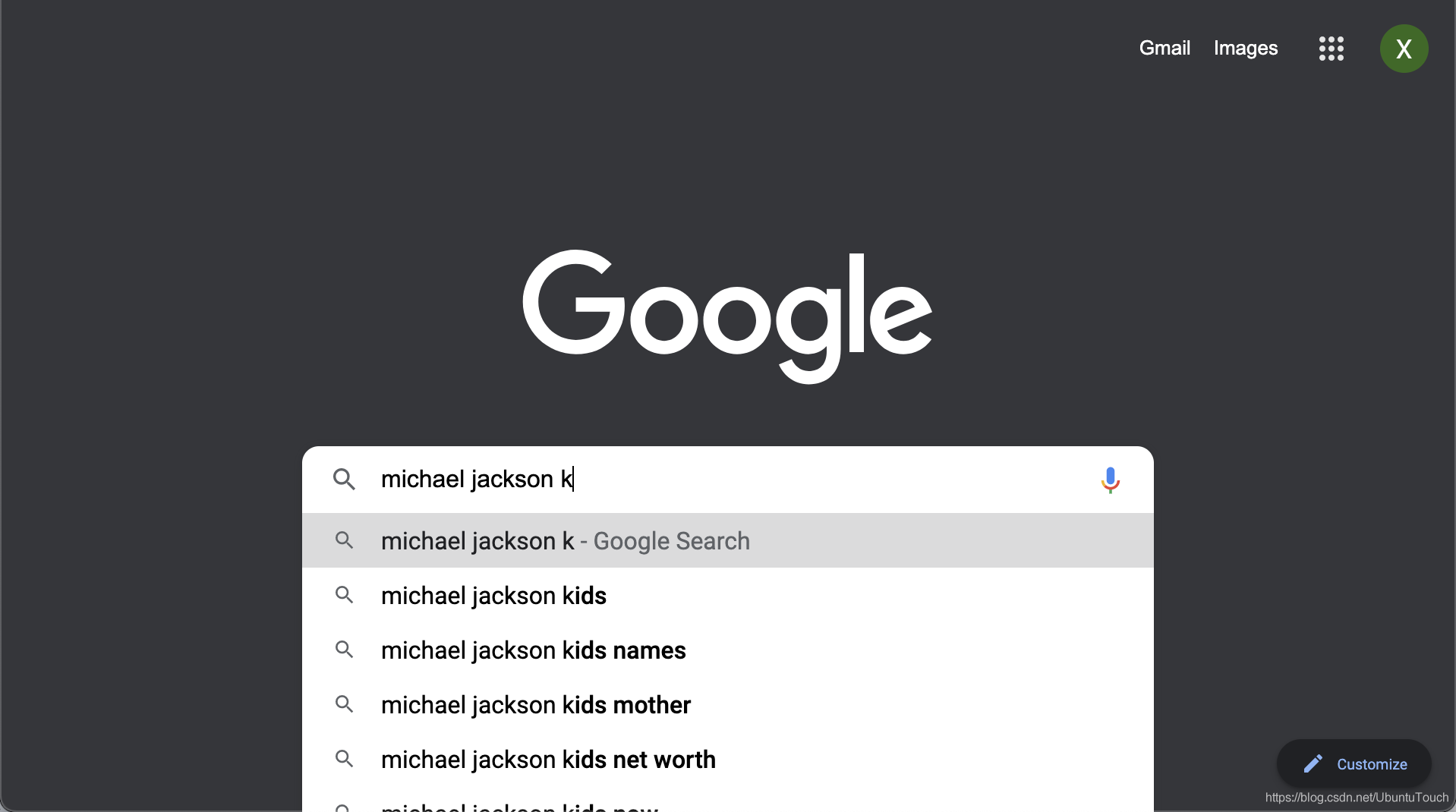
如上图所示,我们首先匹配的单词是 michael, jackson, 以及任何以 k 字母为开头的文档,并且这三者是严格按照这个顺序进行匹配的。
例子
我们首先来创建如下的几个文档:
PUT my_index/_doc/1
{
"content": "quick brown fox"
}
PUT my_index/_doc/2
{
"content": "two quick brown ferrets"
}
PUT my_index/_doc/3
{
"content": "fox is quick and brown"
}我们可以进行如下的搜索:
GET my_index/_search
{
"query": {
"match_phrase_prefix": {
"content": {
"query": "quick brown f",
"slop": 2
}
}
}
}在上面,我们针对 content 字段进行搜索。但凡文档里含有, quick, brown 以及以 f 字母为开头的单词的文档,并且必须是 quick 出现在 brown 的前面,brown 必须出现在 f 为前缀的单词的前面。这个次序不能搞错。另外,我们定义了 slop 为2, 也就是在 quick 和 brown 单词之间可以允许有最多两个单词,比如:
quick is the brown and that function在上面,在 quick 和 brown 之间多出来两个单词 is the,即使是这样的,也会匹配。同样 brown 和 function 之间也有多两个单词 and that,这种情况也是可以进行匹配的。
针对上面的匹配,我们可以看出来:文档 1 和 2 是可以被查询到的,但是第三个文档,虽然它也含有 fox,但是 fox 的位置出现在 quick 之前,这个显然是不可以匹配的。
查询的结果是:
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 1.9136053,
"hits" : [
{
"_index" : "my_index",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.9136053,
"_source" : {
"content" : "quick brown fox"
}
},
{
"_index" : "my_index",
"_type" : "_doc",
"_id" : "2",
"_score" : 1.7178955,
"_source" : {
"content" : "two quick brown ferrets"
}
}
]
}
}














 1386
1386











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









