







算法学习
算法入门内容
排序、动态规划、回溯、图等可以说是必须掌握的基础算法知识了,但发现自己掌握的还很差,知识不成体系,记忆不牢固,理解不深入,所以再来一次梳理,按排序、图、回溯(最小冲突、遗传)、动态规划的顺序依次学习并实现。
主要参考《算法导论》(Introduction of Algorithm[Third Edition])和维基百科。
目录
其中排序是10000~100000个随机数的排序,图算法大多以Romania Problem为例,回溯法用来解决了一个著名八皇后问题,这里当作CSP问题来处理就同时使用了Min-Conflicts和Genetic Algorithm(GA),动态规划解决TSP旅行商问题。
排序
排序算法有无数种,这里实现九种经典排序。
首先是三个最简单的冒泡、插入、选择,然后是归并、快排,之后是计数排序、基数排序、希尔排序,最后是堆排序。另外,这里写的排序算法全部都是Bottom-up迭代的,之后写单独的Top-down递归算法,用以学习递归策略。
#include <iostream>
#include <cstdlib>
#include <ctime>
#include <algorithm>
#define TEST 10
#define ARRAY 100000
using namespace std;
template<typename T>
void output(T arr[], int n) {
for (int i = 0; i < n; i++)
cout << arr[i] << " ";
}
template<typename T>//https://zh.wikipedia.org/wiki/%E5%86%92%E6%B3%A1%E6%8E%92%E5%BA%8F
void bubble(T raw[], int n) {//two adjacent elements
for (int i = 0; i < n - 1; i++)
for (int j = 0; j < n - i - 1; j++)
if (raw[j] > raw[j + 1])
swap(raw[j], raw[j + 1]);
}
template<typename T>//https://zh.wikipedia.org/wiki/%E9%80%89%E6%8B%A9%E6%8E%92%E5%BA%8F
void selection(T raw[], int n) {//find the minimal one every round
for (int i = 0; i < n - 1; i++) {
int min = i;
for (int j = i + 1; j < n; j++)
if (raw[j] < raw[min])
min = j;
swap(raw[min], raw[i]);
}
}
template<typename T>//https://zh.wikipedia.org/wiki/%E6%8F%92%E5%85%A5%E6%8E%92%E5%BA%8F
void insertion(T raw[], int n) {//poker!
for (int i = 1; i < n; i++) {//poker zero is sorted
int poker = raw[i];
int j = i - 1;
while (poker < raw[j] && j >= 0) {
raw[j + 1] = raw[j];
j--;
}
raw[j + 1] = poker;
}
}
template<typename T>//https://zh.wikipedia.org/wiki/%E5%BD%92%E5%B9%B6%E6%8E%92%E5%BA%8F
void merge(T raw[], int n) {
T *a = raw;
T *b = new T[n];//?T b[n]
int start1, end1, start2, end2, i;
for (int seg = 1; seg < n; seg += seg) {
for (int start = 0; start < n; start += seg + seg) {
i = start;
start1 = start;
end1 = min(start + seg, n);
start2 = end1;
end2 = min(start + seg + seg, n);
while (start1 < end1 && start2 < end2)
b[i++] = a[start1] < a[start2] ? a[start1++] : a[start2++];
while (start1 < end1)
b[i++] = a[start1++];
while (start2 < end2)
b[i++] = a[start2++];
}
swap(a, b);
}
if (a != raw) {
for (i = 0; i < n; i++)
b[i] = a[i];
b = a;
}
delete[] b;//?
}
struct Range {
int begin, end;
Range(int b = 0, int e = 0) {
begin = b, end = e;
}
};
template<typename T>
int partition(T raw[], int begin, int end) {//Is that right?
T pivot = raw[end];
int i = begin, j = end;
while (i < j) {
while (i < j && raw[i] < pivot)
i++;
while (i < j && raw[j] >= pivot)
j--;
swap(raw[i], raw[j]);
}
if (raw[i] > pivot)
swap(raw[i], raw[end]);
return i;
}
template<typename T>//https://zh.wikipedia.org/wiki/%E5%BF%AB%E9%80%9F%E6%8E%92%E5%BA%8F
void quick(T raw[], int n) {
/*output(raw, n);
cout << partition(raw, 0, n - 1) << endl;
output(raw, n);*/
int p = 0, i, j, k;
Range *range = new Range[n];//stack
range[p++] = { 0, n - 1 };
while (p) {
Range r = range[--p];
if (r.begin >= r.end)
continue;
i = r.begin;
j = r.end;
k = partition(raw, i, j);
range[p++] = Range{ r.begin, k - 1 };
range[p++] = Range{ k + 1, r.end };
}
}
//https://zh.wikipedia.org/wiki/%E8%AE%A1%E6%95%B0%E6%8E%92%E5%BA%8F
void counting(int raw[], int n) {
int count[RAND_MAX + 1] = { 0 };//1 hour, 32767
int *sorted = new int[n];
int i;
for (i = 0; i < n; i++)
count[raw[i]]++;
for (i = 1; i < RAND_MAX; i++)
count[i] += count[i - 1];
for (i = n - 1; i >= 0; i--)
sorted[--count[raw[i]]] = raw[i];
for (i = 0; i < n; i++)//raw = sorted?
raw[i] = sorted[i];
delete[] sorted;
}
//https://zh.wikipedia.org/wiki/%E5%9F%BA%E6%95%B0%E6%8E%92%E5%BA%8F
void radix(int raw[], int n) {
int max = raw[0];//int?
int i, digits = 1;
for (i = 1; i < n - 1; i++)
if (raw[i] > max)
max = raw[i];
while (max >= 10) {
max /= 10;
digits++;
}
int j, radix = 1, digit;
int *count = new int[10];
int *transition = new int[n];
for (i = 0; i < digits; i++) {
for (j = 0; j < 10; j++)
count[j] = 0;
for (j = 0; j < n; j++) {
digit = (raw[j] / radix) % 10;
count[digit]++;
}
for (j = 1; j < 10; j++)
count[j] += count[j - 1];
for (j = 0; j < n; j++) {
digit = (raw[j] / radix) % 10;
transition[--count[digit]] = raw[j];
}
for (j = 0; j < n; j++)
raw[j] = transition[j];
radix *= 10;
}
delete[] count;
delete[] transition;
}
template<typename T>//https://zh.wikipedia.org/wiki/%E5%B8%8C%E5%B0%94%E6%8E%92%E5%BA%8F
void shell(T raw[], int n) {//insertion 1->D
for (int D = n / 2 - 1; D > 0; D = D / 2 - 1)//faster
for (int i = D; i < n; i++) {
int poker = raw[i];
int j = i - D;
while (j >= 0 && poker < raw[j]) {//!
raw[j + D] = raw[j];
j = j - D;
}
raw[j + D] = poker;
}
}
template<typename T>
void sink(T heap[], int endLeaf, int i) {
while (2 * i + 1 < endLeaf) {
int childIndex = 2 * i + 1;
if (childIndex + 1 < endLeaf && heap[childIndex] < heap[childIndex + 1])
childIndex++;
if (heap[i] < heap[childIndex]) {
swap(heap[i], heap[childIndex]);
i = childIndex;
}
else
break;
}
}
template<typename T>
void maxHeapify(T raw[], int n) {
for (int i = (n - 1) / 2; i >= 0; i--)
sink(raw, n - 1, i);
}
//https://zh.wikipedia.org/wiki/%E5%A0%86%E6%8E%92%E5%BA%8F
//https://www.liwei.party/2019/01/11/algorithms-and-data-structures/heapify-and-heap-sort/
//https://www.youtube.com/watch?v=Nl9E3tURyX8&list=PLe68gYG2zUeVNPEr9XPqeejGHihtQD6tl&index=37
template<typename T>//inplace index from 0, but why
void heap(T raw[], int n) {//selection
maxHeapify(raw, n);
for (int i = n - 1; i > 0; i--) {//interesting
swap(raw[0], raw[i]);//value
sink(raw, i - 1, 0);//index
}
}
int main(int argc, char *argv[]) {
double duration;
clock_t start, end;//clock()函数返回从“开启这个程序进程”到“程序中调用clock()函数”时之间的CPU时钟计时单元(clock tick)数
srand(6324);
//cout << RAND_MAX << endl;
int raw[ARRAY];
int n = sizeof(raw) / sizeof(*raw);
for (int i = 0; i < ARRAY; i++)
raw[i] = rand();
start = clock();
bubble(raw, ARRAY);//c++ dont know the length of raw
end = clock();
duration = (double)(end - start);
cout << "Bubble sort duration " << duration / CLOCKS_PER_SEC << " s" << endl;//CLOCKS_PER_SEC用来表示一秒钟会有多少个时钟计时单元
for (int i = 0; i < ARRAY; i++)
raw[i] = rand();
start = clock();
selection(raw, ARRAY);
end = clock();
duration = (double)(end - start);
cout << "Selection sort duration " << duration / CLOCKS_PER_SEC << " s" << endl;
for (int i = 0; i < ARRAY; i++)
raw[i] = rand();
start = clock();
insertion(raw, ARRAY);
end = clock();
duration = (double)(end - start);
cout << "Insertion sort duration " << duration / CLOCKS_PER_SEC << " s" << endl;
for (int i = 0; i < ARRAY; i++)
raw[i] = rand();
start = clock();
merge(raw, ARRAY);
end = clock();
duration = (double)(end - start);
cout << "Merge sort duration " << duration / CLOCKS_PER_SEC << " s" << endl;
for (int i = 0; i < ARRAY; i++)
raw[i] = rand();
start = clock();
quick(raw, ARRAY);
end = clock();
duration = (double)(end - start);
cout << "Quick sort duration " << duration / CLOCKS_PER_SEC << " s" << endl;
for (int i = 0; i < ARRAY; i++)
raw[i] = rand();
start = clock();
counting(raw, ARRAY);
end = clock();
duration = (double)(end - start);
cout << "Counting sort duration " << duration / CLOCKS_PER_SEC << " s" << endl;
for (int i = 0; i < ARRAY; i++)
raw[i] = rand();
start = clock();
radix(raw, ARRAY);
end = clock();
duration = (double)(end - start);
cout << "Radix sort duration " << duration / CLOCKS_PER_SEC << " s" << endl;
for (int i = 0; i < ARRAY; i++)
raw[i] = rand();
start = clock();
shell(raw, ARRAY);
end = clock();
duration = (double)(end - start);
cout << "Shell sort duration " << duration / CLOCKS_PER_SEC << " s" << endl;
for (int i = 0; i < ARRAY; i++)
raw[i] = rand();
start = clock();
heap(raw, ARRAY);
end = clock();
duration = (double)(end - start);
cout << "Heap sort duration " << duration / CLOCKS_PER_SEC << " s" << endl;
for (int i = 0; i < ARRAY; i++)
raw[i] = rand();
start = clock();
sort(raw, raw + ARRAY);
end = clock();
duration = (double)(end - start);
cout << "C++ sort duration " << duration / CLOCKS_PER_SEC << " s" << endl;
system("pause");
return 0;
}
图
图算法也有无数种,这里实现经典的十种。
首先是三种经典遍历算法,分别是DFS,BFS和A*搜索,然后是最短路径算法Dijkstra,Bellman-Ford,Floyd-Warshall,之后是最小生成树算法Kruskal,Prim,最后是之前用过的强连通分量Tarjan算法和Hungarian解决最大二分匹配问题。Tarjan和Hungarian之后补充。
求SSSP(单源最短路)时,松弛Relax想象为现在你的手攥着u,v两个点,手中有一长一短两根绳子,假设原先你只知道从左手u到右手v只能通过较长的一根到达,扯紧之后发现,较长的那根松掉了,现在发现了从u到v更短的一根,将这种操作就描述为松弛。
基于邻接矩阵实现的算法:
#include <iostream>
#include <string>
#include <queue>
#include <functional>
#include <vector>
#include <algorithm>
#pragma warning(disable:4996)
#define VERTEX 13
using namespace std;//A must?
struct MinHeap {
int vertexID;
int distance;//and Prim key,也就是Prim中扩充的点到生成树的距离,被并入树后变成0,Dijkstra中是记录当前到所有已扩充的点集中的点的最小距离,只是用来push进堆排序用的。其实都算到树的距离了吧?
bool operator > (const MinHeap &vertex) const {//greater要重载>!淦
return this->distance > vertex.distance;
}
};
struct Arcs {
int u;
int v;
int w;
};//为了遍历所有的边,找出一条最短的边让最短边端点的并查集?合并。并查集叫合并吗,去看一下老师的视频。
struct AdjacencyMatrix {//都放结构体里了,实际做肯定不会这样做,只是作为全局变量不舒服。
string vertex[VERTEX];
int edges[VERTEX][VERTEX];
int isTraversed[VERTEX];
int parent[VERTEX];//记录路径用
int distance[VERTEX];
int rank[VERTEX];//Kruskal,也就是在树里的高度,为了将小树并入大树,why?
int nArcs;
Arcs arcs[VERTEX*VERTEX];//迫不得已,做到Kruskal已经不知道可以用什么更好的办法了,有向图最多VERTEX(VERTEX-1)条边。
MinHeap key[VERTEX];
};
void createGraph(AdjacencyMatrix &graph) {
// 00 01 02 03 04 05 06 07 08 09 10 11 12
int map[VERTEX][VERTEX] = { { 0, 75, -1,118, -1, -1, -1,140, -1, -1, -1, -1, -1 },//0
{ -1, 0, 71, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1 },//1
{ -1, -1, 0, -1, -1, -1, -1,151, -1, -1, -1, -1, -1 },//2
{ -1, -1, -1, 0,111, -1, -1, -1, -1, -1, -1, -1, -1 },//3
{ -1, -1, -1, -1, 0, 70, -1, -1, -1, -1, -1, -1, -1 },//4
{ -1, -1, -1, -1, -1, 0, 75, -1, -1, -1, -1, -1, -1 },//5
{ -1, -1, -1, -1, -1, -1, 0, -1, -1,120, -1, -1, -1 },//6
{ -1, -1, -1, -1, -1, -1, -1, 0, 80, -1, 99, -1, -1 },//7
{ -1, -1, -1, -1, -1, -1, -1, -1, 0,146, -1, 97, -1 },//8
{ -1, -1, -1, -1, -1, -1, -1, -1, -1, 0, -1,138, -1 },//9
{ -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, 0, -1,211 },//10
{ -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, 0,101 },//11
{ -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, 0 } //12
};//13 points
graph.nArcs = 0;
for (int i = 0; i < VERTEX; i++)
for (int j = i; j < VERTEX; j++)
if (map[i][j] != -1) {
map[j][i] = map[i][j];
graph.arcs[graph.nArcs] = Arcs{ i, j, map[i][j] };
graph.arcs[graph.nArcs + 1] = Arcs{ j, i, map[j][i] };
graph.nArcs += 2;
}
memcpy(graph.edges, map, sizeof(map));
graph.vertex[0] = "Arad";
graph.vertex[1] = "Zerind";
graph.vertex[2] = "Oradea";
graph.vertex[3] = "Timisoara";
graph.vertex[4] = "Lugoj";
graph.vertex[5] = "Mehadia";
graph.vertex[6] = "Drobeta";
graph.vertex[7] = "Sibiu";
graph.vertex[8] = "Rimnicu-Vilcea";
graph.vertex[9] = "Craiova";
graph.vertex[10] = "Fagaras";
graph.vertex[11] = "Pitesti";
graph.vertex[12] = "Bucharest";
for (int i = 0; i < VERTEX; i++)
graph.isTraversed[i] = 0;
}
void outputGraph(AdjacencyMatrix &graph) {
for (int i = 0; i < VERTEX; i++)
for (int j = 0; j < VERTEX; j++)
if (graph.edges[i][j] > 0)
cout << graph.vertex[i] << " -> " << graph.vertex[j] << " : " << graph.edges[i][j] << endl;
}
void initializeSingleSource(AdjacencyMatrix &graph, int s) {
for (int i = 0; i < VERTEX; i++) {
graph.distance[i] = INT_MAX;
graph.parent[i] = -1;
}
graph.distance[s] = 0;
}
void relax(AdjacencyMatrix &graph, int u, int v) {
if (graph.distance[v] > graph.distance[u] + graph.edges[u][v]) {
graph.distance[v] = graph.distance[u] + graph.edges[u][v];
graph.parent[v] = u;
}
}
void dijkstra(AdjacencyMatrix &graph, int start) {//Shortest path from start city to every city.
initializeSingleSource(graph, start);
priority_queue<MinHeap, vector<MinHeap>, greater<MinHeap>> q;//#include <functional>
q.push(MinHeap{ start, graph.distance[start] });
while (!q.empty()) {
MinHeap vertex = q.top();
q.pop();
graph.isTraversed[vertex.vertexID] = 1;
for (int i = 0; i < VERTEX; i++) {
if (graph.isTraversed[i] == 0 && graph.edges[vertex.vertexID][i] > 0) {
relax(graph, vertex.vertexID, i);
q.push(MinHeap{ i, graph.distance[i] });
}
}
}
}
bool bellmanFord(AdjacencyMatrix &graph, int start) {
initializeSingleSource(graph, start);
for (int i = 0; i < VERTEX - 1; i++)
for (int j = 0; j < VERTEX; j++)//对每条边做遍历的时候用邻接表或者先存一下边会比较好,这里直接扫描全部了
for (int k = 0; k < VERTEX; k++)
if (graph.edges[j][k] > 0)
relax(graph, j, k);
for (int i = 0; i < VERTEX; i++)
for (int j = 0; j < VERTEX; j++)
if (graph.edges[i][j] > 0 && graph.distance[i] > graph.distance[j] + graph.edges[i][j])//Yeah
return false;
return true;
}
void floydWarshall(AdjacencyMatrix &graph) {
for (int k = 0; k < VERTEX; k++)
for (int i = 0; i < VERTEX; i++)
for (int j = 0; j < VERTEX; j++)
if (graph.edges[i][k] != -1 && graph.edges[k][j] != -1 && ((graph.edges[i][j] >= graph.edges[i][k] + graph.edges[k][j]) || graph.edges[i][j] == -1))
graph.edges[i][j] = graph.edges[i][k] + graph.edges[k][j];
}
void makeSet(AdjacencyMatrix &graph, int x) {
graph.parent[x] = x;//parent(root) is the set
graph.rank[x] = 0;
}
int findSet(AdjacencyMatrix &graph, int x) {
if (x != graph.parent[x])
graph.parent[x] = findSet(graph, graph.parent[x]);
return graph.parent[x];
}
void linkSet(AdjacencyMatrix &graph, int u, int v) {
if (graph.rank[u] > graph.rank[v])
graph.parent[v] = u;
else {
graph.parent[u] = v;
if (graph.rank[u] = graph.rank[v])
graph.rank[v]++;
}
}
void unionSet(AdjacencyMatrix &graph, int u, int v) {
linkSet(graph, findSet(graph, u), findSet(graph, v));
}
bool compare(Arcs e1, Arcs e2) {
return e1.w < e2.w;
}
vector<string> kruskal(AdjacencyMatrix &graph) {
vector<string> mst;
for (int i = 0; i < VERTEX; i++)
makeSet(graph, i);
sort(graph.arcs, graph.arcs + graph.nArcs, compare);
for (int i = 0; i < graph.nArcs; i++)
if (findSet(graph, graph.arcs[i].u) != findSet(graph, graph.arcs[i].v)) {
char *buffer = new char[10];
unionSet(graph, graph.arcs[i].u, graph.arcs[i].v);
sprintf(buffer, "%d -> %d", graph.arcs[i].u, graph.arcs[i].v);
mst.push_back(buffer);
}
return mst;
}
bool prim(AdjacencyMatrix &graph) {//我在写什么?以后不要来自习室了,去个别的有人的地方。
int count = 0;
priority_queue<MinHeap, vector<MinHeap>, greater<MinHeap>> q;
initializeSingleSource(graph, 0);//0 is a random root,非常像Dijkstra
q.push(MinHeap{ 0, graph.distance[0] });
while (!q.empty()) {//非常像Dijkstra,但区别是什么呢?Prim只看当前这条边的权重,不看之前的距离!就在这!
MinHeap u = q.top();//和Dijkstra一样,这里只是找最小的那条边,parent比较出的一定是最小的那条边,一定的。
q.pop();
graph.distance[u.vertexID] = 0;//被纳入MST
count++;
for (int i = 0; i < graph.nArcs; i++) {//找u的邻接点也就是弧头v,graph.arcs[i],对边做遍历。
if (graph.arcs[i].u == u.vertexID) {
if (graph.distance[graph.arcs[i].v] != 0) {//这条边或者说这个点没在树内
if (graph.edges[graph.arcs[i].u][graph.arcs[i].v] < graph.distance[graph.arcs[i].v]) {
graph.distance[graph.arcs[i].v] = graph.edges[graph.arcs[i].u][graph.arcs[i].v];
graph.parent[graph.arcs[i].v] = graph.arcs[i].u;
q.push(MinHeap{ graph.arcs[i].v, graph.distance[graph.arcs[i].v] });
}
}
}
}
}
if (count < VERTEX)
return false;
return true;
}
int main(int argc, char *argv[]) {
AdjacencyMatrix graph;
int start = 0, end = 12;
createGraph(graph);
outputGraph(graph);
//Dijkstra
cout << endl << "Dijkstra" << endl;
createGraph(graph);
dijkstra(graph, start);
for (int i = 0; i < VERTEX; i++) {
int j = i;
cout << graph.vertex[j];
while (graph.parent[j] != -1) {
j = graph.parent[j];
cout << " <- " << graph.vertex[j];
}
cout << endl;
}
//Bellman-Ford
cout << endl << "Bellman-Ford" << endl;
if (bellmanFord(graph, start))
for (int i = 0; i < VERTEX; i++) {
int j = i;
cout << graph.vertex[j];
while (graph.parent[j] != -1) {
j = graph.parent[j];
cout << " <- " << graph.vertex[j];
}
cout << endl;
}
else
cout << "There's a negative cycle" << endl;
//Floyd-Warshall
cout << endl << "Floyd-Warshall" << endl;
createGraph(graph);
floydWarshall(graph);
for (int i = 0; i < VERTEX; i++) {
for (int j = 0; j < VERTEX; j++)
cout << graph.edges[i][j] << " ";
cout << endl;
}
//Kruskal
cout << endl << "Kruskal" << endl;
createGraph(graph);
vector<string> mstKruskal = kruskal(graph);
for (int i = 0; i < mstKruskal.size(); i++)
cout << mstKruskal[i] << endl;
//Prim
cout << endl << "Prim" << endl;//稠密图合算?
createGraph(graph);
if (prim(graph))
for (int i = 1; i < VERTEX; i++)
cout << graph.parent[i] << " -> " << i << endl;
else
cout << "不连通,生成树不存在。" << endl;
system("pause");
return 0;
}
基于邻接表实现的算法:
#include <iostream>
#include <string>
#include <vector>
#include <algorithm>
#define VERTEX 13
using namespace std;
struct ArcToNode {//这样和构造函数有什么区别?
int adjacencyVertex;
int weight = 1;
ArcToNode *next;
};
template<typename T>
struct VertexNode {
T vertexData = T();//?
ArcToNode *firstEdge = NULL;
};
template<typename T>
struct AdjacencyList {
int nVertex = VERTEX;
int nEdge = INFINITY;
VertexNode<T> vertex[VERTEX];//?
int isTraversed[VERTEX] = { 0 };//假设只入一次即可,因为先入队列的肯定经过的城市数更少。
int parent[VERTEX];//path
};
//variables of tarjan
int inStack[VERTEX] = { 0 };//In tarjan, it represents whether the vertex is in stack or not.
int low[VERTEX] = { 0 };//lowest dfn in stack
int dfn[VERTEX] = { 0 };//timestamp
int dIndex = 0;//time stamp
int starray[VERTEX] = { 0 };//stack
int sIndex = 0;//stack index
void addEdge(AdjacencyList<string> &graph, int arcTail, int arcHead, int weight) {
ArcToNode *edge = graph.vertex[arcTail].firstEdge;
ArcToNode *arc = new ArcToNode();//申请的是堆内空间?
arc->adjacencyVertex = arcHead;
arc->weight = weight;
arc->next = NULL;
if (edge == NULL)
graph.vertex[arcTail].firstEdge = arc;
else {
while (edge->next != NULL)
edge = edge->next;
edge->next = arc;
}
}
void createGraph(AdjacencyList<string> &graph) {
graph.vertex[0].vertexData = "Arad";
graph.vertex[1].vertexData = "Zerind";
graph.vertex[2].vertexData = "Oradea";
graph.vertex[3].vertexData = "Timisoara";
graph.vertex[4].vertexData = "Lugoj";
graph.vertex[5].vertexData = "Mehadia";
graph.vertex[6].vertexData = "Drobeta";
graph.vertex[7].vertexData = "Sibiu";
graph.vertex[8].vertexData = "Rimnicu-Vilcea";
graph.vertex[9].vertexData = "Craiova";
graph.vertex[10].vertexData = "Fagaras";
graph.vertex[11].vertexData = "Pitesti";
graph.vertex[12].vertexData = "Bucharest";
addEdge(graph, 0, 1, 75); addEdge(graph, 1, 0, 75);
addEdge(graph, 0, 3, 118); addEdge(graph, 3, 0, 118);
addEdge(graph, 0, 7, 140); addEdge(graph, 7, 0, 140);
addEdge(graph, 1, 2, 71); addEdge(graph, 2, 1, 71);
addEdge(graph, 2, 7, 151); addEdge(graph, 7, 2, 151);
addEdge(graph, 3, 4, 111); addEdge(graph, 4, 3, 111);
addEdge(graph, 4, 5, 70); addEdge(graph, 5, 4, 70);
addEdge(graph, 5, 6, 75); addEdge(graph, 6, 5, 75);
addEdge(graph, 6, 9, 120); addEdge(graph, 9, 6, 120);
addEdge(graph, 7, 8, 80); addEdge(graph, 8, 7, 80);
addEdge(graph, 7, 10, 99); addEdge(graph, 10, 7, 99);
addEdge(graph, 8, 9, 146); addEdge(graph, 9, 8, 146);
addEdge(graph, 8, 11, 97); addEdge(graph, 11, 8, 97);
addEdge(graph, 9, 11, 138); addEdge(graph, 11, 9, 138);
addEdge(graph, 10, 12, 211); addEdge(graph, 12, 10, 211);
addEdge(graph, 11, 12, 101); addEdge(graph, 12, 11, 101);
}
void outputGraph(AdjacencyList<string> graph) {
for (int i = 0; i < graph.nVertex; i++) {
ArcToNode *edge = graph.vertex[i].firstEdge;
while (edge != NULL) {
cout << graph.vertex[i].vertexData << " -> " << graph.vertex[edge->adjacencyVertex].vertexData << ": " << edge->weight << endl;
edge = edge->next;
}
}
}
template<typename T>//这里只算到目标城市经过城市最少的路径,weight默认为1,简化一下只是学习BFS。
void breadthFirstSearch(AdjacencyList<T> &graph) {//stack and queue for dfs and bfs, excellent.
int *queue = new int[graph.nVertex];
int head = graph.nVertex - 1, tail = graph.nVertex - 1;//想象撸这个动作
queue[tail--] = 0;//enqueue
graph.isTraversed[0] = 1;
while (tail != head) {
int ver = queue[head--];//dequeue
ArcToNode *arc = graph.vertex[ver].firstEdge;
while (arc != NULL) {
if (graph.isTraversed[arc->adjacencyVertex] != 1) {
graph.isTraversed[arc->adjacencyVertex] = 1;
graph.parent[arc->adjacencyVertex] = ver;
queue[tail--] = arc->adjacencyVertex;
}
if (arc->adjacencyVertex == 12)//start 0, end 12.
break;
arc = arc->next;
}
}
}
void deleteGraph(AdjacencyList<string> &graph) {
for (int i = 0; i < graph.nVertex; i++) {
ArcToNode *edge = graph.vertex[i].firstEdge;
ArcToNode *temp = edge;
while (edge->next != NULL) {//delete linkedlist in C++
temp = edge->next;
delete edge;
edge = temp;
}
}
}
void createTarjanGraph(AdjacencyList<string> &graph) {
graph.vertex[0].vertexData = "Arad";
graph.vertex[1].vertexData = "Zerind";
graph.vertex[2].vertexData = "Oradea";
graph.vertex[3].vertexData = "Timisoara";
graph.vertex[4].vertexData = "Lugoj";
graph.vertex[5].vertexData = "Mehadia";
addEdge(graph, 0, 1, 1);
addEdge(graph, 0, 2, 1);
addEdge(graph, 1, 3, 1);
addEdge(graph, 2, 3, 1);
addEdge(graph, 2, 4, 1);
addEdge(graph, 3, 5, 1);
addEdge(graph, 4, 0, 1);
graph.nVertex = 6;
}
void tarjan(AdjacencyList<string> &graph, int u) {
int v;
dfn[u] = low[u] = dIndex++;
inStack[u] = 1;
starray[sIndex++] = u;
for (ArcToNode *edge = graph.vertex[u].firstEdge; edge != NULL; edge = edge->next) {
v = edge->adjacencyVertex;
if (!dfn[v]) {
tarjan(graph, v);
low[u] = min(low[u], low[v]);//?
}
else if (inStack[v] == 1)
low[u] = min(low[u], dfn[v]);//min? dfn? not low?
}
if (dfn[u] == low[u]) {
do {//?
v = starray[--sIndex];
cout << v << " ";
inStack[u] = 0;
} while (u != v);
cout << endl;
}
}
void hungarian(AdjacencyList<string> &graph) {
}
int main(int argc, char *argv[]) {
//BFS 事实证明写题还是邻接矩阵好用
AdjacencyList<string> graphBFS;
createGraph(graphBFS);
outputGraph(graphBFS);
cout << endl << "BFS solution of Romania problem:" << endl;
breadthFirstSearch(graphBFS);
cout << "So, the path through least cities is : " << graphBFS.vertex[12].vertexData << " <- ";
for (int i = 12; i != 0;) {
i = graphBFS.parent[i];
cout << graphBFS.vertex[i].vertexData << " <- ";
}
cout << " Here we go!" << endl;
deleteGraph(graphBFS);
//Tarjan 个屁,写算法肯定是邻接表好用
AdjacencyList<string> graphTarjan;
createGraph(graphTarjan);
outputGraph(graphTarjan);
cout << endl << "Tarjan solution of Strongly Connected Components:" << endl;
for (int i = 0; 1 < graphTarjan.nVertex; i++)
if (!dfn[i])
tarjan(graphTarjan, i);//强连通分量之间如果有交叉那么肯定可以被合并为同一个强联通分量。
//Hungarian 没写完,抓紧写一下动态规划和回溯
AdjacencyList<string> graphHungarian;
createTarjanGraph(graphHungarian);
outputGraph(graphHungarian);
cout << endl << "Hungarian solution of Bipartite Matching:" << endl;
hungarian(graphHungarian);
system("pause");
return 0;
}
回溯
N皇后问题,这里会用到回溯法、局部搜索的遗传算法、约束满足问题的最小冲突算法(Min-conflicts Algorithm)来尝试解决这些问题。
代码结构:

Solutions:
#pragma warning(disable:4996)
#include <iostream>
#include <string>
#include "Backtracking.h"
#include "Minconflicts.h"
#include "Genetic.h"
#include <ctime>
using namespace std;
#define n 8
int main(int argc, char argv[]) {
double duration;
clock_t start, end;
cout << "Backtracking:" << endl;
Backtracking bt(n);
start = clock();
bt.backtracking(0);//recursive
end = clock();
duration = (double)(end - start);
cout << "回溯法算得 "<<bt.nSolutions() <<" 种答案,用时 "<< duration / CLOCKS_PER_SEC << " 秒" <<endl;
cout << "Minconflicts:" << endl;
Minconflicts mc(n);
start = clock();
mc.compute();
end = clock();
duration = (double)(end - start);
cout << "最小冲突找到一种答案用时 " << duration / CLOCKS_PER_SEC << " 秒" << endl;
cout << "Genetic:" << endl;
Genetic gg(n, 4*n);
start = clock();
gg.compute();
end = clock();
duration = (double)(end - start);
cout << "遗传算法找到一种答案用时 " << duration / CLOCKS_PER_SEC << " 秒" << endl;
system("pause");
return 0;
}
回溯法Backtracking.h:
#pragma once//include防范
#include <iostream>
//原本八皇后问题是C_64^8,64取8是C(64, 8) = 4426165368,44亿种可能的情况,纯暴力不可取。
//每次放皇后的时候都检查每一行每一列每一斜角线是否存在冲突皇后,以此在搜索树上剪枝回溯。那么代码就非常好写。
class Backtracking {
private:
const int n;//board
int total;//solutions
int *queens;
public:
Backtracking(int num = 8) : n(num), queens(new int[num]), total(0) {//queens 0~7
for (int i = 0; i < n; i++)
queens[i] = -1;
};
bool isOk(int row);
void backtracking(int row);
//print all answer
void print();
int nSolutions();
};
回溯法Backtracking.cpp:
#include "Backtracking.h"
bool Backtracking::isOk(int row) {
for (int i = 0; i < row; i++)//Top-down
if (queens[row] - queens[i] == row - i || queens[row] - queens[i] == i - row || queens[row] == queens[i])//两个对角线
return false;
return true;
}
void Backtracking::backtracking(int row) {
if (row >= n) {
total++;
//print();//if you wanna print all solutions
//exit(0);//if you wanna find just 1 solution
}
else
for (int col = 0; col < n; col++) {
queens[row] = col;
if (isOk(row))
backtracking(row + 1);
}
}
void Backtracking::print() {
for (int i = 0; i < n; i++) {
for (int j = 0; j < queens[i]; j++)
std::cout << " .";
std::cout << " Q";
for (int j = queens[i] + 1; j < n; j++)
std::cout << " .";
std::cout << std::endl;
}
std::cout << std::endl;
}
int Backtracking::nSolutions() {
return total;
}
最小冲突Minconflicts.h:
#pragma once
#include <iostream>
#include <random>
#include <windows.h>
#include <algorithm>
//关于Min-Conflicts,在途中给搜索树剪枝回溯的基础上,每次选择可选位置最少的一个来尝试。--读完《人工智能--一种现代方法》的理解,是增量式的。
//先随机初始化一个分配好皇后的棋盘,然后选择一个皇后,检查棋盘,移动到一个使得冲突最少的位置,以此往复,这是看完维基的理解,是完全状态的。
//拖了五天没写,摸了三天鱼,重建了网站,配置好了树莓派,看完了塞林格一本半的书,就是没写算法、没做NLP、没学网络,反正就是不干正事,铁废物。破算法十分钟看明白了。
class Minconflicts {
private:
int n;//N-Queens
int *col;//queens num of every column
//queens num of diagonal, but conflicts equals queens-1
int *mdiag;//main diagonal
int *adiag;//anti-diagonal
int *queens;//board
public:
Minconflicts(int num = 8) : n(num), col(new int[num]), mdiag(new int[2 * num]), adiag(new int[2 * num]), queens(new int[num]) {
for (int i = 0; i < num; i++) {
col[i] = 0;
queens[i] = -1;
}
for (int i = 0; i < 2 * num - 1; i++) {//0 ~ 2*num-2, 2n-1个
mdiag[i] = 0;
adiag[i] = 0;
}
}
//which diagonal the queen is on
int getMainDia(int row, int col);
int getAntiDia(int row, int col);
//key functions
void initialize();
void calculate(int row, int srccol, int destcol);//there is a queen on each row, so integer row represents a queen
bool checkitout(int row);
void compute();//main
//print 1 answer
void print();
};
最小冲突Minconflicts.cpp
#include "Minconflicts.h"
int Minconflicts::getMainDia(int row, int col) {//找一个一条对角线的不变量,就是row - col = constant, 最小是1 - n, 所以加上n - 1,0 ~ 2n - 2共(2n - 1)个。
return row - col + n - 1;
}
int Minconflicts::getAntiDia(int row, int col) {
return row + col;
}
void Minconflicts::initialize() {
for (int i = 0; i < n; i++) {//every row has only one queen
queens[i] = rand() % n;//这里我直接随机分配了,也可以在初始化时就同时保持每行1个每列1个皇后。
calculate(i, -1, queens[i]);
}
std::cout << "初始皇后序列:" << std::endl;
print();
}
void Minconflicts::calculate(int row, int srccol, int destcol) {//这里按行计算,所以行确定,移动列就行。
col[destcol]++;
mdiag[getMainDia(row, destcol)]++;
adiag[getAntiDia(row, destcol)]++;
if (srccol == -1)
return;
col[srccol]--;
mdiag[getMainDia(row, srccol)]--;
adiag[getAntiDia(row, srccol)]--;
}
bool Minconflicts::checkitout(int row) {//给一行找一个最优列
int currentCol = queens[row];
int optimalCol = queens[row];
int minConflicts = col[optimalCol] + mdiag[getMainDia(row, optimalCol)] + adiag[getAntiDia(row, optimalCol)] - 3;//同列或对角线一共这么多个皇后,作者这里写得不对
/*std::cout << col[optimalCol] << " " << mdiag[getMainDia(row, optimalCol)] << " " << adiag[getAntiDia(row, optimalCol)] << std::endl;
std::cout << getMainDia(1, 1) << " " << mdiag[3] << " " << col[0] << std::endl;*/
for (int i = 0; i < n; i++) {//检查第row行的每一列i
if (i == currentCol)
continue;
int conflicts = col[i] + mdiag[getMainDia(row, i)] + adiag[getAntiDia(row, i)];//这里要加上假设移过来的那个皇后,也就是要+2,在上面-2比在下面+2开销小
/*std::cout << "main diagonal " << getMainDia(row, i) << " anti diagonal " << getAntiDia(row, i) << std::endl;
std::cout << "conflicts " << minConflicts << std::endl;*/
if (conflicts < minConflicts) {
optimalCol = i;
minConflicts = conflicts;
}
else if (conflicts == minConflicts && rand() % 2)//关键之一!为避免轻易进入局部最优的情况,比较简单的办法是让每一行的皇后随机改变,这里选择的是两列最小冲突值相等50%移动
optimalCol = i;
}
/*std::cout << "col " << optimalCol << std::endl;
std::cout << "conflicts " << minConflicts << std::endl;
std::system("pause");*/
if (currentCol != optimalCol) {//找到了且不是原来那一列,就把皇后移动过去
queens[row] = optimalCol;
calculate(row, currentCol, optimalCol);
if (col[currentCol] <= 1 && col[optimalCol] <= 1 && mdiag[getMainDia(row, optimalCol)] <= 1 && adiag[getAntiDia(row, optimalCol)] <= 1) {//加个条件略作优化
for (int i = 0; i < n; i++)//每一行检查现在是不是符合要求了
if (col[queens[i]] > 1 || mdiag[getMainDia(i, queens[i])] > 1 || adiag[getAntiDia(i, queens[i])] > 1)//这里原作者不对,可能为0
return false;
return true;
}
}
//print();
return false;//如果没改变,那肯定不对,不然检查上一行的时候就已经可以了
}
void Minconflicts::compute() {//Main
srand(GetCurrentProcessId());
//srand(2333);
initialize();
bool flag = false;
while (!flag) {//一轮找不到,毕竟只扫描了一次,不成功就不退出
for (int i = 0; i < n; i++) {//每一行i
if (checkitout(i)) {
flag = true;//一次没法break出两层循环,所以设置一个flag
break;
}
}
}
std::cout << "最终皇后序列:" << std::endl;
print();
}
void Minconflicts::print() {
for (int i = 0; i < n; i++) {
for (int j = 0; j < queens[i]; j++)
std::cout << " .";
std::cout << " Q";
for (int j = queens[i] + 1; j < n; j++)
std::cout << " .";
std::cout << std::endl;
}
}
遗传算法Genetic.h
#pragma once
#include <iostream>
#include <random>
#include <math.h>
#include <algorithm>
#include <functional>
//写这里的时候突然想到一个问题,给函数的命名用动词还是名词?
//想了一会感觉不必纠结,用动词就想象自己在操控,用名词代表我在旁观变化,模拟变化。均可。
class Genetic {//棋盘上有几个皇后,基因长度就是几,这样足够。
private:
int n;//N-Queens
int k;//K-Groups
//int *queens;//棋盘状态刚好可以当作个体的基因,是一个n位0~n-1的串。
struct Individual {
int *genes;
double fitness;
};
struct Population {
Individual *individuals;
Individual fittest;
}population;
bool flag;//成功找到最优解了吗?成功则false
public:
Genetic(int num_queens = 4, int num_groups = 16) : n(num_queens), k(num_groups), flag(true) {//初始化
population.individuals = new Individual[k];//赋值
for (int i = 0; i < k; i++)//初始化和赋值性质不一样,别忘了。
population.individuals[i].genes = new int[n];
}
//key functions
void initializePopulation();
//初始化种群
void calculateFitness(Individual &individual);//计算适应值
void selection();//选择,选择种群中最好的个体出来杂交
void crossover();//杂交,Crossover is the most significant phase in a genetic algorithm.
void mutation();//变异,发生突变是为了维持种群内部的多样性
void compute();//main
//print 1 answer
void print(int *queens);
};
遗传算法Genetic.cpp
#include "Genetic.h"
void Genetic::initializePopulation() {
for (int i = 0; i < k; i++) {
for (int j = 0; j < n; j++) {
population.individuals[i].genes[j] = rand() % n;
}
calculateFitness(population.individuals[i]);
}
}
void Genetic::calculateFitness(Individual &individual) {
int conflicts = 0;
int *queens = individual.genes;
int fitness;
for (int i = 0; i < n; i++) {
for (int j = i + 1; j < n; j++) {
if (queens[i] == queens[j] || abs(queens[i] - queens[j]) == j - i) {
conflicts++;
}
}
}
if (conflicts == 0) {
population.fittest = individual;
flag = false;
return;
}
individual.fitness = 1.0 / conflicts;//据一篇文章所说,用倒数而不是像书上用冲突数效果提高很多
}
void Genetic::selection() {//这里参考了sicolex的文章
double sum_fitness = 0.0;
for (int i = 0; i < k; i++)
sum_fitness += population.individuals[i].fitness;
for (int i = 0; i < n; i++) {//按轮盘赌选出的,顺序组成新种群,就相当于每次挑两个杂交了
int magnify_fitness = sum_fitness * 10000;
int random_fitness = rand() % magnify_fitness;
double select = (double)random_fitness / (double)10000;
int random_postion = std::lower_bound(population.individuals[i].genes, population.individuals[i].genes + n, select) - population.individuals[i].genes;//个人认为是upper,待会和lower做对比,可能还有更好的办法
std::swap(population.individuals[i], population.individuals[random_postion]);//是一个基因,一个int数组
}
}
void Genetic::crossover() {
int cross_over_point;//这里只是为了熟悉算法,就选择了随机选一个点交换右边的基因片段
for (int i = 0; i < k; i+=2) {
cross_over_point = rand() % n;
for (int j = cross_over_point; j < n; j++) {
std::swap(population.individuals[i].genes[j], population.individuals[i + 1].genes[j]);
}
}
}
void Genetic::mutation() {
for (int i = 0; i < k; i++) {
if (rand() % 2 == 0) {//这个基因组有50%几率突变,改变了就更新适应值
population.individuals[i].genes[rand() % n] = rand() % n;//gene有1/n/2的几率突变
calculateFitness(population.individuals[i]);
}
}
}
void Genetic::compute() {
initializePopulation();
while (flag) {
selection();
crossover();
mutation();
}
print(population.fittest.genes);
}
void Genetic::print(int *queens) {
for (int i = 0; i < n; i++) {
for (int j = 0; j < queens[i]; j++)
std::cout << " .";
std::cout << " Q";
for (int j = queens[i] + 1; j < n; j++)
std::cout << " .";
std::cout << std::endl;
}
}
动态规划
用旅行商问题Travelling Salesman Problem来学习。
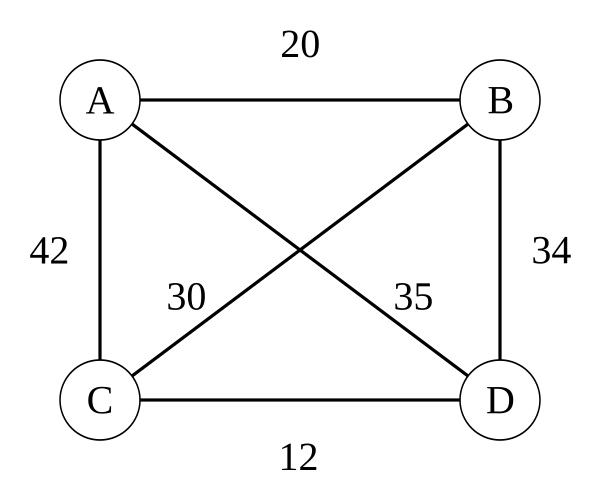
TSP要求从一个点出发,遍历每个点只一次并返回原点的最小代价路径。以来自维基的上图为例求解,动态规划问题一般分为四个步骤,首先刻画问题特征,然后找到一个递归解,最后递推地求最优解。
#pragma warning(disable: 4996)
#include <iostream>
#include <algorithm>
#include <math.h>
#include <string>
using namespace std;
//结果好像还有点问题,刷题去了
#define sqr(x) ((x)*(x))
//constant
//学习用0x3f3f3f3f https://blog.csdn.net/jiange_zh/article/details/50198097
#define INF 0x3f3f3f3f//https://blog.csdn.net/yi_ming_he/article/details/70405364
//Main https://cloud.tencent.com/developer/article/1103366
//variable
string file_name;
int type;//type==0满秩矩阵 type==1二维坐标
int s;
int city_num;//城市数量
int init_point;
double **dp;//动态规划状态数组dp[i][j],i表示集合V',j表示当前的城市
double **dist;//两个城市间的距离
double ans;
//struct
struct vertex {
double x, y;//坐标
int id;//城市id
int inpute(FILE *fp) {
return fscanf(fp, "%d %lf %lf", &id, &x, &y);
}
}*node;
double EuclideanDistance_2D(const vertex &a, const vertex &b) {
return sqrt(sqr(a.x - b.x) + sqr(a.y - b.y));//sqrt不行?sqr就行了
}
void io() {//从文件读数据
cout << "Input file_name and data type:" << endl;
cin >> file_name >> type;
string fname = "D:\\C++\\AlgorithmLearning\\DynamicProgramming\\" + file_name + ".data";
FILE *fp = fopen(fname.c_str(), "r");
fscanf(fp, "%d", &city_num);
node = new vertex[city_num + 1];
dist = new double*[city_num + 1];
//type==0满秩矩阵 type==1二维坐标
if (type == 0) {//矩阵
for (int i = 0; i < city_num; i++) {//就读进来
dist[i] = new double[city_num];
for (int j = 0; j < city_num; j++)
fscanf(fp, "%lf", &dist[i][j]);
}
}
else {//坐标
for (int i = 0; i < city_num; i++)
node[i].inpute(fp);
for (int i = 0; i < city_num; i++) {
dist[i] = new double[city_num];
for (int j = 0; j < city_num; j++)
dist[i][j] = EuclideanDistance_2D(node[i], node[j]);//现算距离
}
}
fclose(fp);
return;
}
void initialization() {
dp = new double*[(1 << city_num) + 1];//1? 5?
for (int i = 0; i < (1 << city_num); i++) {
dp[i] = new double[city_num + 5];
for (int j = 0; j < city_num; j++)
dp[i][j] = INF;
}
ans = INF;
return;
}
double compute() {
int status_num = (1 << city_num);//状态总数,2^city_num
dp[1][0] = 0;//这里是假设出发点是0号城市,出发点可以任选
for (int i = 1; i < status_num; i++) {//V'的所有状态
for (int j = 1; j < city_num; j++) {//下一个加入集合的城市
if (i & (1 << j))//已经在V'中了
continue;
if (!(i & 1))//出发城市固定0号
continue;
for (int k = 0; k < city_num; k++) {//V'城市集合中尝试每一个节点找最优解
if (i & (1 << k)) {//k在集合中并且是上一步转移来的,将j加入i集合
dp[(1 << j) | i][j] = min(dp[(1 << j) | i][j], dp[i][k] + dist[k][j]);//转移方程
}
}
}
}
for (int i = 0; i < city_num; i++)//固定了出发点所以加上到0城市的距离,从所有的完成整个环路的集合V'选择,完成最后的转移。
ans = min(dp[status_num - 1][i] + dist[i][0], ans);
return ans;
}
int main(int argc, char *argv[]) {
io();
initialization();
string fname = "D:\\C++\\AlgorithmLearning\\DynamicProgramming\\" + file_name + ".res";
FILE *fp = fopen(fname.c_str(), "w");
double res = compute();
cout << res << endl;
fprintf(fp, "%.2lf\n", res);
delete[] dp;
delete[] node;
delete[] dist;
fclose(fp);
system("pause");
return 0;
}
小结
还是太菜,任重而道远。
回顾这二十年,似乎做错了每一个人生结点的决定,狭窄的眼界限制了我太多太多。
之后会补充算法的对比和说明,暂时搁下去准备比赛、项目和期末的一堆任务了。
这个算法入门拖了足足半个月才写完。
希望中途打断的亚太杯建模能有个好结果。
哦另外,博客很快就要搬家到blog.v2beach.cn,到时别忘了给我启蒙的www.haomwei.com,www.byvoid.com和www.ruanyifeng.com/blog友情(跪膜)链接。















 1396
1396

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









