









1、为什么要使用 hibernate?
- 对JDBC访问数据库的代码做了封装,大大简化了数据访问层繁琐的重复性代码。
- Hibernate是一个基于JDBC的主流持久化框架,是一个优秀的ORM实现。他很大程度的简化DAO层的编码工作
- hibernate使用Java反射机制,而不是字节码增强程序来实现透明性。
- hibernate的性能非常好,因为它是个轻量级框架。映射的灵活性很出色。它支持各种关系数据库,从一对一到多对多的各种复杂关系。
2、什么是 ORM 框架?
对象-关系映射(Object-Relational Mapping,简称ORM),面向对象的开发方法是当今企业级应用开发环境中的主流开发方法,关系数据库是企业级应用环境中永久存放数据的主流数据存储系统。对象和关系数据是业务实体的两种表现形式,业务实体在内存中表现为对象,在数据库中表现为关系数据。内存中的对象之间存在关联和继承关系,而在数据库中,关系数据无法直接表达多对多关联和继承关系。因此,对象-关系映射(ORM)系统一般以中间件的形式存在,主要实现程序对象到关系数据库数据的映射。
3、hibernate 中如何在控制台查看打印的 sql 语句?
原文:http://mamicode.com/info-detail-1683868.html
(1)使用hibernate-configuration
这也许是最简单的一种配置。我们只需要为hibernate配置一个参数,就可以在console中打印出SQL语句。
需要增加的仅仅是这个参数(其它参数略去):
<hibernate-configuration>
<session-factory>
<property name="show_sql">true</property>
</session-factory>
</hibernate-configuration>与打印SQL语句相关的配置,还有两个:format_sql 和 use_sql_comments 。顾名思义,他们配置的是打印SQL时是否进行格式化、以及是否打印出相关的注释。
但是,hibernate自己的配置中,似乎不能将参数绑定到SQL上,SQL语句中只有问号占位符。
(2)使用log4j
如果使用log4j,我们需要做的就是为hibernate相应的类配置logger和appender。appender的配置略去(开发中一般就配置为console),logger配置如下:
log4j.properties文件配置:
log4j.logger.org.hibernate.SQL=DEBUG
log4j.logger.org.hibernate.type=TRACElog4j.xml文件配置:
<Logger name="org.hibernate.SQL" level="DEBUG"></Logger>
<Logger name="org.hibernate.type" level="TRACE"></Logger>上面的配置中,org.hibernate.SQL 的日志配置的效果与 show_sql=true 的配置果相似,都会把 SQL 语句打印出来。而org.hibernate.type 的日志配置,则会把 SQL 中占位符对应的参数打印出来。两者结合起来,日志结果如下:
Hibernate: INSERT INTO mkyong.stock_transaction (CHANGE, CLOSE, DATE, OPEN, STOCK_ID, VOLUME)VALUES (?, ?, ?, ?, ?, ?)
13:33:07,253 DEBUG FloatType:133 - binding ‘10.0‘ to parameter: 1
13:33:07,253 DEBUG FloatType:133 - binding ‘1.1‘ to parameter: 2
13:33:07,253 DEBUG DateType:133 - binding ‘30 December 2009‘ to parameter: 3
13:33:07,269 DEBUG FloatType:133 - binding ‘1.2‘ to parameter: 4
13:33:07,269 DEBUG IntegerType:133 - binding ‘11‘ to parameter: 5
13:33:07,269 DEBUG LongType:133 - binding ‘1000000‘ to parameter: 6但是,尽管这种方式能够把SQL和参数都打印出来,但是二者却是分开打印的。如果一段时间内执行的SQL非常多,那么这部分日志会比较的杂乱,对于开发来说帮助并不大。
4、hibernate 有几种查询方式?
原文:https://blog.csdn.net/sunrainamazing/article/details/72582887
hibernatez中有三种查询方式:分别是 HQL查询、SQL查询、条件查询。
//hibernate三种查询方式
//HQL: Hibernate Query Language. 面向对象的写法:
Query query = session.createQuery("from Customer where name = ?");
query.setParameter(0, "苍老师");
Query.list();
//QBC: Query By Criteria.(条件查询)
Criteria criteria = session.createCriteria(Customer.class);
criteria.add(Restrictions.eq("name", "花姐"));
List<Customer> list = criteria.list();
//SQL:
SQLQuery query = session.createSQLQuery("select * from customer");
List<Object[]> list = query.list();
SQLQuery query = session.createSQLQuery("select * from customer");
query.addEntity(Customer.class);
List<Customer> list = query.list();HQL: 具体分类:
1、 属性查询 2、 参数查询、命名参数查询 3、 关联查询 4、 分页查询 5、 统计函数
HQL和SQL的区别:
HQL是面向对象查询操作的,SQL是结构化查询语言 是面向数据库表结构的。
5、hibernate 实体类可以被定义为 final 吗?
Hibernate实体类创建注意事项
- 持久化类必须有无参的构造函数,因为反射的原因。
- 要有set/get方法
- 使用包装类型,解决数据库中值为null的问题
- 持久化类需要提供id与数据库中的主键相对应
- 不要用finall修饰class(hibernate是使用cglib代理生成的代理对象)
6、在 hibernate 中使用 Integer 和 int 做映射有什么区别?
- 返回数据库字段值是null的话,int类型会报错。int是基本数据类型,其声明的是变量,而null则是对象。所以 hibernate 实体建议用 integer;
- 通过 jdbc 将实体存储到数据库的操作通过 sql 语句,基本数据类型可以直接存储,对象需要序列化存储。
7、hibernate 是如何工作的?
hibernate 工作原理;
- 通过Configuration config = new Configuration().configure();//读取并解析hibernate.cfg.xml配置文件;
- 由 hibernate.cfg.xml文件中的<mapping resource = "com/vainglory/User.hbm.xml"/>读取并解析映射信息;
- 通过SessionFactory sf = fonfig.buildSessionFactory();//创建Sessionfactory
- Session session = sf.openSession();//打开Session
- Transaction tx = session.beginTransaction();//创建并启动事务Transaction
- persistent operate操作数据库,持久化操作;
- tx.commit();//提交事务;
- 关闭Session
- 关闭SessionFactory
8、get()和 load()的区别?
get()和load()方式是根据 id 取得一个记录。
- 对于Hibernate get方法,Hibernate会确认一下该id对应的数据是否存在,首先在session缓存中查找,然后在二级缓存中查找,还没有就查询数据库,数据 库中没有就返回null。这个相对比较简单,也没有太大的争议。主要要说明的一点就是在这个版本(bibernate3.2以上)中get方法也会查找二级缓存!
- Hibernate load方法加载实体对象的时候,根据映射文件上类级别的lazy属性的配置(默认为true),分情况讨论:
- 若为true,则首先在Session缓存中查找,看看该id对应的对象是否存在,不存在则使用延迟加载,返回实体的代理类对象(该代理类为实体类的子类,由CGLIB动态生成)。等到具体使用该对象(除获取OID以外)的时候,再查询二级缓存和数据库,若仍没发现符合条件的记录,则会抛出一个ObjectNotFoundException。
- 若为false,就跟Hibernateget方法查找顺序一样,只是最终若没发现符合条件的记录,则会抛出一个ObjectNotFoundException。
这里get和load有两个重要区别:
- 如果未能发现符合条件的记录,Hibernate get方法返回null,而load方法会抛出一个ObjectNotFoundException。
- load方法可返回没有加载实体数据的代理类实例,而get方法永远返回有实体数据的对象。
总之对于 get() 和 load() 的根本区别在于:
hibernate对于 load方法认为该数据在数据库中一定存在,可以放心的使用代理来延迟加载,如果在使用过程中发现了问题,只能抛异常;而对于get方 法,hibernate一定要获取到真实的数据,否则返回null。
9、说一下 hibernate 的缓存机制?
原文链接:https://www.jianshu.com/p/14ee37576892
-
Hibernate缓存的作用:
Hibernate是一个持久层框架,经常访问物理数据库,为了降低应用程序对物理数据源访问的频次,从而提高应用程序的运行性能。缓存内的数据是对物理数据源中的数据的复制,应用程序在运行时从缓存读写数据,在特定的时刻或事件会同步缓存和物理数据源的数据; -
Hibernate缓存分类:
Hibernate缓存包括两大类:Hibernate一级缓存和Hibernate二级缓存,Hibernate一级缓存又称为“Session的缓存”,它是内置的,不能被卸载(不能被卸载的意思就是这种缓存不具有可选性,必须有的功能,不可以取消session缓存)。由于Session对象的生命周期通常对应一个数据库事务或者一个应用事务,因此它的缓存是事务范围的缓存。第一级缓存是必需的,不允许而且事实上也无法卸除。在第一级缓存中,持久化类的每个实例都具有唯一的OID。 Hibernate二级缓存又称为“SessionFactory的缓存”,由于SessionFactory对象的生命周期和应用程序的整个过程对应,因此Hibernate二级缓存是进程范围或者集群范围的缓存,有可能出现并发问题,因此需要采用适当的并发访问策略,该策略为被缓存的数据提供了事务隔离级别。第二级缓存是可选的,是一个可配置的插件,在默认情况下,SessionFactory不会启用这个插件。 -
什么样的数据适合存放到第二级缓存中?
- 1 很少被修改的数据
- 2 不是很重要的数据,允许出现偶尔并发的数据
- 3 不会被并发访问的数据
- 4 常量数据
-
不适合存放到第二级缓存的数据?
- 1 经常被修改的数据
- 2 .绝对不允许出现并发访问的数据,如财务数据,绝对不允许出现并发
- 3 与其他应用共享的数据。
-
Hibernate查找对象如何应用缓存?
当Hibernate根据ID访问数据对象的时候,首先从Session一级缓存中查;查不到,如果配置了二级缓存,那么从二级缓存中查;如果都查不到,再查询数据库,把结果按照ID放入到缓存,删除、更新、增加数据的时候,同时更新缓存。Hibernate管理缓存实例无论何时,当你给save()、update()或saveOrUpdate()方法传递一个对象时,或使用load()、 get()、list()、iterate() 或scroll()方法获得一个对象时, 该对象都将被加入到Session的内部缓存中。 当随后flush()方法被调用时,对象的状态会和数据库取得同步。 如果你不希望此同步操作发生,或者你正处理大量对象、需要对有效管理内存时,你可以调用evict() 方法,从一级缓存中去掉这些对象及其集合。
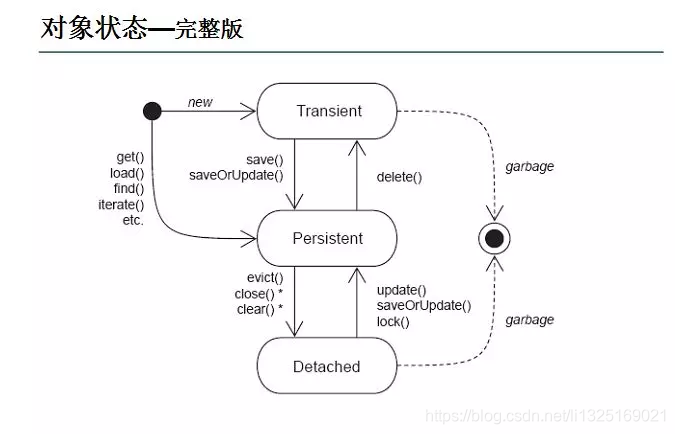
10、hibernate 对象有哪些状态?
hibernate里对象有三种状态:
- Transient 瞬时 :对象刚new出来,还没设id,设了其他值。
- Persistent 持久:调用了save()、saveOrUpdate(),就变成Persistent,有id
- Detached 脱管 : 当session close()完之后,变成Detached。
11、在 hibernate 中 getCurrentSession 和 openSession 的区别是什么?
原文链接:https://www.jianshu.com/p/14ee37576892
getCurrentSession() 和 openSession() 的区别:
- 采用getCurrentSession()创建的session会绑定到当前线程中(第一次调用时会创建一个Session实例,如果该Session未关闭,后续多次获取的是同一个Session实例),而采用openSession()创建的session则不会(每次打开都是新的Session,所以多次获取的Session实例是不同的)。
- 采用getCurrentSession()创建的session在commit或rollback时会自动关闭,而采用openSession()创建的session必须手动关闭。
spring 管理事务的话,如果要保证当前线程内只有一个 session,需要将 sessionFactory 传递给org.springframework.orm.hibernate3.HibernateTransactionManager,spring负责事务的开始,提交,回滚以及 session 的关闭,假设 spring 用于管理事务的 session 是(session1)。如果我还用 HibernateUtils.getCurrentSession() 方法获得 session 的话,得到的 session 却是(session2),和开始事务的 session 不是同一个对象,就造成 session2 的事务没有提交,对数据库的操作是无效的。
总结:
- 如果想让spring帮你管理事务,只能在 spring 中配置 SessionFactory。如果使用 hibernate 原有的 sessionFactory,则只能自己手动管理事务。
- 如果想使用 sessionFactory.getCurrentSession() 方法,必须配置 sessionFactory 和 jta 或 thread 绑定。但是h ibernate3.0 不支持与 thread 绑定,3.1 以上才支持。
- sessionFactory.getCurrentSession() 方法取得的 session,在做数据库操作时必须在事务中做,包括只读的查询,否则会报错。
注意:
在实际开发中,往往使用getCurrentSession多,因为一般是处理同一个事务(即是使用一个数据库的情况),所以在一般情况下比较少使用openSession或者说openSession是比较老旧的一套接口了。
12、hibernate 实体类必须要有无参构造函数吗?为什么?
是的。
Hibernate框架会调用这个默认构造方法通过反射来构造实例对象,即Class类的newInstance方法 ,这个方法就是通过调用默认构造方法来创建实例对象的 。
当查询的时候返回的实体类是一个对象实例,是Hibernate动态通过反射生成的。反射的Class.forName(“className”).newInstance()需要对应的类提供一个无参构造方法,必须有个无参的构造方法将对象创建出来,单从Hibernate的角度讲 他是通过反射创建实体对象的 所以没有默认构造方法是不行的,另外Hibernate也可以通过有参的构造方法创建对象。















 682
682











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









