







配置:anaconda3 + Pycharm
WordCloud
- 英文文本
- 导入第三方模块
from wordcloud import WordCloud # 词云图
import matplotlib.pyplot as plt #画图
- 实例化词云图对象
# wordcloud默认参数示例
text = 'I love python but I dont want to learn it '#
wc = WordCloud() # 实例化词云图对象
wc.generate(text) # 根据文本生成词云图
- 绘图
plt.imshow(wc) # 显示词云图
plt.show()
WordCloud() 词云图对象对应的画布默认长200像素,宽400像素,背景色为黑色。

- 中文文本
import matplotlib.pyplot as plt
from wordcloud import WordCloud
text = '我 爱 中国 我 爱 北京 天安门'#
wc = WordCloud() # 实例化词云图对象
wc.generate(text) # 根据文本生成词云图
plt.imshow(wc) # 显示词云图
plt.show()
import matplotlib.pyplot as plt
from wordcloud import WordCloud
text = '我 爱 中国 我 爱 北京 天安门' #
wc = WordCloud(font_path = 'C:\\Users\\THINKPAD\\PycharmProjects\\PDA\\simhei.ttf')
# font_path=" " 词云图的字体设置,需要进行下载
wc.generate(text) # 根据文本生成词云图
plt.imshow(wc) # 显示词云图
plt.show()

import matplotlib.pyplot as plt
from wordcloud import WordCloud
text = '我爱中国我爱北京天安门'#
wc = WordCloud( font_path = 'C:\\Users\\THINKPAD\\PycharmProjects\\PDA\\simhei.ttf')
wc.generate(text) # 根据文本生成词云图
plt.imshow(wc) # 显示词云图
plt.show()
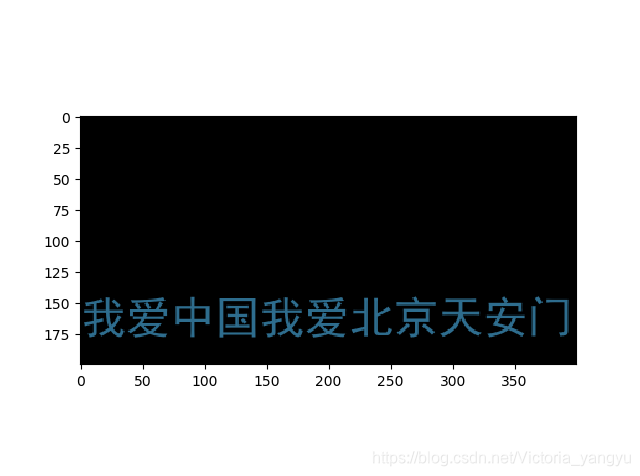
从上面几个小例子我们可以总结出:
- 绘制中文的词云图时一定要设置字体格式(
simhei.ttf),不然就会出现方框。 - 英文的词云图生成比较简单,直接可以使用
Wordcloud()的
generate()方法实现。英文文本单词之间按照空格断开的,因此英文文本可以直接划分,不需要分词。 语法为
WordCloud().generate(text) # Wordcloud类函数主要根据空格或者标点来进行划分和分词,因此可以直接生成英文的词云图
- 对于中文文本的词云图生成,由于不是空格来进行划分,所以需要进行先中文分词,再将其以空格连接,之后对其进行
WordCloud()的generate()函数,这样便可以实现中文文本的词云图的生成。 - 上面绘制的图片是基于wordCloud()的默认参数。如果想要美化词云图,可以参考 wordCloud()参数介绍,
wordCloud()参数官方介绍。
关于Jieba分词
那下面我们重点说说Jieba中文分词。
- 导入第三方模块
import jieba
import jieba.analyse
- 导入文本
常见的集中导入格式可以参考
a="程序设计语言是计算机能够理解和识别用户操作的一种交互体系,它可以按照规则组织计算机指令,是使得计算机进行目的的操作和实现"
- 任选一种分词形式进行分词并用空格进行分隔
b=jieba.lcut(a)#中文文本需要先进行文本分词,在进行空格分隔
newtext=" ".join(b)
print(newtext)
Jieba中文分词 +绘制词云图
在现实中,我们可能通处理多条中文文本。
- 导入第三方模块
import matplotlib.pyplot as plt
from wordcloud import WordCloud
import jieba
- 导入文档并中文分词实现空格分隔
s1 = """ 在克鲁伊夫时代,巴萨联赛中完成了四连冠,后三个冠军都是在末轮逆袭获得的。
在91/92赛季,巴萨末轮前落后皇马1分,结果皇马客场不敌特内里费使得巴萨逆转。
一年之后,巴萨用几乎相同的方式逆袭,皇马还是末轮输给了特内里费。
在93/94赛季中,巴萨末轮前落后拉科1分。
巴萨末轮5比2屠杀塞维利亚,拉科则0比0战平瓦伦西亚,巴萨最终在积分相同的情况下靠直接交锋时的战绩优势夺冠。
神奇的是,拉科球员久基奇在终场前踢丢点球,这才有了巴萨的逆袭。"""
s2 = """ 巴萨上一次压哨夺冠,发生在09/10赛季中。末轮前巴萨领先皇马1分,只要赢球就将夺冠。
末轮中巴萨4比0大胜巴拉多利德,皇马则与对手踢平。
巴萨以99分的佳绩创下五大联赛积分纪录,皇马则以96分成为了悲情的史上最强亚军。"""
s3 = """在48/49赛季中,巴萨末轮2比1拿下同城死敌西班牙人,以2分优势夺冠。
52/53赛季,巴萨末轮3比0战胜毕巴,以2分优势力压瓦伦西亚夺冠。
在59/60赛季,巴萨末轮5比0大胜萨拉戈萨。皇马巴萨积分相同,巴萨靠直接交锋时的战绩优势夺冠。"""
mylist = [s1, s2, s3] #用列表存储
word_list = [" ".join(jieba.cut(sentence)) for sentence in mylist] #依次处理每一条文本 用列表存储分完词的字符串
new_text = ' '.join(word_list)
- 实例词云图并绘制
wc= WordCloud(font_path= 'C:\\Users\\THINKPAD\\PycharmProjects\\PDA\\simhei.ttf').generate(new_text)
plt.imshow(wc) # 词云图的两种显示方式:w.to_file()和
plt.axis("off")
plt.show()
参考:
下面两个连接帮助我完成了自己的代码。链接1帮助我弄清楚中文用空格分词对绘制词云图的重要性以及面对多条文档时,处理文本的逻辑。链接2 教会了我除了基于文本的词云图绘制还有基于词频的词云图绘制。
1、帮助理清中英文文本画词云图的区别
2、中文分词去除停用词和空字符串、基于TFIDF的结果画出词云图
引申思考:目前自己绘制的词云图有两个方面的问题。
- 在给定情境下,一些词语是不能分开的,要给定自己的词典。
- 另一方面,很多程度副词的词频也很大,这与中文的表达习惯有关。要去除这些情感词。
案例
# -*-coding: utf-8 -*-
# encoding=utf-8
import pandas as pd
import jieba
import jieba.analyse
import matplotlib.pyplot as plt
from wordcloud import WordCloud, STOPWORDS, ImageColorGenerator
import jieba.posseg as pseg
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.feature_extraction.text import CountVectorizer
# 读取数据
input_path = "C:\\Users\\THINKPAD\\PycharmProjects\\PDA\\Business_UTF8.csv" #数据格式是按列存储的1500条酒店评论数据
inputs = pd.read_csv(input_path, sep = '\t', header = None, encoding = 'UTF-8')
# 分词并去除停用词
stopwords = set()
fr = open('C:\\Users\\THINKPAD\\PycharmProjects\\PDA\\cn_stopwords.txt', encoding = 'UTF-8')
for word in fr:
stopwords.add(str(word).strip())
fr.close()
word_list = [" ".join(jieba.cut(sentence)) for sentence in inputs[0]] #从数据框读取每一条文本
word_list = list(filter(lambda x: x not in stopwords, word_list)) # 过滤掉停用词
word_list = [str(i) for i in word_list if i != ' '] #过滤掉空字符串
word_list = ' '.join(word_list) #按空格分隔把每一天的分词结果连接成一个超长超长的字符串
tlist = [word_list] # 分词列表 将字符串转换为列表
# Tfidf 算法
vectorizer = CountVectorizer() # 该类会将文本中的词语转换为词频矩阵,矩阵元素a[i][j] 表示j词在i类文本下的词频
transformer = TfidfTransformer() # 该类会统计每个词语的tf-idf权值
tfidf = transformer.fit_transform(vectorizer.fit_transform(tlist)) # 第一个fit_transform是计算tf-idf,第二个fit_transform
# 是将文本转为词频矩阵
word = vectorizer.get_feature_names() # 获取词袋模型中的所有词语
weight = tfidf.toarray() # 将tf-idf矩阵抽取出来,元素a[i][j]表示j词在i类文本中的tf-idf权重
tfidf_list = {}
for i in range(len(weight)): # 打印每类文本的tf-idf词语权重,第一个for遍历所有文本,第二个for便利某一类文本下的词语权重
for j in range(len(word)):
tfidf_list[word[j]] = weight[i][j]
# 使用WordCloud生成词云
wc = WordCloud(font_path = 'C:\\Users\\THINKPAD\\PycharmProjects\\PDA\\simhei.ttf') # 按照默认参数绘制词云图,可以设置参数进一步美化
wc.generate_from_frequencies(tfidf_list)
# 运用matplotlib展现结果
plt.imshow(wc) # 显示词云图
plt.axis("off")
plt.show()

可以看出来图很丑。表示情感态度词还挺多,如果想从评论中获得顾客关于酒店特征的词,应该还要再进一步处理分词列表。
这写得也很好
# -*-coding: utf-8 -*-
# encoding=utf-8
import pandas as pd
import jieba
import jieba.analyse
import matplotlib.pyplot as plt
from wordcloud import WordCloud, STOPWORDS, ImageColorGenerator
import jieba.posseg as pseg
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.feature_extraction.text import CountVectorizer
# 读取数据
input_path = "C:\\Users\\THINKPAD\\PycharmProjects\\PDA\\Business_UTF8.csv"
inputs = pd.read_csv(input_path, sep = '\t', header = None, nrows = 1500, encoding = 'UTF-8')
# 给出停用词词表
stopwords = set()
fr = open('C:\\Users\\THINKPAD\\PycharmProjects\\PDA\\cn_stopwords.txt', encoding = 'UTF-8')
for word in fr:
stopwords.add(str(word).strip())
fr.close()
# 分词并标注词性
word_list = []
for sentence in inputs[0]:
seg = jieba.posseg.cut(sentence)
for i in seg:
word_list.append((i.word, i.flag))
# 删除停用词
for each in word_list:
if each[0] in stopwords or each[0] is None:
word_list.remove(each)
else:
pass
# 删除停用词后的名词词表
tlist = []
for each in word_list:
if each[1] == 'n' or each[1] == 'v' or each[1] == 'a':
tlist.append(each[0])
# Tfidf 算法
vectorizer = CountVectorizer() # 该类会将文本中的词语转换为词频矩阵,矩阵元素a[i][j] 表示j词在i类文本下的词频
transformer = TfidfTransformer() # 该类会统计每个词语的tf-idf权值
tfidf = transformer.fit_transform(vectorizer.fit_transform(tlist)) # 第一个fit_transform是计算tf-idf,第二个fit_transform
# 是将文本转为词频矩阵
word = vectorizer.get_feature_names() # 获取词袋模型中的所有词语
weight = tfidf.toarray() # 将tf-idf矩阵抽取出来,元素a[i][j]表示j词在i类文本中的tf-idf权重
tfidf_list = {}
for i in range(len(weight)): # 打印每类文本的tf-idf词语权重,第一个for遍历所有文本,第二个for便利某一类文本下的词语权重
for j in range(len(word)):
tfidf_list[word[j]] = weight[i][j]
# 使用WordCloud生成词云
wc = WordCloud(font_path = 'C:\\Users\\THINKPAD\\PycharmProjects\\PDA\\simhei.ttf') # 词云图的背景颜色
wc.generate_from_frequencies(tfidf_list)
# 运用matplotlib展现结果
plt.imshow(wc) # 显示词云图
plt.axis("off")
plt.show()

累了 哪里出问题了














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









