




目录
1.使用b表的100条数据循环与a表的1000000条数据去匹配,需要匹配100次a表
2.使用a表的1000000条数据循环与b表的100条数据去匹配,需要匹配1000000次b表
一.先说结论
当B表的数据集小于A表数据集时,用in优于exists。
select id from A where id in (select id from B)当A表的数据集小于B表的数据集时,用exists优于in。
select id from A where exists (select id from B where A.id = B.id)可以这么理解:in后面跟的是小表,exists后面跟的是大表
select * from A where id in (select id from B)也可以写成
select id from B bleft joinselect id from A a where a.id = b.id二.原理
首先,我们需要了解数据库的小表驱动大表。
假设 a表1000000数据,b表100数据,这里有两个过程,b 表数据最少,查询引擎优化选择b为驱动表,循环b表的100条数据,跟a表的1000000数据去匹配,这个匹配的过程是B+树的查找过程,比循环取数要快的多。
已知:数据库存储结构用的B+树形结构,时间复杂度为O(logN),表数量越大,越趋近于一个固定值。
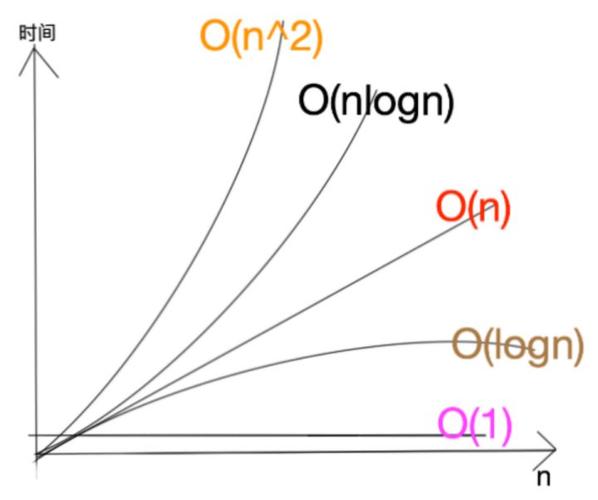
1.使用b表的100条数据循环与a表的1000000条数据去匹配,需要匹配100次a表
由于a表数据较多,所以将趋近于一个具体值,假设复杂度具体值为10,则b表查询100次的复杂度为1000;
2.使用a表的1000000条数据循环与b表的100条数据去匹配,需要匹配1000000次b表
由于b表数据较少,所以会是一个上升状态的值,假设复杂度具体值为1,则a表查询1000000次的复杂度为1000000;
可以通过简单的例子看的出来,小表驱动大表的重要性。
需要注意的是a表字段id和b表字段id 都要建立索引。
三.最后总结
小表驱动大表,in后面跟的是小表,exists后面跟的是大表。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









