







目录
一、前要
在 汇编翻译网址中,左侧是C语言,右侧是汇编语言。一条i++指令,翻译成汇编有三条(黄色底纹)
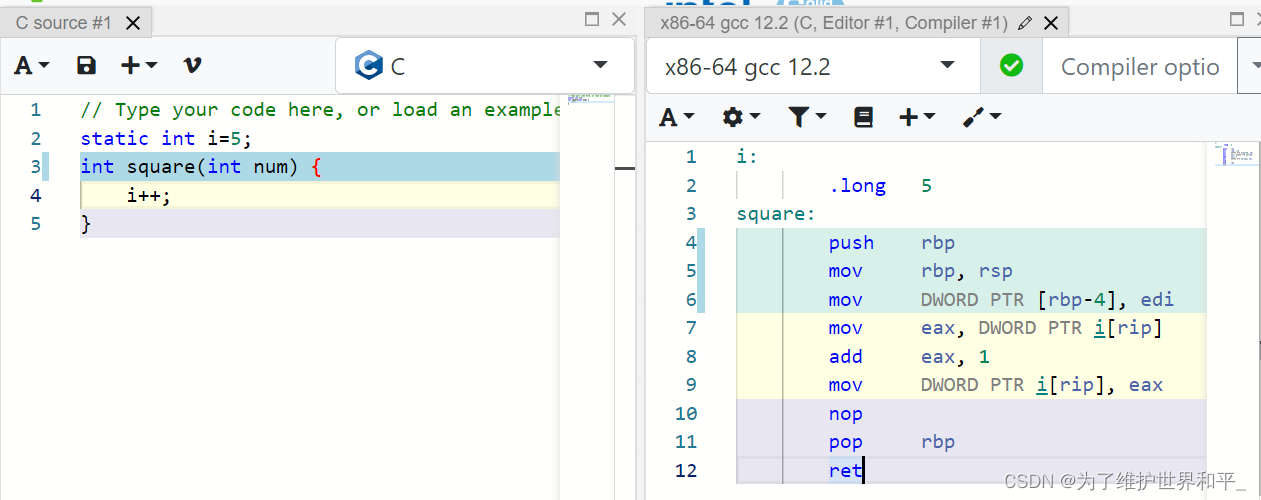
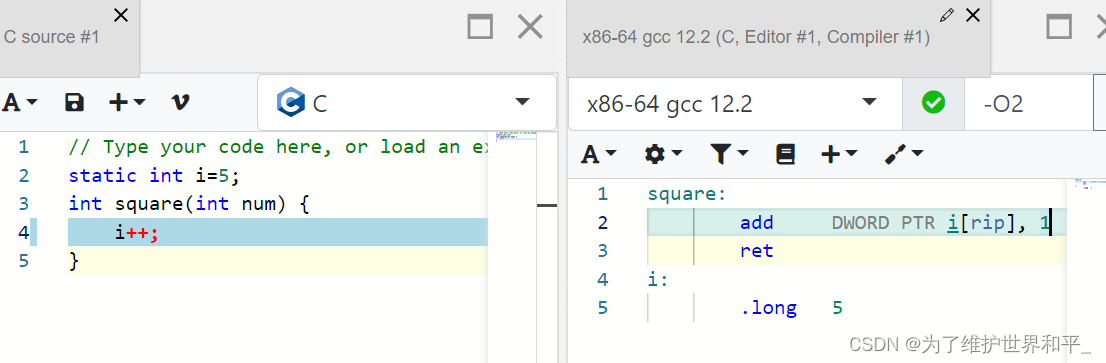
在使用O2优化后,一条i++指令,只有一条汇编指令。
总结:
翻译译成3条指令,需要加锁;-O2优化后,一条指令不需要加锁,本身就是原子的。
事先不知道用什么优化选项,所以需要加锁保护数据原子执行。
临界区:代码路径能够被并行执行,可以共享写数据;
临界区的资源需要保护:也就是说,它必须以相互排斥的方式单独运行/序列化/运行;
二、识别和保护代码中的临界部分
1、比较安全的情况
- 局部变量,在线程私有栈上分配的内存空间;
- 只读的变量;
- 共享写变量不会运行在其他上下文中;
2、竞争的环境
- SMP架构,多核架构
- 竞争的内核
- 阻塞的I/O
- 硬件中断
写程序时如何正确的使用锁
锁的粒度:在大项目中,使用太少的锁是个问题。导致性能问题,拥有大量锁实际上对性能有好处,对复杂度不友好。在项目中,使用一个锁保护一个全局变量是比较典型的用法。
3、锁的顺序
- 必须使用相同顺序
- 避免循环锁的使用
- 防止饥饿产生,有加锁,很快就要有解锁
简单化:
- 避免复杂化或过度设计,尤其关于复杂场景设计的锁
4、死锁场景发生
- 单个锁,进程上下文:尝试两次获取相同的锁,导致死锁
- 多个锁,进程上下文:
在CPU0,线程A获取锁A,同时想获取锁B;并发性的,在CPU1线程B获取锁B,同时想获取锁A,导致AB-BA死锁。进一步扩展,可能是AB-BC-CA循环依赖的死锁。
- 单个锁,进程与中断上下文
锁A发生在中断上下文中:如果中断发生,中断处理函数尝试获取锁A,导致死锁。因此,在中断上下文中获取的锁必须始终在禁用中断的情况下使用。
- 更加复杂的情况,多锁,多进程和中断上下文中:
遵循锁的顺序:获取-释放。复杂的场景导致死锁,可以使用lockdep来检测。
三、如何选择spinlock mutex
1、考虑等待的时间
mutex lock 是睡眠锁,在等待锁时将睡眠,再锁被释放后,内核唤醒等待的进程运行;
spinlock 是不睡眠,一直轮询等待;
睡眠唤醒上下文切换开销,轮询也有开销,比较其时间大小。
2、理论上决定使用哪种锁
- 花在临界区的时间 t1 = t3-t2
- 上下文切换的时间 t2,那么最小的花费在mutex lock/unlock的时间 是 2 * t2
2 * t2 > t1
结论
如果临界区等待的时间小于两次上下文切换的时间,使用mutex是不对的,开销太大;
在临界区的时间很小,非阻塞的临界区,使用spinlock比mutex优越;
3、如何决定使用哪种锁
实际上,如何计算上述的两个时间是不现实的。
一般来说:
- 使用spinlock 临界区资源运行在原子(中断)上下文,或者在进程上下文,不能睡眠
- 使用mutex lock 临界区运行在进程上下文并可以睡眠。
- 当然,使用spinlock考虑比mutex开销低,可以再进程上下文中使用spinlock
那么如何区分程序运行的进程、中断上下文呢?使用PRINT_CTX()宏
if(in_task())
In process contex
else
Atomic or interrput contex
四、mutex lock
1、可中断睡眠和不可中断睡眠
在人机交互应用程序中,一般的经验,通常应该将进程置于可中断的睡眠状态。
此外,不可中断状态的睡眠更多一些,必须无限期阻塞等待,任务不能打断阻塞的等待。
mutex_lock()是不可打断的, muten_lock_interruptible()是可以打断的;前者的速度快一些,用在临界区非常短的条件下
2、忙碌等待,测试锁可用性
mutex_trylock(struct mutex *lock)
返回值 1 :锁可用获取到 0: 还在竞争中
3、信号量与mutex
down_[interruptible]
up()
4、互斥锁与信号量的不同
- 信号量是互斥体的更广义形式;互斥锁可以只获取一次(随后释放或解锁),而信号量可以多次获取(并随后释放)。
- 互斥体用于保护关键部分不被同时访问;而信号量应用作一种机制,以向另一个等待任务发出信号(通常,生产者任务通过信号量对象发布信号,消费者任务正在等待接收该信号,以便继续进一步的工作)。
- 互斥锁具有所有权的概念,只有所有者上下文才能执行解锁;二进制信号量没有所有权。
五、spinlock
头文件 <linux/spinlock.h>
动态申请
spinlock_t lock
spin_lock_init(&lock)
静态申请
DEFINE_SPINLOCK(lock)
基本用法
void spin_lock(spinlock_t *lock);
<critical section>
void spin_unlock(spinlock *lock);
锁中睡眠检测
内核配置:CONFIG_DEBUG_ATOMIC_SLEEP
spin_lock()
schedule_timeout();
spin_unlock()其内部引起schedule()
[ 405.049171] BUG: scheduling while atomic: rdwr_test_secre/895/0x00000002
[ 405.049935] Modules linked in: miscdrv_rdwr_spinlock(OE)
[ 405.053302] CPU: 1 PID: 895 Comm: rdwr_test_secre Tainted: G OE 5.0.0+ #13
[ 405.054026] Hardware name: linux,dummy-virt (DT)
[ 405.054740] Call trace:
[ 405.055790] dump_backtrace+0x0/0x528
[ 405.056319] show_stack+0x24/0x30
[ 405.056726] __dump_stack+0x20/0x2c
[ 405.057021] dump_stack+0x25c/0x388
[ 405.057292] __schedule_bug+0x1d4/0x214
[ 405.057604] __schedule+0x1d8/0x2214
[ 405.057820] schedule+0x4e8/0x790
[ 405.058143] schedule_timeout+0x1bd0/0x1c44
[ 405.060645] write_miscdrv_rdwr+0x1228/0x1bc8 [miscdrv_rdwr_spinlock]
[ 405.061225] __vfs_write+0x54/0x90
[ 405.061935] vfs_write+0x16c/0x2f4
[ 405.062423] ksys_write+0xb4/0x164
[ 405.065050] __se_sys_write+0x48/0x58
[ 405.065653] __arm64_sys_write+0x40/0x48
[ 405.066150] __invoke_syscall+0x24/0x2c
[ 405.066533] invoke_syscall+0xa4/0xd8
[ 405.067189] el0_svc_common+0x100/0x1e4
[ 405.068025] el0_svc_handler+0x418/0x444
[ 405.068582] el0_svc+0x8/0xc六、锁与中断
硬中断优先级最高,能抢占任何资源
问题在于中断处理程序与read方法在做什么,以及实现方式,有以下三种情景:
- 中断处理程序仅仅使用局部变量,即使read方法在临界区,没有竞争关系。
- 中断处理程序正在处理(全局)共享的可写数据,但不处理read方法正在使用的数据项。
- 中断处理程序正在处理read方法正在使用的相同全局共享可写数据,存在数据竞争,需要锁。
第3种方法需要使用spinlock锁,从下图可以看到数据的竞争关系。

可能死锁
- 无论单处理器还是多处理器,解决这个中断数据竞争的方法,使用_irq 的spinlock的API
void spin_lock_irq(spinlock_t *lock);
其内部禁止中断(本处理器上),使得通过中断产生数据竞争是不可能的。
- 考虑中断状态位,在禁止中断再开启后,中断状态位不能改变。如果不进行对中断位进行恢复,中断标志全部变成1了。
unsigned long spin_lock_irqsave(spinlock_t *lock, unsigned long flags); - 在tasklet或softirq 下半部中断机制使用,
spin_lock_bh(spinlock_t *lock)它可以禁用本地处理器上的中断,使用自旋锁,从而保护关键部分。
总结:
| 最简单,低开销 | spin_lock()/spin_unlock | 在进程上下文保护临界资源 |
| 中等开销 使用中断禁用 | spin_lock_irq()/spin_unlock_irq() | 在中断发生时,进程和中断上下文有资源竞争 |
| 高开销 最安全 | spin_lock_irqsave()/spin_unlock_irqsave() | spinlock 保存与恢复中断掩码 |
5.8内核中引入 local lock















 2544
2544











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











