







副本管理器针对生产请求和l拉取请求都有一个全局的延迟缓存,生产请求对应延迟缓存中存储了延迟的生产(DelayedProduce),拉取请求对应延迟缓存中存储了延迟的拉取(DelayedFetch)。Kafka的延迟缓存数据结构(DelayedOperatlonPurgatory)和上一节的Purgatory类似。下面的代码片段以延迟的生产和拉取为例,列举了副本管理器中,与延迟缓存、延迟操作相关的方法:

延迟缓存除了管理延迟操作,还要从分区角度尝试完成延迟的操作,延迟缓存主要有下面两个方法。
- tryCompleteElseWatch()方法。尝试完成延迟的操作,如果不能完成,将延迟操作加入延迟缓存中。一旦将延迟操作加入延迟缓存的监控,延迟操作的每个分区都会监视该延迟操作。
- checkAndComplete()方法。它的参数不是延迟操作对象,而是延迟缓存的键(分区)。外部事件调用该方法,根据指定的键(分区),尝试完成延迟缓存中的延迟操作。
注意:本章分析的延迟生产和延迟拉取,在豆豆迟缓存中的键都是分区,但延迟缓存的键并不一定就是分区。比如上一幸延迟的加入和延迟的心跳,在延迟缓存中的键分别是消费组和消费者编号,而不是分区。
- 监视延迟操作
服务端创建的延迟操作有多个分区,在加入到延迟缓存时,每个分区都对应相同的延迟操作。服务端在刚创建延迟操作时,因为没有满足条件,所以才会创建延迟的操作。以6.3.2节“4.延迟生产的示例”为例,服务端处理生产请求,将消息集写到分区[凹,凹,P3],并创建了延迟的生产。服务端将延迟的生产加入到延迟缓存中,正常的结果是[Pl->DelayedProduce,PZ->DelayedProduce,P3->DelayedProduce]。但如果在加入的过程中,延迟的生产满足了条件,即3个分区的备份副本都同步了主副本的消息,那么服务端就不需要再监控这个延迟的操作了。比如服务端将Pl->DelayedProduce加入延迟缓再后,延迟的生产可以完成,那么剩下的[PZ->DelayedProduce,P3->DelayedProduce]就不会被1111入延迟缓存了。
延迟缓存的tryCoMpleteElseWatch()方法将延迟操作加入延迟缓存之前,会先尝试一次完成延迟的操作。如果不能完成,才会调用watchForOperation()方法将延迟操作加入到分区对应的监视器(Watchers)。在这之后,还会再次尝试一次完成延迟的操作,如果还不能完成,才会将延迟操作加入定时帮(Timer)。相关代码如下:


延迟操作不仅存在于延迟缓存中,还会被定时器监控。延迟操作在延迟缓存中的生命周期分别与外部事件、定时持有关。下面两点解释了延迟操作在延迟缓存中的生命周期。
- 将延迟操作加入延迟缓存,目的是让外部事件有机会尝试完成延迟的操作。当满足条件,可以完成延迟操作H才,服务端才会返回响应结果给客户端,并将延迟操作从延迟缓存中删除。
- 将延迟操作力[I入定时器,目的是在延迟操作超时后,服务端可以强制返回响应结果给客户端。注意:延迟缓存的作用是:外部事件可以根据分区,尝试完成监视器的所有延迟操作。定时器的作用是:在延迟操作超时后,强制完成延迟的操作。两者都保存了延迟操作,但前者有分区,后者没有分区。被定时器监控的延迟操作,并不需要分区,因为定时器与分区无关。
- 监视器
延迟缓’存的每个键都有一个监视器,它管理了链表结构的延迟操作。外部事件发生时,会给定一个键,然后i用用这个健对应监视器的tryCompleteWatched()方法,尝试完成监视器中所有的延迟操作。监视器尝i式完成所有延迟操作的过程中,会调用每个延迟操作的tryComplete()方法,判断能否完成延迟的操作。如果某个延迟操作能够完成,贝lj将对应的延迟操作从链表中移除。相关代码如下:


6.3.2节提到,外部事件根据指定分区尝试完成延迟的操作。如果延迟操作可以完成,只会从延迟缓存中删除这个分区中已经完成的延迟操作,并不会删除其他分区中已经完成的延迟操作。监视器的purgeC0111pleted()方法会清理所有已经完成的延迟操作,这个方法会被清理线程调用。
如图6-64所示,以6.3.2节的延迟拉取为例,外部事件尝试完成分区凹的延迟操作,可以完成DelayedFetch2和DelayedFetch4,它们会立即从延迟缓存中删除。另外,定时的清理线程会检查所有的监视器,在检查到DelayedFetch2和DelayedFetch4时,才会将其从分区P2和分区内的监视器中移除。
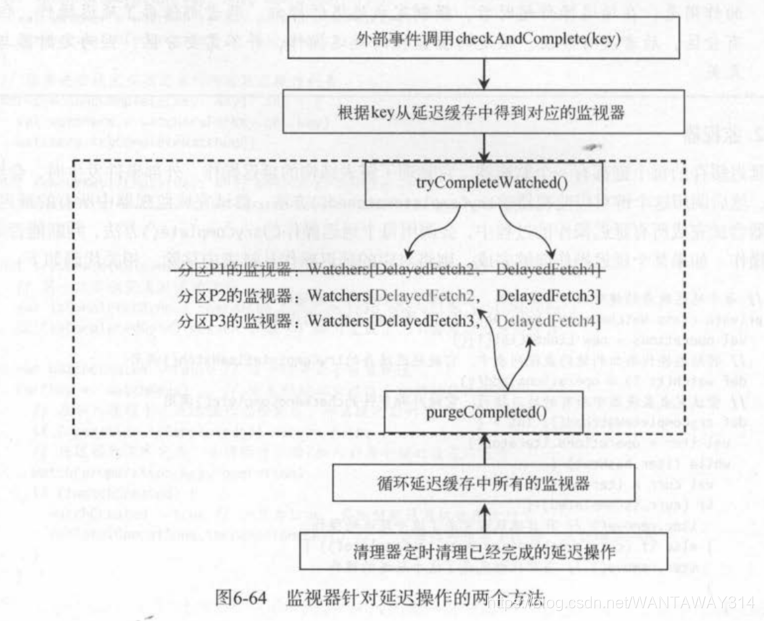
下面对比了监视器尝试完成延迟的操作、清理已完成的延迟操作两个方法的不同点。
- 尝试完成时会先判断延迟操作是否已经完成,如果没有,则调用每个延迟操作的tryComplete()方法。这两者的返回值只要是true,就会删除当前的延迟操作。
- 清理已完成的延迟操作,并不会调用延迟操作的tryComplete()方法,而是直接判断延迟操作是否已经完成,如果是,则从监视器中删除当前的延迟操作。
- 清理线程
清理线程的作用是清理所有监视器中已经完成的延迟操作。它作为延迟缓存的内部类,需要访问延迟缓存的watchersForKey成员变量才能正常地展开工作。另外,清理器每次运行时都会增加定时器的时钟。下面列汁1了清理器与延迟缓存、定时器相关的代码:

延迟缓存的tryCompleteElseWatch()方法在将延迟操作加入指定键的监视器后,会增加esti~时edTotalOperations计数器,并往定时器的延迟队列中添加延迟的操作。清理线程的运行方法根据计数器的值减去定时器的大小(delayed变量),正常来看这个差距会等于零。
但实际上,清理器在运行时会先调用定时器的advanceClock()方法,将定时器的时钟往前移动一次。定时器在运行时,如果延迟的操作超时了,就会将延迟操作从定时器的延迟队列中移除。一旦延迟操作从定时器中删除,定时器的大小就会减少,那么计数器减去定时器的大小就会大于零。最后,清理线程就会满足“差距大于purgeinterval这个条件”,开始清理延迟缓存中所有的监视器。
- 定时器
Kafka服务端创建的延迟操作(DelayedOperation)会作为一个定时任务(TifilerTask),加入定时器(T"imer)的延迟队列(DelayQueue)。当延迟操作超时后,定时器会将延迟操作从延迟队列中弹:-H,并调用延迟操作的运行方法,强制完成延迟的操作。
定时器使用“延迟队列”管理服务端创建的所有延迟操作,延迟队列的每个元素是定时任务列表(TimerTaskli.st),一个定时任务列表可以存放多个定时任务条目(Ti.merTaskEntry)。服务端创建的延迟操作对象,会先包装成定时任务条目,然后才会加入延迟队列指定的一个定时任务列表。“延迟队列”是定时器中保存“定时任务列表”的全局数据结构,但服务端创建的“延迟操作”不是直接加入“定时任务列表”,而是加入到“时间轮”(Ti.mi.ngWheel),延迟队列和时间轮之间的关系如下。
列中。
(2)超时的定时任务列表会被延迟队列的poll()方法弹:-H。定时任务列表超时并不一定表示定时任务超时,将定时任务重新加入时间轮,如果加入失败,说明定时任务的确超时,通过钱程池执行任务。
(3)执行延迟操作对应的定时任务,只在定时器的addTi.merTaskEntry()方法f~I调用。所以在advanceClock()方法中将定时任务列表从延迟队列中弹出后,调用定时任务列表的flush()方法将所有的定时任务重新加入时间轮,这样才有机会执行超时的定时任务。
(4)延迟队列的poll()方法只会弹出超时的定时任务列表,队列中的每个元素按照超时时间排序,如果第一个定时任务列表都没有过期,那么其他定时任务歹lj表也一定不会超时。假设调用advanceClock()方法时,第一次调用延迟队列的poll()方法会弹II\一个超时的定时任务列表,第二次调用延迟队列没有参数的poll()方法没有超时的定时任务列表,就不会再弹州定时任务列表了。
定时器的相关代码如下:


注意:延迟操作本身的失效时间(expirationMs)等于客户端请求设直的延迟时间(delayMs)加上当前时间,它是一个绝对的时间戳。比如客户端请求设置的延这时间是10秒,当前时间是2017-1-110:00:00,那么延迟操作的失效时间等于2017-1-110:00:10。Java的延迟队列是一个基于时间的优先级队列,延迟队列的元素(即每个定时任务列表)都有一个失效时间,这个失效时间也是一个绝对的时间截。不过,定时任务列表在实现Delayed接- 的getDelay()方法,则妥将绝对的失效时间减去当前时间,表示定时任务列表在多长时间之后会过期。当getDelay()方法返回值小于等于零时,就表示定时任务列表已经过期,需妥立即衫t-1于。
时间轮类似于一个环形缓冲区,不同的是,加入环形缓冲区的数据只能顺序加入,而加入时间轮的数据可以不按顺序加入。并且,如果当前时间轮放不下加入的数据时,它会创建一个更高层的时间轮。第一层时间轮的tickMs=l表示一格的长度是l毫秒,wheelSize=20表示一共20格,它的范围是20毫秒。第二层时间轮的tickMs=20表示一格的长度是20毫秒,它的范围是400毫秒。如图6-65所示,假设有5个定时任务,它们的超时时间分别是[8,8,25,3日,35]。前2个定时任务会加入到第一个时间轮的第八个桶,后3个定时任务会加入到第二个时间轮的第一个桶中。
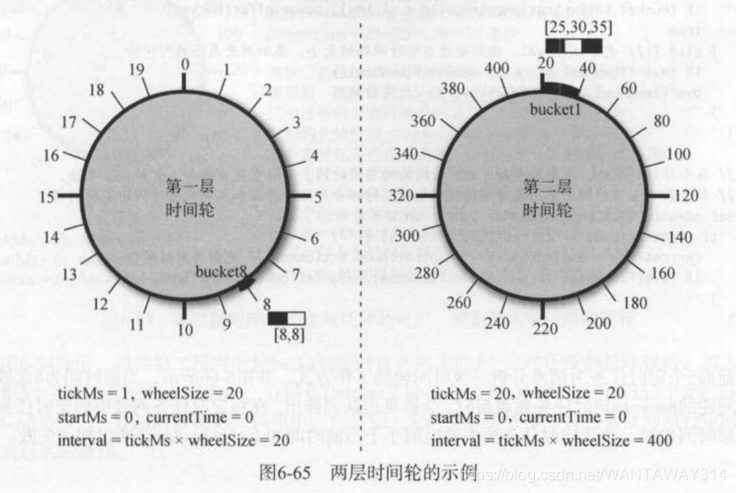
定时器只持有第一层时间轮的引用,并不会持有其他更高层的时间轮。比如上面的示例中,第一层时间轮会持有第二层时间轮的引用,如果还有第三层时间轮,则第二层时间轮会持有第三层时间轮的引用定时器将定时任务加入当前时间轮,要判断定时任务的失效时间是再在当前时间轮的范围内。如果不在当前时间轮的范围内,则要将定时任务上升到更高一层的时间轮中。相关代码如下:

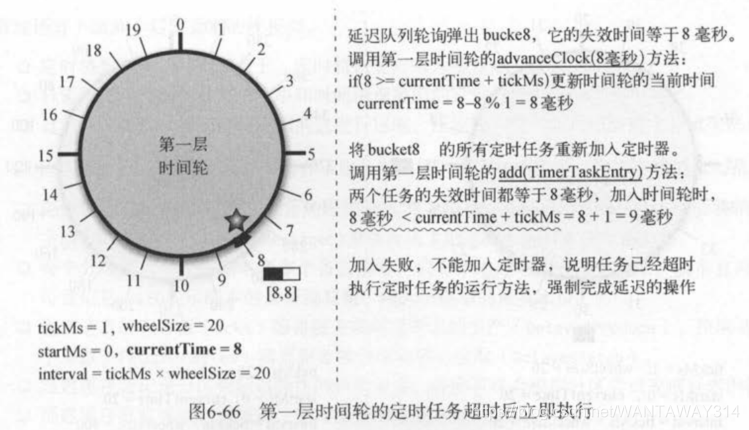
以前面5个定时任务为例来分析层级时间轮的工作方式。如图6-66所示,当前时间为8毫秒时,第一层时间轮的buckets定时任务列表超时,会被延迟队列弹出。在将定时任务列表中的定时任务重新加入第一层时间轮时,由于定时任务的失效时间小于当前时间加上tickMs=lr怡,所以加入失败。
如图6-67所示,当前时间为20毫秒时,第二层时间轮的bucketl定时任务列表超时,也会被延迟队列弹:1:\。不同的是:在将定时任务列表中的定时任务重新加入第一层时间轮时,3个定时任务都还没有失效。并且,它们都在第一层时间轮的范围内,所以允许重新加入定时器的第一层时间轮中。

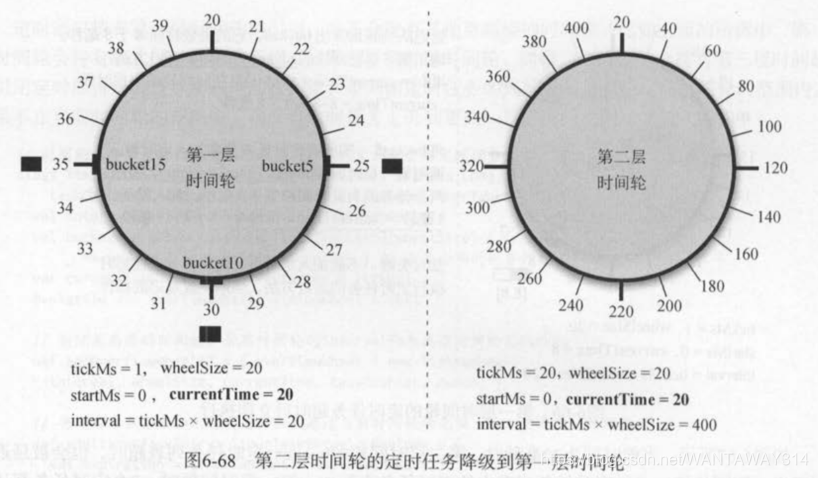
如图6-68所示,最终第二层时间轮bucketl定时任务列表的3个定时任务都被降级后,加入到第一层时间轮3个不同的定时任务列表中,分别是[bucket5,bucket10,bucket10]。后续这3个定时任务的执行和图6-66类似,一旦超时被延迟队列弹出,再次加入定时器就会失败,并且会立即执行定时任务,强制完成延迟的操作。
本节分析了延迟操作在延迟缓存和定时器中的生命周期,外部事件尝试完成延迟缓存中的延迟操作,定时器会在延迟操作失效后强制完成延迟操作。清理器会定期地删除延迟缓存中已经完成的延迟操作。
6.4 小结
本章主要分析了日志存储、日志管理、副本管理器的具体实现。下面分别总结这3个知识点的一些要点。日志存储会将消息集写到底层的日志文件,它的主要概念有以下几点。
- 一个日志(Log)有多个日志分段(LogSegment)。每个日志分段由数据文件(FileMessageSet)和索引文件(Offsetindex)组成。
- 偏移量是消息最重要的组成部分。每条消息写入底层数据文件,者IS会有一个递增的偏移量。
- 索引文件保存了消息偏移量到物理位置的映射关系,但并不是保存数据文件的所有消息,而是间隔一定数量的消息才保存一条映射关系。索引文件保存的偏移量是相对偏移盐,数据文件中每条消息的偏移量是分区级别的绝对偏移量。
- 存储索引文件的条目时,将绝对偏移量减去日志分段的基准偏移盐。查询索引文件返回的相对偏移量要加上基准偏移量,才能用于查询数据文件。
- 客户端每次读取数据文件,服务端都会创建一个文件视图,文件视图和底层数据文件共用一个文件通道,但拥有不同的开始位置和结束位置。
- 服务端返回文件视图给客户端,采用零拷贝技术,将底层文件通道的数据直接传输到网络通道。
日志管理器(LogMa_!1ager)管理了服务端的所有日志,除了上面对日志的追加和读取操作外,日志管理还有下面几个后台管理的线程类。
- 定时将数据文件写到磁盘上、定时将恢复点写入检查点文件。
- 日志清理线程根据日志的大小和时间清理最旧的日志分段。
- 日志压缩线程将相同键的不同消息进行压缩,压缩线程将日志按照清理点分成头部和尾部。
副本管理然(ReplicaManager)保存了服务端的所有分区,并处理客户端发送的读写请求。
- 副本管理器处理读写请求,会先操作分区的主副本。appendMessages()方法会将消息集写入主副本的本地臼志,fetchMessage()方法会从主副本的本地日志读取消息集。
- 每个分区都有一个主副本和多个备份副本,只有本地副本才有日志对象。副本有两个重要的位置信息:LEO表示副本的最新偏移量,HW表示副本的最高水位。
- 生产请求的应答值(acks)需要服务端创建延迟的生产(DelayedProduce),拉取请求的最少字节数(fetchMinBytes)需要服务端创建延迟的拉取(DelayedFetch)。
- 延迟缓存会记录分区到延迟操作的映射关系,外部事件会根据分区尝试完成延迟的操作。
- 延迟缓存有监视器、清理器、定时器协调完成延迟的操作。
在0.8版本以前,Kafka并没有日志复制的特性,因此一旦消息代理节点挂掉,这个节点上的数据就会丢失。在0.8版本以后,Kafka提供了日志的副本机制,虽然只有主副本可以响应数据的读写请求,但是备份副本会向主副本中及时地同步数据。这样,当主副本挂掉后,备份副本就可以选举出新的主副本,并继续响应客户端的读写请求。下一章我们来分析服务端如何实现副本的复制特性。















 96
96











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











