







应用服务器就是处理网站业务的服务器,网站的业务代码都部署在这里,是网站开发最复杂,变化最多的地方,优化手段主要有缓存、集群、异步等。
1 分布式缓存
回顾网站架构演化历程,当网站遇到性能瓶颈时,第一个想到的解决方案就是使用 缓存。在整个网站应用中,缓存几乎无所不在,既存在于浏览器,也存在于应用服务器 和数据库服务器;既可以对数据缓存,也可以对文件缓存,还可以对页面片段缓存。合 理使用缓存,对网站性能优化意义重大。
网站性能优化第一定律:优先考虑使用缓存优化性能。
- 缓存的基本原理
缓存指将数据存储在相对较高访问速度的存储介质中,以供系统处理。一方面缓存访 问速度快,可以减少数据访问的时间,另一方面如果缓存的数据是经过计算处理得到的, 那么被缓存的数据无需重复计算即可直接使用,因此缓存还起到减少计算时间的作用。
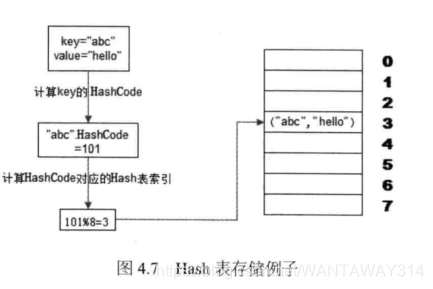
缓存的本质是一个内存Hash表,网站应用中,数据缓存以一对Key、Value的形式 存储在内存Hash表中。Hash表数据读写的时间复杂度为0(1),图4.7为一对KV在 Hash表中的存储。
计算KV对中Key的HashCode对应的Hash表索引,可快速访问Hash表中的数据。 许多语言支持获得任意对象的HashCode,可以把HashCode理解为对象的唯一标示符,Java 语言中Hashcode方法包含在根对象Object中,其返回值是一个Into然后通过Hashcode 计算Hash表的索引下标,最简单的是余数法,使用Hash表数组长度对Hashcode求余, 余数即为Hash表索引,使用该索引可直接访问得到Hash表中存储的KV对。Hash表是
软件开发中常用到的一种数据结构,其设计思想在很多场景下都可以应用。
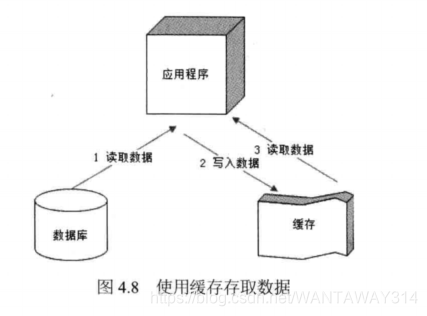
缓存主要用来存放那些读写比很高、很少变化的数据,如商品的类目信息,热门词 的搜索列表信息,热门商品信息等。应用程序读取数据时,先到缓存中读取,如果读取 不到或数据已失效,再访问数据库,并将数据写入缓存,如图4.8所示。
网站数据访问通常遵循二八定律,即80%的访问落在20%的数据上,因此利用Hash 表和内存的高速访问特性,将这20%的数据缓存起来,可很好地改善系统性能,提高数 据读取速度,降低存储访问压力。
- 合理使用缓存
使用缓存对提高系统性能有很多好处,但是不合理使用缓存非但不能提高系统的性 能,还会成为系统的累赘,甚至风险。实践中,缓存滥用的情景屡见不鲜一 分依赖 低可用的缓存系统、不恰当地使用缓存的数据访问特性等。
频繁修改的数据
如果缓存中保存的是频繁修改的数据,就会出现数据写入缓存后,应用还来不及读 取缓存,数据就已失效的情形,徒增系统负担。一般说来,数据的读写比在2:1以上,即 写入一次缓存,在数据更新前至少读取两次,缓存才有意义。实践中,这个读写比通常 非常高,比如新浪微博的热门微博,缓存以后可能会被读取数百万次。
没有热点的访问
缓存使用内存作为存储,内存资源宝贵而有限,不可能将所有数据都缓存起来,只 能将最新访问的数据缓存起来,而将历史数据清理出缓存。如果应用系统访问数据没有 热点,不遵循二八定律,即大部分数据访问并没有集中在小部分数据上,那么缓存就没 有意义,因为大部分数据还没有被再次访问就已经被挤出缓存了。
数据不一致与脏读
般会对缓存的数据设置失效时间,一旦超过失效时间,就要从数据库中重新加载。
因此应用要容忍一定时间的数据不一致,如卖家已经编辑了商品属性,但是需要过一段 时间才能被买家看到。在互联网应用中,这种延迟通常是可以接受的,但是具体应用仍 需慎重对待。还有一种策略是数据更新时立即更新缓存,不过这也会带来更多系统开销 和事务一致性的问题。
缓存可用性
缓存是为提高数据读取性能的,缓存数据丢失或者缓存不可用不会影响到应用程序 的处理——它可以从数据库直接获取数据。但是随着业务的发展,缓存会承担大部分数 据访问的压力,数据库已经习惯了有缓存的日子,所以当缓存服务崩溃时,数据库会因 为完全不能承受如此大的压力而宕机,进而导致整个网站不可用。这种情况被称作缓存 雪崩,发生这种故障,甚至不能简单地重启缓存服务器和数据库服务器来恢复网站访问。
实践中,有的网站通过缓存热备等手段提高缓存可用性:当某台缓存服务器宕机时, 将缓存访问切换到热备服务器上。但是这种设计显然有违缓存的初衷,缓存根本就不应 该被当做一个可靠的数据源来使用。
通过分布式缓存服务器集群,将缓存数据分布到集群多台服务器上可在一定程度上 改善缓存的可用性。当一台缓存服务器宕机的时候,只有部分缓存数据丢失,重新从数 据库加载这部分数据不会对数据库产生很大影响。
产品在设计之初就需要一个明确的定位:什么是产品要实现的功能,什么 不是产品提供的特性。在产品漫长的生命周期中,会有形形色色的困难和诱惑 来改变产品的发展方向,左右摇摆、什么都想做的产品,最后有可能成为一个 失去生命力的四不像。
缓存预热
缓存中存放的是热点数据,热点数据又是缓存系统利用LRU (最近最久未用算法) 对不断访问的数据筛选淘汰出来的,这个过程需要花费较长的时间。新启动的缓存系统 如果没有任何数据,在重建缓存数据的过程中,系统的性能和数据库负载都不太好,那 么最好在缓存系统启动时就把热点数据加载好,这个缓存预加载手段叫作缓存预热(warmUp )o对于一些元数据如城市地名列表、类目信息,可以在启动时加载数据库中全部数据 到缓存进行预热。
缓存穿透
如果因为不恰当的业务、或者恶意攻击持续高并发地请求某个不存在的数据,由于 缓存没有保存该数据,所有的请求都会落到数据库上,会对数据库造成很大压力,甚至 崩溃。一个简单的对策是将不存在的数据也缓存起来(其value值为null)。
- 分布式缓存架构
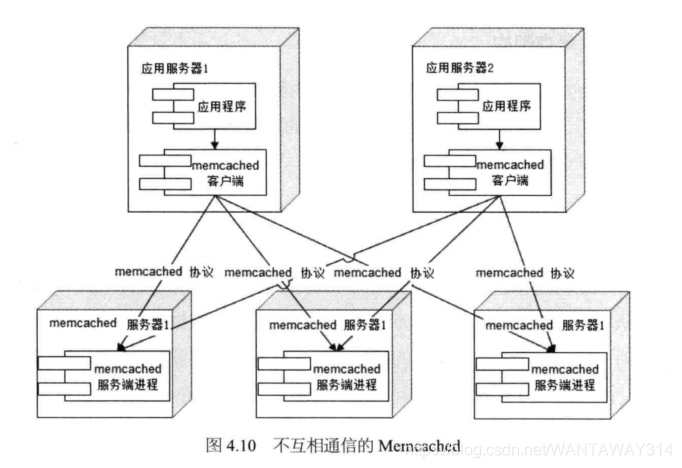
分布式缓存指缓存部署在多个服务器组成的集群中,以集群方式提供缓存服务,其 架构方式有两种,一种是以JBoss Cache为代表的需要更新同步的分布式缓存,一种是以 Memcached为代表的不互相通信的分布式缓存。
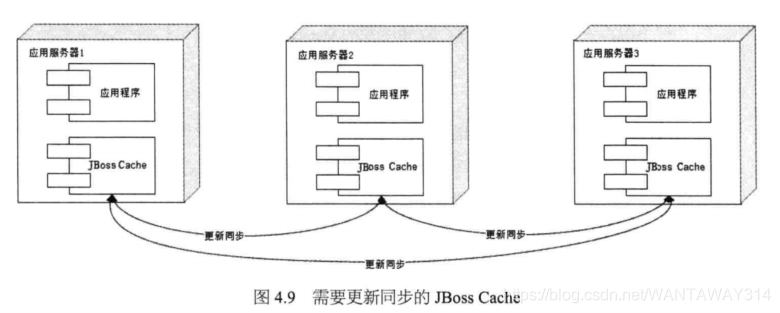
JBoss Cache的分布式缓存在集群中所有服务器中保存相同的缓存数据,当某台服务 器有缓存数据更新的时候,会通知集群中其他机器更新缓存数据或清除缓存数据,如 图4.9所示。JBoss Cache通常将应用程序和缓存部署在同一台服务器上,应用程序可从本地快速获取缓存数据,但是这种方式带来的问题是缓存数据的数量受限于单一服务器 的内存空间,而且当集群规模较大的时候,缓存更新信息需要同步到集群所有机器,其 代价惊人。因而这种方案更多见于企业应用系统中,而很少在大型网站使用。
大型网站需要缓存的数据量一般都很庞大,可能会需要数TB的内存做缓存,这时候
就需要另一种分布式缓存,如图4.10所不。Memcached采用一种集中式的缓存集群管理, 也被称作互不通信的分布式架构方式。缓存与应用分离部署,缓存系统部署在一组专门 的服务器上,应用程序通过一致性Hash等路由算法选择缓存服务器远程访问缓存数据, 缓存服务器之间不通信,缓存集群的规模可以很容易地实现扩容,具有良好的可伸缩性。
- Memcached
Memcached曾一度是网站分布式缓存的代名词,被大量网站使用。其简单的设计、优异的性能、互不通信的服务器集群、海量数据可伸缩的架构令网站架构师们趋之若鹜。
简单的通信协议
远程通信设计需要考虑两方面的要素,一是通信协议,即选择TCP协议还是UDP协 议,抑或HTTP协议;一是通信序列化协议,数据传输的两端,必须使用彼此可识别的 数据序列化方式才能使通信得以完成,如XML、JSON等文本序列化协议,或者Google Protobuffer等二进制序列化协议。Memcached使用TCP协议(UDP也支持)通信,其序 列化协议则是一套基于文本的自定义协议,非常简单,以一个命令关键字开头,后面是 一组命令操作数。例如读取一个数据的命令协议是get o Memcached以后,许多 NoSQL产品都借鉴了或直接支持这套协议。
丰富的客户端程序
Memcached通信协议非常简单,只要支持该协议的客户端都可以和Memcached服务 器通信,因此Memcached发展出非常丰富的客户端程序,几乎支持所有主流的网站编程 语言,Java、C/C++/C#、Perl. Python. PHP、Ruby等,因此在混合使用多种编程语言的 网站,Memcached更是如鱼得水。
高性能的网络通信
Memcached服务端通信模块基于Libevent, 一个支持事件触发的网络通信程序库。
Libevent的设计和实现有许多值得改善的地方,但它在稳定的长连接方面的表现却正是
Memcached 需要的。
高效的内存管理
内存管理中一个令人头痛的问题就是内存碎片管理。操作系统、虚拟机垃圾回收在 这方面想了许多办法:压缩、复制等。Memcached使用了一个非常简单的办法——固定 空间分配。Memcached将内存空间分为一组slab,每个slab里又包含一组chunk,同一个 slab里的每个chunk的大小是固定的,拥有相同大小chunk的slab被组织在一起,叫作 slab class,如图4.11所示。存储数据时根据数据的Size大小,寻找一个大于Size的最小 chunk将数据写入。这种内存管理方式避免了内存碎片管理的问题,内存的分配和释放都是以chunk为单位的。和其他缓存一样,Memcached采用LRU算法释放最近最久未被访 问的数据占用的空间,释放的chunk被标记为未用,等待下一个合适大小数据的写入。
当然这种方式也会带来内存浪费的问题。数据只能存入一个比它大的chunk里,而一
个chunk只能存一个数据,其他空间被浪费了。如果启动参数配置不合理,浪费会更加惊
人,发现没有缓存多少数据,内存空间就用尽了。
互不通信的服务器集群架构
如上所述,正是这个特性使得Memcached从JBossCache、OSCache等众多分布式缓存产品中脱颖而出,满足网站对海量缓存数据的需求。而其客户端路由算法一致性Hash 更成为数据存储伸缩性架构设计的经典范式(参考本书第6章)。事实上,正是集群内服 务器互不通信使得集群可以做到几乎无限制的线性伸缩,这也正是目前流行的许多大数
据技术的基本架构特点。
虽然近些年许多NoSQL产品层岀不穷,在数据持久化、支持复杂数据结构、甚至性 能方面有许多产品优于Memcached,但Memcached由于其简单、稳定、专注的特点,仍 然在分布式缓存领域占据着重要地位。
2异步操作
使用消息队列将调用异步化,可改善网站的扩展性(参考本书第7章内容)。事实上, 使用消息队列还可改善网站系统的性能,如图4.12和图4.13所示。
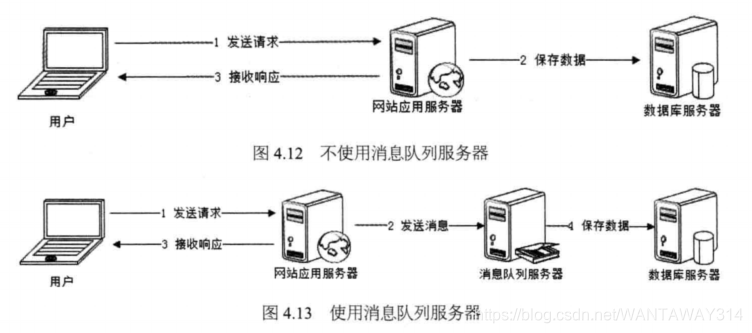
在不使用消息队列的情况下,用户的请求数据直接写入数据库,在高并发的情况下,
会对数据库造成巨大的压力,同时也使得响应延迟加剧。在使用消息队列后,用户请求 的数据发送给消息队列后立即返回,再由消息队列的消费者进程(通常情况下,该进程 通常独立部署在专门的服务器集群上)从消息队列中获取数据,异步写入数据库。由于 消息队列服务器处理速度远快于数据库(消息队列服务器也比数据库具有更好的伸缩 性),因此用户的响应延迟可得到有效改善。
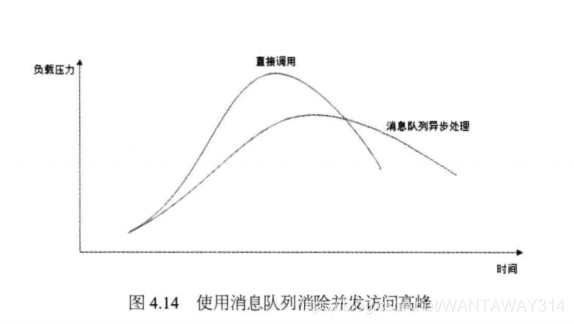
消息队列具有很好的削峰作用一即通过异步处理,将短时间高并发产生的事务消 息存储在消息队列中,从而削平高峰期的并发事务。在电子商务网站促销活动中,合理 使用消息队列,可有效抵御促销活动刚开始大量涌入的订单对系统造成的冲击。如图4.14所示。
需要注意的是,由于数据写入消息队列后立即返回给用户,数据在后续的业务校验、 写数据库等操作可能失败,因此在使用消息队列进行业务异步处理后,需要适当修改业 务流程进行配合,如订单提交后,订单数据写入消息队列,不能立即返回用户订单提交 成功,需要在消息队列的订单消费者进程真正处理完该订单,甚至商品岀库后,再通过 电子邮件或SMS消息通知用户订单成功,以免交易纠纷。
任何可以晚点做的事情都应该晚点再做。
3使用集群
在网站高并发访问的场景下,使用负载均衡技术为一个应用构建一个由多台服务器 组成的服务器集群,将并发访问请求分发到多台服务器上处理,避免单一服务器因负载 压力过大而响应缓慢,使用户请求具有更好的响应延迟特性,如图4.15所示。
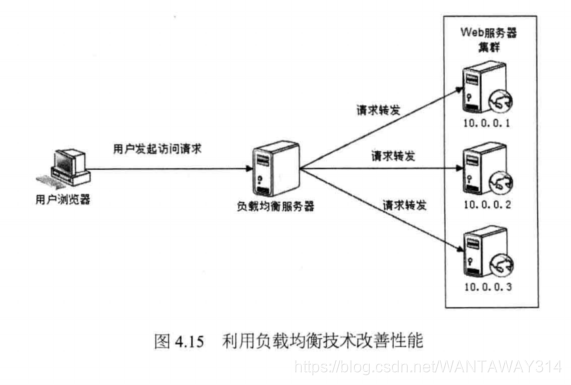
三台Web服务器共同处理来自用户浏览器的访问请求,这样每台Web服务器需要处 理的http请求只有总并发请求数的三分之一,根据性能测试曲线,使服务器的并发请求 数目控制在最佳运行区间,获得最佳的访问请求延迟。
4代码优化
网站的业务逻辑实现代码主要部署在应用服务器上,需要处理复杂的并发事务。合 理优化业务代码,可以很好地改善网站性能。不同编程语言的代码优化手段有很多,这 里我们概要地关注比较重要的几个方面。
- 多线程
多用户并发访问是网站的基本需求,大型网站的并发用户数会达到数万,单台服务
器的并发用户也会达到数百。CGI编程时代,每个用户请求都会创建一个独立的系统进程 去处理。由于线程比进程更轻量,更少占有系统资源,切换代价更小,所以目前主要的
Web应用服务器都采用多线程的方式响应并发用户请求,因此网站开发天然就是多线程
编程。
从资源利用的角度看,使用多线程的原因主要有两个:10阻塞与多CPUo当前线程 进行10处理的时候,会被阻塞释放CPU以等待10操作完成,由于10操作(不管是磁 盘IO还是网络IO)通常都需要较长的时间,这时CPU可以调度其他的线程进行处理。
前面我们提到,理想的系统Load是既没有进程(线程)等待也没有CPU空闲,利用多 线程10阻塞与执行交替进行,可最大限度地利用CPU资源。使用多线程的另一个原因是服务器有多个CPU,在这个连手机都有四核CPU的时代,除了最低配置的虚拟机,一 般数据中心的服务器至少16核CPU,要想最大限度地使用这些CPU,必须启动多线程。
网站的应用程序一般都被Web服务器容器管理,用户请求的多线程也通常被Web服 务器容器管理,但不管是Web容器管理的线程,还是应用程序自己创建的线程,一台服 务器上启动多少线程合适呢?假设服务器上执行的都是相同类型任务,针对该类任务启 动的线程数有个简化的估算公式可供参考:
启动线程数=[任务执行时间/ (任务执行时间-IO等待时间)]xCPU内核数
最佳启动线程数和CPU内核数量成正比,和IO阻塞时间成反比。如果任务都是CPU
计算型任务,那么线程数最多不超过CPU内核数,因为启动再多线程,CPU也来不及调 度;相反如果是任务需要等待磁盘操作,网络响应,那么多启动线程有助于提高任务并 发度,提高系统吞吐能力,改善系统性能。
多线程编程一个需要注意的问题是线程安全问题,即多线程并发对某个资源进行修 改,导致数据混乱。这也是缺乏经验的网站工程师最容易犯错的地方,而线程安全Bug 又难以测试和重现,网站故障中,许多所谓偶然发生的“灵异事件”都和多线程并发问 题有关。对网站而言,不管有没有进行多线程编程,工程师写的每一行代码都会被多线 程执行,因为用户请求是并发提交的,也就是说,所有的资源——对象、内存、文件、 数据库,乃至另一个线程都可能被多线程并发访问。
编程上,解决线程安全的主要手段有如下几点。
将对象设计为无状态对象:所谓无状态对象是指对象本身不存储状态信息(对象无 成员变量,或者成员变量也是无状态对象),这样多线程并发访问的时候就不会岀现状态 不一致,Java Web开发中常用的Servlet对象就设计为无状态对象,可以被应用服务器多 线程并发调用处理用户请求。而Web开发中常用的贫血模型对象都是些无状态对象。不 过从面向对象设计的角度看,无状态对象是一种不良设计。
使用局部对象:即在方法内部创建对象,这些对象会被每个进入该方法的线程创建, 除非程序有意识地将这些对象传递给其他线程,否则不会出现对象被多线程并发访问的情形。
并发访问资源时使用锁:即多线程访问资源的时候,通过锁的方式使多线程并发操作转为顺序操作,从而避免资源被并发修改。随着操作系统和编程语言的进步,出现各种轻量级锁,使得运行期线程获取锁和释放锁的代价都变得更小,但是锁导致线程同 步顺序执行,可能会对系统性能产生严重影响。
- 资源复用
系统运行时,要尽量减少那些开销很大的系统资源的创建和销毁,比如数据库连接、 网络通信连接、线程、复杂对象等。从编程角度,资源复用主要有两种模式:单例 (Singleton )和对象池(Object Pool )。
单例虽然是GoF经典设计模式中较多被诟病的一个模式,但由于目前Web开发中主 要使用贫血模式,从Service到Dao都是些无状态对象,无需重复创建,使用单例模式也 就自然而然了。事实上,Java开发常用的对象容器Spring默认构造的对象都是单例(需 要注意的是Spring的单例是Spring容器管理的单例,而不是用单例模式构造的单例)。
对象池模式通过复用对象实例,减少对象创建和资源消耗。对于数据库连接对象,
每次创建连接,数据库服务端都需要创建专门的资源以应对,因此频繁创建关闭数据库 连接,对数据库服务器而言是灾难性的,同时频繁创建关闭连接也需要花费较长的时间。因此在实践中,应用程序的数据库连接基本都使用连接池(Connection Pool)的方式。数据库连接对象创建好以后,将连接对象放入对象池容器中,应用程序要连接的时候,就 从对象池中获取一个空闲的连接使用,使用完毕再将该对象归还到对象池中即可,不需 要创建新的连接。
前面说过,对于每个Web请求(HTTP Request), Web应用服务器都需要创建一个独 立的线程去处理,这方面,应用服务器也采用线程池(Thread Pool)的方式。这些所谓的 连接池、线程池,本质上都是对象池,即连接、线程都是对象,池管理方式也基本相同。
- 数据结构
早期关于程序的一个定义是,程序就是数据结构+算法,数据结构对于编程的重要性
不言而喻。在不同场景中合理使用恰当的数据结构,灵活组合各种数据结构改善数据读 写和计算特性可极大优化程序的性能。
前面缓存部分已经描述过Hash表的基本原理,Hash表的读写性能在很大程度上依赖 HashCode的随机性,即HashCode越随机散列,Hash表的冲突就越少,读写性能也就越
高,目前比较好的字符串Hash散列算法有Time33算法,即对字符串逐字符迭代乘以33, 求得Hash值,算法原型为:
hash (i) = hash (i-1) * 33 + str [i]
Time33虽然可以较好地解决冲突,但是有可能相似字符串的HashCode也比较接近, 如字符串“AA”的HashCode是2210,字符串“AB”的HashCode是2211。这在某些应 用场景是不能接受的,这种情况下,一个可行的方案是对字符串取信息指纹,再对信息 指纹求HashCode,由于字符串微小的变化就可以引起信息指纹的巨大不同,因此可以获得较好的随机散列,如图4.16所示。

- 垃圾回收
如果Web应用运行在JVM等具有垃圾回收功能的环境中,那么垃圾回收可能会对系 统的性能特性产生巨大影响。理解垃圾回收机制有助于程序优化和参数调优,以及编写 内存安全的代码。
以JVM为例,其内存主要可划分为堆(heap )和堆栈(stack )o堆栈用于存储线程上 下文信息,如方法参数、局部变量等。堆则是存储对象的内存空间,对象的创建和释放、 垃圾回收就在这里进行。通过对对象生命周期的观察,发现大部分对象的生命周期都极 其短暂,这部分对象产生的垃圾应该被更快地收集,以释放内存,这就是JVM分代垃圾回收,其基本原理如图4.17所示。
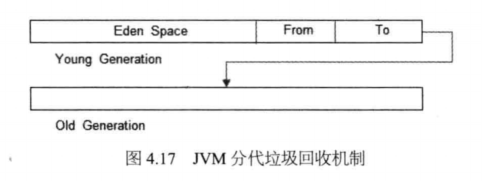
在JVM分代垃圾回收机制中,将应用程序可用的堆空间分为年轻代(Young Generation )和年老代(Old Generation ),又将年轻代分为 Eden 区(Eden Space )、From 区和To区,新建对象总是在Eden区中被创建,当Eden区空间已满,就触发一次YoungGC ( Garbage Collection,垃圾回收),将还被使用的对象复制到From区,这样整个Eden区都是未被使用的空间,可供继续创建对象,当Eden区再次用完,再触发一次Young GC, 将Eden区和From区还在被使用的对象复制到To区,下一次Young GC则是将Eden区和To区还被使用的对象复制到From区。因此,经过多次Young GC,某些对象会在From区和To区多次复制,如果超过某个阈值对象还未被释放,则将该对象复制到OldGenerationo如果0Id Generation空间也已用完,那么就会触发Full GC,即所谓的全量回收,全量回收会对系统性能产生较大影响,因此应根据系统业务特点和对象生命周期,合理设置Young Generation和Old Generation大小,尽量减少Full GCO事实上,某些Web 应用在整个运行期间可以做到从不进行Full GC。















 1780
1780











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











