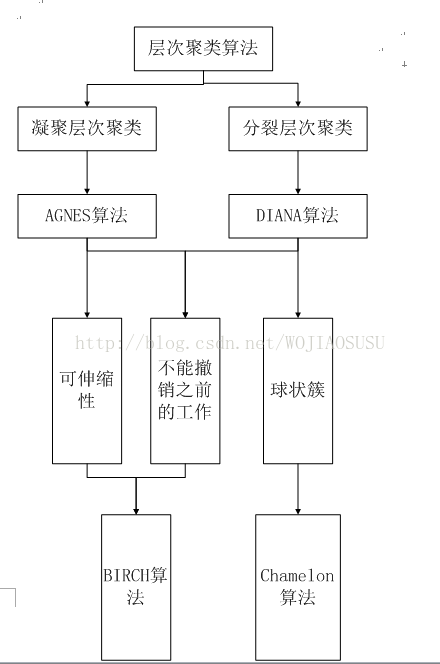
上述的几篇博文已经大致将基本的层次聚类算法讲了一下,现在做个简单总结,将这几个算法串联起来。
AGNES和DIANA这两个层次聚类算法尽管比较简单,但是存在缺点,因此需要改进,针对不同的缺点,引入了不同的算法。
(1)可伸缩性差
(2)在凝聚或者分裂的聚类过程中,之前的操作不能撤销。
(3)只能发现球状簇。
主要针对这三个缺点,下面对应的算法做了改进。通过这一个流程图,可以轻松的将层次聚类的算法串联在一块。
上述的几篇博文已经大致将基本的层次聚类算法讲了一下,现在做个简单总结,将这几个算法串联起来。
AGNES和DIANA这两个层次聚类算法尽管比较简单,但是存在缺点,因此需要改进,针对不同的缺点,引入了不同的算法。
(1)可伸缩性差
(2)在凝聚或者分裂的聚类过程中,之前的操作不能撤销。
(3)只能发现球状簇。
主要针对这三个缺点,下面对应的算法做了改进。通过这一个流程图,可以轻松的将层次聚类的算法串联在一块。
 3771
3771











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言