






import requests
url='http://localhost:63342/zjc/news.html?_ijt=p2l5n0shp613m01ad0jlpobino'
res=requests.get(url)
res.encoding='utf-8'
from bs4 import BeautifulSoup
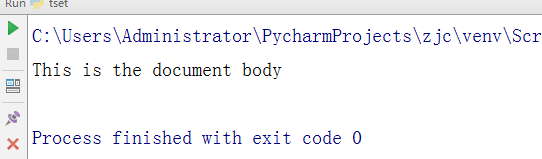
soup=BeautifulSoup(res.text,'html.parser')取出h1标签的文本
print(soup.h1.text)
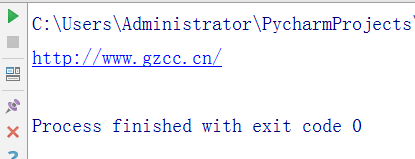
取出a标签的链接
s=soup.a.attrs['href']
print(s)
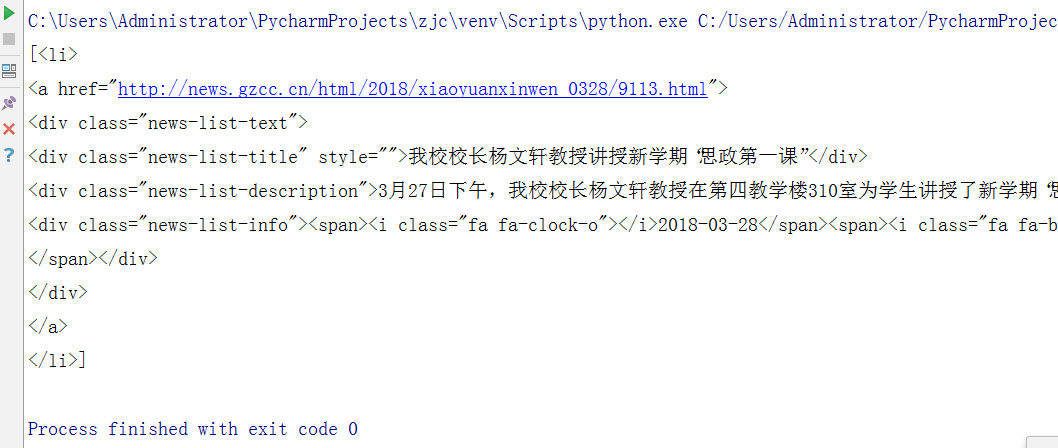
取出所有li标签的所有内容
s=soup.select('li')
print(s)
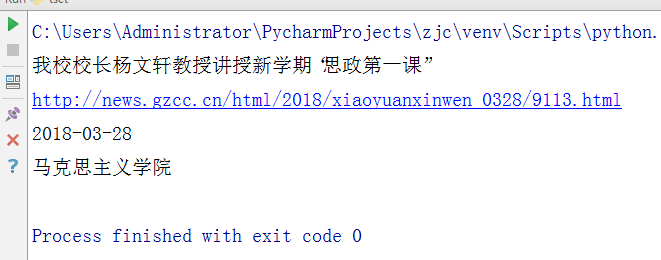
取出一条新闻的标题、链接、发布时间、来源
s0=soup.select('.news-list-title')[0].text
s1=soup.body.li.a.attrs['href']
s2=soup.select('.news-list-info')[0].contents[0].text
s3=soup.select('.news-list-info')[0].contents[1].text
print(s0+"\n"+s1+"\n"+s2+"\n"+s3)















 876
876











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









