 Shell脚本基础与常用命令详解
Shell脚本基础与常用命令详解





 本文详细介绍了Shell脚本的基础知识,包括脚本的编写、执行和常用命令,如who、echo、sed、awk、grep、find、tr等。讲解了如何进行文件操作、输入输出重定向、正则表达式、管道和过滤器的使用。此外,还探讨了环境变量、Shell特殊变量、预设变量以及条件测试。文章以实例展示各种命令的用法,帮助读者更好地理解和掌握Shell脚本编程。
本文详细介绍了Shell脚本的基础知识,包括脚本的编写、执行和常用命令,如who、echo、sed、awk、grep、find、tr等。讲解了如何进行文件操作、输入输出重定向、正则表达式、管道和过滤器的使用。此外,还探讨了环境变量、Shell特殊变量、预设变量以及条件测试。文章以实例展示各种命令的用法,帮助读者更好地理解和掌握Shell脚本编程。
Shell编程基础
1 基础知识
Shell脚本,就是利用Shell的命令解释的功能,对一个纯文本的文件进行解析,然后执行这些功能,也可以说Shell脚本就是一系列命令的集合。
Shell可以直接使用在win/Unix/Linux上面,并且可以调用大量系统内部的功能来解释执行程序,如果熟练掌握Shell脚本,可以让我们操作计算机变得更加轻松,也会节省很多时间。
Shell不是具体哪一款程序,是一类程序的统称,这些程序只要是能够按照用户的要求去调用操作系统的接口,就可以称之为Shell程序.
linux发展至今,有许多shell程序,其中一款软件叫做bash。
系统提供 shell命令解析器: sh ash bash
查看自己linux系统的默认解析:`echo $SHE
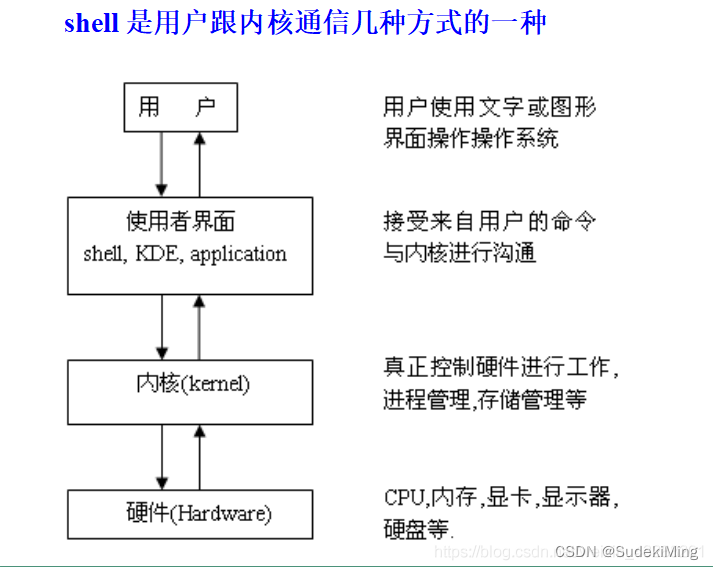
shell脚本是一种脚本语言,我们只需使用任意文本编辑器,按照语法编写相应程序,增加可执行权限,即可在安装shell命令解释器的环境下执行
拓展:
脚本的调用形式:
(1)打开终端时系统自动调用:
/etc/profile或~/.bashrc
/etc/profile
此文件为系统的每个用户设置环境信息,当用户第一次登录时,该文件被执行,系统的公共环境变量在这里设置开始自启动的程序,一般也在这里设置。
~/.bashrc
用户自己的家目录中的.bashrc
登录时会自动调用,打开任意终端时也会自动调用,这个文件一般设置与个人用户有关的环境变量,如交叉编译器的路径等等。
(2)用户手动调用:用户实现的脚本脚本三种执行方式:
(1)./xxx.sh :先按照 文件中#!指定的解析器解析
如果#!指定指定的解析器不存在 才会使用系统默认的解析器(2)bash xxx.sh:指明先用bash解析器解析
如果bash不存在 才会使用默认解析器(3). xxx.sh 直接使用默认解析器解析(不会执行第一行的#!指定的解析器)但是第一行还是要写的
1.1 基础命令
1.1.1.常用Linux帮助
(1)help
sgdisk --help
在–help中,最重要的是命令语法中特殊字符,搞定它们则搞定–help
[ ] 表示可选项,即需要则⽤,不需要不⽤
{ } 表示必选项,即⾥⾯的选项为必⽤
| 或者,⽐如:a|b的意思是a或者b只能选其中⼀个
特殊情况:
{a | b} 意思是a或b必选⼀个
[a | b] 意思是要么⼀个不选,要么选a或b其中⼀个
<> 这个符号有些特殊,有些命令中是必选,但是有些命令中是可选
… 表示多个,此符号前⾯是什么就是多个什么,⽐如:file…那就表示多个⽂件
(2)man手册
man sgdisk
【1】⼀般命令
【2】系统调⽤库
【3】c标准库
【4】设备⽂件
【5】配置⽂件
【6】游戏相关
【7】杂项 //所谓杂项,其⼤部分都是没办法很好分给其他8类的帮助
【8】系统管理相关命令
【9】内核(rhel5) //从rhel6开始,因为内核类的命令较少,将其废弃
进入man手册后常用快捷键
空格翻⻚
回⻋翻⾏
g 定位到⼿册顶部
G 定位到⼿册底部
/关键字 ⾼亮所有关键字
关键字之间切换:
n 按关键字往下翻
N 按关键字往上翻
q 退出
1.1.2 找出登录人员:who命令
#获取当前已登录系统中的所有用户的信息
#当用户登录熊同事,UNIX系统会为用户所在终端或网络设备分配一个唯一的标识数字,这个数字就是tty编号
who
1.1.3 回显字符:echo命令
echo命令会在终端打印出(或者说回显)你在行中输入的所有内容,且echo会将单词间多余的空白字符压缩,通常会忽略多余的空白字符。
echo this is test
echo ? #打印出一个字母的文件
echo a? #打印出以a开头的两个字母
echo ?? #打印出两个字母的文件
echo ??* #打印出两个字母以上的所有文件
echo * #使用文件名替换,列出所有文件
#echo参数选项
-e 激活转义字符。使用-e选项时,若字符串中出现以下字符,则特别加以处理,而不会将它当成一般文字输出:
\a 发出警告声;
\b 删除前一个字符;
\c 最后不加上换行符号;
\f 换行但光标仍旧停留在原来的位置;
\n 换行且光标移至行首;
\r 光标移至行首,但不换行;
\t 插入tab;
\v 与\f相同;
\\ 插入\字符;
\nnn 插入nnn(八进制)所代表的ASCII字符;
-n 不换行输出
-e 开启输出字串中对反斜杠的转译
-E 禁用反斜杠转译
1.2 使用文件
UNIX系统只识别三种基本类型的文件:普通文件、目录文件和特殊文件。
1.2.3 统计文件中单词数量:wc命令
wc命令可以获得文件中的行数、单词数和字符数。需要将待统计的文件名作为该命令的参数。
// 命令
wc [参数] [文件名]
// 命令选项(参数)
l 统计文件包含的行数
c 统计文件中包含的字符数
w 统计文件中包含的单词数
1.2.6 文件重命名:mv命令
可以使用mv(move)命令重命名文件。
// 命令
mv [待重命名文件] [文件的新名字]
例:
mv saved_names hold_it
注意:在执行mv或cp命令时,UNIX体统不管命令行中的第二个参数指定的文件是否存在。如果存在,文件内容会被覆盖。
1.2.7 删除文件:rm命令
rm命令可以从系统中删除文件。rm命令的参数就是要删除的文件。
rm hold_it
#命令选项
-i 删除前逐一询问确认
-f 即使原档案属性设为只读,亦直接删除,无需逐一确认
-r 将目录及以下之档案亦逐一删除
#作用是无提示地强制递归删除文件,慎用!在确定rm -rf后面没有奇怪的空格之后再运行
rm -rf file
1.2.8 创建文件指令:touch命令
touch命令用于修改文件或者目录的时间属性,包括访问时间和修改时间,若文件不存在,系统会建立一个新的文件。
touch命令有两个功能:
1、是用于把已存在文件的时间标签更新为系统当前的时间(默认方式),它们的数据将原封不动地保留下来;
2、是用来创建新的空文件。
语法格式:
touch [-acfm][-d<日期时间>][-r<参考文件或目录>] [-t<日期时间>][--help][--version][文件或目录…]
touch常见命令参数:
-a 只更改访问时间
-c, --no-create 不创建任何文件
-d, --date=字符串 使用指定字符串表示时间而非当前时间
-f (忽略)
-h, --no-dereference 会影响符号链接本身,而非符号链接所指示的目的地
(当系统支持更改符号链接的所有者时,此选项才有用)
-m 只更改修改时间
-r, --reference=FILE use this file's times instead of current time
-t STAMP use [[CC]YY]MMDDhhmm[.ss] instead of current time
--time=WORD change the specified time:
WORD is access, atime, or use: equivalent to -a
WORD is modify or mtime: equivalent to -m
--help 显示此帮助信息并退出
--version 显示版本信息并退出
请注意,-d 和-t 选项可接受不同的时间/日期格式。
例:
#使用touch命令创建一个空文件
touch file2.txt
1.3 使用目录
1.3.1 主目录和路径名
按照惯例,【…】指向当前目录的上一级目录,也称为父目录。
另一种惯用写法是单点号【.】,他总是引用当前目录。
1.3.2 显示工作目录:pwd命令
pwd命令可以告诉你当前的工作目录的名字,帮助你确定自己所处的位置。
1.3.3 更改目录:cd命令
cd … 和cd / 命令的区别:
#cd命令语法
cd [相对路径或绝对路径或特殊符号]
#命令选项(参数)
~ 表示用户主目录,即HOME变量指定的目录,如root用户的主目录为/root
- 表示前一个工作目录
.. 表示上级目录
. 表示当前目录
/ 进入系统根目录
#命令范例
(1)cd 进入用户主目录
(2)cd ~ 进入用户主目录
(3)cd - 返回进入此目录之前所在目录
(4)cd . 进入当前目录
(4)cd .. 返回上一级目录
(5)cd ../..返回上两级目录
(6)cd !$ 把上个命令的参数作为cd 参数使用
(7)cd / 进入系统根目录
1.3.5 创建目录:mkdir命令
mkdir用于创建目录
mkdir misc
#参数选项
-p:确保目录名称存在,不存在的就建一个,即使要创建的子目录的上一层目录不存在
-m:创建指定权限的目录
1.3.6 在目录之间复制文件
cp命令可以将多个文件复制到一个具体的文件名或一个已经存在的目录下,也可以同时复制多个文件到一个指定的目录中。
cp命令可以用来目录间复制文件
cp prgrams/wb misc/wbx
你可以一次向目录中复制多个文件:wb 和 coollect 和 mon
cp wb collect mon ../misc
#语法格式:
cp [参数] [文件]
常用参数:
| 参数 | 含义 |
|---|---|
| -f | 若目标文件已存在,则会直接覆盖原文件 |
| -i | 若目标文件已存在,则会询问是否覆盖 |
| -p | 保留源文件或目录的所有属性 |
| -r | 递归复制文件和目录 |
| -d | 当复制符号连接时,把目标文件或目录也建立为符号连接,并指向与源文件或目录连接的原始文件或目录 |
| -l | 对源文件建立硬连接,而非复制文件 |
| -s | 对源文件建立符号连接,而非复制文件 |
| -b | 覆盖已存在的文件目标前将目标文件备份 |
| -a | 等价于“dpr”参数组合。此选项通常在复制目录时使用,它保留链接、文件属性,并复制目录下的所有内容。 |
1.3.7 在目录间移动文件
mv memos/plan proposals/plan
如果是同一目录,即为重命名
如果是非同一目录,即为移动
1.3.8 文件链接:ln命令
为特定文件创建多个名字的命令时ln,即创建快捷方式
ln wb writeback
1.3.9 删除目录:rmdir命令
rmdir命令可以用来删除目录。如果指定的目录中包含任何文件和子目录,rmdir不会继续进行处理,这样就避免误删文件的可能。
#删除目录/users/pat
rmdir /users/pat
#参数选项
-r 删除目录及其内容
-f 强制执行操作,不再逐条命令发出提示
#删除空文件夹
rm -r floder
1.4.1 星号
Shell有一个强大的特性:文件名的替换。Shell会自动将模式【*】替换成当前目录下能够匹配到的所有文件名。
1.4.2 匹配单个字符
星号(*)能够匹配零个或多个字符,也就是说,x星能够匹配文件x,也能够匹配x1、x2、xabc等。问号(?)仅能匹配单个字符。
破折号(-)指定一个字符的逻辑范围。例如,[0-9]能够匹配字符0~9。在指定字符范围的时候,唯一的限制就是第一个字符在字母表上的必须位于最后一个字符之前。
1.5.1 文件名中的空格
有两种解决办法:使用反斜杠将所有空格进行转义,或者将整个文件名放在引号中,让Shell指导这是一个包含了空格的单词,并非多个单词。
例:
cat "my test document"
cat "my\test\document"
1.6 标准输入/输出和I/O重定向
1.6.1 标准输入和标准输出
UNIX命令可以使用文件或上一条命令的输出作为其输入,也可以将其输出发送给另一条命令或其它程序。这个概念极其重要。
Ctrl+d,表示数据输入完毕。
1.6.2 输出重定向
将发送到标准输出的命令输出转移到文件中,即叫做输出重定向。
如果将【>file】放置在能够将输出写入到标准输出上的命令之后,那么该命令的输出就会被写入到文件【file】中:
#使who的输出结果被写入到文件users中
who > users
注意:这个不会有任何输出内容出现,因为输出已经从默认的标准输出设备(终端)重定向到了指定文件中。
如果命令的输出被重定向到某个文件,而这个文件中之前已经有了内容存在,那么这个已有的内容会被重写。
当使用字符【>>】时表示另一种类型的输出重定向。这组字符使得命令的标准输出内容被追加到指定文件的现有内容之后,文件中先前的内容并不会丢失,新的输出只不过被添加到尾部而已。
例:
#将file1的内容追加到file2之后
cat file1 >> file2
1.6.3 输入重定向
正如命令的输出可以被重定向到文件中,文件也可以被重定向命令的输入中。小于号【<】则被作为输入重定向符号。只有哪些从标准输入中接收输入的指令擦能够使用这种方法将文件重定向到其输入中。
1.6.4 命令后面常见的>/dev/null 解释
Linux中的标准输入输出
- 0 是标准输入,一般是从键盘获得输入
- 1 是标准输出,一般是输出到屏幕了
- 2 是标准错误,有时候屏幕上可以看到,但是重定向的文件中看不到的就是它了
- >为重定向符号
>/dev/null 是一个特殊的设备文件,这个文件接收到任何数据都会被丢弃,俗称“黑洞”
2>/dev/null意思就是把错误输出到“黑洞” ,也就是说如果你的命令出错的话,错误报告直接就删除了。不会显示在屏幕上
1.7 管道
1.7.1 管道
UNIX能够将两个命令“连接”在一起,这种连接叫做管道,它可以将一个命令的输出直接作为另一个命令的输入。
管道的具体语法格式如下:
command1 | command2
command1 | command2 [ | commandN... ]
当在两个命令之间设置管道时,管道符|左边命令的输出就变成了右边命令的输入。只要第一个命令向标准输出写入,而第二个命令是从标准输入读取,那么这两个命令就可以形成一个管道。大部分的 Linux 命令都可以用来形成管道。
管道使用字符【|】表示,被放置在两个命令之间。例如,在【who】和【wc -l】之间创建一个管道,可以输入:
who | wc -l #计算行数
管道可以在任意两个程序间创建,前提是第一个程序会将输出写入到标准输出,第二个程序会从标准输入中读取输入。
1.7.1 过滤器
可以从标准输入中接收输入,对输入数据进行处理,然后将结果写入标准输出。总的来说就是用来在管道中修改其他程序输出的程序。
cat、sort都可以作为过滤器。
ls、who、date、cd、pwd、echo、rm、mv、及cp并没有从标准输入中读取输入,不是过滤器。
1.9.1 在一行中输入多个命令
如果在一行中输入多个命令,只需要使用分号作为命令之间的分隔符就行。
1.9.3 ps命令
ps命令能够给出系统中所运行的进程信息。
如果配合【-f】选项,ps会打印出更多的进程信息,包括父进程ID(PPID)、进程开始时间(STIME)及其他命令参数。
2.什么是Shell
#!/bin/bash: 是指此脚本使用/bin/bash来解释执行。其中,#!是一个特殊的表示符,后面紧跟着解释此脚本的shell路径。bash只是shell的一种,还有很多其它shell,比如:sh,csh,ksh,tcsh等等。
#!/bin/bash只能放在第一行,如果后面还有#!,那么只能看成是注释。
2.1 内核和实用工具
UNIX系统在逻辑上被划分为两个不同的部分:内核和实用工具(Utility),通常来说,所有访问都要经由Shell,Shell是一个实用工具程序,它作为登录过程的一部分被载入到内存中执行。
2.3 在Shell中输入命令
重要的要认识到Shell是一个程序,在系统中没有什么特权。
2.4 Shell的职责
(1)程序执行
(2)变量及文件明替换
(3)I/O重定向
(4)管道
(5)环境控制
(6)解释型编程语言
3.常备工具
3.1 正则表达式
正则表达式给出了一种便捷、一致的方式来指定待匹配的模式。
Shell认为【?】能够匹配任意单个字符,而在正则表达式中(regular expression,通常简写为regex)则是使用点号(.)来实现相同的效果。
3.1.1 匹配任意字符:点号(.)
正则表达式
r. #可以匹配r以及任意单个字符
正则表达式
.x. #可以匹配由任意两个字符包围的x,这两个字符不必相同
正则表达式:查找功能
/ ... /
注:编辑器ed是一个旧式的行编辑器,一直存在与Linux中
ed命令正则表达式测试:
ed temp.txt #使用ed编辑器打开文件,然后终端后会打印出文件中总的字符数
1,$p #打印出全部行,【p】为打印命令,【$】为范围限定符,
#最基本的范围限定符就是1,$,这表示从文件的第一行到最后一行
/ ... / #表示查找由空格包围的3个字符
/ #表示重复最后一次查询(继续搜索)
1,$s/p.o/XXX/g #将所有的p.o修改成XXX,【s】为替换命令,【g】表示执行全局替换
3.1.2 匹配行首:脱字符(^)
脱字符^作为正则表达式的第一个字符,用来匹配行首位置
/the/ #表示查找the
/^the/ #表示查找以the开头的行
1,$s/^/>>/ #在每一行的行首插入>>
1,$s/^/ / #在每一行的行首插入4个空格
3.1.3 匹配行尾:美元符号($)
点号可以匹配任意字符,因此正则表达式【$】匹配的是行尾的任意字符(包括点号)。
如何匹配点号?一般而言,如果你想匹配任何对于正则表达式来说有特殊含义的字符,可以在该字符前加一个反斜杠(\)来去除其特殊含义。
\.$ #匹配以点号结尾的行
^\. #匹配以点号开头的行
#将反斜线作为普通字符,可以使用连续两个反斜线【\\】
/\.$/ #搜索以点号结尾的行
1,$s/..$// #删除每行最后的两个字符
^$ #匹配空行
^ $ #匹配由单个空格组成的行
3.1.4.Shell中变量的原型:${var}
使用变量的原形:${var},即是加一个大括号来限定变量名称的范围
[root@bogon sh]# aa='ajax'
[root@bogon sh]# echo $aa
ajax
[root@bogon sh]# echo $aa_AA
[root@bogon sh]# echo ${aa}_AA
ajax_AA
$VAR 和 ${VAR} 效果相同,后者可以精确的标识替换范围
3.1.5.Shell脚本中的特殊变量
(1)Shell 特殊变量及其含义
| 变量 | 含义 |
|---|---|
| $0 | 当前脚本的文件名。 |
| $n(n≥1) | 传递给脚本或函数的参数。n 是一个数字,表示第几个参数。例如,第一个参数是 $1,第二个参数是 $2。 |
| $# | 传递给脚本或函数的参数个数。 |
| $* | 传递给脚本或函数的所有参数。 |
| $@ | 传递给脚本或函数的所有参数。当被双引号" "包含时,$@ 与 $* 稍有不同 |
| $? | 上个命令的退出状态,或函数的返回值 |
| $$ | 当前 Shell 进程 ID。对于 Shell 脚本,就是这些脚本所在的进程 ID。 |
(2)预定义变量与位置变量
#预定义变量,bash内置变量,可以调用但是不能赋值或者修改
$0 shell本身文件名
$? 最后运行命令的返回值
$! shell最后运行的后台process的PID
$$ shell本身的pid
$# shell的参数个数
$@ 所有参数列表, 以"$1 $2 … $n"的形式输出所有参数,此选项参数可超过9个
$* 所有参数列表, 以"$1" "$2" … "$n" 的形式输出所有参数
#位置变量,bash内置变量,存储脚本执行时的参数
$n : n为数字,$0代表脚本本身,$1~$9代表第1~9参数,10以上的参数需要用大括号包含,如:${10}
(3)环境变量
变量名通常大写,由操作系统维护,存储在/etc/profile或者~/.bash_profile
命令env可以列出所有环境变量
常见的环境变量有:PATH,PWD,USER,UID,HOME,SHELL
可以使用echo $PATH查看值
3.1.6 匹配字符组:【…】
[tT]he #匹配小写或大写的t,然后是字符the
/[tT]he/ #查找the或The
1,$s/aeiouAEIOU//g #所有的元音字母
#可以在中括号内使用字符范围来表示,具体的写法师使用连接符(-)来分隔起始字符与终止字符
[123456789] 或 [0-9]
[A-Z] #匹配大写字母
[A-Za-z] #匹配大写或小写字母
/^[A-Z]/ #找出以大写字母起始的行
在ed编辑器中,像*、.、[…]、$和^这类正则表达式序列仅在搜索字符串中有意义,在替换字符串中没有任何特殊含义。
如果脱字符(^)是左中括号后的第一个字符,那么所匹配内容的意义就相反了(相比之下,Shell使用!来实现相同的效果)
[^A-Z] #匹配除大写字母以外的任意字符
[^A-Za-z] #匹配任意非字母字符
3.1.7 匹配零个或多个字符:星号(*)
+可用于匹配一次或多次出现在其之前的表达式,因此以下两种表达方式在功能上没有什么不同
XX* #能够匹配到X以及跟随在其后的零个或多个连续的X
XXX* #能匹配至少两个连续的X
X+
1,$s/ */ / #将多个空格修改成单个空格
.* #常用于指定零个或多个任意字符,记住,正则表达式匹配的是符合模式的最长字符串,因此,匹配的总是整个文本行
正则表达式
1,$s/e.*e/+++/ #将一行中第一个e到最后一个e之间的全部字符(包括首尾的e在内)替换成+++
[A-Za-z][A-Za-z]* #匹配后面跟着零个或多个字母字符的那些字母字符
[]a-z] #能够匹配右中括号或小写字母
3.1.8 匹配固定次数的子模式:\{…\}
通用来精确指定需要匹配的字符数量:
\{min,max\} #min指定了待匹配正则表达式需要出现的最小次数,max指定了要出现的最大次数。
#并注意,必须使用反斜线对花括号进行转义
X\{1,10\} #匹配1到10个连续的X
几种特殊情况:
\{10\} #花括号中只有一个数字,表明此正则表达四必须匹配的次数
.\{10\} #能够匹配10个任意字符
1,$s/^.\{10\}// #删除每行的前10个字符
1,$s/.\{5\}$// #删除每行后5个字符,注意,不是5个字符的,无法满足匹配条件,不做任何修改
#如果花括号中的单个数字后紧跟着一个逗号,则表示之前的正则表达式至少应该匹配的次数
+\{5,\} #能够至少匹配5个连续加号,
3.1.9 保存已匹配的字符:\(…\)
要想引用已经由正则表达式匹配到的字符,可以将这部分正则表达式放在由反斜线转义过得括号里。这些被捕获到的字符会被保存在由正则表达式解析器预定义好的叫做寄存器的变量中,其编号从1到9。
#能够匹配文本行中的第一个字符并将其保存在寄存器1中
^\(.\)
#要想检索保存在某个寄存器中的字符,使用 \n (其中n是从1到9的数字)
^\(.\)\1 #首先匹配文本行中的第一个字符并将其保存在寄存器1中,然后匹配保存在寄存器1中的内容(\1指定的)
#这个正则表达式的最终效果就是能够匹配一行中头两个相同的字符。
^\(.\).*\1$ #能够匹配行首字符(^.)和行尾字符(\1$)相同的所有的行。首尾字符之间的所有字符有.*匹配
连续出现的\(…\)可以将其匹配的内容分配给后续的多个寄存器。例:
#文本行中的前3个字符会保存在寄存器1中,接下来3个字符会保存在寄存器2中
^\(...\)\(...\)
#能够匹配到一个长度为12个字符的字符串,其中地1~3个字符和第10~12个字符一样,第4~6个字符和第7~9个字符一样
^\(...\)\(...\)\2\1
在ed中使用替换命令时,寄存器也可以作为替换字符串中的一部分引用。
1,$s/\(.*\) \(.*\)/\2 \1/ #交换两个字段
3.1.10 命令执行结果替换 $()
用于做命令替换,将$()替换为执行结果
即,在 bash shell 中,$()是将括号内命令的执行结果赋值给变量
#eg
echo Today $(echo is $(date "+%Y-%m-%d"))
#解析
执行$(date "+%Y-%m-%d")括号中的date "+%Y-%m-%d",结果为2020-05-01
替换$(date "+%Y-%m-%d")为执行结果2020-05-01,命令还剩下echo Today $(echo is 2020-05-01)
同理执行$(echo is 2020-05-01)并替换,命令还剩下echo Today is 2020-05-01
最终输出Today is 2020-05-01
在 bash 中 ``(反引号)和 $() 具有相同的结果,前者优点支持所有类 Unix 系统,后者优点是比较直观。
3.2 cut
cut 命令从文件的每一行剪切字节、字符和字段并将这些字节、字符和字段写至标准输出。
如果不指定 File 参数,cut 命令将读取标准输入。必须指定 -b、-c 或 -f 标志之一。
该命令在从数据文件或命令输出中提取(切出)各种字段的时候非常方便。
cut -cchars file
其中,“chars”指定了你想从file中的每行内提取哪些字符(依据位置)包含:
(1)单个数字;如-c5,可以从输入的每行中提取第5个字符
(2)以逗号分隔的数字列表;如,-c1,13,50,可以提取第1个、第13个、第50个字符
(3)连接符分隔的数字范围;如-c20-50,可以提取第20~50个字符
cut -c5- data #提取从自定位置到行尾的所有字符,并将结果写入标准输出
如果没有指定file,cut会从标准输入中读取输入,这意味着你可以在管道中将cut作为过滤器使用。
可以利用cut从文本行中提取不同位置上的字符,如下:
who | cut -c1-8,18- #提取第1~8个字符(用户名),然后提取第18个到行尾的字符(登录时间)
# 命令
cut [参数] [文件名]
# 命令选项(参数),解决非固定格式数据文件
-b :以字节为单位进行分割。这些字节位置将忽略多字节字符边界,除非也指定了 -n 标志。
-c :以字符为单位进行分割。
-d :自定义分隔符,默认为制表符。
-f :指定待提取的字段,与-d一起使用,指定显示哪个区域。
-n :取消分割多字节字符。仅和 -b 标志一起使用。如果字符的最后一个字节落在由 -b 标志的 List 参数指示的范围之内,该字符将被写出;否则,该字符将被排除
cut -d: -f1,6 /etc/passwd #表示提取出以“:”分隔行第一个字段和第6个字段
如果在不使用-d选项的情况下用cut命令从文件中提取字段,则使用制表符作为默认的字段分隔符,而不是空格。
如果字段是由制表符分隔的,可以使用cut的-f选项:
cut -f1 phonebook #提取文件中的第一个字段
拓展:制表符
制表符即相当于键盘上的 Tab键(Q的左方,Caps lock的上方)
在格式控制输出中用“\t”表示
相当于回车在printf中用“\n”表示通常用于将输出对齐
如何知道字段是有空格还是由制表符分隔的?
(1)试错法
(2)命令:
sed -n 1 file
如果字段是由制表符分隔的,在制表符的位置上显示:\t
3.3 paste
paste 命令的效果和cut相反;它不是拆分行,而是合并行。该命令的一般格式为:
paste files
由files指定的每个文件中对应的行被“粘贴”或合并在一起,形成一行,然后写入到标准文件中(两者之间由制表符分隔)。连接符“-”可以用在files中,将输入源指定为标准输入。
# 命令
paste [参数] [列前文件名] [列后文件名]
# 命令选项(参数)
-d 指定单个分隔符,该分隔符用来分隔粘贴的所有字段
-s 指定paste只能从同一个文件中粘贴行,不管其他文件,如果指定了单个文件,其效果是将该文件中所有的行合并到一 起,彼此之间用制表符分隔(或者是由-d选项指定的分隔符)
例:
paste -d'+' names address numbers #将分隔符放在单引号中总是最安全的办法
paste -s names #粘贴names文件中的所有行
ls | paste -d' ' -s - #粘贴ls命令的输入,使用空格作为分隔符
3.4 sed
sed是Linux下一款功能强大的非交互流式文本编辑器,可以对文本文件进行增、删、改、查等操作,支持按行、按字段、按文本内容,灵活方便,特别适合于大文件的编辑。
sed可以用来在管道或命令序列中编辑数据。它是stream editor(流编辑器)的简称。和ed不同,sed并非交互式程序。sed会将指定的命令应用在输入的每一行上,并将结果写入到标准输出。sed的一般用法:
sed -e 's/wang/w/g;s/xu/x/g' user.txt #sed -e 是可以在一行里执行多条命令
#'s/wang/w/g;s/xu/x/g'的意思,s代表替换,
#g是尽可能多的匹配,有多少替换多少,
#因而意思是将user.text文本中的wang 替换成w,xu 替换成x
要养成将sed命令放入单引号的习惯。
sed不会修改原始输入文件。要想使更改永久生效,必须将sed的输出重定向到临时文件,然后使用该临时文件替换掉原文件:
sed -e 's/Unix/UNIX/g' intro > temp #做出修改
mv temp intro #是修改永久生效
在sed命令中利用正则表达式删除从一个空格(标记了用户名的结束)到本行末尾的所有字符:
who | sed 's/ .*$//'
sed命令使用空(nothing)(//)降低一个空格到本行末尾的所有字符(.*$)全部替换掉。也就是说,删除了每行中第一个空格之后的所有字符。
# 命令
sed [参数] [模式] [文件名]
# 命令选项(参数)
-e 是可以在一行里执行多条命令
-n 指定提取特定的行
-d 删除文本行
-p 打印当前模式空间内容,追加到默认输出之后
-P 打印当前模式空间开端至\n的内容,并追加到默认输出之前
-n: 静默模式,不再默认显示模式空间中的内容
-i: 直接修改原文件
-f /PATH/TO/SED_SCRIPT
-r: 表示使用扩展正则表达式
例:
sed -n '1,2p' intro #只打印前两行
#使用sed显示包含指定字符串的行
sed -n '/UNIX/p' intro #只打印出包含UNIX行
sed默认会将所有的输入行写入标准输出,如果在d命令前加上模式,就可以使用sed删除素有符合模式的的行。
例:
sed '1,2p' intro #删除行1和行2
sed '/UNIX/d' intro #删除所有包含UNIX的行
3.5 tr
过滤器tr可用于转换标准输入中的字符。该命令的一般形式为:
tr from-chars to-chars
其中,from-chars和to-chars可以是一个或多个字符。也可以是字符组。
# 命令
tr [参数] [字符1] [字符2]
# 命令选项(参数)
-s "压缩"to-chars中多次连续出现的字符
-d 删除输入流中的个别字符
例:
tr e x <intro #将所有的字符e转换成x
注意:必须将文件intro重定向到tr的输入中,因为tr要从标准输入中获得输入。转换结果被写入标准输出,不会改动原始文件。
可以把tr命令放在管道的末尾,通过将冒号转换成制表符,从而生成可读性更好的输出结果:
cut -d: -f1,6 /etc/passwd | tr : ' '
单引号中的是制表符。必须将其放在引号中,以避免在解析命令行时被Shell当做是多余的空白字符丢弃。
若处理不可打印字符,也可在tr中使用字符的八进制描述形式:
tr : '\11' #将冒号转换成制表符
date | tr ' ' '\12' #将空格转换成换行符
tr '[a-zA-Z]' '[A-Za-z]' #将大写字母转换成小写字母,将小写字母转换成大写字母
tr -s ':' '\11' #将所有磨耗转换成制表符,使用单个制表符替换多个制表符
也可以使用tr中的-s选项来压缩多个空格,只需要将单个空格字符作为第一个和第二个参数即可:
tr -s ' ' ' ' ' ' < lotsaspaces #使用空格来转换多个空格,也就是将输出中的多个空格替换成单个空格
tr也可用于删除输入流中的个别字符,其用法:
tr -d form-chars
例:
tr -d ' ' < intro #删除文件intro中的所有空格
注意:tr只能够处理单个字符,如果你需要转换的字符不止一个,就只能借助其他程序,如sed。
3.6 grep
grep能够在一个或多个文件搜索指定的模式,该命令的一般格式为:
grep pattern files
每个文件中匹配模式的行都会显示在终端中。如果grep中的命令中指定了不止一个文件,文件名会出现在每一行之前,以便于识别模式所对应的文件。
#在文件ed.cmd中查找素有单词shell
#如果指定的模式不存在于指定文件中,grep命令什么都不显示
grep shell ed.cmd
#grep命令在当前目录的所有文件中搜索单词shell
grep shell *
和sed中的表达式以及tr中的模式一样,最好是把grep中的模式放在单引号之中,避免shell误解。
#Shell发现了命令行中的星号,自动将其替换成当前目录下的所有文件名
grep * stars
#将星号放在引号中就可以避免Shell对其进行解析和解释
grep '*' stars
3.6.1 正则表达式与grep
#搜索以小写t或者大写T开头,然后搜是he的字符串
grep '[tT]' intro
#也可以用grep的-i选项,该选项可以忽略模式中的大小写
grep -i 'the' intro
3.6.2 grep 命令选项
# 命令
grep [参数] [模式] [文件]
# 命令选项(参数)
-i 忽略模式中的大小写
-v 不匹配指定模式的行
-l 输出匹配模式的那些行所在文件的文件名
-n 文件中匹配指定模式的每一行前面会加上对应的行号
#eg
grep -v 'UNIX' intro #打印不包含UNIX的行
grep -l 'Move_history' *.c #列出包含Move_history的文件
grep -n 'Move_history' testch.c #在匹配的行前加上行号
3.7 sort
sort基础的功能就是:给出输入,他会将其按照字母顺序排序并输出排序结果。默认情况下,sort会提取指定输入文件中的每一行,按照升序排列。特殊字符会根据其内部编码来排序。例如,空格在内部是用数字32描述的,双引号是用数字34描述的,这意味着前者会排在后者之前。
3.7.1 sort命令选项
# 命令
sort [参数] [文件]
# 命令选项(参数)
-u 消除输出中重复的行
-r 可以实现逆序排列
-o 将排序结果放在文件中
-n 指定将行中的第一个字段视为数字,对应的数据进行算术排序
-k2n 表示跳过每一行的第一个字段,从第二个字段开始排序。与此类似,-k5n表示对每行的第5个字段进行算术排序
-t 如果跳过了某些字段,sort则假定这些字段之间是以空格或者制表符分隔的。使用-t,其后的字符会被视为分隔符
#eg
sort -u names #消除文件中的重复行
sort | uniq #消除文件中的重复行
sort -r names #逆序
sort names > sorted_names #将排序结果不写进标准输出,而是放进文件中
sort names -o sorted_names #将排序结果不写进标准输出,而是放进文件中
sort -n data #算术排序
sort -k2n data #从第二个字段开始排序(字段间默认使用空格或制表符分隔的)
sort -k3n -t: /etc/passwd #对第3个以冒号分隔的字段(用户ID)进行算术排序
3.8 uniq
uniq命令可用于查找或者删除文件中的重复行。
该命令的基本格式:
# 命令
uniq [in_file] [out_file]
# 命令选项(参数)
-d 找出文件中重复的内容
-c 统计出出现的次数
其中,uniq将in_file复制为out_file,同事删除所有重复的行,uniq将重复的行定义为内容一模一样的连续行。
如果没有指定out_file,则结果会写入标准输出。如果in_file也没有指定,那么uniq可以作为过滤器,从标准输入中去读取内容。
sort常用于将重复的行调整到一起并将sort排序后的结果再交给uniq:
sort names |uniq
sort names | uniq -d #列出重复行
sort /etc/passwd | uniq -d #找出/etc/passwd中重复的条目
uniq的-c选项可以统计出现的次数,在脚本中极为有用:
sort names | uniq -c #统计行出现的次数
uniq -c的一个常见的用法是找出数据文件中词频最高的单词,可以通过下面的命令行实现:
tr '[A-Z]' '[a-z]' datafile | sort | uniq-c | head
3.9 awk拓展了解
AWK 是一种处理文本文件的语言,是一个强大的文本分析工具。
于 awk 脚本,我们需要注意两个关键词 BEGIN 和 END。
BEGIN{ 这里面放的是执行前的语句 }
END {这里面放的是处理完所有的行后要执行的语句 }
{这里面放的是处理每一行时要执行的语句}
# 命令
awk [选项] '指令' 操作文件
# 命令选项(参数)
-v 定义变量
-f 调用脚本
-F 指定分隔符
调用awk
(1)将所有的awk命令插入一个单独文件,然后调用:
awk -f awk-script-file input-file(s)
其中,-f选项加载awk-script-file中的awk脚本,input-file(s)跟上面的是一样的。
其中,-f选项加载awk-script-file中的awk脚本,input-file(s)跟上面的是一样的。
(2)命令行方式
awk [-F field-separator] ‘commands’ input-file(s)
其中,commands 是真正awk命令,[-F域分隔符]是可选的。 input-file(s) 是待处理的文件。
在awk中,文件的每一行中,由域分隔符分开的每一项称为一个域。通常,在不指名-F域分隔符的情况下,默认的域分隔符是空格。
其中,commands 是真正awk命令,[-F域分隔符]是可选的。 input-file(s) 是待处理的文件。
在awk中,文件的每一行中,由域分隔符分开的每一项称为一个域。通常,在不指名-F域分隔符的情况下,默认的域分隔符是空格。
(3)shell脚本方式
将所有的awk命令插入一个文件,并使awk程序可执行,然后awk命令解释器作为脚本的首行,一遍通过键入脚本名称来调用。
相当于shell脚本首行的:#!/bin/sh
可以换成:#!/bin/awk
3.10 perl拓展了解
perl 语言是用于文本处理语言,它代表实用提取和报告语言,可在各种平台运行(windows unix等)
perl借用了C、sed、awk、shell脚本以及很多其他编程语言的特性,语法与这些语言有些类似,也有自己的特点。
Perl 程序有声明与语句组成,程序自上而下执行,包含了循环,条件控制,每个语句以分号 ( ; ) 结束。
3.10.1 perl 基础语法
perl 代码可以写在一个文本文件中,以 .pl、.PL 作为后缀
perl 注释的方法为在语句的开头用字符 #
perl 输出字符串可以使用单引号和双引号
3.10.2 Perl 数据类型
标量,开头,开头,开头,myfirst=123;
数组,@开头,@arr=(1,2,3)
哈希,%开头,类似python的字典,有key和value,%h=(‘a’=>1,‘b’=>2);
3.10.3 函数
定义函数:sub 开头,大括号包含函数体
sub subroutine{
statements;
}
调用子程序语法格式:
subroutine( 参数列表 );
3.10.4 特殊:@_ 表示所有的参数
特有命令:
push:从数组的末尾加入元素。
pop :从数组的末尾取出元素
shift: 从数组的开头取出元素
unshift:从数组的开头加入元素
4 变量
4.1 定义变量
变量名=变量值
#注:直接赋值时禁止在等号两端添加空格
4.2 变量操作
#引用变量
$变量名
huo
${变量名}
#清除变量值
unset :变量
#从键盘获取值read
read 变量
#在一行上显示和添加提示 需要加上-p
read -p "请输入num的值:" num
#只读变量
readonly num=10
#查看环境变量
env
4.2.1 双引号 单引号的区别
双引号:可以解析变量的值
单引号:不能解析变量的值
num=200
echo "num=$num" #$num当成变量的值处理
echo 'num=$num' #$num当成字符串处理
4.2.2.PATH变量中 追加一个路径
export PATH=$PATH:/需要添加的路径
例:
#LD_LIBRARY_PATH是Linux环境变量名
#该环境变量主要用于指定查找共享库(动态链接库)时除了默认路径之外的其他路径。
export LD_LIBRARY_PATH=/mnt/navikit/lib:/mnt/navikit/
4.3 预设变量
shell直接提供无需定义的变量
4.4 脚本标量的特殊用法

4.5 变量的拓展
4.5.1 判断变量是否存在
#!/bin/bash
#${num:-val} 如果num存在,整个表达式的值为num,否则为val
echo ${num:-100} #100
num=200
echo ${num:-100} #200
4.5.2 字符串的操作
#!/bin/bash
str="hehe:haha:xixi:lala"
#测量字符串的长度 ${#str}
echo "str的长度为:${#str}" #19
#从下标3为位置提取 ${str:3}
echo ${str:3} #"e:haha:xixi:lala"
#从下标3为位置提取6个字节 ${str:3:6}
echo ${str:3:6} #"e:haha"''
#用new替换str中出现的第一个old ${str/old/new}
echo ${str/:/#} #"hehe#haha:xixi:lala"
#用new替换str中所有的old ${str//old/new}
echo ${str//:/#} #"hehe#haha#xixi#lala"
4.6 变量替换
4.6.1 基本变量替换
msg=beautiful
echo you are ${msg}
you are beautiful #输出结果
4.6.2 按照索引值取子串
file=/dir1/dir2/dir3/my.file.txt
命令 解释 结果
${file:0:5} 提取最左边的 5 个字节 /dir1
${file:5:5} 提取第 5 个字节右边的连续 5 个字节 /dir2
4.6.2 查找替换
file=/dir1/dir2/dir3/my.file.txt
命令 解释 结果
${file/dir/path} 将第一个 dir 提换为 path /path1/dir2/dir3/my.file.txt
${file//dir/path} 将全部 dir 提换为 path /path1/path2/path3/my.file.txt
4.6.2 按照路径取文件名
file=/dir1/dir2/dir3/my.file.txt
命令 解释 结果
${file##*/} 拿掉最后一条 / 及其左边的字符串 my.file.txt
#是去掉左边(在键盘上 # 在 $ 之左边)
%是去掉右边(在键盘上 % 在 $ 之右边)
单一符号是最小匹配;两个符号是最大匹配
*是用来匹配不要的字符,也就是想要去掉的那部分
还有指定字符分隔号,与*配合,决定取哪部分
4.7 重新定义变量值(())
#((2#110)) 2代表2进制,110为2进制表示的值,因此echo $6最终输出6
echo $((2#110))
#结果
6
4.8 局部变量和全局变量
#使用local定义个局部变量p
local p
作用:一般用于shell内局部变量的定义,多使用在函数内部
关于局部变量和全局变量:
(1)shell 脚本中定义的变量是global的,作用域从被定义的地方开始,一直到shell结束或者被显示删除的地方为止。
(2)shell函数定义的变量也是global的,其作用域从 函数被调用执行变量的地方 开始,到shell或结束或者显示删除为止。函数定义的变量可以是local的,其作用域局限于函数内部。但是函数的参数是local的。
(3)如果局部变量和全局变量名字相同,那么在这个函数内部,会使用局部变量。
5 条件测试
test命令:用于测试字符串、文件状态和数字
test命令有两种格式:
test condition
或
[ condition ]
使用方括号时,要注意在条件两边加上空格。
5.1 字符串测试

5.2 文件测试

#!/bin/bash
read -p "请输入一个文件名" fileName
#test -e $fileName
[ -e $fileName ]
echo $?
5.3 退出状态
只要程序执行完成,就会向Shell返回一个退出状态码。这个状态码是一个数值,指明了程序是否运行成功。按照惯例:
为0的退出状态码表示程序运行成功
非0的退出按状态吗表示程序运行失败,不同的值对应着不同的失败原因
对于文件复制命令来说,可能的错误情况会是:
1 文件没找到
2 文件不可读
3 目标目录没有找到
4 目标目录不可写
5 一般性错误
6 if条件语句
6.1 if命令的一般格式
if [ command ]; then
符合该条件执行的语句
fi
拓展语法:
if [ command ];then
符合该条件执行的语句
elif [ command ];then
符合该条件执行的语句
else
符合该条件执行的语句
fi
语法说明:
(1) bash shell会按顺序执行if语句,如果command执行后且它的返回状态是0,则会执行符合该条件执行的语句,否则后面的命令不执行,跳到下一条命令。
(2)当有多个嵌套时,只有第一个返回0退出状态的命令会导致符合该条件执行的语句部分被执行,如果所(3)有的语句的执行状态都不为0,则执行else中语句。
(4)返回状态:最后一个命令的退出状态,或者当没有条件是真的话为0。
注意:
1、[ ]表示条件测试。注意这里的空格很重要。要注意在’[‘后面和’]'前面都必须要有空格
2、在shell中,then和fi是分开的语句。如果要在同一行里面输入,则需要用分号将他们隔开。
3、注意if判断中对于变量的处理,需要加引号,以免一些不必要的错误。没有加双引号会在一些含空格等的字符串变量判断的时候产生错误。比如[ -n “$var” ]如果var为空会出错
4、判断是不支持浮点值的
5、如果只单独使用>或者<号,系统会认为是输出或者输入重定向,虽然结果显示正确,但是其实是错误的,因此要对这些符号进行转意
6、在默认中,运行if语句中的命令所产生的错误信息仍然出现在脚本的输出结果中
7、使用-z或者-n来检查长度的时候,没有定义的变量也为0
8、空变量和没有初始化的变量可能会对shell脚本测试产生灾难性的影响,因此在不确定变量的内容的时候,在测试号前使用-n或者-z测试一下
9、? 变量包含了之前执行命令的退出状态(最近完成的前台进程)(可以用于检测退出状态)
6.2 常用参数:
6.2.1 文件/目录判断:
常用的:
[ -a FILE ] 如果 FILE 存在则为真。
[ -d FILE ] 如果 FILE 存在且是一个目录则返回为真。
[ -e FILE ] 如果 指定的文件或目录存在时返回为真。
[ -f FILE ] 如果 FILE 存在且是一个普通文件则返回为真。
[ -r FILE ] 如果 FILE 存在且是可读的则返回为真。
[ -w FILE ] 如果 FILE 存在且是可写的则返回为真。(一个目录为了它的内容被访问必然是可执行的)
[ -x FILE ] 如果 FILE 存在且是可执行的则返回为真。
不常用的:
[ -b FILE ] 如果 FILE 存在且是一个块文件则返回为真。
[ -c FILE ] 如果 FILE 存在且是一个字符文件则返回为真。
[ -g FILE ] 如果 FILE 存在且设置了SGID则返回为真。
[ -h FILE ] 如果 FILE 存在且是一个符号符号链接文件则返回为真。(该选项在一些老系统上无效)
[ -k FILE ] 如果 FILE 存在且已经设置了冒险位则返回为真。
[ -p FILE ] 如果 FILE 存并且是命令管道时返回为真。
[ -s FILE ] 如果 FILE 存在且大小非0时为真则返回为真。
[ -u FILE ] 如果 FILE 存在且设置了SUID位时返回为真。
[ -O FILE ] 如果 FILE 存在且属有效用户ID则返回为真。
[ -G FILE ] 如果 FILE 存在且默认组为当前组则返回为真。(只检查系统默认组)
[ -L FILE ] 如果 FILE 存在且是一个符号连接则返回为真。
[ -N FILE ] 如果 FILE 存在 and has been mod如果ied since it was last read则返回为真。
[ -S FILE ] 如果 FILE 存在且是一个套接字则返回为真。
[ FILE1 -nt FILE2 ] 如果 FILE1 比 FILE2 新, 或者 FILE1 存在但是 FILE2 不存在则返回为真。
[ FILE1 -ot FILE2 ] 如果 FILE1 比 FILE2 老, 或者 FILE2 存在但是 FILE1 不存在则返回为真。
[ FILE1 -ef FILE2 ] 如果 FILE1 和 FILE2 指向相同的设备和节点号则返回为真。
例:
#!/bin/bash
#如果文件夹不存在,则创建文件夹 -d 判断是否存在一个目录
tempPath="/home/sudeki/Workplace/test/temp"
if [ ! -d "$tempPath" ]; then
mkdir temp
echo "文件夹创建成功!"
else
echo "文件夹已存在!"
fi
6.2.2 字符串判断
[ -z STRING ] 如果STRING的长度为零则返回为真,即空是真
[ -n STRING ] 如果STRING的长度非零则返回为真,即非空是真
[ STRING1 ] 如果字符串不为空则返回为真,与-n类似
[ STRING1 == STRING2 ] 如果两个字符串相同则返回为真
[ STRING1 != STRING2 ] 如果字符串不相同则返回为真
[ STRING1 < STRING2 ] 如果 “STRING1”字典排序在“STRING2”前面则返回为真。
[ STRING1 > STRING2 ] 如果 “STRING1”字典排序在“STRING2”后面则返回为真。
6.2.3 数值判断
[ INT1 -eq INT2 ] INT1和INT2两数相等返回为真 ,=
[ INT1 -ne INT2 ] INT1和INT2两数不等返回为真 ,<>
[ INT1 -gt INT2 ] INT1大于INT2返回为真 ,>
[ INT1 -ge INT2 ] INT1大于等于INT2返回为真,>=
[ INT1 -lt INT2 ] INT1小于INT2返回为真 ,<
[ INT1 -le INT2 ] INT1小于等于INT2返回为真,<=
6.2.4 逻辑判断
[ ! EXPR ] 逻辑非,如果 EXPR 是false则返回为真。
[ EXPR1 -a EXPR2 ] 逻辑与,如果 EXPR1 and EXPR2 全真则返回为真。
[ EXPR1 -o EXPR2 ] 逻辑或,如果 EXPR1 或者 EXPR2 为真则返回为真。
[ ] || [ ] 用OR来合并两个条件
[ ] && [ ] 用AND来合并两个条件
6.2.5 其他判断
[ -t FD ] 如果文件描述符 FD (默认值为1)打开且指向一个终端则返回为真
[ -o optionname ] 如果shell选项optionname开启则返回为真
6.2.6 IF高级特性
双圆括号(( )):表示数学表达式
在判断命令中只允许在比较中进行简单的算术操作,而双圆括号提供更多的数学符号,而且在双圆括号里面的’>‘,’<'号不需要转意。
双方括号[[ ]]:表示高级字符串处理函数
双方括号中判断命令使用标准的字符串比较,还可以使用匹配模式,从而定义与字符串相匹配的正则表达式。
双括号的作用:
在shell中,[ $a != 1 || $b = 2 ]是不允许出,要用[ $a != 1 ] || [ $b = 2 ],而双括号就可以解决这个问题的,[[ $a != 1 || b=2]]。又比如这个["b = 2 ]]。又比如这个[ "b=2]]。又比如这个["a" -lt “b"],也可以改成双括号的形式(("b" ],也可以改成双括号的形式(("b"],也可以改成双括号的形式(("a”
< “$b”))
7 case分支语句(多分支条件判断)
case分支语句格式如下:
case $变量名 in
模式1)
命令列表
;;
模式2)
命令列表
;;
*)
;;
esac
case行尾必须为单词“in”,每一个模式必须以右括号“)”结束。
双分号“;;”表示命令序列结束。
#!/bin/bash
printf "Input integer number: "
read num
case $num in
1)
echo "Monday"
;;
2)
echo "Tuesday"
;;
3)
echo "Wednesday"
;;
4)
echo "Thursday"
;;
5)
echo "Friday"
;;
6)
echo "Saturday"
;;
7)
echo "Sunday"
;;
*)
echo "error"
esac
因为*能够匹配任何字符(就像echo *能够匹配当前目录下所有文件一样),它被用来case语句的结尾,处理剩余的其他条件或作为默认值:如果之前分支中的值都不能匹配,可以在此处获得匹配。
8 循环
8.1 for循环
#for循环格式
for var in item1 item2 ... itemN
do
command1
command2
...
commandN
done
#for循环格式也可以表示成
for variable in (list)
do
commands
done
8.1.1 循环数字
#!/bin/bash
for((i=1;i<=10;i++));
do
echo $(expr $i * 3 + 1); #expr,进行表达式整数计算
done
#!/bin/bash
for i in $(seq 1 10)
do
echo $(expr $i * 3 + 1);
done
#!/bin/bash
for i in {1..10}
do
echo $(expr $i * 3 + 1);
done
#!/bin/bash
awk 'BEGIN{for(i=1; i<=10; i++) print i}'
#对设备2~6进行ext4型文件系统进行检测修复
#list使用的引号符号是``(键盘右上角esc下面的),而不是''(回车键左边的)
for i in `/usr/bin/seq 2 6`; do
/sbin/fsck.ext4 -y /dev/mmcblk1p${i}
done
8.1.2 循环字符串
#!/bin/bash
for i in `ls`;
do
echo $i is file name! ;
done
#结果:输出当前文件名
#!/bin/bash
for i in f1 f2 f3 ;
do
echo $i is appoint ;
done
#结果:结果(循环空格隔开的字符list)
8.1.2 路径查找
#!/bin/bash
for file in /Volumes/work/*;
do
echo $file is file path ! ;
done
#结果:循环查找当前目录
8.1.3 continue
continue指令并不会直接终止整个循环,而只是终止当前变量中的一个指令
continue指令指定跳出循环层级:
continue [数字]:用来指定跳出层级;多个循环嵌套式,默认只跳出内循环。
8.1.4 if 参数-a至-z
[-a file] 如果file存在则为真
不过貌似有时候-a表示为and:条件与
在[] 表达式中,常见的>,<需要加转义字符,表示字符串大小比较,以acill码 位置作为比较。 不直接支持<>运算符,还有逻辑运算符|| && 它需要用-a[and] –o[or]表示
[-b file] 如果file存在且是一个块特殊文件则为真
[-c file] 如果file存在且是一个字特殊文件则为真
[-d file] 如果file文件存在且是一个目录则为真
-d前的!是逻辑非
[-e file] 如果file文件存在则为真
[-f file] 如果file存在且是一个普通文件则为真
[-g file] 如果file存在且已经设置了SGID则为真(SUID 是 Set User ID, SGID 是 Set Group ID的意思)
[-h file] 如果file存在且是一个符号连接则为真
[-k file] 如果file存在且已经设置粘制位则为真
[-p file] 如果file存在且是一个名字管道(F如果O)则为真
管道是linux里面进程间通信的一种方式,其他的还有像信号(signal)、信号量、消息队列、共享内存、套接字(socket)等。
[-r file] 如果file存在且是可读的则为真
[-s file] 如果file存在且大小不为0则为真
[-t FD] 如果文件描述符FD打开且指向一个终端则为真
[-u file] 如果file存在且设置了SUID(set userID)则为真
[-w file] 如果file存在且是可写的则为真
[-x file] 如果file存在且是可执行的则为真
[-O file] 如果file存在且属有效用户ID则为真
[-G file] 如果file存在且属有效用户组则为真
[-L file] 如果file存在且是一个符号连接则为真
[-N file] 如果file存在and has been mod如果ied since it was last read则为真
[-S file] 如果file存在且是一个套接字则为真
[file1 –nt file2] 如果file1 has been changed more recently than file2或者file1 exists and file2 does not则为真
[file1 –ot file2] 如果file1比file2要老,或者file2存在且file1不存在则为真
[file1 –ef file2] 如果file1和file2指向相同的设备和节点号则为真
[-o optionname] 如果shell选项“optionname”开启则为真
[-z string] “string”的长度为零则为真
[-n string] or [string] “string”的长度为非零non-zero则为真
[sting1==string2] 如果2个字符串相同。“=”may be used instead of “==”for strict posix compliance则为真
[string1!=string2] 如果字符串不相等则为真
8.2 while循环
while循环是shell脚本中最简单的一种循环:
当条件满足时,while重复地执行一组语句,当条件不满足时,就退出while循环
while condition
do
statements
done
condition表示判断条件,statements表示要执行的语句
注意:
(1)在while循环体中必须有相应的语句使得condition越来越趋于“不成立”,只有这样才能最终退出循环,都则while就成了死循环,会一直执行下去,永无休止
(2)while语句和if else 语句中的condition用法都是一样的,你可以使用test或者[ ]命令,也可以使用(( ))或[[ ]]
#!/bin/bash
#计算1到100的和
sum=0
n=1
while ((n<=100))
do
((sum+=n))
((n++))
done
echo "The sum is $sum"

















 4287
4287

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









