







1.1:前言
当我们开发定时任务一般都是使用 quartz 或者 spring-task,无论使用quartz 还是 spring-task ,都会遇到以下两个痛点:
- 不敢轻易跟着应用服务器多节点部署,因为可能会重复多次执行而引发系统逻辑错误
- quartz 集群仅仅只是用来做 HA,节点数量的增加并不能给我们每次执行效率带来提升,不能实现水平扩展
但是:elastic-job 分布式任务调度,可以帮助我们解决以上两个痛点。
1.2:介绍
elastic-job 是由当当网基于quartz 二次开发之后的分布式调度解决方案 , 由两个相对独立的子项目Elastic-Job-Lite和Elastic-Job-Cloud组成 。Elastic-Job-Lite主要的设计理念是无中心化的分布式定时调度框架,使用jar包的形式提供分布式任务的协调服务。思路来源于Quartz的基于数据库的高可用方案。但数据库没有分布式协调功能,所以在高可用方案的基础上增加了弹性扩容和数据分片的思路,以便于更大限度的利用分布式服务器的资源。
中心化:
所谓的中心化,是指所有定时任务的执行是由某个调度中心判断作业是否到了执行的时间,然后通知业务系统去执行,即是作业节点并不知道自己应该什么时候执行定时任务,只能通过调度中心去决定作业的执行。缺点是部署麻烦。
去中心化:
elastic-job是去中心化设计,使用jar包的形式提供分布式任务的协调服务,各个作业节点是自治的,作业框架的程序在到达相应时间点时各自触发调度,缺点是可能会存在各个作业服务器的时间不一致的问题。
1.3: Elastic-Job-Lite主要功能:
a) 分布式:重写Quartz基于数据库的分布式功能,改用Zookeeper实现注册中心。
b) 并行调度:采用任务分片方式实现。将一个任务拆分为n个独立的任务项,由分布式的服务器并行执行各自分配到的分片项。
c) 弹性扩容缩容:将任务拆分为n个任务项后,各个服务器分别执行各自分配到的任务项。一旦有新的服务器加入集群,或现有服务器下线,elastic-job将在保留本次任务执行不变的情况下,下次任务开始前触发任务重分片。
d) 集中管理:采用基于Zookeeper的注册中心,集中管理和协调分布式作业的状态,分配和监听。外部系统可直接根据Zookeeper的数据管理和监控elastic-job。
e) 定制化流程型任务:作业可分为简单和数据流处理两种模式,数据流又分为高吞吐处理模式和顺序性处理模式,其中高吞吐处理模式可以开启足够多的线程快速的处理数据,而顺序性处理模式将每个分片项分配到一个独立线程,用于保证同一分片的顺序性,这点类似于kafka的分区顺序性。
f) 失效转移:弹性扩容缩容在下次作业运行前重分片,但本次作业执行的过程中,下线的服务器所分配的作业将不会重新被分配。失效转移功能可以在本次作业运行中用空闲服务器抓取孤儿作业分片执行。同样失效转移功能也会牺牲部分性能。
g) Spring命名空间支持:elastic-job可以不依赖于spring直接运行,但是也提供了自定义的命名空间方便与spring集成。
h) 运维平台:提供web控制台用于管理作业。
1.4 非功能需求:
a) 稳定性:在服务器无波动的情况下,并不会重新分片;即使服务器有波动,下次分片的结果也会根据服务器IP和作业名称哈希值算出稳定的分片顺序,尽量不做大的变动。
b) 高性能:同一服务器的批量数据处理采用自动切割并多线程并行处理。
c) 灵活性:所有在功能和性能之间的权衡,都可通过配置开启/关闭。如:elastic-job会将作业运行状态的必要信息更新到注册中心。如果作业执行频度很高,会造成大量Zookeeper写操作,而分布式Zookeeper同步数据可能引起网络风暴。因此为了考虑性能问题,可以牺牲一些功能,而换取性能的提升。
d) 幂等性:elastic-job可牺牲部分性能用以保证同一分片项不会同时在两个服务器上运行。
e) 容错性:作业服务器和Zookeeper断开连接则立即停止作业运行,用于防止分片已经重新分配,而脑裂的服务器仍在继续执行,导致重复执行。
1.5 架构图
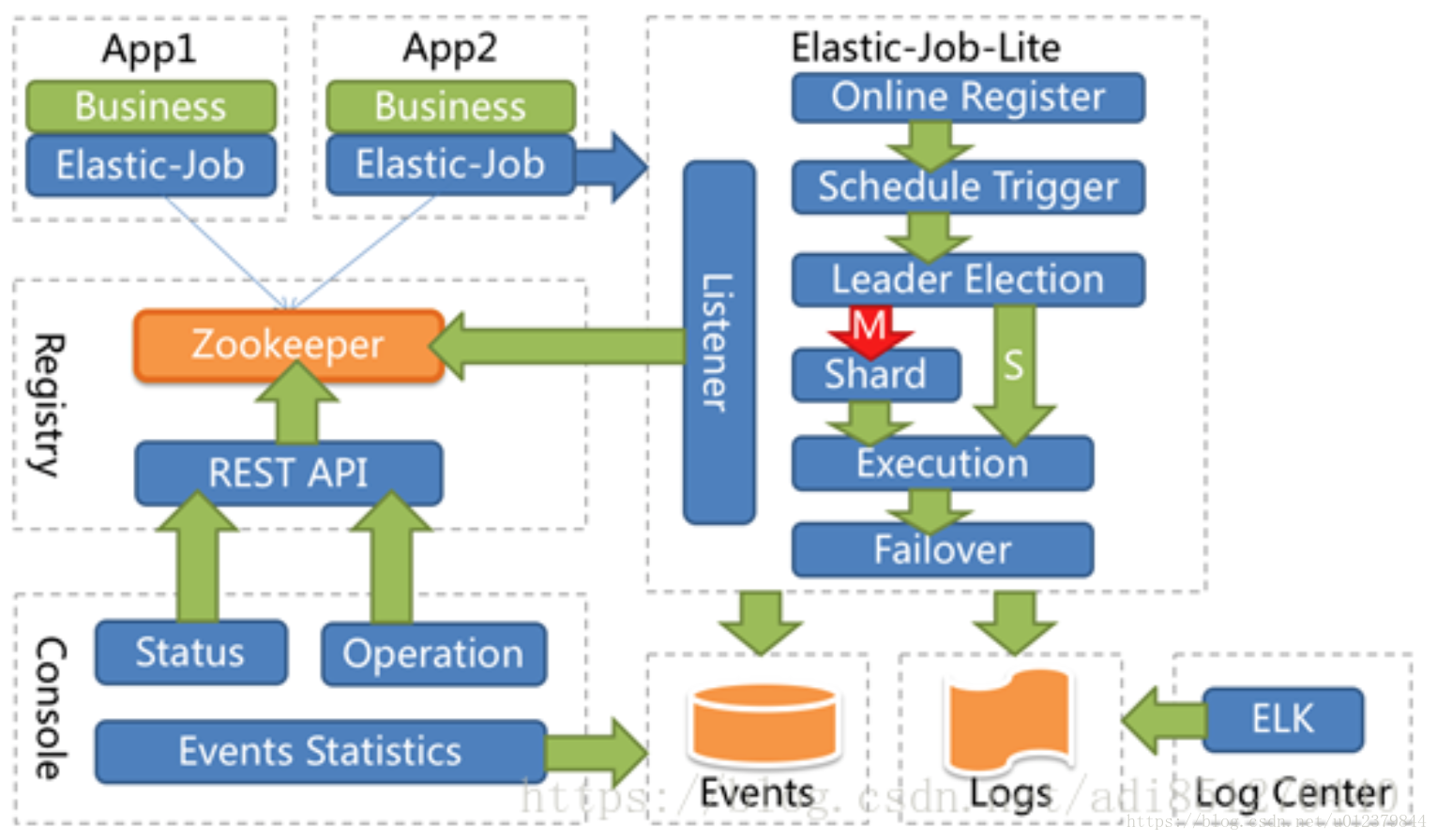
从上图可以发现:
Elastic-Job-Lite分布式定时任务,使用ZooKeeper作为注册中心,通过感知Zookeeper数据变化,做相应处理。并不直接提供数据处理的功能,框架只会将分片项分配给各个正在运行的服务器,分片项于业务数据的对应关系需要开发者在程序中自行处理。
Elastic-Job-Lite-console运维平台,也是通过读取ZK数据展现作业状态,或者更新ZK数据修改全局配置。
Elastic-Job-Lite 和 Elastic-Job-Lite-console 没有直接联系,完全解耦。
注册中心数据结构
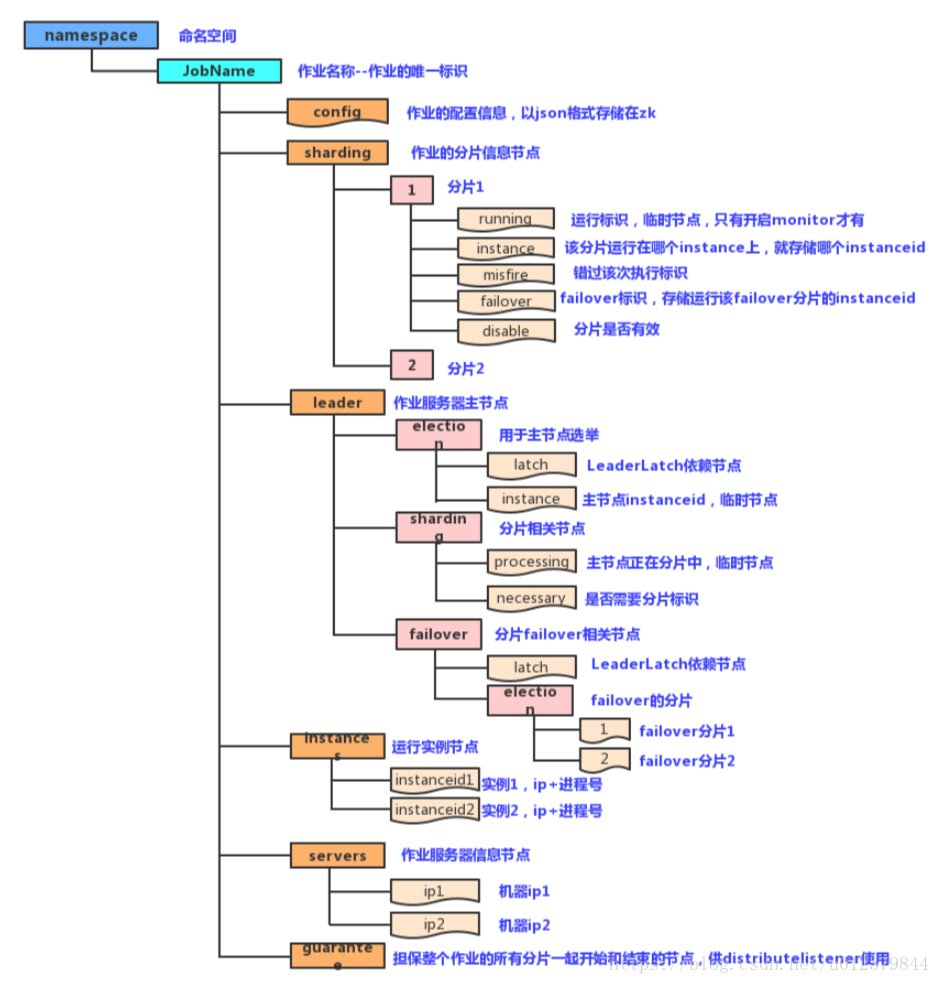
config:保存作业的配置信息,以JSON格式存储。
sharding:保存作业的分片信息,它的子节点是分片项序号,从零开始,至分片总数减一、
leader:该节点保存作业服务器主节点的信息,分为election、sharding和failover三个子节点,分别用于主节点的选举、分片和失效转移
instances:该节点保存的是作业运行实例的信息,子节点是当前作业运行实例的主键
servers:该节点保存作业服务器的信息,子节点是作业服务器的IP地址
实现原理
- 第一台服务器上线触发主服务器选举,主服务器一旦下线,则重新触发选举,选举过程中阻塞,只有当主服务器选举完成,才会去执行其他的任务;
- 某服务器上线时会自动将服务器的信息注册到注册中心,下线时会自动更新服务器的状态;
主节点选举,服务器上下线,分片总数变更均更新重新分片标记;
定时任务触发时,如需重新分片,则通过主服务器分片,分片过程中阻塞,分片结束后才可以执行任务。如分片过程中主服务器下线,则先选举主服务器在分片;
由上一项说明可知,为了维持作业运行时的稳定性,运行过程中只会标记分片的状态,不会重新分片,分片仅可能发生在下次任务触发前;
每次分片都会按照ip排序,保证分片结果不会产生较大的波动;
实现失效转移功能,在某台服务器执行完毕后主动抓取未分配的分片,并且在某台服务器下线后主动寻找可用的服务器执行任务。
elastic底层的任务调度还是使用的quartz,通过zookeeper来动态给job节点分片。如果很大体量的用户需要我们在特定的时间段内计算完成,那么我们肯定是希望我们的任务可以通过集群达到水平的扩展,集群里的每个节点都处理部分的用户,不管用户的数量有多大,我们只需要增加机器就可以了。举个例子:比如我们希望3台机器跑job,我么将我们的任务分成3片,框架通过zk的协调,最终会让3台机器分配到0,1,2的任务片,比如server0->0、server1->1、server2->2,当server0执行时,可以只查询id%3==0的用户,server1可以只查询id%3==1的用户,server2可以只查询id%3==2的用户。
在以上的基础上再增加一个server3,此时,server3分不到任何的分片,没有分到任务分片的程序将不执行。如果此时server2挂了,那么server2被分到的任务分片将会分配给server3,所以server3就会代替server2执行。如果此时server3也挂了,那么框架也会自动的将server3的任务分片随机分配到server0或者server1,那么就可能成:server0->0、server1->1,2。
原文链接:https://blog.csdn.net/u012379844/article/details/82716146














 8928
8928











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









