






这篇博客总结了半天,希望自己以后返回来看的时候理解更深刻,也希望可以起到帮助初学者的作用.
转载请注明 出自 : luogg的博客园 ,
泛型
泛型介绍
1)、类内部的属性的类型可以由外部决定;
2)、泛型可以解决数据类型的安全性问题;实现原理
1、在类声明时通过一个标识表示类中的某个属性的类型或者是某个方法的返回值及参数类型,
2、在实例化时只要指定好需要的具体的类型即可泛型类定义
[访问权限] class 类名称<泛型类型标识>{
[访问权限] 泛型类型标识 变量名称; 占位符
[访问权限] 泛型类型标识 方法名称(){}
[访问权限] 返回值类型声明 方法名称(泛型类型标识 变量名称){};
}泛型对象定义
类名称<具体类> 对象名称 = new 类名称<具体类>();定义多个泛型
类名称<具体类1,具体类2,…> 对象名称 = new 类名称<具体类1,具体类2,…>();
泛型构造方法
构造方法可以为类中的成员变量初始化,如果类中的成员变量类型通过泛型指定,但初始化又需要由构造方法来完成,那么这时就可以将泛型应用在构造方法上。格式:
[访问权限] 构造方法 ([泛型类型 参数名称]){
} 泛型的安全警告
在泛型应用中最好的在声明类对象时指定好其内部的数据类型,如 Info,如果不指定类型,在使用该类的时候就会出现不安全的警告,但是这样并不影响程序的运行
/**
* 泛型练习2 创建一个xy轴
* @author luogg
* @version v1.0 2016-xx-xx
*/
public class Test2 {
public static void main(String[] args) {
Point2<Integer> p1 = new Point2<Integer>();
p1.setX(10);
p1.setY(12);
int x = p1.getX();
int y = p1.getY();
System.out.println("x坐标:"+ x + ",y坐标:"+ y);
Point2<Character> p2 = new Point2<Character>();
p2.setX('哈');
p2.setY('呵');
char c1 = p2.getX();
char c2 = p2.getY();
System.out.println(c1+",,,"+c2);
Point2<Boolean> p3 = new Point2<Boolean>();
p3.setX(true);
System.out.println(p3.getX());
}
}
class Point2<T>{
private T x;
private T y;
public T getX() {
return x;
}
public void setX(T x) {
this.x = x;
}
public T getY() {
return y;
}
public void setY(T y) {
this.y = y;
}
}集合
定义
和数组类似,可以用来存放一组数据,和数组不同的是,集合里面只能放对象,长度是可变的,也已叫做“对象容器”
表示:
用 Java API 中定义好的一系列类和接口,这些类和接口放在 java .util 包中。java中的集合结构
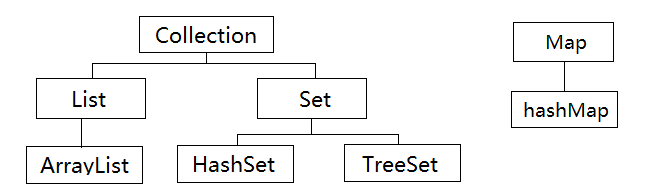
List接口(有序的)
List 接口是 Collection 的子接口,也是最常用的接口。此接口对 Collection 接口进行了大量的扩充,里面的内容是可以重复存放的
ArrayList类
一、方法的使用
核心方法:
- add(E e)添加元素
- get(int index)获取指定位置元素
- size()长度
常用方法:
clear()
isEmpty()
remove(int index) 移除指定位置元素
set(int index, E element) 替换
其他方法(熟悉即可)
二、集合的遍历
1、普通for
2、增强for循环,不需要写集合的大小,for( : )前边写接收的,后边写集合名字
3、迭代器 Iterator(集合的输出接口,用于输出集合中的内容,只能进行从前到后的单项输出) / / 直接将it.next写在syso中, Perosn的输出结果会少一半,因为next是取,取第一个人的名,取第二个人的年龄...Set 接口(无序的)
同样是 Collection 的子接口,但没有对 Collection 接口进行扩充,里面不允许存放重复的值HashSet类
集合中内容是无序的,并且不能存放重复数据
一、常用方法
add(E e); 加进去元素
remove(Object o);移除所加元素
clear(); 清空所有元素二、集合的遍历
1、增强for循环
2、迭代器三、加不进去重复数据的原因:
当使用 HashSet 时,会自动调用 hashCode(),判断已经存储的 Hash code 值是否与增加的 hash code 值一致,如果不一致,直接放进去,如果一致,再进行 equals 的比较,equals 方法返回 true,表示对象已经加进去了,就不会加进去新的对象,否则加进去。
所以,重复与否与 equals()和 hashCode()方法有关,重写 equals 方法必须重写 HashCode()方法,反之亦然。四、自定义对象想要实现不重复必须实现 equals()和 hashCode()
//在Person类中通过sorce,快捷导入equals()方法和hashcode()方法,之后输入相同的数据就不会输出了.
TreeSet类
自动排序,有小到大排序, 集合中内容是有序的,并且不能存放重复数据
一、方法的使用
和 HashSet 相同
其他方法(熟悉即可) 二、集合的遍历
1、增强for循环
2、迭代器三、自定义对象的排序问题
如果想要自定义的对象进行排序。需要两步:
1、实现 Comparable 接口
2、覆写其中的所有抽象类,(重点覆写compareTo方法)
定义排序规则,若要TreeSet.add()一个自定义对象,
这个对象所在的类必须要有CompareTo()方法 Map接口
是存放一对值的最大父接口,所谓的对值指的是每一个元素都是一对,以 key -> value 的形式保存的
HashMap类
Map 接口不同,每次操作的是一对对象,即二元偶对象,Map中的每个元素都使用“key-->value”的形式存储在集合中。一、方法的使用
put(key , value); //添加数据
get(key) //通过 key 值获取对象
keySet() //以 Set 的形式获得 Map 对象的 key 值二、集合内容的遍历
不可以使用for 也不可以使用增强for 不可以输出两个值key value
1、使用ketSet 然后用增强for循环 通过key获取 Map<Integer, Person> map = new HashMap<Integer,Person>();
map.put(10, new Person("张三",20));
map.put(1, new Person("李四",18));
map.put(5, new Person("王五",23));
Set<Integer> set = map.keySet();
for(int key:set) {
Person p = map.get(key);
System.out.println(p.getName()+p.getAge());
}总结
集合的特点:
集合中提供了很多方法,便于程序员操作集合中的元素
集合的长度是可变的。
数组可以放简单数据类型和复合类型,而集合只能存放对象
//集合不能装简单数据类型 会自动装箱区别总结:
List 和 Set的区别 //重复与不重复 父类一样
HashSet 和 TreeSet 的区别//都不可以重复 有序 无序
Collection 和 Map 的区别 //单值存放最大父接口 对值存放最大父接口














 843
843

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









