import sys
from lxml import etree
import time
import random
import requests
import json
import csv
from selenium import webdriver
from bs4 import BeautifulSoup
from time import sleep
class ChengxingspiderItem:
def __init__(self):
self.fund_code = ""
self.fund_name = ""
self.fund_price = ""
self.category = ""
self.inception = ""
self.subscribe = ""
self.redeem = ""
self.sbdesc = ""
self.sharprate = ""
self.date = ""
self._i = 0
def __iter__(self):
return self
def __next__(self):
if self._i == 0:
self._i += 1
return self.fund_code
elif self._i == 1:
self._i += 1
return self.fund_name
elif self._i == 2:
self._i += 1
return self.fund_price
elif self._i == 3:
self._i += 1
return self.category
elif self._i == 4:
self._i += 1
return self.sharprate
elif self._i == 5:
self._i += 1
return self.date
else:
raise StopIteration()
class FundSpider():
name = 'fund'
allowed_domains = ['cn.morningstar.com/quicktake/']
fund_list = ['0P0000RU7I', '0P0000S0NU', '0P0000XBF0', '0P0000YXTA', '0P0000Z5JW', '0P0000ZEAH', '0P00015WGK', '0P0001606X', '0P000160TK', '0P00016A08', '0P00016DKC',
'0P00016FT6', '0P000178CP', '0P00018J2K', '0P00018KU4', '0P0001ABM2', '0P0001D6IU', '0P0001F1K9', '0P0001FDKQ', 'F0000003VJ', 'F0000004AI', 'F0000004JE']
start_urls = [
f'http://cn.morningstar.com/quicktake/{page}' for page in fund_list]
url = 'http://cn.morningstar.com/handler/quicktake.ashx'
webUrl = 'http://cn.morningstar.com/quicktake/'
def parse(self, response):
fund_xpath = etree.HTML(response)
item = ChengxingspiderItem()
fund_name = fund_xpath.xpath('//*[@id="qt_fund"]/span[1]/text()')
fund_price = fund_xpath.xpath(
'//*[@id="qt_base"]/ul[1]/li[2]/span/text()')
date = fund_xpath.xpath('//*[@id="qt_base"]/ul[1]/li[3]/text()')
category = fund_xpath.xpath(
'//*[@id="qt_base"]/ul[3]/li[7]/span/text()')
sharprate = fund_xpath.xpath('//*[@id="qt_risk"]/li[30]/text()')
item.fund_code = fund_name[0][:6]
item.fund_name = fund_name[0][7:]
item.fund_price = fund_price[0]
if len(category) != 0:
item.category = category[0]
if len(sharprate) != 0:
item.sharprate = sharprate[0]
item.date = date[0][5:]
print(item.fund_code)
print(item.fund_name)
print(item.fund_price)
print(item.category)
print(item.sharprate)
return list(item)
if __name__ == '__main__':
fs = FundSpider()
options = webdriver.ChromeOptions()
options.add_argument("--no-sandbox")
driver = webdriver.Chrome(
'./chromedriver/chromedriver.exe', chrome_options=options)
cookies = ''
headers = ['fund_code', 'fund_name',
'fund_price', 'category', 'sharprate', 'date']
rows = [
]
for urlitem in fs.start_urls:
if(cookies == ''):
driver.get(urlitem)
username = driver.find_element_by_id('emailTxt')
password = driver.find_element_by_id('pwdValue')
username.send_keys('***********@qq.com')
password.send_keys('w*************')
submit = driver.find_element_by_id('loginGo')
submit.click()
sleep(1)
cookies = driver.get_cookies()
else:
driver.get(urlitem)
singlerow = fs.parse(driver.page_source)
rows.append(singlerow)
with open('test.csv', 'w', newline='')as f:
f_csv = csv.writer(f)
f_csv.writerow(headers)
f_csv.writerows(rows)
如图:
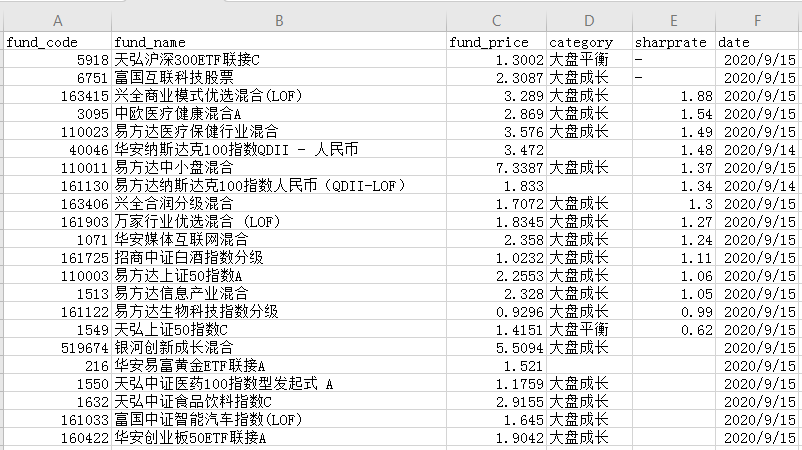
CSV示例
import csv
headers = ['class', 'name', 'sex', 'height', 'year']
rows = [
[1, 'xiaoming', 'male', 168, 23],
[1, 'xiaohong', 'female', 162, 22],
[2, 'xiaozhang', 'female', 163, 21],
[2, 'xiaoli', 'male', 158, 21]
]
with open('test.csv', 'w',newline='')as f:
f_csv = csv.writer(f)
f_csv.writerow(headers)
f_csv.writerows(rows)
如图:
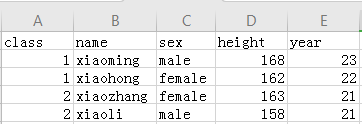
下载地址




























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









