



 本文介绍了一种在中文自然语言处理任务中去除英文、数字及特殊字符的方法,使用Python的正则表达式库re实现文本清洗,显著减少了文本数据量。
本文介绍了一种在中文自然语言处理任务中去除英文、数字及特殊字符的方法,使用Python的正则表达式库re实现文本清洗,显著减少了文本数据量。
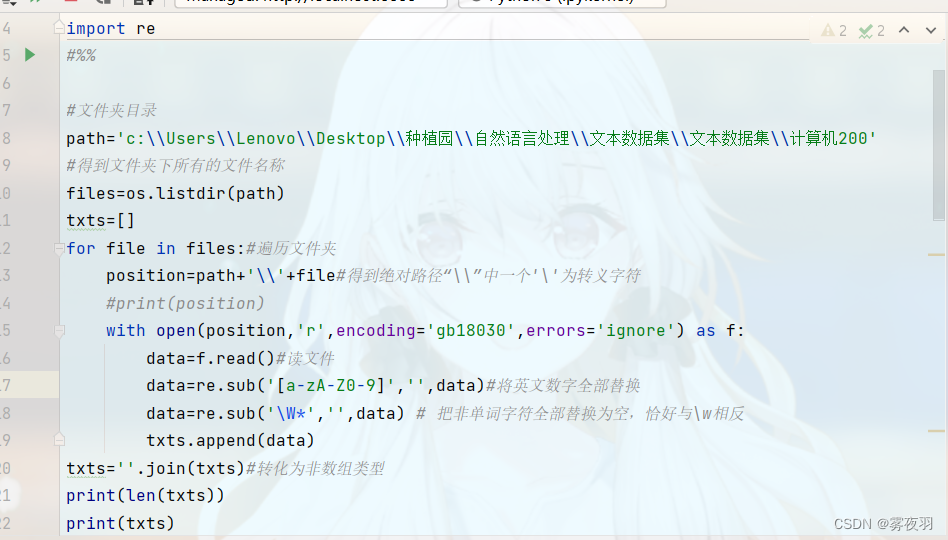
在中文的自然语言处理,英文、数字和字符是无法在词典中对比成功的,所以需要消除掉。
方法如下:
首先引入re库:
import re
然后使用sub()函数先消除字母和数字
re.sub('[a-zA-Z0-9]','',data)
#第一个参数是搜索a-z,A-Z,0-9
#第二个参数是''用于替换第一个参数
#第三个参数是读取到的文本
接着在消除字符
re.sub('\W','',data)
#用去替换特殊字符,即非字母、非数字、非汉字、非_
处理前 文本长度660331

处理过后 文本长度334183


















 3638
3638

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









