







AI 图片截取(ffmpeg), anaconda环境,图片标注(labelme),模型训练(yolov5),CUDA+Pytorch安装及版本相关问题
一、截取有效图片
-
录制RTSP视频脚本
#!/bin/bash datetime=$(date +%Y-%m-%d-%H%M%S) username=admin password=Z@n\(j\!t8 read -p "ip " ip nohup ffmpeg -ss 0:01 -i rtsp://$username:$password@$camera_ip -c copy fog-record-$camera_ip-$datetime.mkv -y -c:a aac -fflags +genpts >> fog-record-$camera_ip-$datetime.mkv.log 2>&1 & echo $!ffmpeg在录制视频的时候报错"Can’t write packet with unknown timestamp"错误,则在 ffmpeg 后面加上 -ss 0:01 -fflags +genpts
-
提取视频有效画面图片
首先以视频文件名称创建目录,所有从该视频提取到的图片,均保存在相应的目录中
Linux安装ffmpeg(ffmpeg是具备段视频截取以及段视频图片截取功能的)
sudo apt-get install ffmpeg若apt无法安装或者安装报错,则可通过如下方法安装 1. 进入官方下载对应版本包 https://ffmpeg.org/download.html 2. 或者通过命令下载 wget https://johnvansickle.com/ffmpeg/builds/ffmpeg-git-amd64-static.tar.xz 3. 将下载包解压将 .xz 后缀去掉 xz -d ffmpeg-git-amd64-static.tar.xz 4. 解压tar包 tar -xvf ffmpeg-git-amd64-static.tar 5. 解压完成后生成目录 ffmpeg-git-20220108-amd64-static , 进入该目录 6. 该目录中包含的可执行文件 ffmpeg, ffprobe , ./ffmpeg 执行即可 7. 将ffmpeg设置为全局可用,进入/usr/bin/ 下创建软连接即可 cd /usr/bin/ ln -s /root/ffmpeg-git-20220108-amd64-static/ffmpeg ffmpeg ln -s /root/ffmpeg-git-20220108-amd64-static/ffprobe ffprobeWindows安装ffmpeg(Linux也可用此方法,但不如apt方式方便)
Download FFmpeg直接使用 ffmpeg,指定开始结束时间截取图片时,会因找不到P frame和 I frame,耗费非常长的时间。随着视频时间越长,截取时间越久
截取位于 10 分钟的片段为图片,实测需要花费4~5分钟
先截为视频,可提升效率
使用 ffmpeg,先截为视频,再转为图片
$dir 为文件目录
$file 为文件名
截取段视频
ffmpeg -i d i r / dir/ dir/file -ss $start -to $end -async 1 -c copy d i r / dir/ dir/start.mkv
将视频截取为图片
ffmpeg -i d i r / dir/ dir/start.mkv -r 1 d i r / i m a g e dir/image dir/imagestart-%3d.jpeg也可使用如下的小脚本,通过视频中需要生成图片的起始与结束时间,直接生成对应的图片,会更方便一些
#!/bin/bash dir=视频文件目录(结尾不带/ file=视频文件名 while true do read -p "开始时间 " start read -p "结束时间 " end # 截取视频 ffmpeg -i $dir/$file -ss $start -to $end -async 1 -c copy $dir/$start.mkv # 将视频截取为图片 ffmpeg -i $dir/$start.mkv -r 1 $dir/image$start-%3d.jpeg done
二、使用labelme或labelImg对图片进行标注
(此文章以labelme进行标注工作)
-
安装 labelme 标注工具
再次之前需要先安装anaconda,anaconda是开源的python发行版本,用起来很方便。 labelme 与 yolov5 ,官方均建议使用 anaconda 进行部署- anaconda的安装
-
下载 anaconda 安装程序
https://www.anaconda.com/products/individual下载获得 anaconda3-xxx.sh
-
sh 安装anaconda
bash anaconda3-xxx.sh -
添加环境变量
vim ~/.bashrc export PATH=/home/alen/anaconda3/bin:$PATH -
换源(可选)
anaconda 安装时,因软件包源 为国外,下载可能过于缓慢。
anaconda换为清华源conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/ conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/ conda config --set show_channel_urls yes
-
- labelme的安装部署
-
创建conda环境
conda create --name labelme python=3.6 -
进入环境
conda create --name labelme python=3.6 # 进入成功时,命令行前出现括号(laeblme) -
安装labelme
pip install labelme安装过程中可能会需要安装pyqt5、pyside2
pip installl pyqt5
pip install pyside2
在安装时报错qt.qpa.plugin: Could not load the Qt platform plugin xcb
解决方法:
sudo apt-get install libxcb-xinerama0
-
测试进入labelme
# 命令行直接输入labelme,应弹出 labelme 图形界面 labelme
-
- anaconda的安装
-
使用矩形工具,进行标注
labelme的图形界面就长这样,当然,没有这只猫
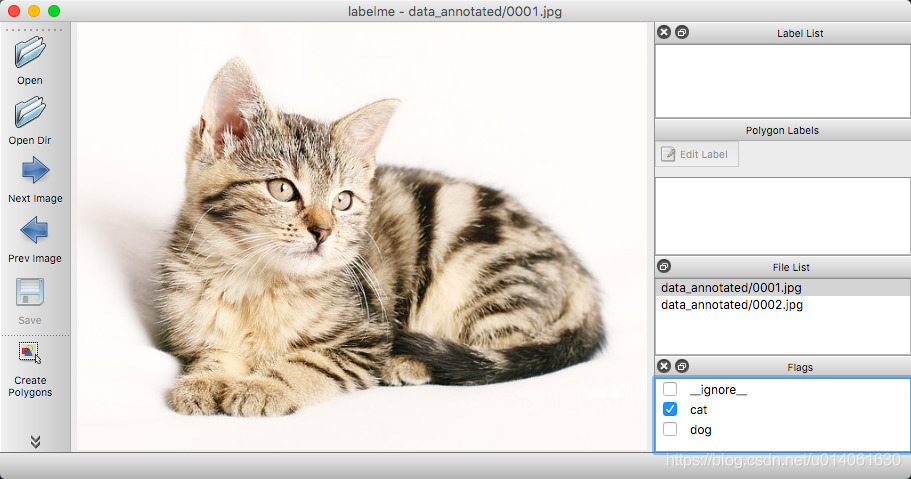
labelme的使用并部复杂,进入之后,选择Open或者Open Dir打开要标注的图片
使用ctrl+R 或 鼠标右键选择,进入矩形标注模式进行标注即可
这里就不错啰嗦了
labelme详解(引用一下这位大佬的文章, 写的蛮详细的,为大佬增加点流量,哈哈)
这里要注意的点是:标注类最好与后面模型训练的类名称相同这里自制了个小脚本: 主要作用是删除一些不需要标定的图片,因为通过上述生成图片的方法中,会有相似图片不需要标定,为不影响标定效率,可跳过标定,后续执行该脚本即可将未标定图片删除
#!/bin/sh forder=需要过滤文件夹路径 for img in ${forder}/* do a=${img%.*} if [ -f $a.jpeg ]; then if [ ! -f $a.json ]; then rm $img fi fi done -
保存,生成 json 文件
点击save即保存为json文件了
三、自制数据集
-
将 labelme 的获得的json文件的坐标,进行归一化处理。并转为txt文件
将 labelme 获得的 json 数据文件转换为 txt 文件。并且把labelme获得的坐标进行归一转化,转为 (0,1)之间的浮点数
Labelme标注数据转为YOLOV5 训练的数据集–>这块引用一下这位大佬的博客,算是现成的工具吧,文章中的第一个.py文件是将json转换为txt文件
不过在使用这位大佬写好的.py代码的时候,需要注意以下几点:- 检查图片格式,该博客中图片格式为jpg, 而图片的格式可能是png/jpeg等
- 标注的图片需与json在同一目录下
- 需要导入对应的包
转化后的txt文件,格式应为:class x_center y_center width height,例如:
0 0.7685 0.4072413793103448 0.40000000000000013 0.267816091954023这里的class对应的是在标准过程中的标注类,在做模型训练的过程中,模型类最好是与标注类对应,类名称相同
-
制作数据集
Labelme标注数据转为YOLOV5 训练的数据集 -->还是这个大佬
这篇文章的第二个py程序是将生成的txt文件与标注图片对应生成VOC数据集
通过
这里要注意的点如下:- 数据集中图片和 label 的名称应完全一致。仅文件类型不同
…
生成的数据集目录长这样
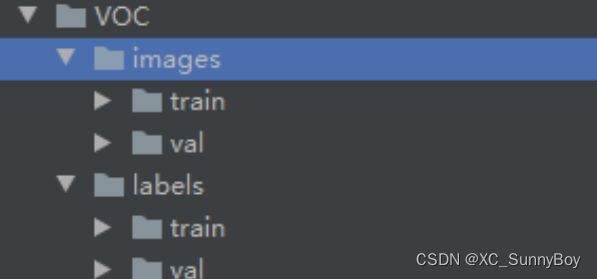
- 数据集中图片和 label 的名称应完全一致。仅文件类型不同
四、使用yolov5进行AI模型训练
-
部署训练所需环境
- anaconda的环境第二阶段1.1已经说过,不重复说了
- yolov5环境安装及搭建
-
创建conda环境
conda create -n pytorch python=3.7
conda activate pytorch -
安装pytorch-cpu
conda install pytorch torchvision torchaudio cpuonly -c pytorch
-
下载yolov5源码
源码地址
https://github.com/ultralytics/yolov5
git clone或者下载zip包都可以git clone https://github.com/ultralytics/yolov5.git
-
搭建yolov5环境
cd yolov5
进度yolov5包中pip执行requirements.txt文件安装相关python第三方库即可pip install -r requirements.txt
-
测试
yolov5本身提供了测试文件cd yolov5
python dect
测试成功的话,会在代码目录下,生成一个run目录,里面有被标注的两张图片,代表yolov5安装成功
-
-
yolov5各模型及数据集的区别
数据集: coco128、coco、VOC
模型:yolov5s(最小的模型)、yolov5m、yolov5l、yolov5x(最大的模型)
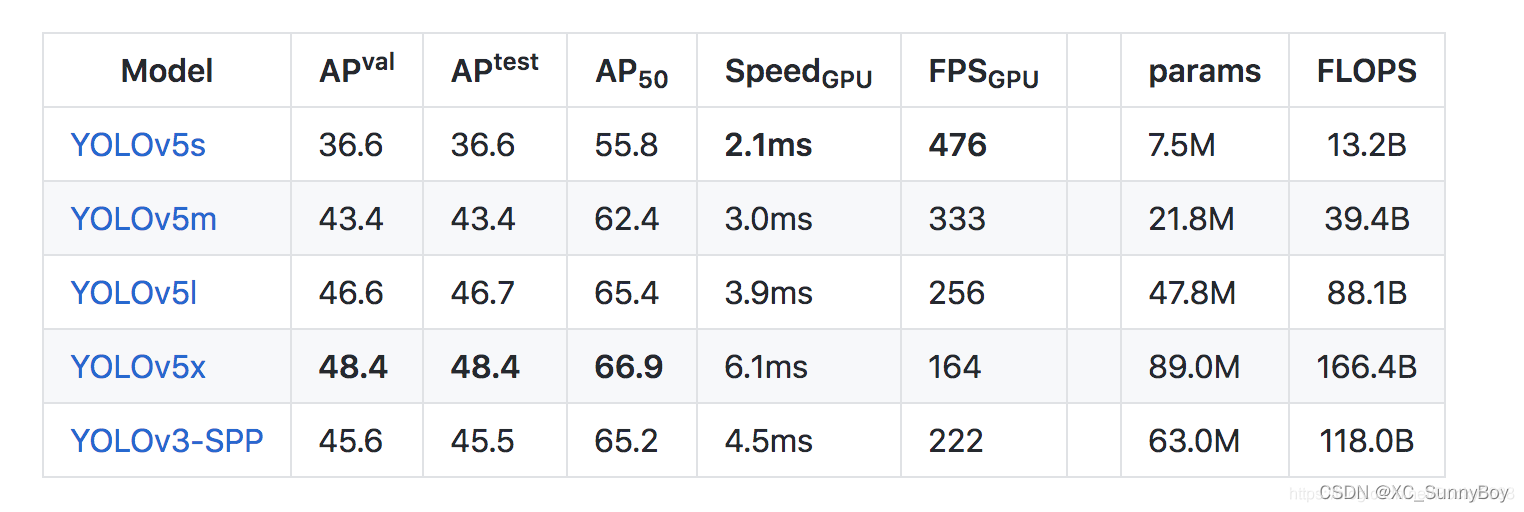
YOLOv5s网络是YOLOv5系列中深度最小,特征图的宽度最小的网络。后面的3种网络都是在此基础上不断加深,不断加宽。
YOLOv5s网络最小,速度最快,AP精度也最低。但如果检测的大目标为主的场景,追求速度,那么这个模型也是一个很好的选择。
其他的三种网络,在此基础上不断的加深加宽网络,AP精度也不断提升,但速度的消耗也在不断增加
-
配置训练的yaml文件,此处以coco128.yaml+yolov5s.yaml为例
-
配置coco128.yaml
原文件配置在这里插入代码片根据需求进行配置即可,此处假设标注类型只有cat,对cat进行训练,固配置如下
注释:我将上述自制的数据集VOC放在了yolov5/data/下# 修改 数据集路径为自己的路径 # 修改 nc 为数据集类的数量 # 修改 names 为数据集中类的名称 vim yolov5-master/data/coco128.yaml path: ../yolov5/data # 数据集主路径 train: VOC/images/train # 改为训练集 路径 val: VOC/images/val # 改为 测试集 路径 nc: 1 # 类的总数量 names: ['cat'] # 类的名称,类名称与标注时标签类名称尽量一一对应 -
配置yolov5s.yaml
原文件现配置(# 仅修改 nc 为对应类的数量即可)
nc: 1
-
-
通过自制数据集,训练权重文件
开始训练
python train.py --img 640 --batch 24 --epochs 100 --data ./data/coco128.yaml --cfg ./models/yolov5s.yaml
使用训练好的模型继续进行训练
python train.py --img 640 --batch 24 --epochs 5100–data ./data/coco128.yaml --cfg ./models/yolov5s.yaml --weights weighs/yolov5s.pt
参数解析
–img:照片尺寸。(输入 32 的倍数。最好和照片最大尺寸相同)
–batch:每次输入网格的图片数量
–epoch:训练的循环次数, 根据需求可自调整次数
–data:指定编辑好的 yaml 文件,coco128.yaml
–cfg:指定编辑好的 yaml 文件,yolov5s.yaml
–weights:指定继续训练的模型训练完成后,会在/yolov5/runs/train下生成训练结果
训练产生的权重文件,存放在 weight 目录下,分为 best.pt和last.pt
best.pt 为精度最高的权重文件(使用及测试时,使用该文件)
last.pt 用于程序中断时,下一次可以继续接着训练
-
测试
使用 代码目录中 的 detect.py 文件,进行测试,测试结果会在 runs/decect/下生成python detect.py --weights ./best.pt --img 640 --source test.mkv
参数解析
–weights:指定权重文件。使用训练后生成的权重文件
–img:指定照片尺寸
–source:指定测试文件存放的地址
五、CUDA环境安装,GPU调用
AI视觉分析如果用CPU版本的pytorch去实现,那么效率极其低下,视觉图像分析,独立显卡的GPU才是王道
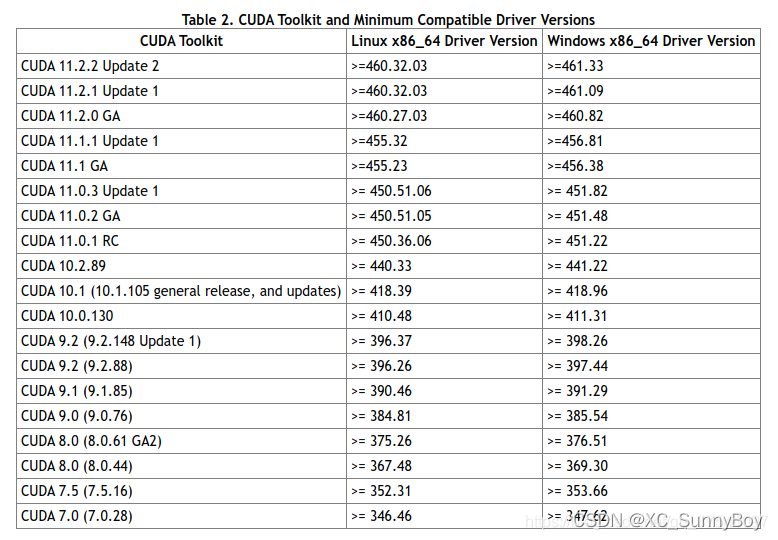
下图为显卡对应的CUDA版本
linux查看显卡信息命令
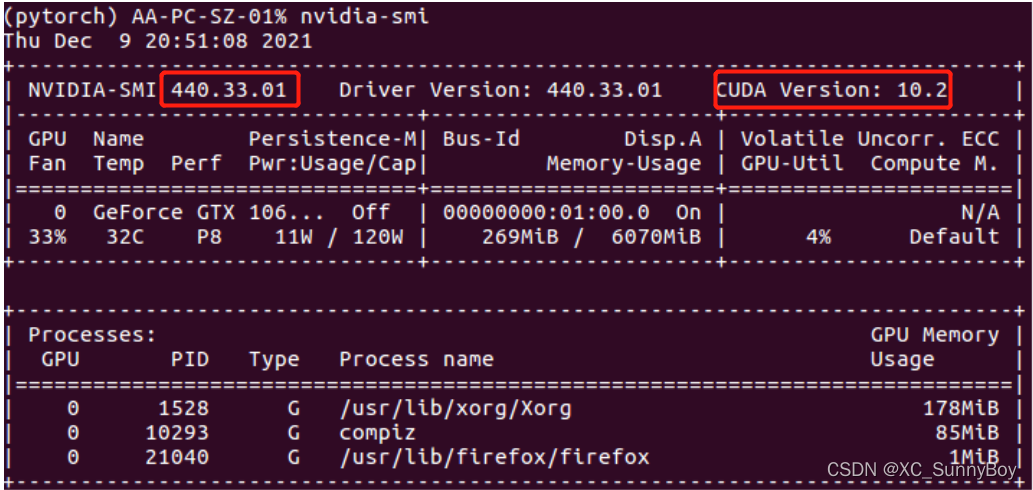
nvidia-smi
nvidia-smi(The Nvidia System Management Interface)是Nvidia显卡命令行管理套件,基于NVML(Nvidia Management Library)库,旨在管理和监控Nvidia GPU设备。
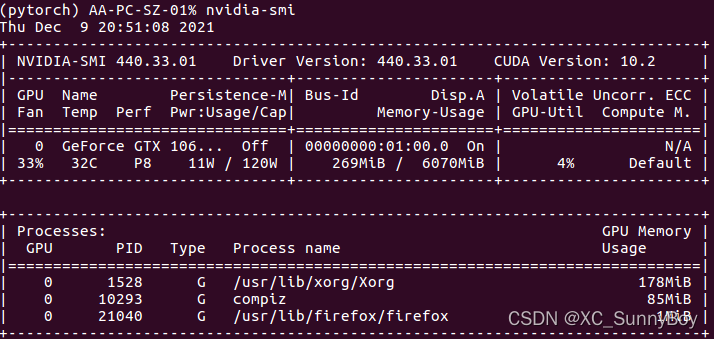
这个电脑已经安装了CUDA 10.2的版本,440.33对应的也是10.2的版本
CUDA与Pytorch版本对https://pytorch.org/get-started/previous-versions/
安装CUDA需要注意的点:
-
CUDA+Pytorch的使用,一定要注意的是版本要对应,电脑显卡(GPU)的版本所对应的CUDA版本,CUDA版本所对应的pytorch版本,pytorch对应的torchvision版本,都必须要一一对应。
-
显卡必须是NADIVA显卡驱动
-
显卡版本过老,对应的CUDA版本过低,使用yolov5可能会报错。初测是CUDA的版本要大于9.2,torch版本要大于1.2.0
如果显卡的驱动过低,则可以通过更新驱动的方式,来更新显卡的版本。也有可能是由于系统的版本太低,版本内核过于老旧,更新下系统也可以试试。
CUDA官方下载地址https://developer.nvidia.com/cuda-downloads
cudnn官方下载https://developer.nvidia.cn/zh-cn/cudnn
CUDA看作是一个工作台,上面配有很多工具,如锤子、螺丝刀等。cuDNN是基于CUDA的深度学习GPU加速库,有了它才能在GPU上完成深度学习的计算。它就相当于工作的工具,比如它就是个扳手。但是CUDA这个工作台买来的时候,并没有送扳手。想要在CUDA上运行深度神经网络,就要安装cuDNN,就像你想要拧个螺帽就要把扳手买回来。这样才能使GPU进行深度神经网络的工作,工作速度相较CPU快很多。
下载合适版本,解压安装即可,具体安装方式不在这里阐述了,如有需要,自行百度下。














 1459
1459











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









