







归一化
(1)什么是归一化?
通俗理解,就是对原始数据进行线性变换把数据映射到[0, 1]区间。
具有的特点:
1、对不同特征维度进行伸缩变换。
2、改变原始数据的分布。使各个特征维度对目标函数的影响权重是一致的(即使得那些扁平分布的数据伸缩变换成类圆形)。
3、对目标函数的影响体现在数值上 。
4、把有量纲表达式变为无量纲表达式 。
(2)归一化有什么优点?
A、使数据处理更加便捷、快速。
B、把有量纲的数据变换为无量纲的纯量,即使数据处于同一数量级,可以消除指标之间的量纲和量纲单位的影响,提高不同数据指标之间的可比性。
C、提升模型的收敛速度。
D、提升模型的精度。
E、深度学习中数据归一化可以防止模型梯度爆炸。
(3)归一化有哪些缺点?
A、最大值与最小值非常容易受异常点影响。
B、鲁棒性较差,只适合传统精确小数据场景。
(4)归一化有哪些方法?
A、线性转换,即min-max归一化(常用方法)例如: y=(x-min)/(max-min)
B、对数函数转换,例如 y=log10(x)
C、反余切函数转换, 例如 y=atan(x)*2/PI
标准化
(1)什么是标准化?
通俗理解,把数据按比例缩放,使之落入一个小的空间里。
具有的特点:对不同特征维度的伸缩变换的目的是使得不同度量之间的特征具有可比性。同时不改变原始数据的分布。
(2)标准化有什么优点?
1、不改变原始数据的分布。保持各个特征维度对目标函数的影响权重 。
2、对目标函数的影响体现在几何分布上 。
3、在已有样本足够多的情况下比较稳定,适合现代嘈杂大数据场景。
(3)标准化有哪些方法?
1、z-score标准化,经过处理后的数据均值为0,标准差为1。方法为:
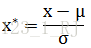
其中,其中μ是样本的均值, σ是样本的标准差。这种标准化方法一般要求原始数据的分布近似为高斯分布(正太分布),否则标准化的效果会变得很差。它们可以通过现有样本进行估计,在已有样本足够多的情况下比较稳定,适合现代嘈杂大数据场景
2、小数定标标准化:通过移动X的小数位置来进行规范化,y= x/10的j次方(其中,j使得Max(|y|) <1的最小整数。
3、对数Logistic模式:新数据=1/(1+e^(-原数据))。
说明:其实网上已经有很多这方面的知识了,为什么自己还要整理,其实是因为,想找一个比较全的资料,方便查阅,算是自己的笔记吧,大神勿喷,多提意见,共同学习 哦,下面是我参考的一些比较好的资源,总结也大部分来自他们文章。
参考资料:
[1]:https://blog.csdn.net/starter_____/article/details/79215684
[2]:https://blog.csdn.net/pipisorry/article/details/52247379
[3]:https://blog.csdn.net/Nicholas_Liu2017/article/details/74852453
[4]:https://blog.csdn.net/u012101561/article/details/72506273
[5]:https://www.zhihu.com/question/20455227














 2284
2284











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









